PatrickStar
v0.4.6

Siehe CHANGE_LOG.md.
Pre-Trained Models (PTM) werden zum Hotspot sowohl der NLP-Forschung als auch der Industrieanwendung. Allerdings erfordert das Training von PTMs enorme Hardware-Ressourcen, sodass es nur einem kleinen Teil der Menschen in der KI-Community zugänglich ist. Jetzt macht PatrickStar das PTM-Training für jedermann zugänglich!
Out-of-Memory-Fehler (OOM) sind der Albtraum jedes Ingenieurs, der PTMs ausbildet. Um solche Fehler zu verhindern, müssen wir oft mehr GPUs zum Speichern der Modellparameter einführen. PatrickStar bietet eine bessere Lösung für dieses Problem. Mit dem heterogenen Training (DeepSpeed Zero Stage 3 nutzt es auch) könnte PatrickStar sowohl den CPU- als auch den GPU-Speicher vollständig nutzen, sodass Sie weniger GPUs zum Trainieren größerer Modelle verwenden könnten.
Die Idee von Patrick ist so. Die Nicht-Modelldaten (hauptsächlich Aktivierungen) variieren während des Trainings, aber die aktuellen heterogenen Trainingslösungen teilen die Modelldaten statisch auf CPU und GPU auf. Um die GPU besser zu nutzen, schlägt PatrickStar eine dynamische Speicherplanung mit Hilfe eines Chunk-basierten Speicherverwaltungsmoduls vor. Die Speicherverwaltung von PatrickStar unterstützt die Auslagerung aller Daten außer dem aktuellen Rechenteil des Modells auf die CPU, um GPU zu sparen. Darüber hinaus ist die Chunk-basierte Speicherverwaltung für die kollektive Kommunikation bei der Skalierung auf mehrere GPUs effizient. Sehen Sie sich das Papier und dieses Dokument für die Idee hinter PatrickStar an.
Im Experiment ist Patrickstar v0.4.3 in der Lage, ein 18 Milliarden (18B) Parametermodell mit 8xTesla V100 GPU und 240 GB GPU-Speicher im WeChat-Rechenzentrumsknoten zu trainieren, dessen Netzwerktopologie wie folgt aussieht. PatrickStar ist mehr als doppelt so groß wie DeepSpeed. Und auch bei Modellen gleicher Größe ist die Leistung von PatrickStar besser. Der Pstar ist PatrickStar v0.4.3. Die Tiefen zeigen die Leistung von DeepSpeed v0.4.3 anhand des offiziellen DeepSpeed-Beispiels Zero3 Stage mit standardmäßig geöffneten Aktivierungsoptimierungen an.

Wir haben PatrickStar v0.4.3 auch auf einem einzelnen Knoten des A100 SuperPod evaluiert. Es kann 68B-Modelle auf 8xA100 mit 1 TB CPU-Speicher trainieren, was über 6x größer ist als DeepSpeed v0.5.7. Abgesehen vom Modellmaßstab ist PatrickStar viel effizienter als DeepSpeed. Die Benchmark-Skripte finden Sie hier.

Detaillierte Benchmark-Ergebnisse zum WeChat AI-Rechenzentrum und NVIDIA SuperPod werden in diesem Google-Dokument veröffentlicht.
Skalieren Sie PatrickStar auf mehreren Maschinen (Knoten) auf SuperPod. Es gelingt uns, einen GPT3-175B auf 32 GPUs zu trainieren. Soweit wir wissen, ist es das erste Werk, GPT3 auf einem so kleinen GPU-Cluster auszuführen. Microsoft hat 10.000 V100 für GPT3 verwendet. Jetzt können Sie es verfeinern oder sogar Ihr eigenes Gerät auf einer 32 A100-GPU vortrainieren, großartig!

