FasterTransformer
v5.3 release
Hinweis: Die FasterTransformer-Entwicklung wurde auf TensorRT-LLM umgestellt. Alle Entwickler werden ermutigt, TensorRT-LLM zu nutzen, um die neuesten Verbesserungen von LLM Inference zu erhalten. Das NVIDIA/FasterTransformer-Repo bleibt bestehen, wird jedoch nicht weiterentwickelt.
Dieses Repository bietet ein Skript und ein Rezept zum Ausführen der hochoptimierten transformatorbasierten Encoder- und Decoder-Komponente und wird von NVIDIA getestet und gewartet.
Im NLP sind Encoder und Decoder zwei wichtige Komponenten, wobei die Transformatorschicht zu einer beliebten Architektur für beide Komponenten geworden ist. FasterTransformer implementiert eine hochoptimierte Transformatorschicht sowohl für den Encoder als auch für den Decoder zur Inferenz. Auf Volta-, Turing- und Ampere-GPUs wird die Rechenleistung von Tensor-Kernen automatisch genutzt, wenn die Genauigkeit der Daten und Gewichte FP16 beträgt.
FasterTransformer basiert auf CUDA, cuBLAS, cuBLASLt und C++. Wir stellen mindestens eine API der folgenden Frameworks bereit: TensorFlow, PyTorch und Triton-Backend. Benutzer können FasterTransformer direkt in diese Frameworks integrieren. Für unterstützende Frameworks stellen wir auch Beispielcodes zur Verfügung, um die Verwendung zu demonstrieren und die Leistung dieser Frameworks zu zeigen.
| Modelle | Rahmen | FP16 | INT8 (nach Turing) | Sparsity (nach Ampere) | Tensorparallel | Parallele Pipeline | FP8 (nach Hopper) |
|---|---|---|---|---|---|---|---|
| BERT | TensorFlow | Ja | Ja | - | - | - | - |
| BERT | PyTorch | Ja | Ja | Ja | Ja | Ja | - |
| BERT | Triton-Backend | Ja | - | - | Ja | Ja | - |
| BERT | C++ | Ja | Ja | - | - | - | Ja |
| XLNet | C++ | Ja | - | - | - | - | - |
| Encoder | TensorFlow | Ja | Ja | - | - | - | - |
| Encoder | PyTorch | Ja | Ja | Ja | - | - | - |
| Decoder | TensorFlow | Ja | - | - | - | - | - |
| Decoder | PyTorch | Ja | - | - | - | - | - |
| Dekodierung | TensorFlow | Ja | - | - | - | - | - |
| Dekodierung | PyTorch | Ja | - | - | - | - | - |
| GPT | TensorFlow | Ja | - | - | - | - | - |
| GPT/OPT | PyTorch | Ja | - | - | Ja | Ja | Ja |
| GPT/OPT | Triton-Backend | Ja | - | - | Ja | Ja | - |
| GPT-MoE | PyTorch | Ja | - | - | Ja | Ja | - |
| BLÜHEN | PyTorch | Ja | - | - | Ja | Ja | - |
| BLÜHEN | Triton-Backend | Ja | - | - | Ja | Ja | - |
| GPT-J | Triton-Backend | Ja | - | - | Ja | Ja | - |
| Langformer | PyTorch | Ja | - | - | - | - | - |
| T5/UL2 | PyTorch | Ja | - | - | Ja | Ja | - |
| T5 | TensorFlow 2 | Ja | - | - | - | - | - |
| T5/UL2 | Triton-Backend | Ja | - | - | Ja | Ja | - |
| T5 | TensorRT | Ja | - | - | Ja | Ja | - |
| T5-MoE | PyTorch | Ja | - | - | Ja | Ja | - |
| Swin-Transformator | PyTorch | Ja | Ja | - | - | - | - |
| Swin-Transformator | TensorRT | Ja | Ja | - | - | - | - |
| ViT | PyTorch | Ja | Ja | - | - | - | - |
| ViT | TensorRT | Ja | Ja | - | - | - | - |
| GPT-NeoX | PyTorch | Ja | - | - | Ja | Ja | - |
| GPT-NeoX | Triton-Backend | Ja | - | - | Ja | Ja | - |
| BART/mBART | PyTorch | Ja | - | - | Ja | Ja | - |
| WeNet | C++ | Ja | - | - | - | - | - |
| DeBERTa | TensorFlow 2 | Ja | - | - | Laufend | Laufend | - |
| DeBERTa | PyTorch | Ja | - | - | Laufend | Laufend | - |
Weitere Details zu bestimmten Modellen finden Sie in xxx_guide.md von docs/ , wobei xxx für den Modellnamen steht. Einige häufig gestellte Fragen und die entsprechenden Antworten finden Sie in docs/QAList.md . Beachten Sie, dass die Modelle von Encoder und BERT ähnlich sind und wir die Erklärung zusammen in bert_guide.md einfügen.
