RWKV LM
v5
RWKV-Homepage: https://www.rwkv.com
RWKV-5/6 Eagle/Finch-Papier : https://arxiv.org/abs/2404.05892
Fantastischer RWKV in Vision: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
RWKV-6 3B Demo: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
RWKV-6 7B Demo: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
RWKV-6 GPT-Modus-Democode (mit Kommentaren und Erklärungen) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
RWKV-6 RNN-Modus-Demo: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
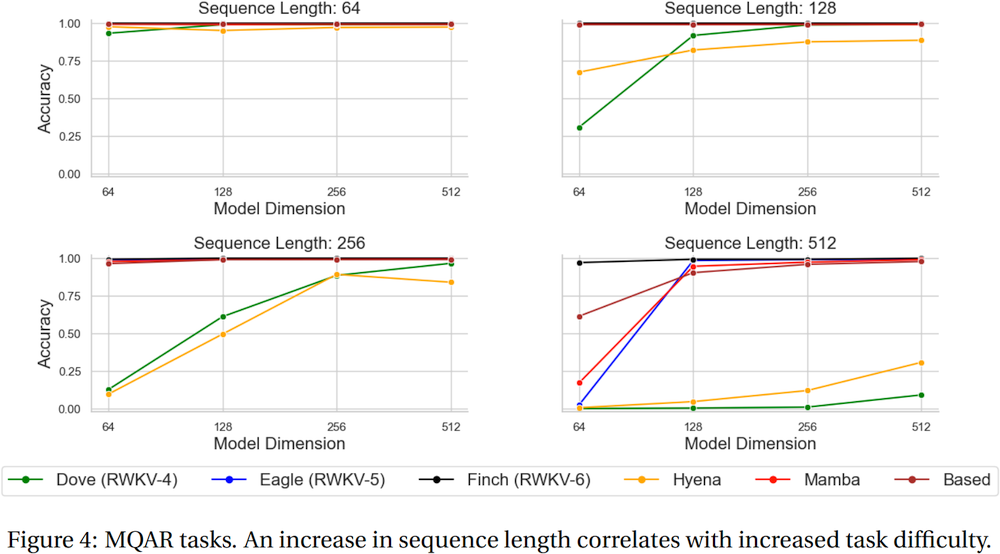
Als Referenz verwenden Sie Python 3.10+, Torch 2.5+, Cuda 12.5+, neueste Deepspeed, aber behalten Sie pytorch-lightning==1.9.5 bei
Trainieren Sie RWKV-6 : Verwenden Sie /RWKV-v5/ und verwenden Sie --my_testing „x060“ in demo-training-prepare.sh und demo-training-run.sh
Trainieren Sie RWKV-7 : Verwenden Sie /RWKV-v5/ und verwenden Sie --my_testing „x070“ in demo-training-prepare.sh und demo-training-run.sh
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
Ihre Verlustkurve sollte fast genau so aussehen, mit den gleichen Höhen und Tiefen (wenn Sie dasselbe BSZ und dieselbe Konfiguration verwenden):
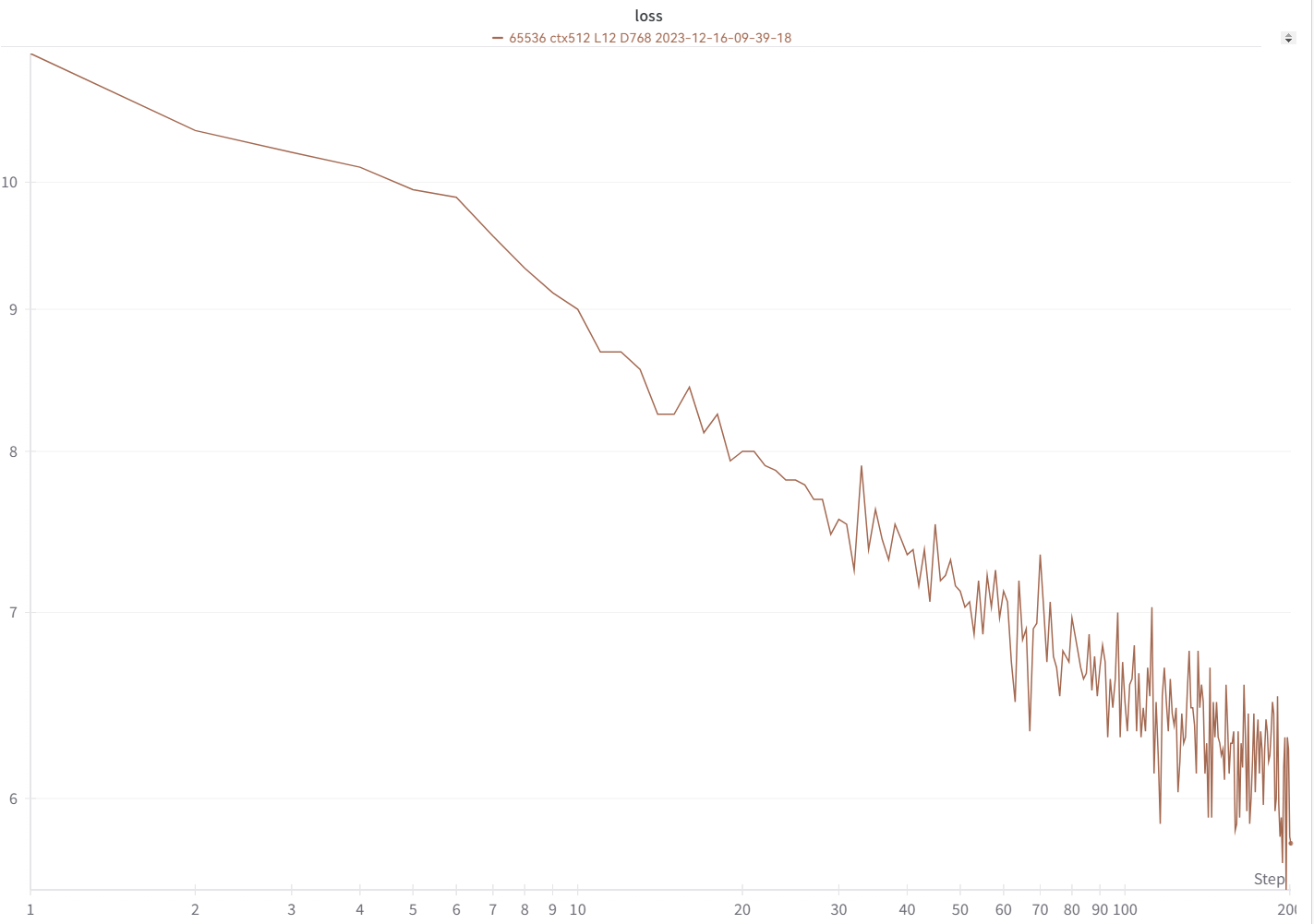
Sie können Ihr Modell mit https://pypi.org/project/rwkv/ ausführen (verwenden Sie „rwkv_vocab_v20230424“ anstelle von „20B_tokenizer.json“).
