lightllm
1.0.0
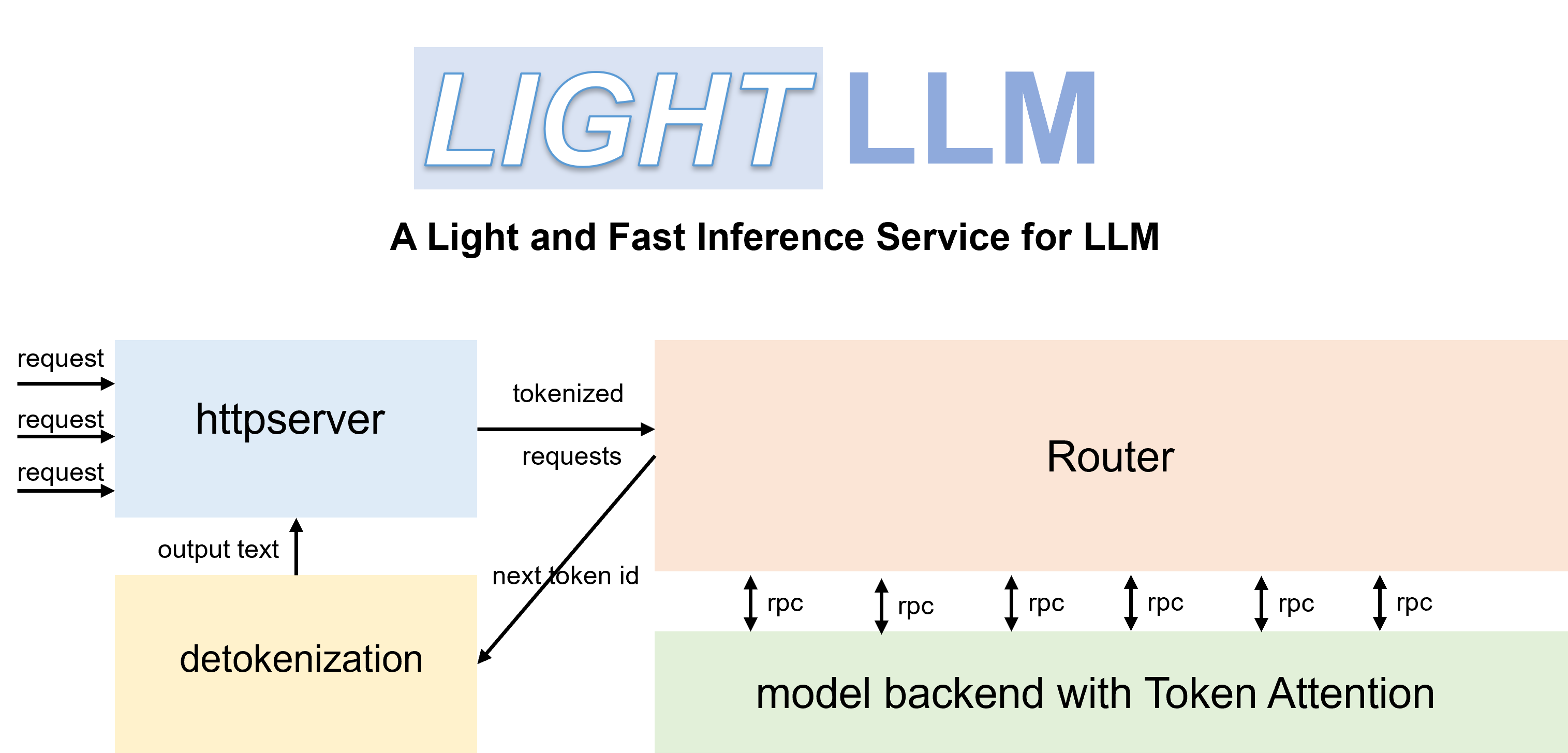
LightLLM ist ein Python-basiertes LLM-Inferenz- und Serving-Framework (Large Language Model), das sich durch sein leichtes Design, einfache Skalierbarkeit und Hochgeschwindigkeitsleistung auszeichnet. LightLLM nutzt die Stärken zahlreicher angesehener Open-Source-Implementierungen, darunter unter anderem FasterTransformer, TGI, vLLM und FlashAttention.