Der folgende Code listet die Verzeichnisstruktur von FasterTransformer auf:
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
Beachten Sie, dass viele Ordner viele Unterordner enthalten, um verschiedene Modelle aufzuteilen. Quantisierungswerkzeuge werden in examples verschoben, z. B. examples/tensorflow/bert/bert-quantization/ und examples/pytorch/bert/bert-quantization-sparsity/ .
FasterTransformer bietet einige praktische Umgebungsvariablen zum Debuggen und Testen.
FT_LOG_LEVEL : Diese Umgebung steuert die Protokollebene von Debug-Meldungen. Weitere Details finden Sie in src/fastertransformer/utils/logger.h . Beachten Sie, dass das Programm viele Meldungen ausgibt, wenn die Stufe niedriger als DEBUG ist und das Programm dadurch sehr langsam wird.FT_NVTX : Wenn es wie FT_NVTX=ON ./bin/gpt_example auf ON gesetzt ist, fügt das Programm das Tag von nvtx ein, um die Profilierung des Programms zu unterstützen.FT_DEBUG_LEVEL : Wenn DEBUG eingestellt ist, führt das Programm nach jedem Kernel cudaDeviceSynchronize() aus. Andernfalls wird der Kernel standardmäßig asynchron ausgeführt. Es ist hilfreich, den Fehlerpunkt während des Debuggens zu lokalisieren. Dieses Flag wirkt sich jedoch erheblich auf die Leistung des Programms aus. Daher sollte es nur zum Debuggen verwendet werden. Hardwareeinstellungen:
Um den folgenden Benchmark ausführen zu können, müssen wir das Unix-Computing-Tool „bc“ installieren
apt-get install bc Die FP16-Ergebnisse von TensorFlow wurden durch Ausführen von benchmarks/bert/tf_benchmark.sh erhalten.
Die INT8-Ergebnisse von TensorFlow wurden durch Ausführen von benchmarks/bert/tf_int8_benchmark.sh erhalten.
Die FP16-Ergebnisse von PyTorch wurden durch Ausführen von benchmarks/bert/pyt_benchmark.sh erhalten.
Die INT8-Ergebnisse von PyTorch wurden durch Ausführen von benchmarks/bert/pyt_int8_benchmark.sh erhalten.
Weitere Benchmarks finden Sie in docs/bert_guide.md .