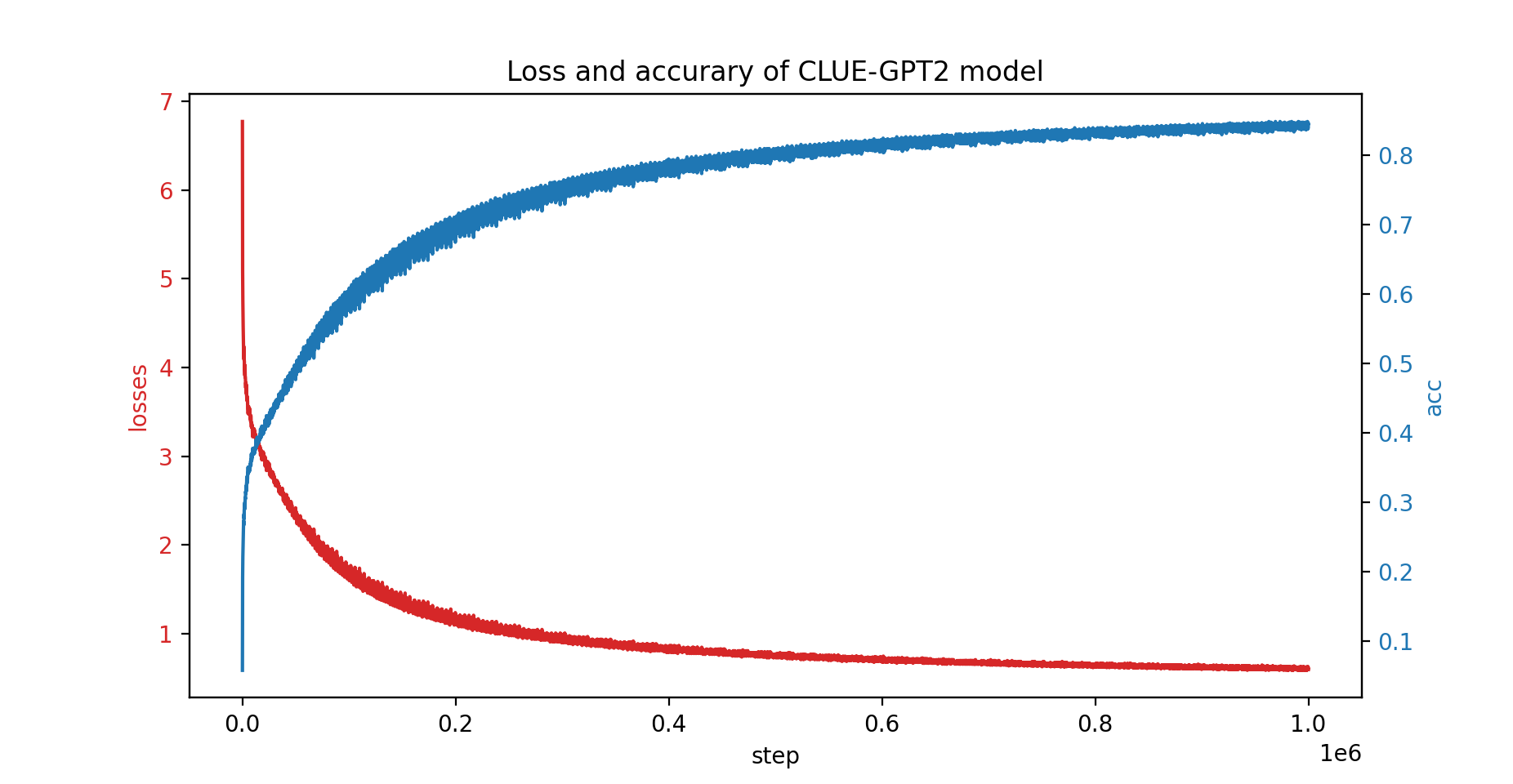
Wir haben auch das CLUE-GPT2-Modell mit PatrickStar trainiert. Die Verlust- und Genauigkeitskurve ist unten dargestellt:
pip install .Beachten Sie, dass PatrickStar gcc der Version 7 oder höher erfordert. Sie können auch NVIDIA NGC-Bilder verwenden. Das folgende Bild wurde getestet:
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar basiert auf PyTorch und erleichtert so die Migration eines Pytorch-Projekts. Hier ist ein Beispiel von PatrickStar:
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () Wir verwenden dasselbe config wie die DeepSpeed-Konfigurations-JSON, das hauptsächlich Parameter des Optimierers, des Verlustskalierers und einige PatrickStar-spezifische Konfigurationen enthält.
Eine ausführliche Erläuterung des obigen Beispiels finden Sie in der Anleitung hier
Weitere Beispiele finden Sie hier.
Ein Schnellstart-Benchmark-Skript finden Sie hier. Es wird mit zufällig generierten Daten ausgeführt; Daher müssen Sie keine echten Daten vorbereiten. Außerdem wurden alle Optimierungstechniken für Patrickstar demonstriert. Weitere Optimierungstricks zum Ausführen des Benchmarks finden Sie unter Optimierungsoptionen.
BSD-3-Klausel-Lizenz
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josepyu}@tencent.com
Unterstützt vom WeChat AI Team, Tencent NLP Oteam.