Verwenden Sie https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py, um Binidx-Daten aus JSONL vorzubereiten und „--my_exit_tokens“ und „--magic_prime“ zu berechnen.
Viel schnellerer Tokenizer für große Datenmengen: https://github.com/cahya-wirawan/json2bin
Die „Epoche“ in train.py ist „Mini-Epoche“ (keine echte Epoche, nur der Einfachheit halber) und 1 Mini-Epoche = 40320 * ctx_len-Token.
Wenn Ihr Binidx beispielsweise 1498226207 Token und ctxlen=4096 hat, legen Sie „--my_exit_tokens 1498226207“ fest (dies überschreibt epoch_count), und es beträgt 1498226207/(40320 * 4096) = 9,07 Miniepochs. Der Trainer wird nach „--my_exit_tokens“-Tokens automatisch beendet. Setzen Sie „--magic_prime“ auf die größte 3n+2 Primzahl kleiner als datalen/ctxlen-1 (= 1498226207/4096-1 = 365776), was in diesem Fall „--magic_prime 365759“ ist.
Ganz einfach: Bereiten Sie SFT jsonl vor => Wiederholen Sie Ihre SFT-Daten drei- oder viermal in make_data.py. Mehr Wiederholung führt zu einer Überanpassung.
Fortgeschritten: Wiederholen Sie Ihre SFT-Daten drei- oder viermal in Ihrem JSONL (beachten Sie, dass make_data.py alle JSONL-Elemente mischt) => fügen Sie einige Basisdaten (z. B. Slimpajama) zu Ihrem JSONL hinzu => und wiederholen Sie den Vorgang nur einmal in make_data.py.
Trainingsspikes reparieren : Siehe den Teil „Reparieren von RWKV-6-Spikes“ auf dieser Seite.
Einfache Schlussfolgerung für RWKV-5 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Einfache Schlussfolgerung für RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
Hinweis: In [state = kv + w * state] muss alles in fp32 sein, da w sehr nahe bei 1 liegen kann. Wir können also state und w in fp32 behalten und kv in fp32 konvertieren.
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
Chat-Demo für Entwickler: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Tipps für kleine Modelle/kleine Datenmengen : Wenn ich RWKV-Musikmodelle trainiere, verwende ich tiefe und schmale Abmessungen (z. B. L29-D512) und wende wd und dropout an (z. B. wd=2 dropout=0,02). Beachten Sie, dass der RWKV-LM-Dropout sehr effektiv ist – verwenden Sie 1/4 Ihres üblichen Wertes.
Verwenden Sie das .jsonl-Format für Ihre Daten (Formate finden Sie unter https://huggingface.co/BlinkDL/rwkv-5-world).
Verwenden Sie https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py, um es mithilfe des World-Tokenizers in binidx zu tokenisieren, was für die Feinabstimmung von World-Modellen geeignet ist.
Benennen Sie den Basisprüfpunkt in Ihrem Modellordner in rwkv-init.pth um und ändern Sie die Trainingsbefehle so, dass sie --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 für 7B verwenden.
0.1B = --n_layer 12 --n_embd 768 // 0.4B = --n_layer 24 --n_embd 1024 // 1.5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 / / 7B = --n_layer 32 --n_embd 4096
Derzeit nicht optimierte Implementierung, benötigt denselben VRAM wie vollständiges SFT
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
Verwenden Sie rwkv 0.8.26+, um den trainierten „time_state“ automatisch zu laden.
Wenn Sie RWKV von Grund auf trainieren, probieren Sie meine Initialisierung aus, um die beste Leistung zu erzielen. Überprüfen Sie „generate_init_weight()“ von src/model.py:
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!! Wenn Sie positionelle Einbettung verwenden, ist es vielleicht besser, block.0.ln0 zu entfernen und die Standardinitialisierung für emb.weight anstelle von my uniform_(a=-1e-4, b=1e-4) zu verwenden !!!
Wenn Sie von Grund auf trainieren, fügen Sie „k = k * Torch.clamp(w, max=0).exp()“ vor „RUN_CUDA_RWKV6(r, k, v, w, u)“ hinzu und denken Sie daran, auch Ihren Inferenzcode zu ändern . Sie werden eine schnellere Konvergenz feststellen.