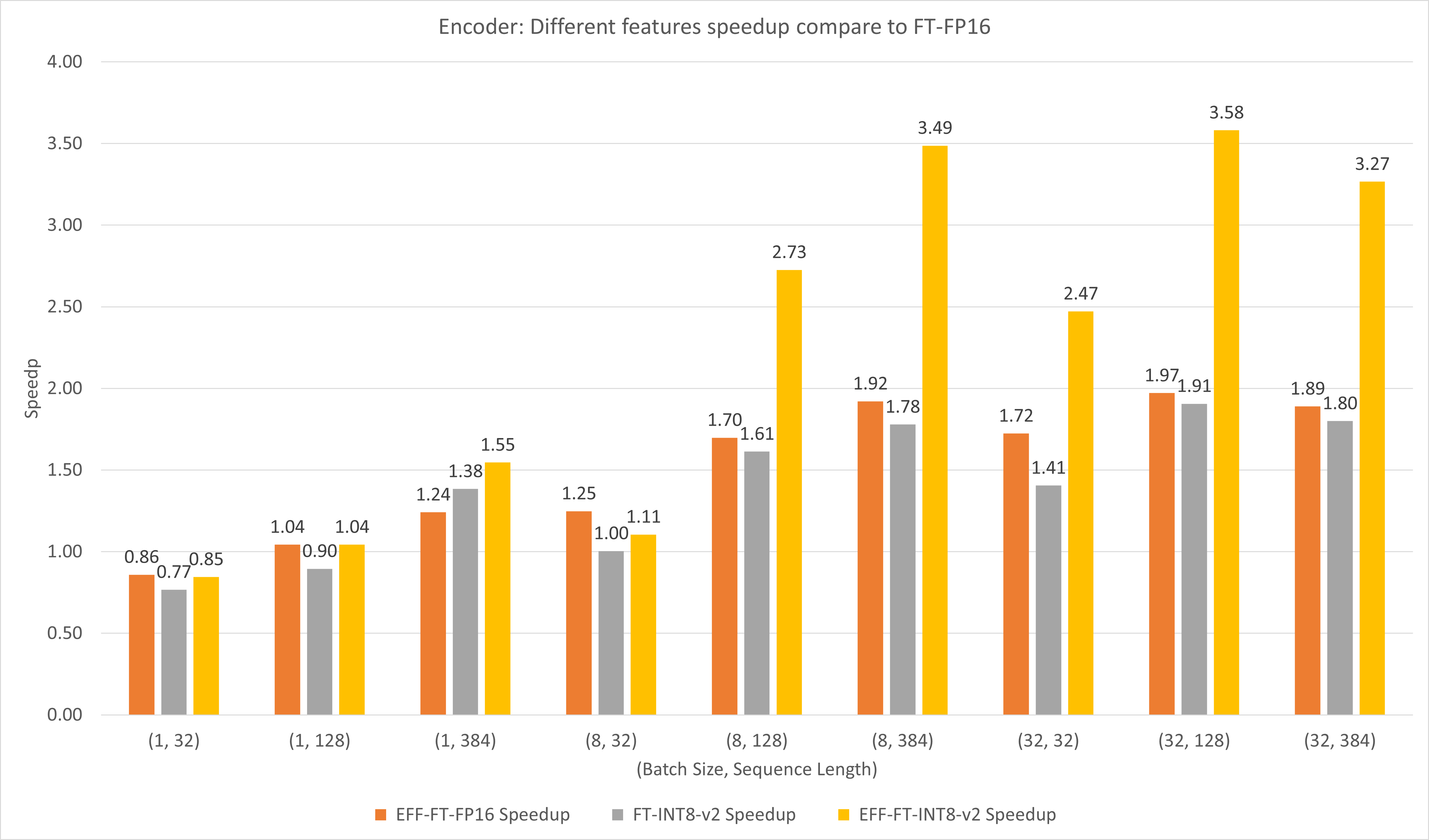
Die folgende Abbildung vergleicht die Leistung verschiedener Funktionen von FasterTransformer und FasterTransformer unter FP16 auf T4.
Bei großen Batchgrößen und Sequenzlängen bewirken sowohl EFF-FT als auch FT-INT8-v2 eine etwa zweifache Beschleunigung. Die gleichzeitige Verwendung von Effective FasterTransformer und int8v2 kann bei großen Fällen zu einer etwa 3,5-fachen Beschleunigung im Vergleich zu FasterTransformer FP16 führen.
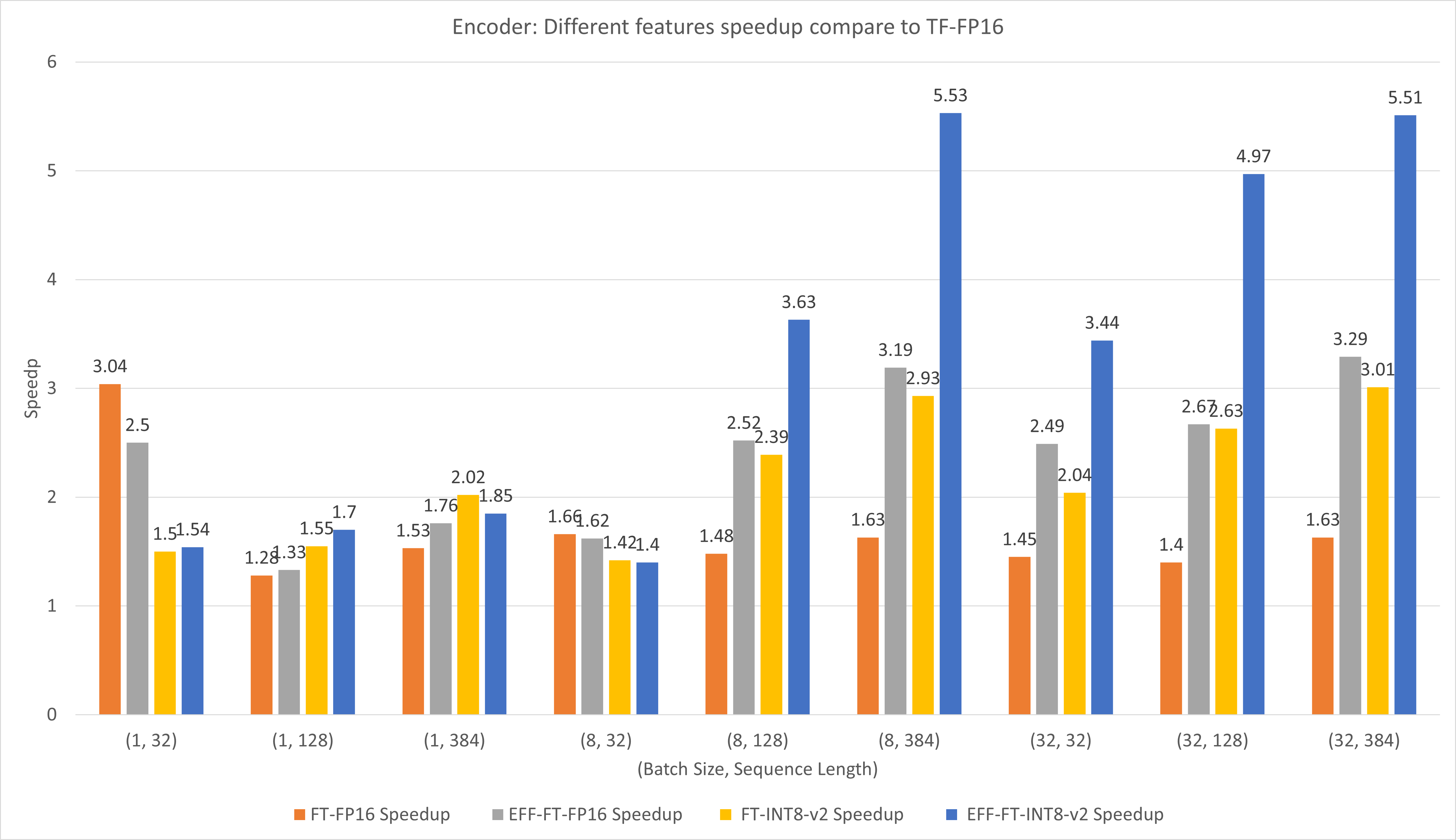
Die folgende Abbildung vergleicht die Leistungen verschiedener Funktionen von FasterTransformer und TensorFlow XLA unter FP16 auf T4.
Bei kleinen Batchgrößen und Sequenzlängen kann die Verwendung von FasterTransformer eine etwa dreifache Geschwindigkeitssteigerung bewirken.
Bei großen Batchgrößen und Sequenzlängen kann die Verwendung von Effective FasterTransformer mit INT8-v2-Quantisierung eine etwa fünffache Beschleunigung bewirken.
