DiGIT
1.0.0
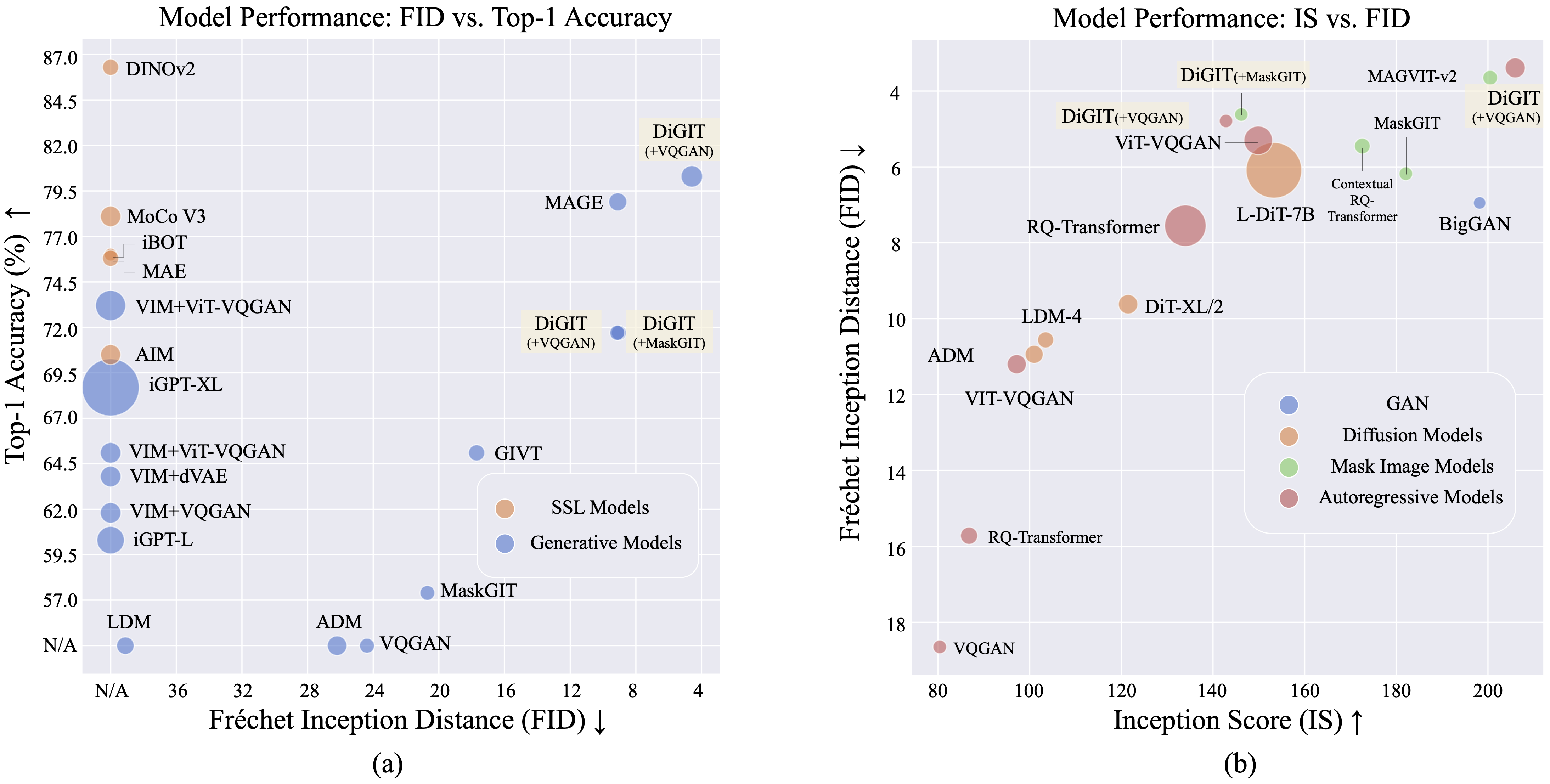
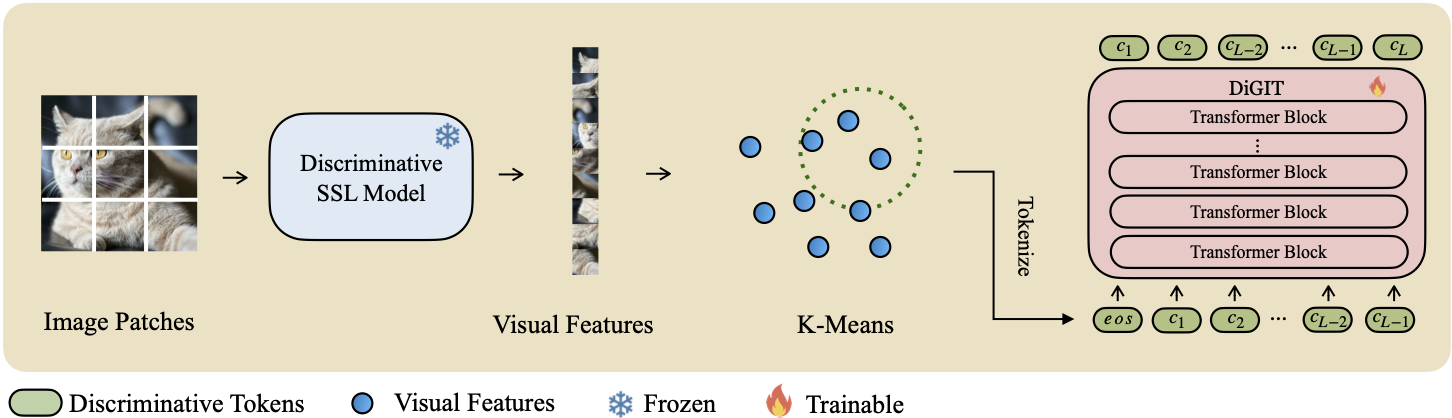
Wir präsentieren DiGIT , ein autoregressives generatives Modell, das eine Next-Token-Vorhersage in einem abstrakten latenten Raum durchführt, der aus selbstüberwachten Lernmodellen (SSL) abgeleitet ist. Indem wir K-Means-Clustering auf die verborgenen Zustände des DINOv2-Modells anwenden, erstellen wir effektiv einen neuartigen diskreten Tokenizer. Diese Methode steigert die Bildgenerierungsleistung im ImageNet-Datensatz erheblich und erreicht einen FID-Score von 4,59 für klassenbedingte Aufgaben und 3,39 für klassenbedingte Aufgaben . Darüber hinaus verbessert das Modell das Bildverständnis und erreicht eine lineare Sondengenauigkeit von 80,3 .
| Methoden | # Token | Merkmale | # Parameter | Top-1 Acc. |
|---|---|---|---|---|
| iGPT-L | 32 | 1536 | 1362M | 60.3 |
| iGPT-XL | 64 | 3072 | 6801M | 68,7 |
| VIM+VQGAN | 32 | 1024 | 650M | 61,8 |
| VIM+dVAE | 32 | 1024 | 650M | 63,8 |
| VIM+ViT-VQGAN | 32 | 1024 | 650M | 65.1 |
| VIM+ViT-VQGAN | 32 | 2048 | 1697M | 73,2 |
| ZIEL | 16 | 1536 | 0,6B | 70,5 |
| DiGIT (unser) | 16 | 1024 | 219M | 71,7 |
| DiGIT (unser) | 16 | 1536 | 732M | 80,3 |
| Typ | Methoden | # Param | # Epoche | FID | IST |
|---|---|---|---|---|---|
| GAN | BigGAN | 70M | - | 38.6 | 24.70 |
| Diff. | LDM | 395M | - | 39.1 | 22.83 |
| Diff. | ADM | 554M | - | 26.2 | 39,70 |
| MIM | MAGIER | 200M | 1600 | 11.1 | 81.17 |
| MIM | MAGIER | 463M | 1600 | 9.10 | 105.1 |
| MIM | MaskGIT | 227M | 300 | 20.7 | 42.08 |
| MIM | DiGIT (+MaskGIT) | 219M | 200 | 9.04 | 75.04 |
| AR | VQGAN | 214M | 200 | 24.38 | 30.93 |
| AR | Ziffer (+VQGAN) | 219M | 400 | 9.13 | 73,85 |
| AR | Ziffer (+VQGAN) | 732M | 200 | 4.59 | 141,29 |
| Typ | Methoden | # Param | # Epoche | FID | IST |
|---|---|---|---|---|---|
| GAN | BigGAN | 160M | - | 6,95 | 198.2 |