Englische Dokumente | 中文文档
Wenn Sie Qwen-7b starten, müssen Sie den Parameter „--eos_id 151643 --trust_remote_code“ festlegen.
ChatGLM2 muss den Parameter „--trust_remote_code“ setzen.
InternLM muss den Parameter „--trust_remote_code“ setzen.
InternVL-Chat(Phi3) muss den Parameter „--eos_id 32007 --trust_remote_code“ setzen.
InternVL-Chat(InternLM2) muss den Parameter „--eos_id 92542 --trust_remote_code“ setzen.
Qwen2-VL-7b muss den Parameter „--eos_id 151645 --trust_remote_code“ festlegen und „pip install git+https://github.com/huggingface/transformers“ verwenden, um auf die neueste Version zu aktualisieren.
Stablelm muss den Parameter „--trust_remote_code“ festlegen.
Phi-3 unterstützt nur Mini und Small.
DeepSeek-V2-Lite und DeepSeek-V2 müssen den Parameter „--data_type bfloat16“ festlegen.
Der Code wurde mit Pytorch>=1.3, CUDA 11.8 und Python 3.9 getestet. Um die erforderlichen Abhängigkeiten zu installieren, lesen Sie bitte die bereitgestellte Datei „requirements.txt“ und befolgen Sie die Anweisungen
# for cuda 11.8
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
# this version nccl can support torch cuda graph
pip install nvidia-nccl-cu12==2.20.5Sie können den offiziellen Docker-Container verwenden, um das Modell einfacher auszuführen. Gehen Sie dazu folgendermaßen vor:
Ziehen Sie den Container aus der GitHub Container Registry:
docker pull ghcr.io/modeltc/lightllm:mainFühren Sie den Container mit GPU-Unterstützung und Portzuordnung aus:
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
ghcr.io/modeltc/lightllm:main /bin/bashAlternativ können Sie den Container auch selbst bauen:
docker build -t < image_name > .
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
< image_name > /bin/bashSie können auch ein Hilfsskript verwenden, um sowohl den Container als auch den Server zu starten:
python tools/quick_launch_docker.py --help Hinweis: Wenn Sie mehrere GPUs verwenden, müssen Sie möglicherweise die Größe des gemeinsam genutzten Speichers erhöhen, indem Sie --shm-size zum docker run -Ausführungsbefehl hinzufügen.
python setup.py installDer Code wurde auf einer Reihe von GPUs getestet, darunter V100, A100, A800, 4090 und H800. Wenn Sie den Code auf A100, A800 usw. ausführen, empfehlen wir die Verwendung von triton==3.0.0.
pip install triton==3.0.0 --no-depsWenn Sie den Code auf H800 oder V100 ausführen, können Sie triton-nightly ausprobieren, um eine bessere Leistung zu erzielen.
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly --no-depsMit effizienten Routern und TokenAttention kann LightLLM als Dienst bereitgestellt werden und die modernste Durchsatzleistung erreichen.
Starten Sie den Server:
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 120000 Der Parameter max_total_token_num wird vom GPU-Speicher der Bereitstellungsumgebung beeinflusst. Sie können auch --mem_faction angeben, damit es automatisch berechnet wird.