Verwenden Sie „--adam_eps 1e-18“
„--beta2 0,95“, wenn Sie Spitzen sehen
in Trainer.py machen Sie „lr = lr * (0,01 + 0,99 * Trainer.global_step / w_step)“ (ursprünglich 0,2 + 0,8) und „--warmup_steps 20“
„--weight_decay 0.1“ führt zu einem besseren Endverlust, wenn Sie viele Daten trainieren. Setzen Sie dabei lr_final auf 1/100 von lr_init.
RWKV ist ein RNN mit LLM-Leistung auf Transformer-Ebene, das auch direkt wie ein GPT-Transformator trainiert werden kann (parallelisierbar). Und es ist 100 % aufmerksamkeitsfrei. Sie benötigen nur den verborgenen Zustand an Position t, um den Zustand an Position t+1 zu berechnen. Sie können den „GPT“-Modus verwenden, um schnell den verborgenen Zustand für den „RNN“-Modus zu berechnen.
Es kombiniert also das Beste von RNN und Transformer – großartige Leistung, schnelle Inferenz, spart VRAM, schnelles Training, „unendliche“ ctx_len und kostenlose Satzeinbettung (unter Verwendung des endgültigen verborgenen Zustands).
RWKV Runner GUI https://github.com/josStorer/RWKV-Runner mit Ein-Klick-Installation und API
Alle aktuellen RWKV-Gewichte: https://huggingface.co/BlinkDL
HF-kompatible RWKV-Gewichte: https://huggingface.co/RWKV
RWKV-Pip-Paket : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (erfordert zum Trainieren keinen benutzerdefinierten CUDA-Kernel, funktioniert für jede GPU/CPU)
Twitter : https://twitter.com/BlinkDL_AI
Homepage : https://www.rwkv.com
Coole Community-RWKV-Projekte :
Alle (über 300) RWKV-Projekte: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV Vision RWKV
https://github.com/feizc/Diffusion-RWKV Diffusion RWKV
https://github.com/cgisky1980/ai00_rwkv_server Schnellste WebGPU-Inferenz (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv Backend für ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp Schnelle CPU/cuBLAS/CLBlast-Inferenz: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state tuning
https://github.com/RWKV/RWKV-infctx-trainer Infctx-Trainer
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md Digitaler Assistent mit RWKV
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda Schnelle GPU-Inferenz mit cuda/amd/vulkan
RWKV v6 in 250 Zeilen (auch mit Tokenizer): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 in 250 Zeilen (auch mit Tokenizer): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 in 150 Zeilen (Modell, Inferenz, Textgenerierung): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
RWKV v4 Vorabdruck https://arxiv.org/abs/2305.13048
Einführung in RWKV v4 und in 100 Zeilen Numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
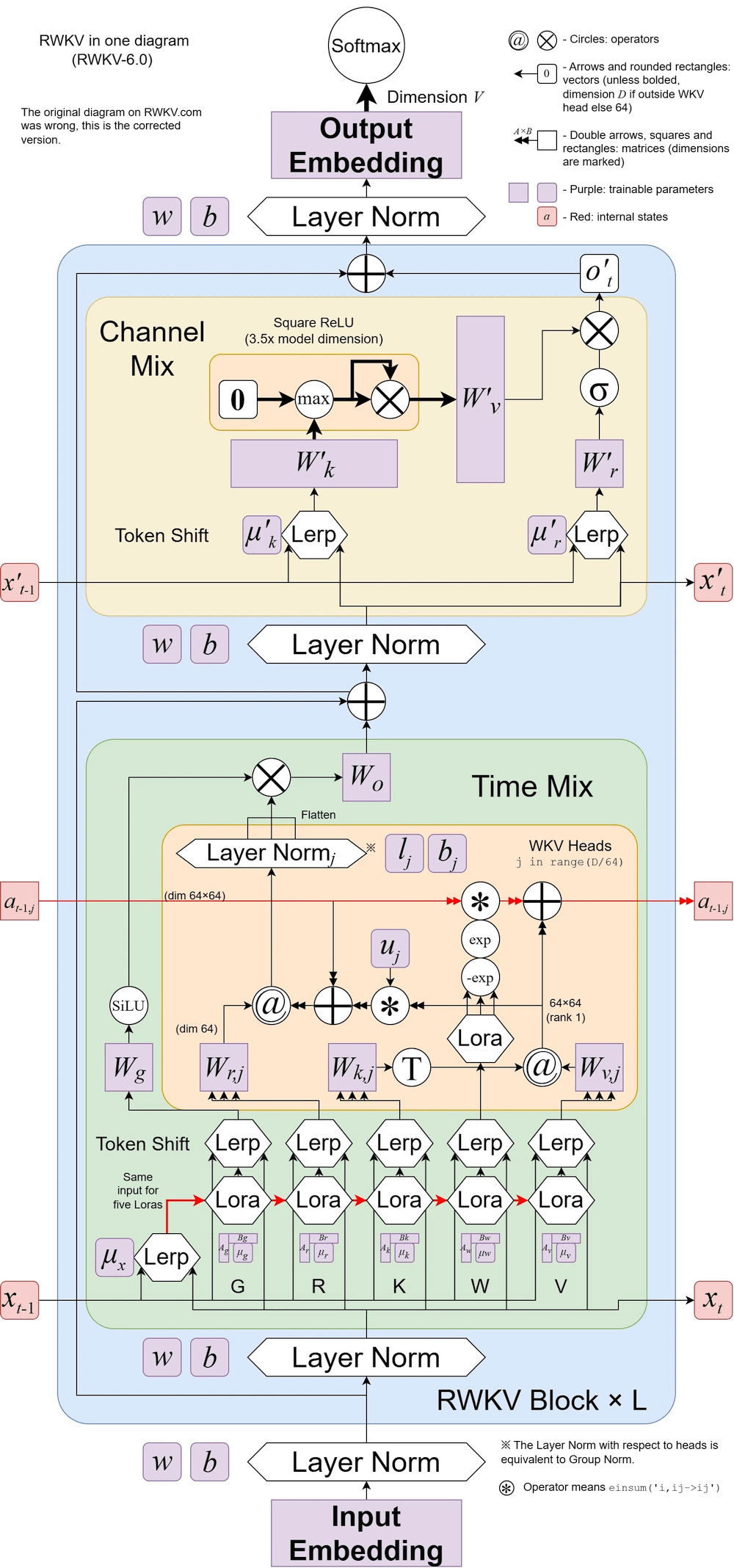
RWKV v6 illustriert:
Ein cooler Artikel (Spiking Neural Network) mit RWKV: https://github.com/ridgerchu/SpikeGPT
Sie sind herzlich eingeladen, dem RWKV-Discord https://discord.gg/bDSBUMeFpc beizutreten, um darauf aufzubauen. Wir verfügen jetzt über reichlich potenzielle Rechenleistung (A100 40Gs) (dank Stability und EleutherAI). Wenn Sie also interessante Ideen haben, kann ich sie ausführen.

