EasyInstruct
1.0.0

Ein benutzerfreundliches Framework zur Befehlsverarbeitung für große Sprachmodelle.
Projekt • Papier • Demo • Übersicht • Installation • Schnellstart • Verwendung • Dokumente • Video • Zitat • Mitwirkende
Dieses Repository ist ein Teilprojekt von KnowLM.
EasyInstruct ist ein Python-Paket, das als benutzerfreundliches Framework zur Befehlsverarbeitung für Large Language Models (LLMs) wie GPT-4, LLaMA und ChatGLM in Ihren Forschungsexperimenten vorgeschlagen wird. EasyInstruct modularisiert die Generierung, Auswahl und Aufforderung von Anweisungen und berücksichtigt dabei auch deren Kombination und Interaktion.
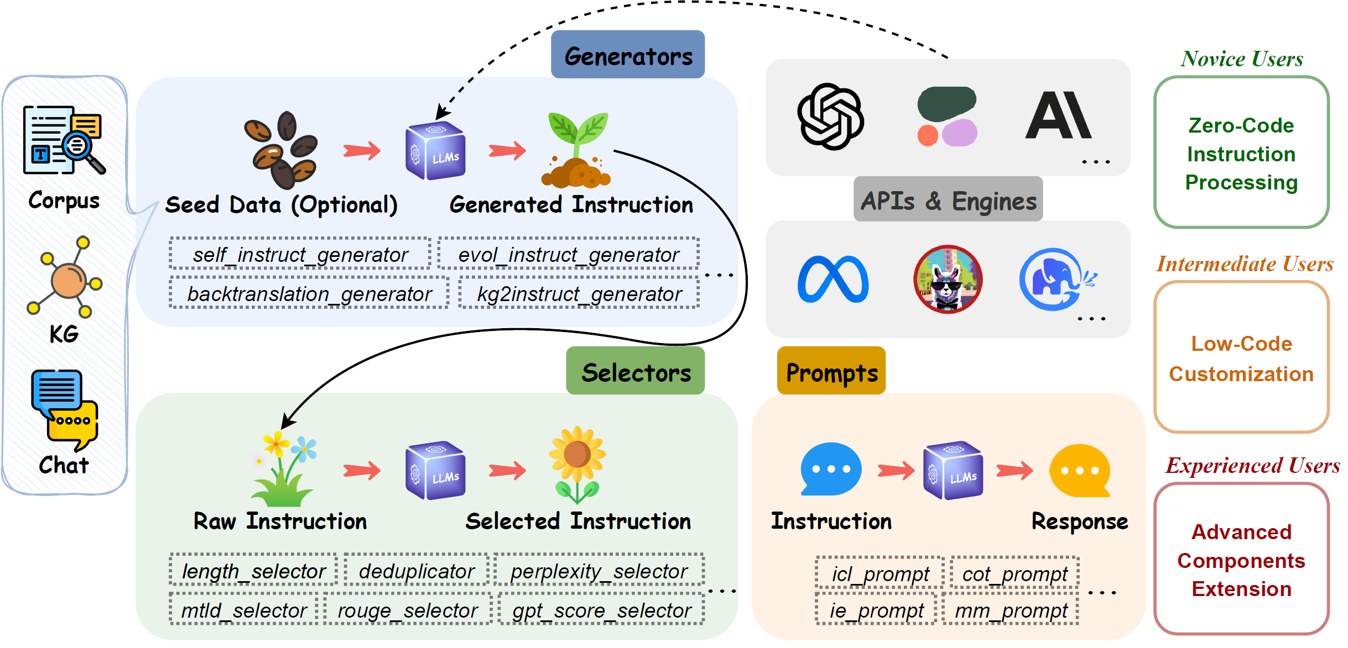
Die derzeit unterstützten Techniken zur Befehlsgenerierung sind wie folgt:
| Methoden | Beschreibung |
|---|---|
| Selbstunterricht | Die Methode, die zu Demonstrationszwecken zufällig einige Anweisungen aus einem von Menschen kommentierten Seed-Aufgabenpool auswählt und einen LLM dazu auffordert, weitere Anweisungen und entsprechende Eingabe-Ausgabe-Paare zu generieren. |
| Evol-Instruct | Die Methode, die einen anfänglichen Satz von Anweisungen schrittweise in komplexere Anweisungen aktualisiert, indem ein LLM mit bestimmten Eingabeaufforderungen aufgefordert wird. |
| Rückübersetzung | Die Methode, die eine Anweisung nach einer Trainingsinstanz erstellt, indem sie eine Anweisung vorhersagt, die von einem Teil eines Dokuments des Korpus korrekt beantwortet werden würde. |
| KG2Anweisen | Die Methode, die eine Anweisung nach einer Trainingsinstanz erstellt, indem sie eine Anweisung vorhersagt, die von einem Teil eines Dokuments des Korpus korrekt beantwortet werden würde. |
Die derzeit unterstützten Metriken für die Befehlsauswahl lauten wie folgt:
| Metriken | Notation | Beschreibung |
|---|---|---|
| Länge | Die begrenzte Länge jedes Paars aus Anweisung und Antwort. | |
| Verwirrung | Die potenzierte durchschnittliche negative logarithmische Antwortwahrscheinlichkeit. | |
| MTLD | Maß für die lexikalische Vielfalt im Text, die mittlere Länge aufeinanderfolgender Wörter in einem Text, der einen TTR-Mindestschwellenwert einhält. | |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation, eine Reihe von Metriken, die zur Bewertung von Ähnlichkeiten zwischen Sätzen verwendet werden. | |