| Diff. | ADM | 554M | - | 10.94 | 101,0 |
| Diff. | LDM-4 | 400M | - | 10.56 | 103,5 |
| Diff. | DiT-XL/2 | 675M | - | 9.62 | 121,50 |
| Diff. | L-DiT-7B | 7B | - | 6.09 | 153,32 |
| MIM | CQR-Trans | 371M | 300 | 5.45 | 172,6 |
| MIM+AR | VAR | 310M | 200 | 4,64 | - |
| MIM+AR | VAR | 310M | 200 | 3,60* | 257,5* |
| MIM+AR | VAR | 600M | 250 | 2,95* | 306,1* |
| MIM | MAGVIT-v2 | 307M | 1080 | 3,65 | 200,5 |
| AR | VQVAE-2 | 13,5B | - | 31.11 | 45 |
| AR | RQ-Trans | 480M | - | 15.72 | 86,8 |
| AR | RQ-Trans | 3,8B | - | 7.55 | 134,0 |
| AR | ViTVQGAN | 650M | 360 | 11.20 | 97,2 |
| AR | ViTVQGAN | 1,7B | 360 | 5.3 | 149,9 |
| MIM | MaskGIT | 227M | 300 | 6.18 | 182.1 |
| MIM | DiGIT (+MaskGIT) | 219M | 200 | 4,62 | 146,19 |
| AR | VQGAN | 227M | 300 | 18.65 | 80,4 |
| AR | Ziffer (+VQGAN) | 219M | 400 | 4,79 | 142,87 |
| AR | Ziffer (+VQGAN) | 732M | 200 | 3.39 | 205,96 |
*: VAR wird mit klassifikatorfreier Anleitung trainiert, alle anderen Modelle jedoch nicht.
Die K-Means NPY-Datei und die Modellprüfpunkte können heruntergeladen werden von:
| Modell | Link |
|---|---|
| HF-Gewichte? | Umarmendes Gesicht |
Für das Basismodell verwenden wir DINOv2-base und DINOv2-large für das große Modell. Das von uns verwendete VQGAN ist das gleiche wie MAGE.
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITfairseq über pip install fairseq . Laden Sie den ImageNet-Datensatz herunter und platzieren Sie ihn in Ihrem Datensatzverzeichnis $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012 .
Extrahieren Sie SSL-Funktionen und speichern Sie sie als .npy-Dateien. Verwenden Sie den K-Means-Algorithmus mit Faiss, um die Schwerpunkte zu berechnen. Sie können auch unsere vorab trainierten Schwerpunkte nutzen, die auf Huggingface verfügbar sind.
bash preprocess/run.shSchritt 1