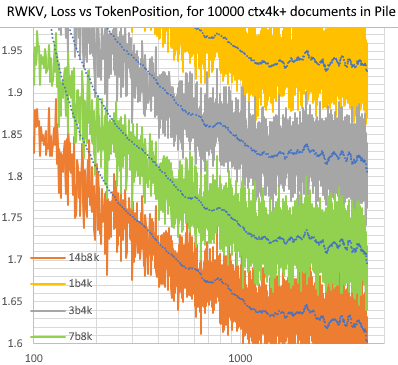
RWKV [Verlust vs. Token-Position] für 10.000 ctx4k+-Dokumente im Stapel. RWKV 1B5-4k ist nach ctx1500 größtenteils flach, aber 3B-4k und 7B-4k und 14B-4k weisen einige Steigungen auf und werden besser. Dies widerlegt die alte Ansicht, dass RNNs keine langen Cctxlens modellieren können. Wir können vorhersagen, dass RWKV 100B großartig sein wird und RWKV 1T wahrscheinlich alles ist, was Sie brauchen :)
ChatRWKV mit RWKV 14B ctx8192:

Ich glaube, dass RNN ein besserer Kandidat für grundlegende Modelle ist, weil: (1) es für ASICs geeigneter ist (kein KV-Cache). (2) Es ist freundlicher für RL. (3) Wenn wir schreiben, ähnelt unser Gehirn eher RNN. (4) Das Universum ist ebenfalls wie ein RNN (wegen der Lokalität). Transformatoren sind nicht-lokale Modelle.
RWKV-3 1,5B auf A40 (tf32) = immer 0,015 Sek./Token, getestet mit einfachem Pytorch-Code (kein CUDA), GPU-Auslastung 45 %, VRAM 7823M
GPT2-XL 1.3B auf A40 (tf32) = 0,032 Sek./Token (für ctxlen 1000), getestet mit HF, GPU-Auslastung ebenfalls 45 % (interessant), VRAM 9655M
Trainingsgeschwindigkeit: (neuer Trainingscode) RWKV-4 14B BF16 ctxlen4096 = 114.000 Token/s auf 8x8 A100 80G (NULL2+CP). (alter Trainingscode) RWKV-4 1.5B BF16 ctxlen1024 = 106.000 Token/s auf 8xA100 40G.
Ich mache auch Bildexperimente (zum Beispiel: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder) und RWKV wird in der Lage sein, txt2img-Diffusion durchzuführen :) Meine Idee: 256x256 RGB-Bild -> 32x32x13bit latente Bilder - > Wenden Sie RWKV an, um die Übergangswahrscheinlichkeit für jedes der 32x32-Gitter zu berechnen -> Stellen Sie sich vor, die Gitter wären unabhängig und „diffusieren“ mithilfe dieser Wahrscheinlichkeiten.