| GPT-Score | Die von ChatGPT bereitgestellte Bewertung, ob die Ausgabe ein gutes Beispiel dafür ist, wie AI Assistant auf die Anweisungen des Benutzers reagieren soll. | |
| CIRS | Der Score verwendet den abstrakten Syntaxbaum, um strukturelle und logische Attribute zu kodieren und die Korrelation zwischen Code und Argumentationsfähigkeiten zu messen. |
Derzeit verfügbare API-Dienstleister und ihre entsprechenden LLM-Produkte:
| Modell | Beschreibung | Standardversion |
|---|---|---|
| OpenAI | ||
| GPT-3.5 | Eine Reihe von Modellen, die GPT-3 verbessern und natürliche Sprache oder Code verstehen und generieren können. | gpt-3.5-turbo |
| GPT-4 | Eine Reihe von Modellen, die GPT-3.5 verbessern und natürliche Sprache oder Code verstehen und generieren können. | gpt-4 |
| Anthropisch | ||
| Claude | Ein KI-Assistent der nächsten Generation, der auf der Forschung von Anthropic zum Trainieren hilfreicher, ehrlicher und harmloser KI-Systeme basiert. | claude-2.0 |
| Claude-Instant | Eine leichtere, kostengünstigere und viel schnellere Option als Claude. | claude-instant-1.2 |
| Zusammenhängen | ||
| Befehl | Ein Flaggschiff-Textgenerierungsmodell von Cohere, das darauf trainiert ist, Benutzerbefehlen zu folgen und in praktischen Geschäftsanwendungen sofort nützlich zu sein. | command |
| Kommandolicht | Eine abgespeckte Version von Command-Modellen, die schneller ist, aber möglicherweise qualitativ schlechter generierten Text erzeugt. | command-light |
Installation vom Git-Repo-Zweig:
pip install git+https://github.com/zjunlp/EasyInstruct@main
Installation für lokale Entwicklung:
git clone https://github.com/zjunlp/EasyInstruct
cd EasyInstruct
pip install -e .
Installation mit PyPI (nicht die neueste Version):
pip install easyinstruct -i https://pypi.org/simple
Wir bieten Benutzern zwei Möglichkeiten für den schnellen Einstieg in EasyInstruct. Sie können je nach Ihren spezifischen Anforderungen entweder das Shell-Skript oder die Gradio-App verwenden.
