EasyEdit
1.0.0

Ein benutzerfreundliches Wissensbearbeitungs-Framework für große Sprachmodelle.
Installation • Schnellstart • Dokument • Papier • Demo • Benchmark • Mitwirkende • Folien • Video • Von AK vorgestellt
2024-10-23, EasyEdit integriert eingeschränkte Decodierungsmethoden von der Steuerungsbearbeitung zur Linderung von Halluzinationen in LLM und MLLM, wobei detaillierte Informationen in DoLa und DeCo verfügbar sind.
26.09.2024, ?? Unser Artikel „WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models“ wurde von NeurIPS 2024 angenommen.
20.09.2024, ?? Unsere Beiträge: „Knowledge Mechanisms in Large Language Models: A Survey and Perspective“ und „Editing Conceptual Knowledge for Large Language Models“ wurden von EMNLP 2024 Findings angenommen.
29.07.2024: EasyEdit hat einen neuen Modellbearbeitungsalgorithmus EMMET hinzugefügt, der ROME auf die Stapeleinstellung verallgemeinert. Dies ermöglicht im Wesentlichen die Durchführung von Stapelbearbeitungen mithilfe der ROME-Verlustfunktion.
Am 23.07.2024 veröffentlichen wir einen neuen Artikel: „Knowledge Mechanisms in Large Language Models: A Survey and Perspective“, der untersucht, wie Wissen in großen Sprachmodellen erworben, genutzt und weiterentwickelt wird. Diese Umfrage könnte die grundlegenden Mechanismen für die präzise und effiziente Manipulation (Bearbeitung) von Wissen in LLMs liefern.
04.06.2024, ?? EasyEdit Paper wurde vom ACL 2024 System Demonstration Track akzeptiert.
Am 03.06.2024 haben wir einen Artikel mit dem Titel „WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models“ veröffentlicht und gleichzeitig eine neue Bearbeitungsaufgabe eingeführt: Continuous Knowledge Editing und die entsprechende lebenslange Bearbeitungsmethode namens WISE.
24.04.2024, EasyEdit kündigte Unterstützung für die ROME-Methode für Llama3-8B an. Benutzern wird empfohlen, ihr Transformers-Paket auf Version 4.40.0 zu aktualisieren.
29.03.2024, EasyEdit hat Rollback-Unterstützung für GRACE eingeführt. Eine ausführliche Einführung finden Sie in der EasyEdit-Dokumentation. Zukünftige Updates werden nach und nach Rollback-Unterstützung für andere Methoden beinhalten.
Am 22.03.2024 wurde ein neues Papier mit dem Titel „Detoxifying Large Language Models via Knowledge Editing“ veröffentlicht, zusammen mit einem neuen Datensatz namens SafeEdit und einer neuen Entgiftungsmethode namens DINM.
Am 12.03.2024 wurde ein weiteres Papier mit dem Titel „Editing Conceptual Knowledge for Large Language Models“ veröffentlicht, in dem ein neuer Datensatz namens ConceptEdit vorgestellt wird.
01.03.2024, EasyEdit hat Unterstützung für eine neue Methode namens FT-M hinzugefügt. Bei dieser Methode wird eine bestimmte MLP-Schicht trainiert , indem Kreuzentropieverlust für die Zielantwort verwendet und der Originaltext maskiert wird . Es übertrifft die FT-L -Implementierung in ROME. Wir danken dem Autor der Ausgabe Nr. 173 für seinen Rat.
27.02.2024: EasyEdit hat Unterstützung für eine neue Methode namens InstructEdit hinzugefügt. Technische Details finden Sie im Artikel „InstructEdit: Instruction-based Knowledge Editing for Large Language Models“ .