Reibungsloses Training – keine Verlustspitzen! (lr & bsz ändern sich um 15G-Token) 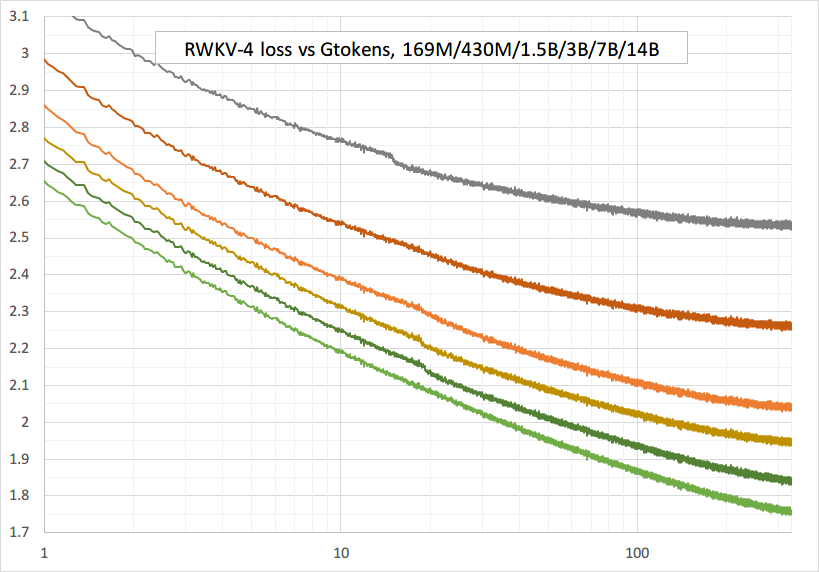
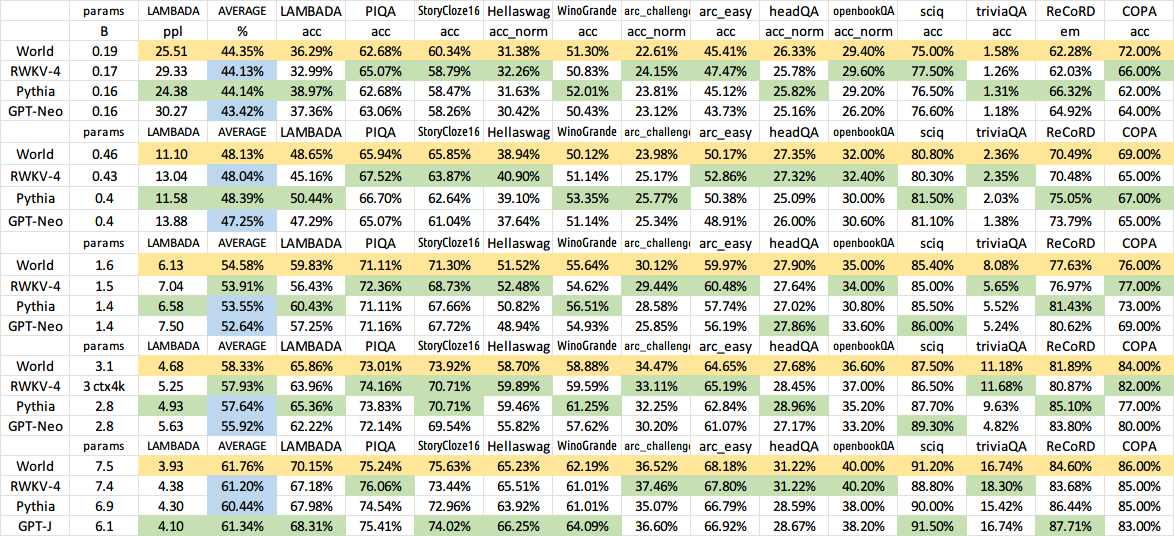
Alle trainierten Modelle werden Open Source sein. Die Inferenz ist selbst auf CPUs sehr schnell (nur Matrix-Vektor-Multiplikationen, keine Matrix-Matrix-Multiplikationen), sodass Sie sogar ein LLM auf Ihrem Telefon ausführen können.
So funktioniert es: RWKV sammelt Informationen zu einer Reihe von Kanälen, die ebenfalls mit unterschiedlicher Geschwindigkeit abklingen, wenn Sie zum nächsten Token wechseln. Es ist ganz einfach, wenn man es erst einmal verstanden hat.
RWKV ist parallelisierbar, da der Zeitabfall jedes Kanals datenunabhängig (und trainierbar) ist . Beispielsweise können Sie im üblichen RNN den Zeitabfall eines Kanals von beispielsweise 0,8 auf 0,5 einstellen (diese werden „Gates“ genannt), während Sie im RWKV einfach die Informationen von einem W-0,8-Kanal auf einen W-0,5 verschieben -Kanal, um den gleichen Effekt zu erzielen. Darüber hinaus können Sie RWKV in ein nicht parallelisierbares RNN verfeinern (dann können Sie Ausgaben späterer Schichten des vorherigen Tokens verwenden), wenn Sie zusätzliche Leistung wünschen.

Hier sind einige meiner TODOs. Lasst uns zusammenarbeiten :)
HuggingFace-Integration (siehe Huggingface/Transformers#17230) und optimierte CPU-, iOS-, Android-, WASM- und WebGL-Inferenz. RWKV ist ein RNN und sehr freundlich für Edge-Geräte. Machen wir es möglich, ein LLM auf Ihrem Telefon auszuführen.
Testen Sie es mit bidirektionalen und MLM-Aufgaben sowie Bild-, Audio- und Video-Tokens. Ich denke, RWKV kann Encoder-Decoder auf folgende Weise unterstützen: Verwenden Sie für jedes Decoder-Token eine erlernte Mischung aus [vorheriger verborgener Zustand des Decoders] und [endgültiger verborgener Zustand des Encoders]. Daher haben alle Decoder-Token Zugriff auf den Encoder-Ausgang.
Trainieren Sie jetzt RWKV-4a mit einer einzigen kleinen zusätzlichen Aufmerksamkeit (nur ein paar zusätzliche Zeilen im Vergleich zu RWKV-4), um einige schwierige Nullschussaufgaben (wie LAMBADA) für kleinere Modelle weiter zu verbessern. Siehe https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
Benutzer-Feedback:
Bisher habe ich mit dem zeichenbasierten Modell auf unserem relativ kleinen Datensatz vor dem Training herumgespielt (ungefähr 10 GB Text), und die Ergebnisse sind extrem gut – ähnlich wie bei Modellen, deren Training viel, viel länger dauert.
Lieber Gott, RWKV ist schnell. Ich wechselte zu einem anderen Tab, nachdem ich angefangen hatte, es von Grund auf zu trainieren, und als ich zurückkam, gab es plausible englische und Maori-Wörter aus, ich ging, um Kaffee in die Mikrowelle zu stellen, und als ich zurückkam, produzierte es völlig grammatikalisch korrekte Sätze.