Benutzer können die Parameter von EasyInstruct einfach in einer Datei im YAML-Stil konfigurieren oder einfach schnell die Standardparameter in den von uns bereitgestellten Konfigurationsdateien verwenden. Im Folgenden finden Sie ein Beispiel für die Konfigurationsdatei für Self-Instruct:
generator :
SelfInstructGenerator :
target_dir : data/generations/
data_format : alpaca
seed_tasks_path : data/seed_tasks.jsonl
generated_instructions_path : generated_instructions.jsonl
generated_instances_path : generated_instances.jsonl
num_instructions_to_generate : 100
engine : gpt-3.5-turbo
num_prompt_instructions : 8Weitere Beispielkonfigurationsdateien finden Sie unter configs.
Benutzer sollten zunächst die Konfigurationsdatei angeben und ihren eigenen OpenAI-API-Schlüssel bereitstellen. Führen Sie dann das folgende Shell-Skript aus, um den Befehlsgenerierungs- oder -auswahlprozess zu starten.
config_file= " "
openai_api_key= " "
python demo/run.py
--config $config_file
--openai_api_key $openai_api_key Wir bieten Benutzern eine Gradio-App für den schnellen Einstieg in EasyInstruct. Sie können den folgenden Befehl ausführen, um die Gradio-App lokal auf dem Port 8080 zu starten (falls verfügbar).
python demo/app.pyWir hosten auch eine laufende Gradio-App in HuggingFace Spaces. Hier können Sie es ausprobieren.
Weitere Einzelheiten entnehmen Sie bitte unseren Dokumentationen.
Das Modul Generators rationalisiert den Prozess der Befehlsdatengenerierung und ermöglicht die Generierung von Befehlsdaten auf Basis von Seed-Daten. Sie können den passenden Generator entsprechend Ihren spezifischen Anforderungen auswählen.
BaseGeneratorist die Basisklasse für alle Generatoren.
Sie können diese Basisklasse auch problemlos erben, um Ihre eigene Generatorklasse anzupassen. Überschreiben Sie einfach die Methode
__init__undgenerate“.
SelfInstructGeneratorist die Klasse für die Befehlsgenerierungsmethode von Self-Instruct. Weitere Einzelheiten finden Sie unter Self-Instruct: Sprachmodell mit selbstgenerierten Anweisungen ausrichten.
Beispiel
from easyinstruct import SelfInstructGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = SelfInstructGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate self-instruct data
generator . generate ()
BacktranslationGeneratorist die Klasse für die Befehlsgenerierungsmethode der Befehlsrückübersetzung. Weitere Einzelheiten finden Sie unter Selbstausrichtung mit Anweisungsrückübersetzung.
from easyinstruct import BacktranslationGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = BacktranslationGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate backtranslation data
generator . generate ()
EvolInstructGeneratorist die Klasse für die Befehlsgenerierungsmethode von EvolInstruct. Weitere Einzelheiten finden Sie unter WizardLM: Große Sprachmodelle in die Lage versetzen, komplexen Anweisungen zu folgen.
from easyinstruct import EvolInstructGenerator
from easyinstruct . utils . api import set_openai_key
# Step1: Set your own API-KEY
set_openai_key ( "YOUR-KEY" )
# Step2: Declare a generator class
generator = EvolInstructGenerator ( num_instructions_to_generate = 10 )
# Step3: Generate evolution data
generator . generate ()
KG2InstructGeneratorist die Klasse für die Befehlsgenerierungsmethode von KG2Instruct. Weitere Einzelheiten finden Sie unter InstructIE: Ein auf chinesischen Anweisungen basierender Datensatz zur Informationsextraktion.
Das Selectors Modul standardisiert den Befehlsauswahlprozess und ermöglicht die Extraktion hochwertiger Befehlsdatensätze aus rohen, unverarbeiteten Befehlsdaten. Die Rohdaten können aus öffentlich verfügbaren Befehlsdatensätzen stammen oder vom Framework selbst generiert werden. Sie können den passenden Selektor entsprechend Ihren spezifischen Anforderungen auswählen.
