xcodec
1.0.0
Einheitlicher semantischer und akustischer Codec für das Audio-Sprachmodell.
Titel : Codec spielt eine Rolle: Untersuchung des semantischen Mangels von Codec für das Audio-Sprachmodell
Autoren : Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo*, Wei Xue*
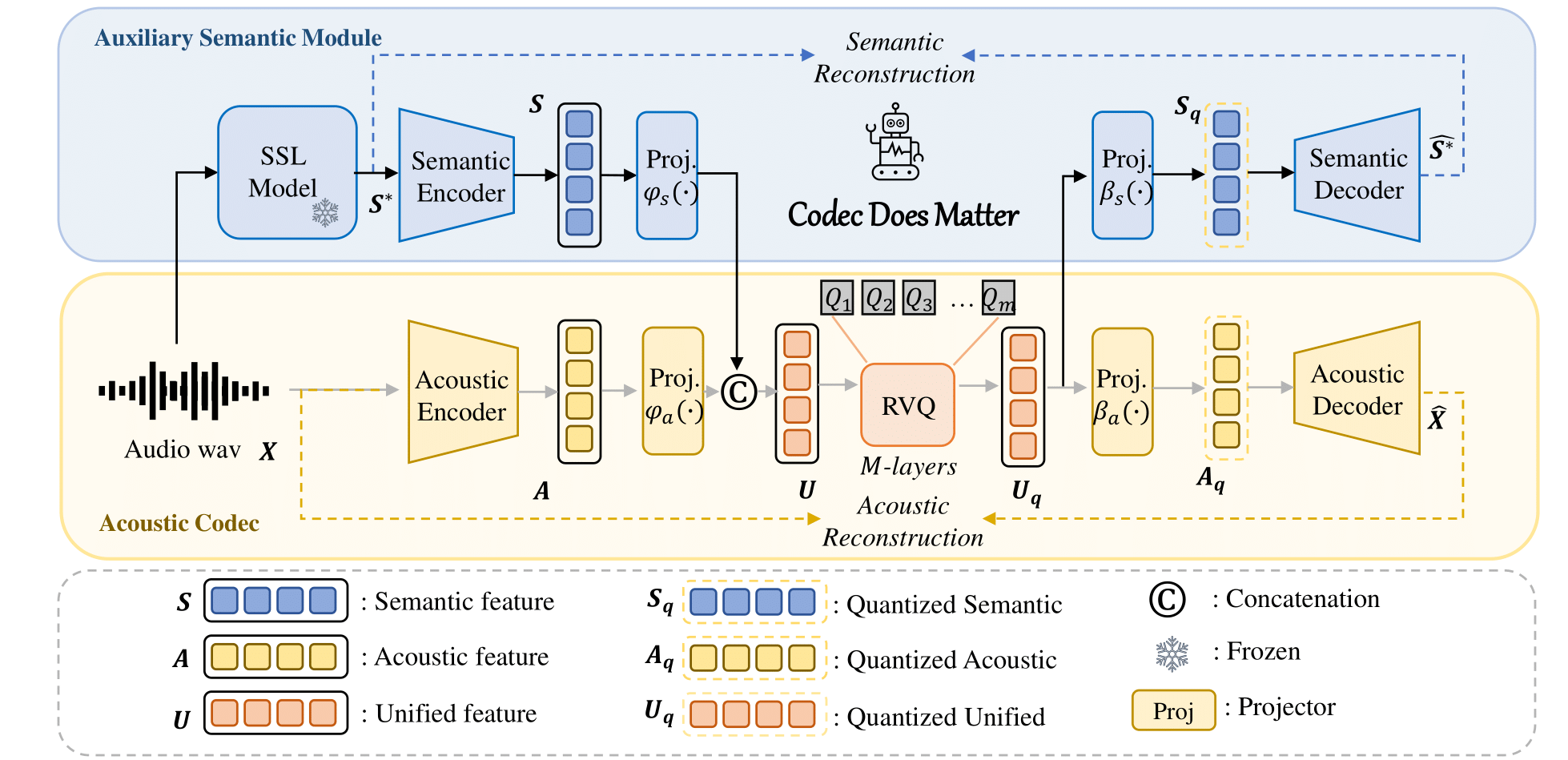
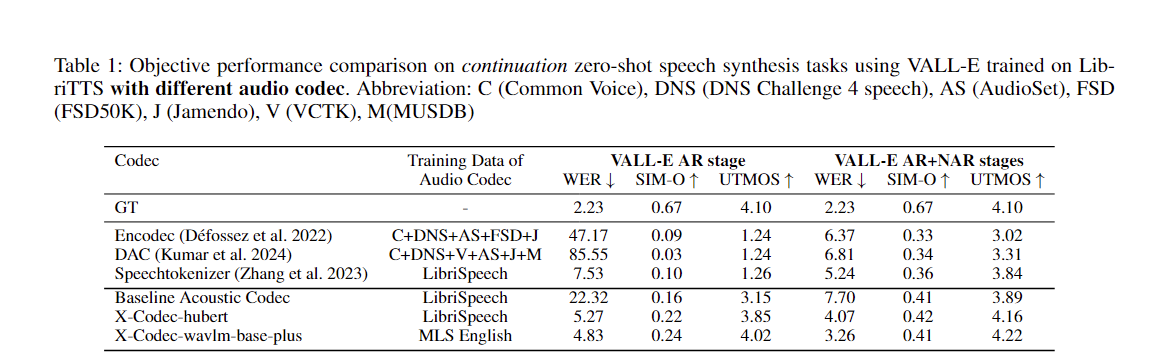
Sie können unseren Ansatz ganz einfach anwenden, um jeden vorhandenen akustischen Codec zu verbessern:
Zum Beispiel
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) Weitere Einzelheiten finden Sie in unserem Code.
? Links zum Huggingface-Modell-Hub.
| Modellname | Umarmendes Gesicht | Konfig | Semantisches Modell | Domain | Trainingsdaten |
|---|---|---|---|---|---|
| xcodec_hubert_librispeech | ? | ? | ? Hubert-Basis | Rede | Librirede |
| xcodec_wavlm_mls (im Papier nicht erwähnt) | ? | ? | ? Wavlm-base-plus | Rede | MLS-Englisch |
| xcodec_wavlm_more_data (im Papier nicht erwähnt) | ? | ? | ? Wavlm-base-plus | Rede | MLS Englisch + Interne Daten |
| xcodec_hubert_general_audio | ? | ? | ?Hubert-base-general-audio | Allgemeines Audio | 200.000 Stunden interne Daten |
| xcodec_hubert_general_audio_more_data (nicht im Papier erwähnt) | ? | ? | ?Hubert-base-general-audio | Allgemeines Audio | Ausgewogenere Daten |
Um die Inferenz auszuführen, laden Sie zunächst das Modell und die Konfiguration von Hugging Face herunter.
python inference.pyBereiten Sie die Trainingsdatei und die Validierungsdatei in der Konfiguration vor. In der Datei sollten die Pfade zu Ihren Audiodateien aufgeführt sein:
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...Dann:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.pyIch möchte den Autoren von Uniaudio und DAC einen besonderen Dank aussprechen, da unsere Codebasis hauptsächlich von Uniaudio und DAC übernommen wurde.
Wenn Sie dieses Repo hilfreich finden, erwägen Sie bitte, im folgenden Format zu zitieren:
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