Tweet von Sepp Hochreiter (Danke!): https://twitter.com/HochreiterSepp/status/1524270961314484227
Sie finden mich (BlinkDL) auch im EleutherAI Discord: https://www.eleuther.ai/get-involved/
WICHTIG: Verwenden Sie deepspeed==0.7.0 pytorch-lightning==1.9.5 Torch==1.13.1+cu117 und cuda 11.7.1 oder 11.7 (beachten Sie, dass Torch2 + Deepspeed seltsame Fehler aufweist und die Modellleistung beeinträchtigt).
Verwenden Sie https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (neuester Code, kompatibel mit v4).
Hier finden Sie eine hervorragende Möglichkeit zum Testen von Fragen und Antworten zu LLMs. Funktioniert für jedes Modell: (gefunden durch Minimierung der ChatGPT-Personen für RWKV 1.5B)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisFühren Sie RWKV-4-Pfahlmodelle aus: Laden Sie Modelle von https://huggingface.co/BlinkDL herunter. Setzen Sie TOKEN_MODE = 'pile' in run.py und führen Sie es aus. Selbst im CPU-Betrieb (Standardmodus) ist es schnell.
Colab für RWKV-4 Pile 1.5B : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
Führen Sie RWKV-4 Pile-Modelle in Ihrem Browser (und der Onnx-Version) aus: siehe diese Ausgabe Nr. 7
RWKV-4-Webdemo: https://josephrocca.github.io/rwkv-v4-web/demo/ (Hinweis: vorerst nur Gier-Sampling)
Für den alten RWKV-2: Sehen Sie sich die Veröffentlichung hier für ein 27M-Parametermodell auf enwik8 mit 0,72 BPC(dev) an. Führen Sie run.py unter https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN aus. Sie können es sogar in Ihrem Browser ausführen: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (dies verwendet tf.js WASM Single-Thread-Modus).
pip install deepspeed==0.7.0 // pip install pytorch-lightning==1.9.5 // Torch 1.13.1+cu117
HINWEIS: Fügen Sie Gewichtsabfall (0,1 oder 0,01) und Dropout (0,1 oder 0,01) hinzu, wenn Sie mit einer kleinen Datenmenge trainieren. Versuchen Sie x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) usw.
Trainieren Sie RWKV-4 von Grund auf: Führen Sie train.py aus, das standardmäßig den enwik8-Datensatz verwendet (entpacken Sie https://data.deepai.org/enwik8.zip).
Sie trainieren die „GPT“-Version, da diese parallezierbar und schneller zu trainieren ist. RWKV-4 kann extrapolieren, sodass das Training mit ctxLen 1024 für ctxLen von 2500+ funktionieren kann. Sie können das Modell mit längeren ctxLens feinabstimmen und es kann sich schnell an längere ctxLens anpassen.
Feinabstimmung der RWKV-4-Pile-Modelle: Verwenden Sie „prepare-data.py“ in https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3, um .txt in den Zug zu tokenisieren. NPY-Daten. Verwenden Sie dann https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py, um es zu trainieren.
Lesen Sie den Inferenzcode in src/model.py und versuchen Sie, den endgültigen verborgenen Zustand (.xx .aa .bb) als originalgetreue Satzeinbettung für andere Aufgaben zu verwenden. Wahrscheinlich sollten Sie mit .xx und .aa/.bb beginnen (.aa dividiert durch .bb).
Colab zur Feinabstimmung von RWKV-4-Pfahlmodellen: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
Großer Korpus: Verwenden Sie https://github.com/Abel2076/json2binidx_tool, um .jsonl in .bin und .idx zu konvertieren
Das JSONL-Formatbeispiel (eine Zeile für jedes Dokument):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
generiert durch Code wie diesen:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
Unendliches Cctxlen-Training (WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
Betrachten Sie RWKV 14B. Der Zustand hat 200 Vektoren, also 5 Vektoren für jeden Block: fp16 (xx), fp32 (aa), fp32 (bb), fp32 (pp), fp16 (xx).
Verwenden Sie keinen Durchschnittspool, da verschiedene Vektoren (xx aa bb pp xx) im Bundesstaat sehr unterschiedliche Bedeutungen und Bereiche haben. Sie können pp wahrscheinlich entfernen.
Ich schlage vor, zunächst die Mittelwert- und Standardabweichungsstatistiken für jeden Kanal jedes Vektors zu erfassen und alle zu normalisieren (Hinweis: Die Normalisierung sollte datenunabhängig sein und aus verschiedenen Texten erfasst werden). Dann trainieren Sie einen linearen Klassifikator.
RWKV-5 ist mehrköpfig und zeigt hier einen Kopf. Außerdem gibt es für jeden Kopf eine LayerNorm (also eigentlich GroupNorm).
Dynamischer Mix und dynamischer Decay. Beispiel (tun Sie dies sowohl für TimeMix als auch für ChannelMix):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

Verwenden Sie den parallelisierten Modus, um den Status schnell zu generieren, und verwenden Sie dann ein fein abgestimmtes vollständiges RNN (die Schichten von Token n können Ausgaben aller Schichten von Token n-1 verwenden) für die sequentielle Generierung.
Jetzt beträgt der Zeitabfall etwa 0,999^T (0,999 ist lernbar). Ändern Sie es in etwas wie (0,999^T + 0,1), wobei 0,1 auch erlernbar ist. Der 0,1-Teil bleibt für immer erhalten. Oder A^T + B^T + C = schneller Zerfall + langsamer Zerfall + Konstante. Es können sogar andere Formeln verwendet werden (z. B. K^2 anstelle von e^K für eine Zerfallskomponente oder ohne Normalisierung).
Verwenden Sie in einigen Kanälen einen komplexwertigen Zerfall (also Rotation statt Zerfall).