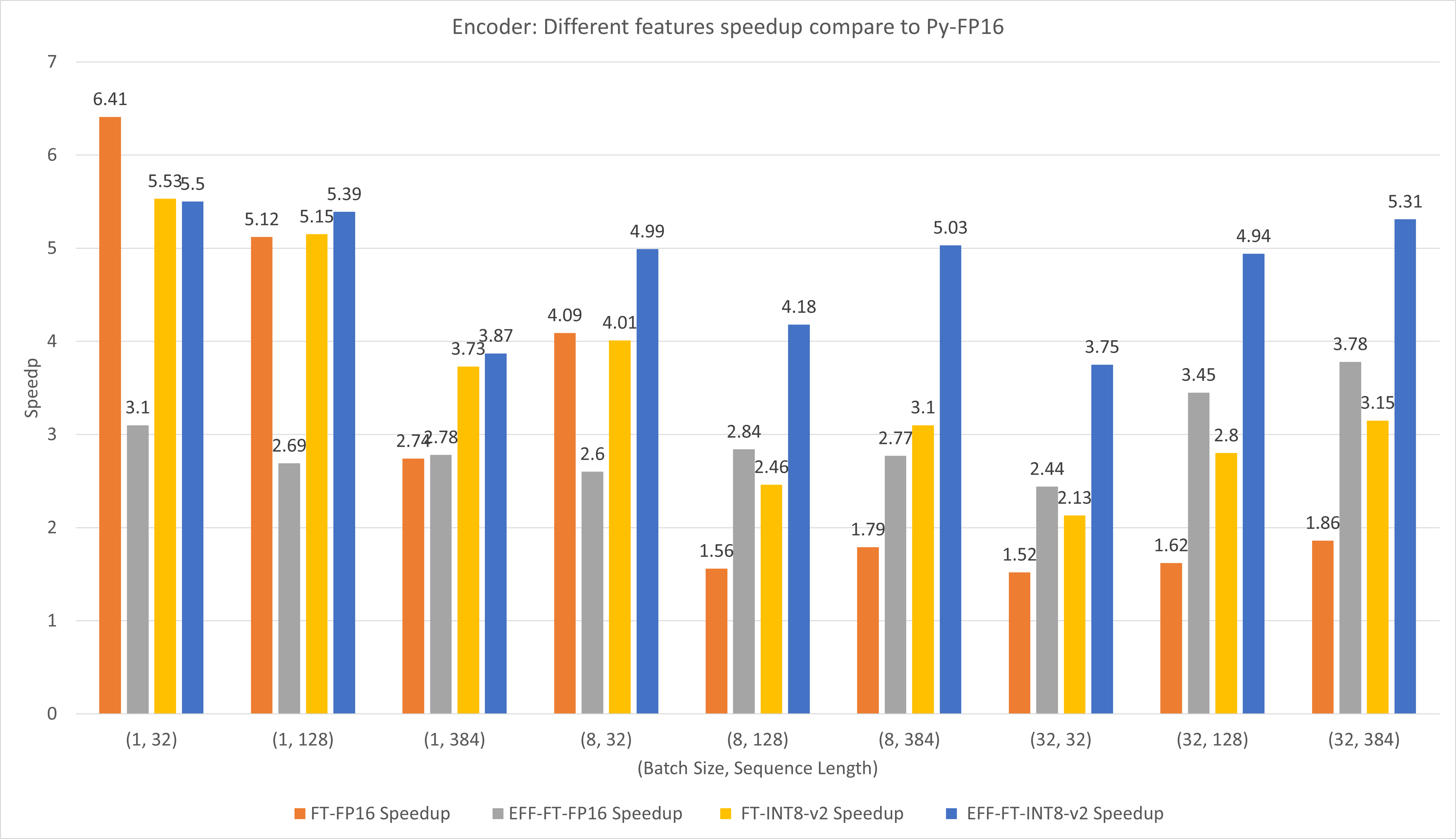
Die folgende Abbildung vergleicht die Leistung verschiedener Funktionen von FasterTransformer und PyTorch TorchScript unter FP16 auf T4.
Bei kleinen Batchgrößen und Sequenzlängen kann die Verwendung von FasterTransformer CustomExt eine etwa 4- bis 6-fache Beschleunigung bewirken.
Bei großen Batchgrößen und Sequenzlängen kann die Verwendung von Effective FasterTransformer mit INT8-v2-Quantisierung eine etwa fünffache Beschleunigung bewirken.
Die Ergebnisse von TensorFlow wurden durch Ausführen von benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh und benchmarks/decoding/tf_decoding_sampling_benchmark.sh erhalten
Die Ergebnisse von PyTorch wurden durch Ausführen von benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh erhalten.
In den Dekodierungsexperimenten haben wir die folgenden Parameter aktualisiert:
Weitere Benchmarks finden Sie in docs/decoder_guide.md .