BaseSelectorist die Basisklasse für alle Selektoren.
Sie können diese Basisklasse auch problemlos erben, um Ihre eigene Selektorklasse anzupassen. Überschreiben Sie einfach die Methoden
__init__und__process__.
Deduplicatorist die Klasse zur Eliminierung doppelter Befehlsbeispiele, die sich negativ auf die Stabilität vor dem Training und die Leistung von LLMs auswirken könnten.Deduplicatorermöglicht außerdem eine effiziente Nutzung und Optimierung des Speicherplatzes.
LengthSelectorist die Klasse zum Auswählen von Anweisungsbeispielen basierend auf der Länge der Anweisung. Zu lange oder zu kurze Anweisungen können die Datenqualität beeinträchtigen und sind nicht förderlich für die Befehlsoptimierung.
RougeSelectorist die Klasse zur Auswahl von Befehlsbeispielen basierend auf der ROUGE-Metrik, die häufig zur Bewertung der Qualität der automatisierten Textgenerierung verwendet wird.
GPTScoreSelectorist die Klasse zum Auswählen von Anweisungsbeispielen basierend auf dem GPT-Score, der widerspiegelt, ob die Ausgabe ein gutes Beispiel dafür ist, wie AI Assistant auf die von ChatGPT bereitgestellten Anweisungen des Benutzers reagieren soll.
PPLSelectorist die Klasse zum Auswählen von Befehlsbeispielen basierend auf der Perplexität, bei der es sich um die potenzierte durchschnittliche negative Log-Wahrscheinlichkeit einer Antwort handelt.
MTLDSelectorist die Klasse zum Auswählen von Befehlsbeispielen basierend auf MTLD, was für Measure of Textual Lexical Diversity steht.
CodeSelectorist die Klasse zur Auswahl von Codeanweisungsbeispielen basierend auf dem Complexity-Impacted Reasoning Score (CIRS), der strukturelle und logische Attribute kombiniert, um die Korrelation zwischen Code und Argumentationsfähigkeiten zu messen. Sehen Sie, wann das Gedankenprogramm zum Denken funktioniert? für weitere Details.
from easyinstruct import CodeSelector
# Step1: Specify your source file of code instructions
src_file = "data/code_example.json"
# Step2: Declare a code selecter class
selector = CodeSelector (
source_file_path = src_file ,
target_dir = "data/selections/" ,
manually_partion_data = True ,
min_boundary = 0.125 ,
max_boundary = 0.5 ,
automatically_partion_data = True ,
k_means_cluster_number = 2 ,
)
# Step3: Process the code instructions
selector . process ()
MultiSelectorist die Klasse zum Kombinieren mehrerer geeigneter Selektoren basierend auf Ihren spezifischen Anforderungen.
Das Prompts -Modul standardisiert den Schritt der Anweisungsaufforderung, bei dem Benutzeranfragen als Anweisungsaufforderungen erstellt und an bestimmte LLMs gesendet werden, um Antworten zu erhalten. Sie können die geeignete Aufforderungsmethode basierend auf Ihren spezifischen Anforderungen auswählen.