Accelerate hinzugefügt.Eine umfassende Studie zur Wissensbearbeitung für große Sprachmodelle [Papier][Benchmark][Code]
IJCAI 2024-Tutorial Google Drive
COLING 2024 Tutorial Google Drive
AAAI 2024-Tutorial Google Drive
AACL 2023-Tutorial [Google Drive] [Baidu Pan]
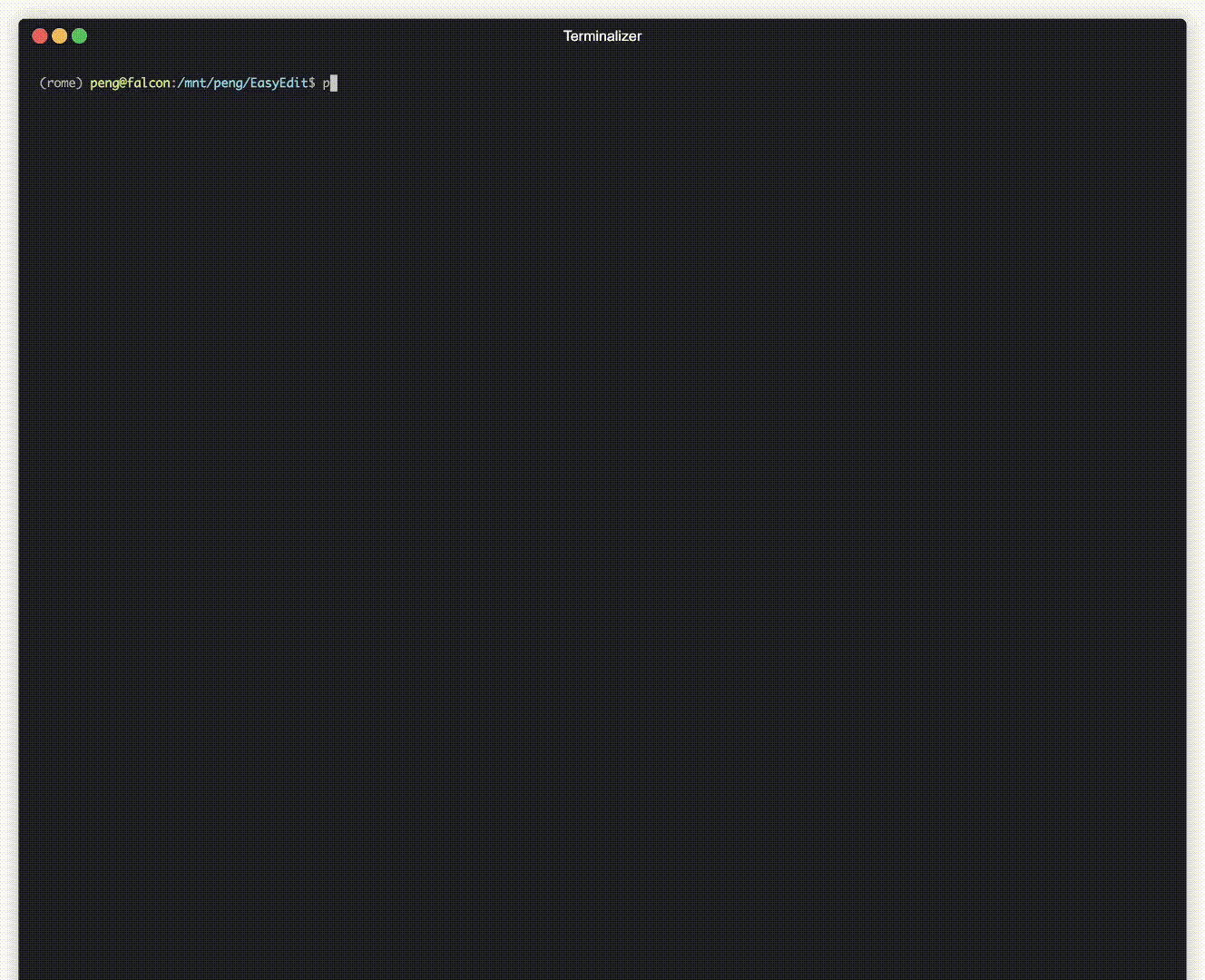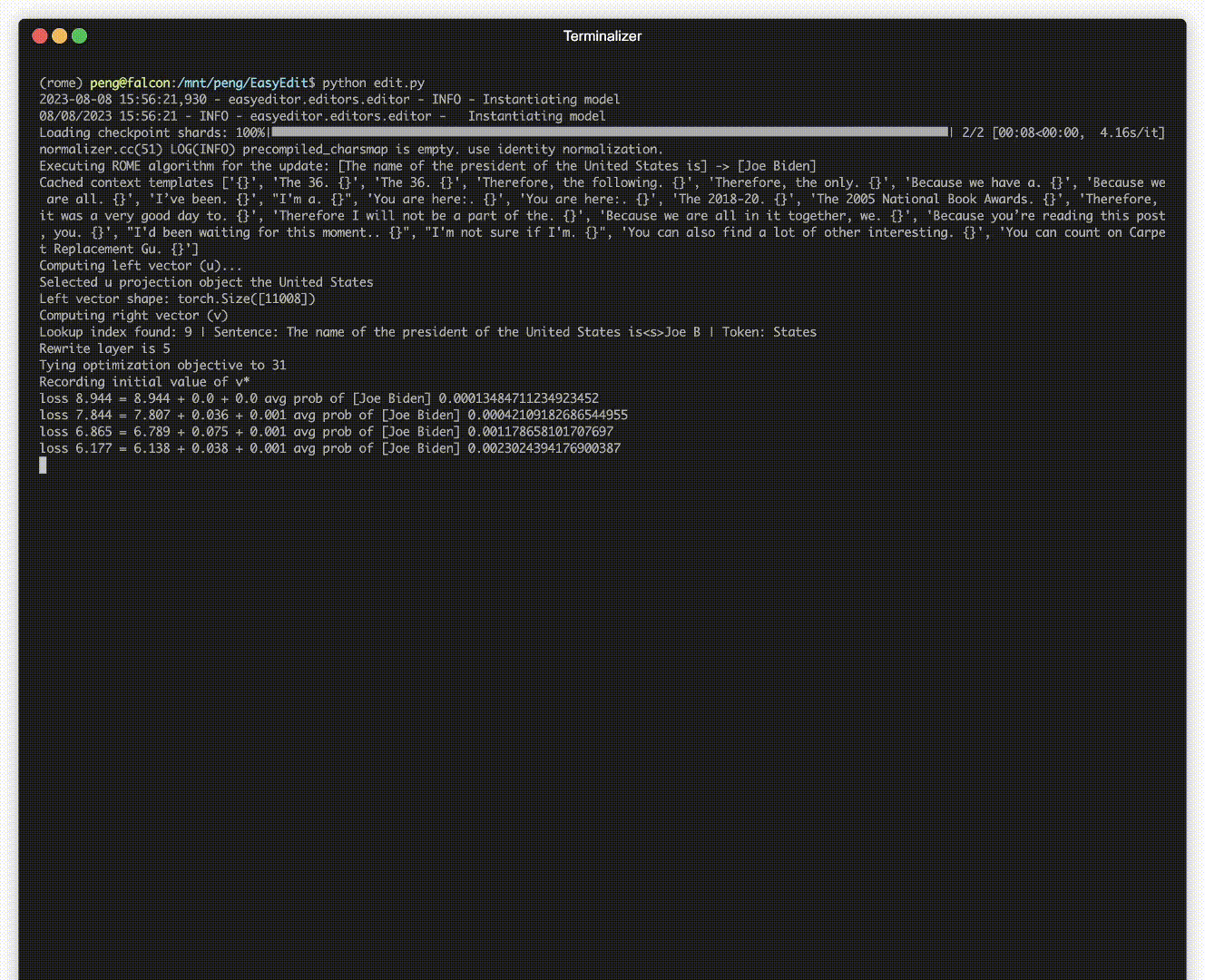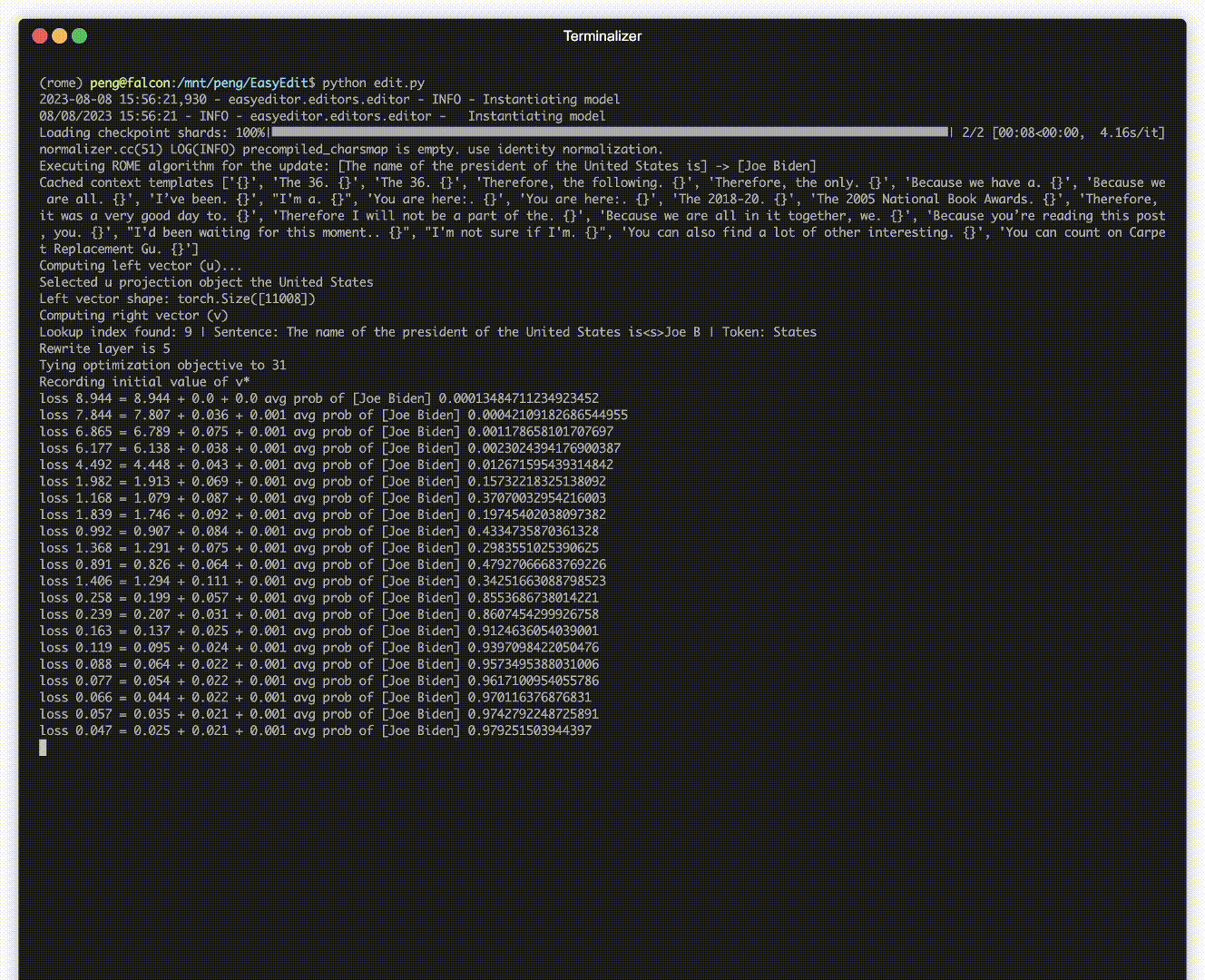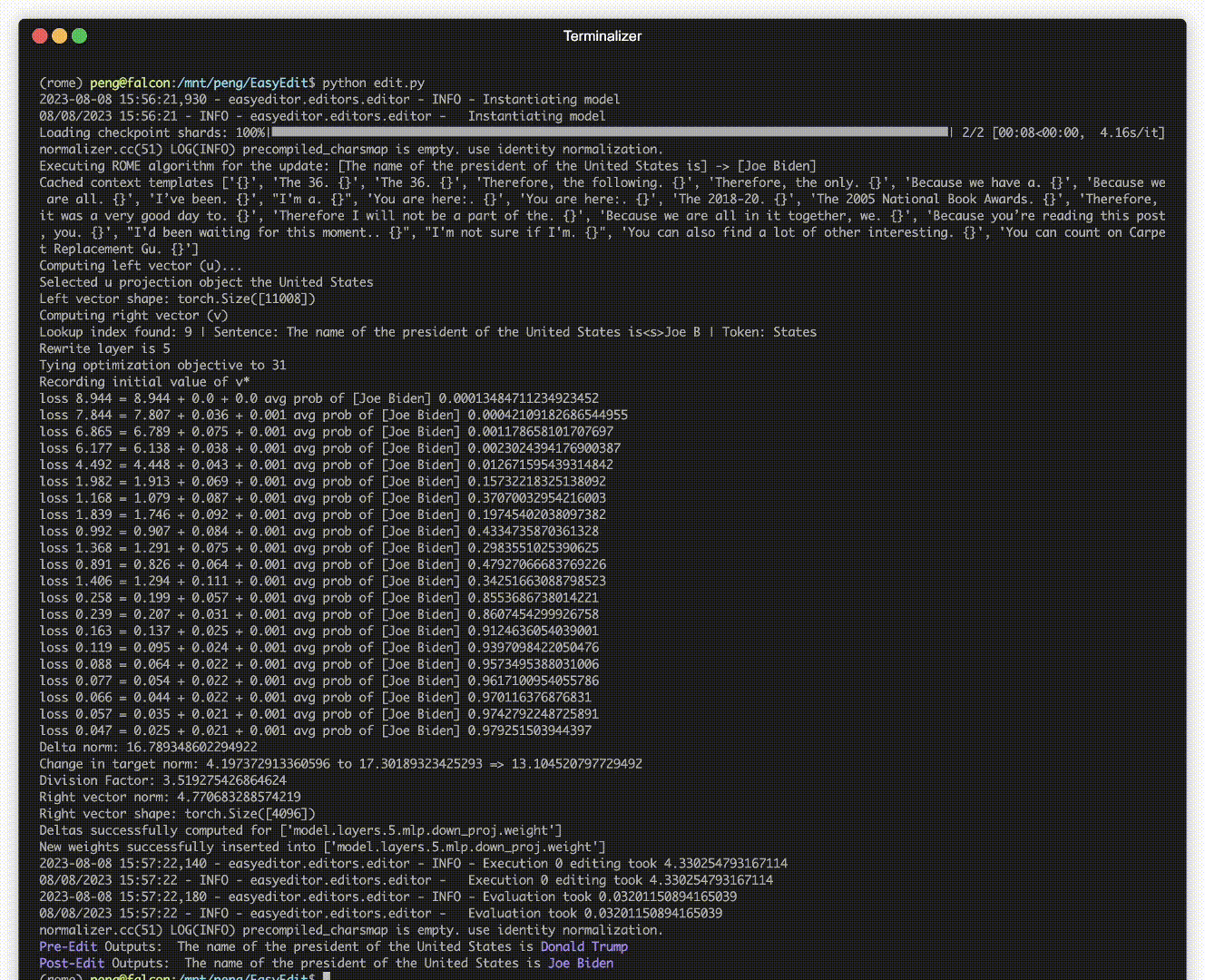
Es gibt eine Demonstration der Bearbeitung. Die GIF-Datei wird von Terminalizer erstellt.
Wir stellen ein praktisches Jupyter-Notizbuch zur Verfügung! Es ermöglicht Ihnen, das Wissen eines LLM über den US-Präsidenten zu bearbeiten und von Biden zu Trump und sogar zurück zu Biden zu wechseln. Dazu gehören Methoden wie WISE, AlphaEdit, AdaLoRA und Prompt-basierte Bearbeitung.