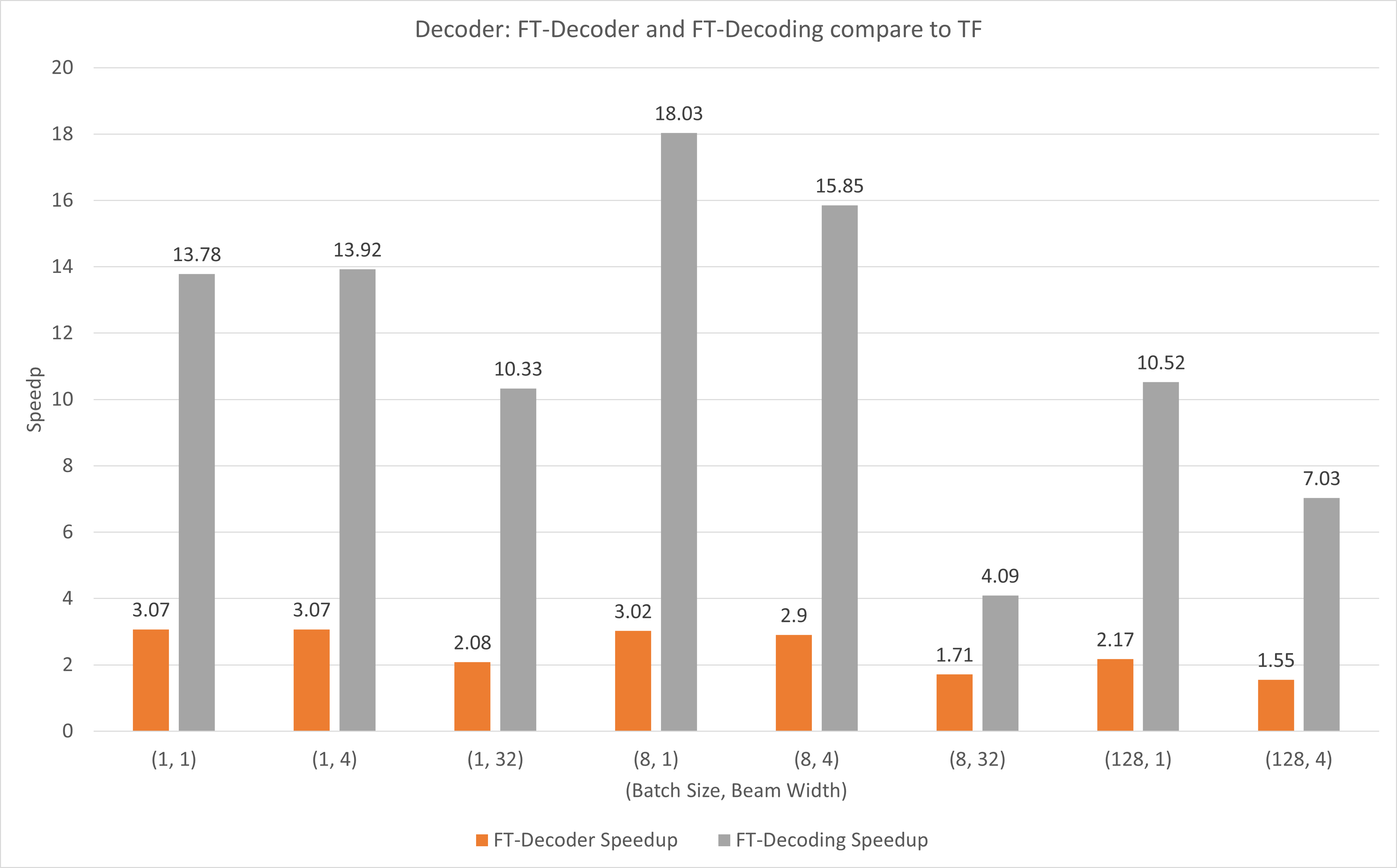
Die folgende Abbildung zeigt die Beschleunigung von FT-Decoder op und FT-Decoding op im Vergleich zu TensorFlow unter FP16 mit T4. Hier nutzen wir den Durchsatz der Übersetzung eines Testsatzes, um zu verhindern, dass die Gesamttokens der einzelnen Methoden unterschiedlich sein können. Im Vergleich zu TensorFlow bietet FT-Decoder eine 1,5- bis 3-fache Beschleunigung; während die FT-Dekodierung eine 4- bis 18-fache Beschleunigung bietet.