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--mem_faction 0.9So starten Sie eine Abfrage in der Shell:
curl http://127.0.0.1:8080/generate
-X POST
-d ' {"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}} '
-H ' Content-Type: application/json 'So fragen Sie aus Python ab:
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
data = {
'inputs' : 'What is AI?' ,
"parameters" : {
'do_sample' : False ,
'ignore_eos' : False ,
'max_new_tokens' : 1024 ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )python -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/Qwen-VL or /path/of/Qwen-VL-Chatpython -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/llava-v1.5-7b or /path/of/llava-v1.5-13b import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "<img></img>Generate the caption in English with grounding:" ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text ) import json
import requests
import base64
def run_once ( query , uris ):
images = []
for uri in uris :
if uri . startswith ( "http" ):
images . append ({ "type" : "url" , "data" : uri })
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images . append ({ 'type' : "base64" , "data" : b64 })
data = {
"inputs" : query ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" , " <|im_start|>" , " <|im_end|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
# url = "http://127.0.0.1:8080/generate_stream"
url = "http://127.0.0.1:8080/generate"
headers = { 'Content-Type' : 'application/json' }
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( " + result: ({})" . format ( response . json ()))
else :
print ( ' + error: {}, {}' . format ( response . status_code , response . text ))
"""
multi-img, multi-round:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<img></img>
<img></img>
上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>
<|im_start|>assistant
根据提供的信息,两张图片分别是重庆和北京。<|im_end|>
<|im_start|>user
这两座城市分别在什么地方?<|im_end|>
<|im_start|>assistant
"""
run_once (
uris = [
"assets/mm_tutorial/Chongqing.jpeg" ,
"assets/mm_tutorial/Beijing.jpeg" ,
],
query = "<|im_start|>system n You are a helpful assistant.<|im_end|> n <|im_start|>user n <img></img> n <img></img> n上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|> n <|im_start|>assistant n根据提供的信息,两张图片分别是重庆和北京。<|im_end|> n <|im_start|>user n这两座城市分别在什么地方?<|im_end|> n <|im_start|>assistant n "
) import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image> n Please explain the picture. ASSISTANT:" ,
"parameters" : {
"max_new_tokens" : 200 ,
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )Zusätzliche LAN-Parameter:
--enable_multimodal,--cache_capacity, größer--cache_capacityerfordert eine größereshm-size
Unterstützt
--tp > 1, wenntp > 1, wird das visuelle Modell auf der GPU 0 ausgeführt
Das spezielle Bild-Tag für Qwen-VL ist
<img></img>(<image>für Llava), die Länge derdata["multimodal_params"]["images"]sollte mit der Anzahl der Tags, der Zahl, übereinstimmen kann 0, 1, 2, ... sein
Format der Eingabebilder: Liste für Diktate wie
{'type': 'url'/'base64', 'data': xxx}
Wir haben die Serviceleistung von LightLLM und vLLM==0.1.2 auf LLaMA-7B unter Verwendung eines A800 mit 80G GPU-Speicher verglichen.
Bereiten Sie die Daten zunächst wie folgt vor:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.jsonStarten Sie den Dienst:
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode autoAuswertung:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200Die Ergebnisse des Leistungsvergleichs sind nachstehend aufgeführt:
| vLLM | LightLLM |
|---|---|
| Gesamtzeit: 361,79 s Durchsatz: 5,53 Anfragen/s | Gesamtzeit: 188,85 s Durchsatz: 10,59 Anfragen/s |
Zum Debuggen bieten wir statische Performance-Testskripte für verschiedene Modelle an. Beispielsweise können Sie die Inferenzleistung des LLaMA-Modells anhand von bewerten
cd test/model
python test_llama.pypip install protobuf==3.20.0 ausführen.error : PTX .version 7.4 does not support .target sm_89bash tools/resolve_ptx_version python -m lightllm.server.api_server ... Wenn Sie ein Projekt haben, das integriert werden soll, kontaktieren Sie uns bitte per E-Mail oder erstellen Sie eine Pull-Anfrage.
Sobald Sie lightllm und lazyllm installiert haben, können Sie den folgenden Code verwenden, um Ihren eigenen Chatbot zu erstellen:
from lazyllm import TrainableModule , deploy , WebModule
# Model will be download automatically if you have an internet connection
m = TrainableModule ( 'internlm2-chat-7b' ). deploy_method ( deploy . lightllm )
WebModule ( m ). start (). wait ()Dokumente: https://lazyllm.readthedocs.io/
Für weitere Informationen und Diskussionen treten Sie unserem Discord-Server bei.
Dieses Repository wird unter der Apache-2.0-Lizenz veröffentlicht.
Bei der Entwicklung von LightLLM haben wir viel aus den folgenden Projekten gelernt.