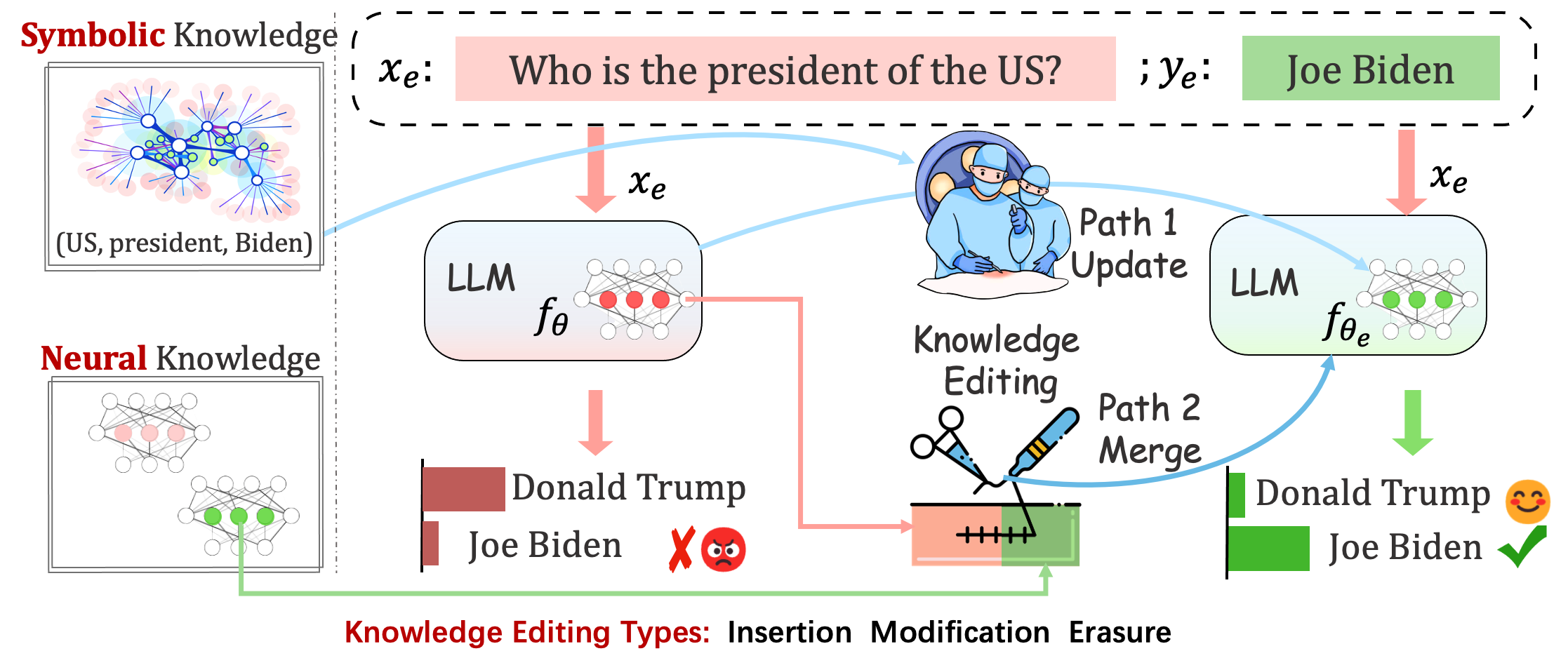
Eingesetzte Modelle können immer noch unvorhersehbare Fehler machen. Beispielsweise halluzinieren LLMs bekanntermaßen, halten Voreingenommenheit aufrecht und verfallen faktisch , sodass wir in der Lage sein sollten, bestimmte Verhaltensweisen vorab trainierter Modelle anzupassen.
Ziel der Wissensbearbeitung ist es, Basismodelle anzupassen
Bewerten der Leistung des Modells nach einer einzelnen Bearbeitung. Das Modell lädt nach einer einzelnen Bearbeitung die ursprünglichen Gewichte neu (z. B. verwirft LoRA die Adaptergewichte). Sie sollten sequential_edit=False festlegen