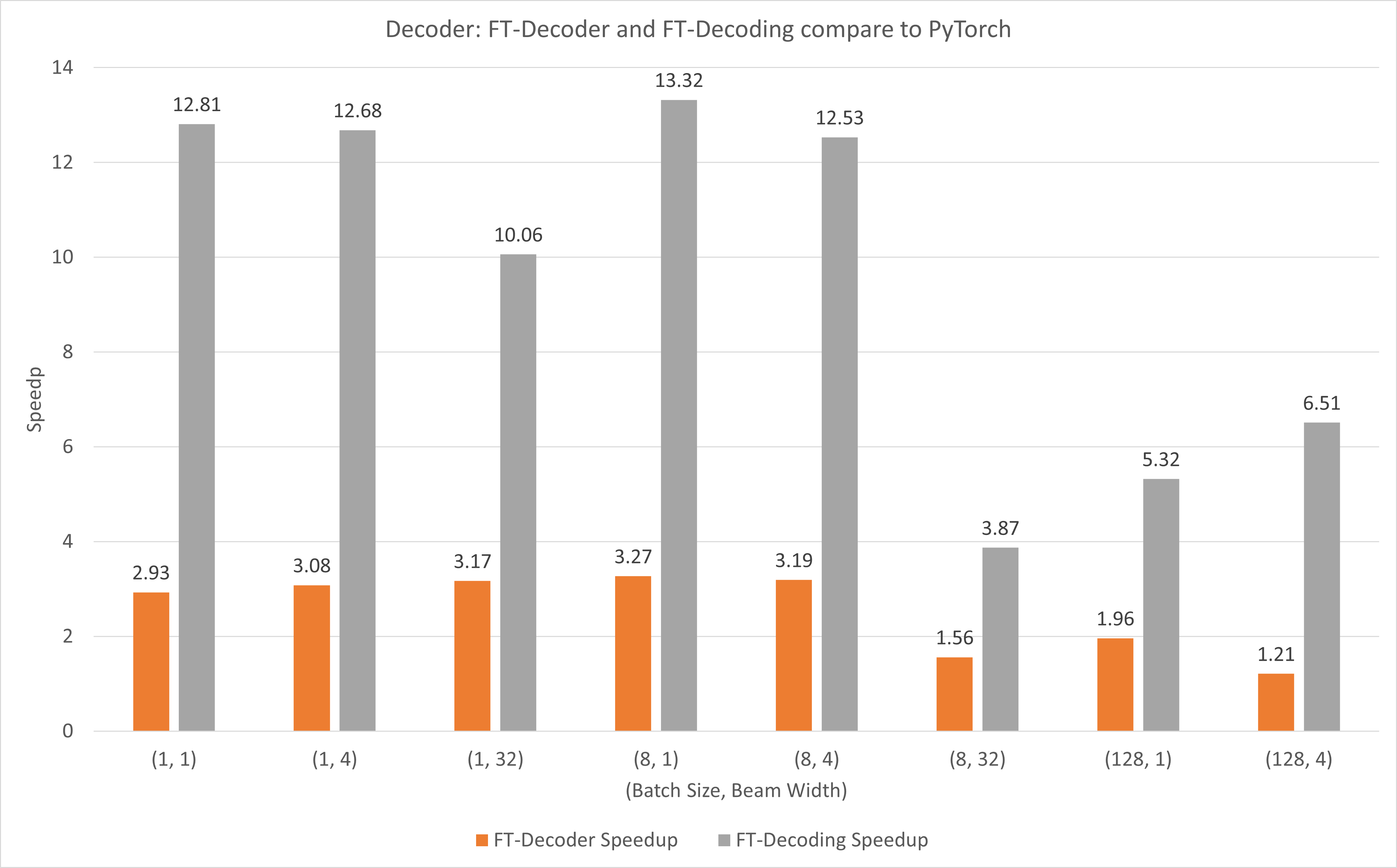
Die folgende Abbildung zeigt die Beschleunigung von FT-Decoder op und FT-Decoding op im Vergleich zu PyTorch unter FP16 mit T4. Hier nutzen wir den Durchsatz der Übersetzung eines Testsatzes, um zu verhindern, dass die Gesamttokens der einzelnen Methoden unterschiedlich sein können. Im Vergleich zu PyTorch bietet FT-Decoder eine 1,2- bis 3-fache Beschleunigung; während die FT-Dekodierung eine 3,8- bis 13-fache Beschleunigung bietet.