Eine trainierbare und extrapolierbare Positionskodierung einbauen?
Neben der 2D-Rotation können wir auch andere Lie-Gruppen wie die 3D-Rotation (SO(3)) ausprobieren. Nicht-abelsches RWKV lol.
RWKV eignet sich möglicherweise hervorragend für analoge Geräte (suchen Sie nach Analog Matrix-Vektormultiplikation und Photonic Matrix-Vektormultiplikation). Der RNN-Modus ist sehr hardwarefreundlich (Verarbeitung im Speicher). Kann auch ein SNN sein (https://github.com/ridgerchu/SpikeGPT). Ich frage mich, ob es für die Quantenberechnung optimiert werden kann.
Trainierbarer anfänglicher verborgener Zustand (xx aa bb pp xx).
Layerweise (oder sogar zeilen-/spaltenweise, elementweise) LR und testen Sie den Lion-Optimierer.
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
Vielleicht können wir das Auswendiglernen verbessern, indem wir einfach den Kontext wiederholen (ich denke, zwei Mal ist genug). Beispiel: Referenz -> Referenz(erneut) -> Frage -> Antwort
Die Idee besteht darin, sicherzustellen, dass jedes Token im Vokabular seine Länge und die rohen UTF-8-Bytes versteht.
Sei a = max(len(token)) für alle Token im Vokabular. AA definieren: float[a][d_emb]
Sei b = max(len_in_utf8_bytes(token)) für alle Token im Vokabular. BB definieren: float[b][256][d_emb]
Für jedes Token X im Vokabular seien [x0, x1, ..., xn] seine rohen UTF-8-Bytes. Wir werden seiner Einbettung EMB(X) einige zusätzliche Werte hinzufügen:
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (Hinweis: AA BB sind lernbare Gewichte)
Ich habe eine Idee, die Tokenisierung zu verbessern. Wir können einige Kanäle fest codieren, damit sie Bedeutungen haben. Beispiel:
Kanal 0 = „Leerzeichen“
Kanal 1 = „Anfangsbuchstaben groß schreiben“
Kanal 2 = „Alle Buchstaben groß schreiben“
Daher:
Einbettung von „abc“: [0, 0, 0, x0, x1, x2, ..]
Einbettung von „abc“: [1, 0, 0, x0, x1, x2, ..]
Einbettung von „Abc“: [1, 1, 0, x0, x1, x2, ..]
Einbettung von „ABC“: [0, 0, 1, x0, x1, x2, ...]
......
Daher teilen sie sich den Großteil der Einbettung. Und wir können die Ausgabewahrscheinlichkeit aller Variationen von „abc“ schnell berechnen.
Hinweis: Die obige Methode geht davon aus, dass p(" xyz") / p("xyz") für jedes "xyz" gleich ist, was falsch sein kann.
Besser: Definieren Sie „emb_space“, „em_capitalize_first“, „emb_capitalize_all“ als eine Funktion von „em“.
Vielleicht das Beste: Lassen Sie „abc“, „abc“ usw. die letzten 90 % ihrer Einbettungen teilen.
Derzeit geben alle unsere Tokenisierer zu viele Elemente aus, um alle Variationen von „abc“, „abc“, „Abc“ usw. darzustellen. Darüber hinaus kann das Modell nicht erkennen, dass diese tatsächlich ähnlich sind, wenn einige dieser Variationen im Datensatz selten sind. Die Methode hier kann dies verbessern. Ich habe vor, dies in einer neuen Version von RWKV zu testen.
Beispiel (Fragen und Antworten in einer Runde):
Erzeugen Sie den Endzustand aller Wiki-Dokumente.
Suchen Sie für jeden Benutzer Q das beste Wiki-Dokument und verwenden Sie seinen Endzustand als Anfangszustand.
Trainieren Sie ein Modell, um für jeden Benutzer Q direkt den optimalen Anfangszustand zu generieren.
Bei Fragen und Antworten in mehreren Runden kann dies jedoch etwas schwieriger sein :)
RWKV ist von Apples AFT inspiriert (https://arxiv.org/abs/2105.14103).
Darüber hinaus nutzt es eine Reihe meiner Tricks, wie zum Beispiel:
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb (gilt für alle Transformatoren), was die Einbettungsqualität verbessert und Post-LN stabilisiert (was ich verwende).
Token-Shift: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (gilt für alle Transformatoren), besonders hilfreich für Modelle auf Char-Ebene.
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (gilt für alle Transformer). Hinweis: Es ist hilfreich, aber ich habe es im Pile-Modell deaktiviert, um 100 % RNN beizubehalten.
Zusätzliches R-Gate im FFN (gilt für alle Transformatoren). Ich verwende auch reluSquared von Primer.
Bessere Initialisierung: Ich initiiere die meisten Matrizen auf NULL (siehe RWKV_Init in https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py).
Sie können einige Parameter von einem kleinen Modell auf ein großes Modell übertragen (Hinweis: Ich sortiere und glätte sie auch), um eine schnellere und bessere Konvergenz zu erreichen (siehe https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with /).
Mein CUDA-Kernel: https://github.com/BlinkDL/RWKV-CUDA zur Beschleunigung des Trainings.

Die abcd-Faktoren bilden zusammen eine Zeit-Abklingkurve: [X, 1, W, W^2, W^3, ...].
Schreiben Sie die Formeln für „Token an Pos 2“ und „Token an Pos 3“ auf und Sie werden auf die Idee kommen:
kv/k ist der Speichermechanismus. Der Token mit hohem k kann lange im Gedächtnis bleiben, wenn W im Kanal nahe bei 1 liegt.