Trainieren Sie ein GPT-Modell mit einem diskriminierenden Tokenizer. Sie finden die Trainingsskripte in scripts/train_stage1_ar.sh und die Hyperparams in config/stage1/dino_base.yaml . Informationen zur Konfiguration der klassenbedingten Generierung finden Sie scripts/train_stage1_classcond.sh .
Schritt 2
Trainieren Sie einen Pixeldecoder (entweder AR-Modell oder NAR-Modell), abhängig von den Unterscheidungstoken. Sie finden die autoregressiven Trainingsskripte in scripts/train_stage2_ar.sh und die NAR-Trainingsskripte in scripts/train_stage2_nar.sh .
Zum Speichern der Prüfpunkte wird ein Ordner mit dem Namen outputs/EXP_NAME/checkpoints erstellt. TensorBoard-Protokolldateien werden unter outputs/EXP_NAME/tb gespeichert. Protokolle werden in outputs/EXP_NAME/train.log aufgezeichnet.
Sie können den Trainingsprozess mit tensorboard --logdir=outputs/EXP_NAME/tb überwachen.
Erste Stichprobe diskriminierender Token mit scripts/infer_stage1_ar.sh . Für die Basismodellgröße empfehlen wir die Einstellung topk=200 und für eine große Modellgröße topk=400.
Führen Sie dann scripts/infer_stage2_ar.sh aus, um VQ-Tokens basierend auf den zuvor abgetasteten Unterscheidungstokens abzutasten.
Generierte Token und synthetisierte Bilder werden in einem Verzeichnis namens outputs/EXP_NAME/results gespeichert.
Bereiten Sie den ImageNet-Validierungssatz für die FID-Bewertung vor:
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val Installieren Sie das Evaluierungstool, indem Sie pip install torch-fidelity ausführen.
Führen Sie den folgenden Befehl aus, um FID auszuwerten:
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shDieses Projekt ist unter der MIT-Lizenz lizenziert – Einzelheiten finden Sie in der LIZENZ-Datei.
Wenn Sie unser Projekt nützlich finden, hoffen Sie, dass Sie unser Repo markieren und unsere Arbeit wie folgt zitieren können.
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