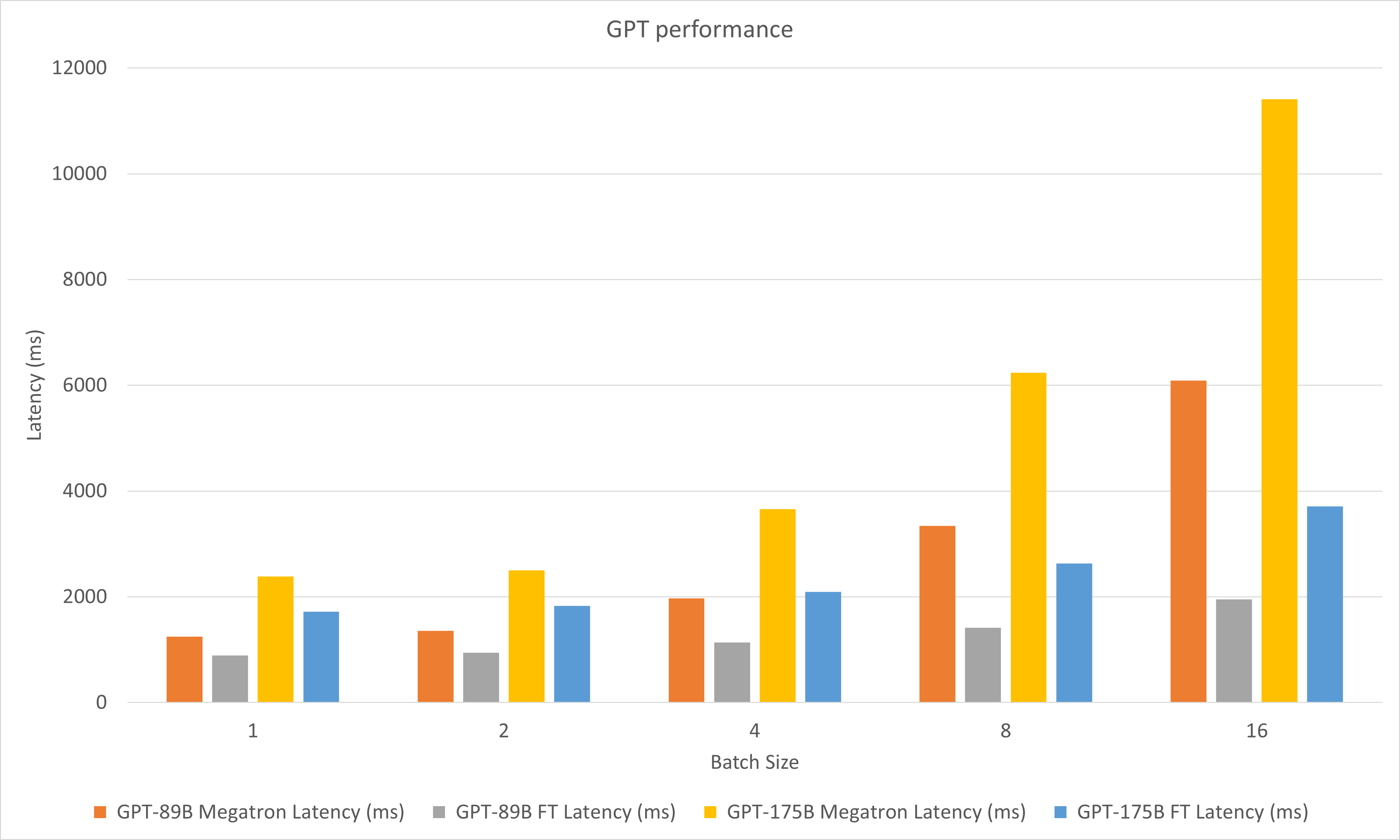
Die folgende Abbildung vergleicht die Leistungen von Megatron und FasterTransformer unter FP16 auf A100.
In den Dekodierungsexperimenten haben wir die folgenden Parameter aktualisiert:
Mai 2023
Januar 2023
Dez. 2022
November 2022
Okt. 2022
September 2022
August 2022
Juli 2022
Juni 2022
Mai 2022
April 2022
März 2022
stop_ids und ban_bad_ids in GPT-J.start_id und end_id in GPT-J, GPT, T5 und Decoding.Februar 2022
Dezember 2021
November 2021
August 2021
layer_para in pipeline_para .size_per_head 96, 160, 192, 224, 256 für das GPT-Modell.Juni 2021
April 2021
Dezember 2020
November 2020
September 2020
August 2020
Juni 2020
Mai 2020
translate_sample.py .April 2020
decoding_opennmt.h in decoding_beamsearch.hdecoding_sampling.hbert_transformer_op.h und bert_transformer_op.cu.cc in bert_transformer_op.cc zusammendecoder.h und decoder.cu.cc in decoder.cc zusammendecoding_beamsearch.h und decoding_beamsearch.cu.cc in decoding_beamsearch.cc zusammenbleu_score.py zu utils hinzu. Beachten Sie, dass für den BLEU-Score Python3 erforderlich ist.März 2020
translate_sample.py hinzu, um zu demonstrieren, wie ein Satz durch Wiederherstellen des vorab trainierten Modells von OpenNMT-tf übersetzt wird.Februar 2020
Juli 2019
import torch . Wenn dies geschehen ist, liegt es an der inkompatiblen C++-ABI. Möglicherweise müssen Sie überprüfen, ob der während der Kompilierung und Ausführung verwendete PyTorch identisch ist, oder Sie müssen überprüfen, wie Ihr PyTorch kompiliert ist, oder die Version Ihres GCC usw.