Das R-Gate ist wichtig für die Leistung. k = Informationsstärke dieses Tokens (wird an zukünftige Token weitergegeben). r = ob die Informationen auf dieses Token angewendet werden sollen.
Verwenden Sie unterschiedliche trainierbare TimeMix-Faktoren für R/K/V in SA- und FF-Schichten. Beispiel:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )Verwenden Sie preLN anstelle von postLN (stabilere und schnellere Konvergenz):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))Die Bausteine des RWKV-3-GPT-Modus ähneln denen eines üblichen PreLN-GPT.
Der einzige Unterschied besteht in einem zusätzlichen LN nach der Einbettung. Beachten Sie, dass Sie diese LN nach Abschluss des Trainings in die Einbettung aufnehmen können.
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logitsEs ist wichtig, Emb auf winzige Werte wie nn.init.uniform_(a=-1e-4, b=1e-4) zu initialisieren, um meinen Trick https://github.com/BlinkDL/SmallInitEmb anzuwenden.
Für den 1.5B RWKV-3 verwende ich den Adam-Optimierer (kein WD, kein Dropout) auf 8 * A100 40G.
BatchSz = 32 * 896, ctxLen = 896. Ich verwende tf32, daher ist BatchSz etwas klein.
Für die ersten 15B Token ist LR auf 3e-4 und Beta=(0,9, 0,99) festgelegt.
Dann setze ich Beta=(0,9, 0,999) und führe einen exponentiellen Abfall von LR durch, der 1e-5 bei 332B Token erreicht.
Der RWKV-3 hat keine Aufmerksamkeit im üblichen Sinne, wir werden diesen Block aber trotzdem ATT nennen.
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionDie Matrizen self.key, self.receptance und self.output werden alle auf Null initialisiert.
Die Vektoren time_mix, time_decay und time_first werden von einem kleineren trainierten Modell übertragen (Hinweis: Ich sortiere und glätte sie auch).
Der FFN-Block hat im Vergleich zum üblichen GPT drei Tricks:
Mein time_mix-Trick.
Die sqReLU aus dem Primer-Papier.
Ein zusätzliches Empfangstor (ähnlich dem Empfangstor im ATT-Block).
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvDie Selbstwert- und Selbstrezeptionsmatrizen werden alle auf Null initialisiert.

Sei F[t] der Systemzustand zum Zeitpunkt t.
Sei x[t] die neue externe Eingabe zum Zeitpunkt t.
In GPT erfordert die Vorhersage von F[t+1] die Berücksichtigung von F[0], F[1], ... F[t]. Es ist also O(T^2) erforderlich, um eine Sequenz der Länge T zu erzeugen.
Die vereinfachte Formel für GPT:
Theoretisch ist es sehr leistungsfähig, das bedeutet jedoch nicht, dass wir seine Leistungsfähigkeit mit üblichen Optimierern voll ausschöpfen können . Ich vermute, dass die Verlustlandschaft für unsere derzeitigen Methoden zu schwierig ist.
Vergleichen Sie mit der vereinfachten Formel für RWKV (der Parallelmodus sieht ähnlich aus wie Apples AFT):
R, K, V sind trainierbare Matrizen und W ist ein trainierbarer Vektor (Zeitabfallfaktor für jeden Kanal).
In GPT wird der Beitrag von F[i] zu F[t+1] mit gewichtet.
In RWKV-2 wird der Beitrag von F[i] zu F[t+1] mit gewichtet.
Hier kommt die Pointe: Wir können es in eine RNN (rekursive Formel) umschreiben. Notiz:
Daher ist es einfach zu überprüfen:
wobei A[t] und B[t] jeweils der Zähler und der Nenner des vorherigen Schritts sind.
Ich glaube, dass RWKV performant ist, weil W dem wiederholten Anwenden einer Diagonalmatrix gleicht. Beachten Sie, dass (P^{-1} DP)^n = P^{-1} D^n P ist, es ähnelt also der wiederholten Anwendung einer allgemeinen diagonalisierbaren Matrix.
Darüber hinaus ist es möglich, es in eine kontinuierliche ODE umzuwandeln (ähnlich wie State Space Models). Ich werde später darüber schreiben.
Ich habe eine Idee für [Text -> 32x32 RGB-Bild] mit einem LM (Transformator, RWKV usw.). Werde es bald testen.
Erstens LM-Verlust (anstelle von L2-Verlust), damit das Bild nicht unscharf wird.
Zweitens Farbquantisierung. Lassen Sie beispielsweise nur 8 Stufen für R/G/B zu. Dann beträgt die Bildvokabulargröße 8x8x8 = 512 (für jedes Pixel) statt 2^24. Daher ist ein 32x32 RGB-Bild = eine len1024-Sequenz von vocab512 (Bild-Tokens), was eine typische Eingabe für übliche LMs ist. (Später können wir Diffusionsmodelle verwenden, um RGB888-Bilder hochzurechnen und zu generieren. Möglicherweise können wir hierfür auch einen LM verwenden.)
Drittens: 2D-Positionseinbettungen, die für das Modell leicht zu verstehen sind. Fügen Sie beispielsweise One-Hot-X- und Y-Koordinaten zu den ersten 64 (=32+32) Kanälen hinzu. Angenommen, das Pixel liegt bei x=8, y=20, dann addieren wir 1 zu Kanal 8 und Kanal 52 (=32+20). Darüber hinaus können wir wahrscheinlich die Float-X- und Y-Koordinaten (normalisiert auf den Bereich 0–1) zu weiteren 2 Kanälen hinzufügen. Und andere periodische Pos. Codierung könnte auch helfen (wird getestet).
Schließlich RandRound wann