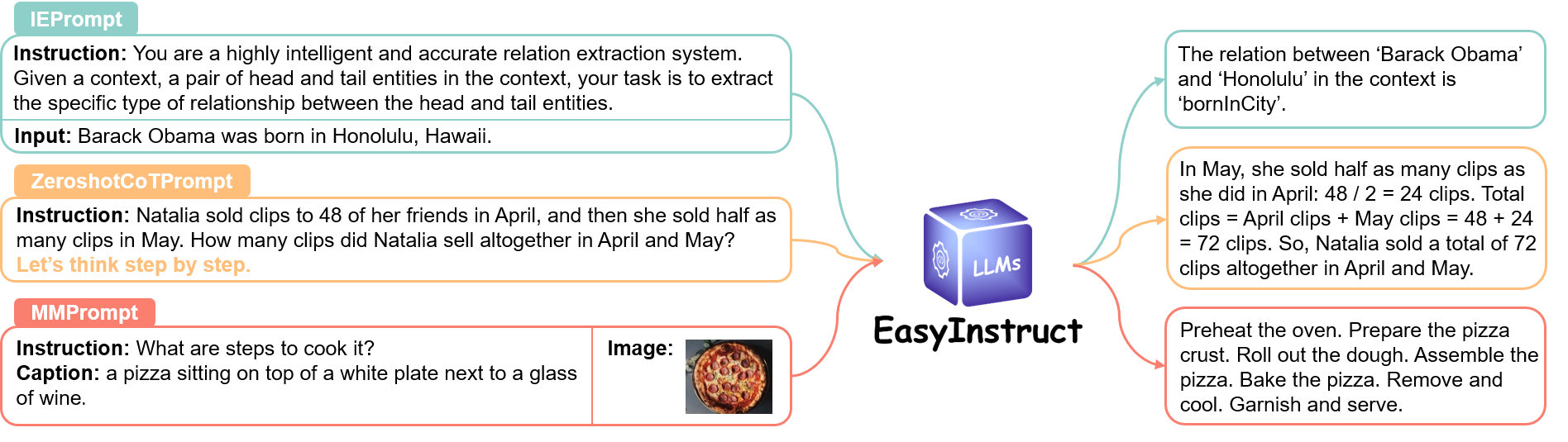
Weitere Informationen finden Sie unter dem Link.
Das Engines -Modul standardisiert den Befehlsausführungsprozess und ermöglicht die Ausführung von Befehlsaufforderungen auf bestimmten lokal bereitgestellten LLMs. Sie können den passenden Motor entsprechend Ihren spezifischen Anforderungen auswählen.
Weitere Informationen finden Sie unter dem Link.
Bitte zitieren Sie unser Repository, wenn Sie EasyInstruct in Ihrer Arbeit verwenden.
@article { ou2024easyinstruct ,
title = { EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models } ,
author = { Ou, Yixin and Zhang, Ningyu and Gui, Honghao and Xu, Ziwen and Qiao, Shuofei and Bi, Zhen and Chen, Huajun } ,
journal = { arXiv preprint arXiv:2402.03049 } ,
year = { 2024 }
}
@misc { knowlm ,
author = { Ningyu Zhang and Jintian Zhang and Xiaohan Wang and Honghao Gui and Kangwei Liu and Yinuo Jiang and Xiang Chen and Shengyu Mao and Shuofei Qiao and Yuqi Zhu and Zhen Bi and Jing Chen and Xiaozhuan Liang and Yixin Ou and Runnan Fang and Zekun Xi and Xin Xu and Lei Li and Peng Wang and Mengru Wang and Yunzhi Yao and Bozhong Tian and Yin Fang and Guozhou Zheng and Huajun Chen } ,
title = { KnowLM: An Open-sourced Knowledgeable Large Langugae Model Framework } ,
year = { 2023 } ,
url = { http://knowlm.zjukg.cn/ } ,
}
@article { bi2023program ,
title = { When do program-of-thoughts work for reasoning? } ,
author = { Bi, Zhen and Zhang, Ningyu and Jiang, Yinuo and Deng, Shumin and Zheng, Guozhou and Chen, Huajun } ,
journal = { arXiv preprint arXiv:2308.15452 } ,
year = { 2023 }
}Wir bieten eine langfristige Wartung an, um Fehler zu beheben, Probleme zu lösen und neue Anforderungen zu erfüllen. Wenn Sie also Probleme haben, wenden Sie sich bitte an uns.
Andere verwandte Projekte
? Wir möchten uns herzlich für den Beitrag von Self-Instruct zu unserem Projekt bedanken, da wir Teile ihres Quellcodes in unserem Projekt verwendet haben.