Dies erfordert eine sequenzielle Bearbeitung und die Auswertung erfolgt, nachdem alle Wissensaktualisierungen angewendet wurden:
Es nimmt Parameteranpassungen für vor sequential_edit=True festlegen: README (für weitere Details).
Ohne das Modellverhalten bei nicht verwandten Proben zu beeinflussen, besteht das ultimative Ziel darin, ein bearbeitetes Modell zu erstellen
Bearbeitungsaufgabe für Bildunterschriften und visuelle Beantwortung von Fragen . README
Die vorgeschlagene Aufgabe erfordert den ersten Versuch, die Persönlichkeit von LLMs zu bearbeiten, indem ihre Meinungen zu bestimmten Themen bearbeitet werden, vorausgesetzt, dass die Meinungen einer Person Aspekte ihrer Persönlichkeitsmerkmale widerspiegeln können. Wir stützen uns bei der Erstellung unseres Datensatzes und der Beurteilung der Persönlichkeitsausdrücke der LLMs auf die etablierte BIG-FIVE-Theorie. README
Auswertung
Protokollbasiert
Generationsbasiert
Zur Beurteilung von Acc und TPEI können Sie den trainierten Klassifikator hier herunterladen.
Der Wissensbearbeitungsprozess wirkt sich im Allgemeinen auf die Vorhersagen für eine breite Reihe von Eingaben aus , die eng mit dem Bearbeitungsbeispiel verknüpft sind und als Bearbeitungsbereich bezeichnet werden.
Eine erfolgreiche Bearbeitung sollte das Verhalten des Modells innerhalb des Bearbeitungsbereichs anpassen und gleichzeitig unabhängige Eingaben beibehalten:
Reliability : Die Erfolgsquote der Bearbeitung mit einem bestimmten BearbeitungsdeskriptorGeneralization : Die Erfolgsquote der Bearbeitung innerhalb des BearbeitungsbereichsLocality : ob sich die Ausgabe des Modells nach der Bearbeitung für nicht verwandte Eingaben ändertPortability : Die Erfolgsquote der Bearbeitung für Argumentation/Anwendung (ein Hop, Synonym, logische Verallgemeinerung)Efficiency : Zeit- und Speicherverbrauch EasyEdit ist ein Python-Paket zum Bearbeiten großer Sprachmodelle (LLM) wie GPT-J , Llama , GPT-NEO , GPT2 , T5 (unterstützt Modelle von 1B bis 65B ), dessen Ziel darin besteht, das Verhalten von LLMs effizient innerhalb eines zu ändern spezifische Domäne ohne negative Auswirkungen auf die Leistung anderer Eingaben. Es ist so konzipiert, dass es einfach zu bedienen und leicht zu erweitern ist.
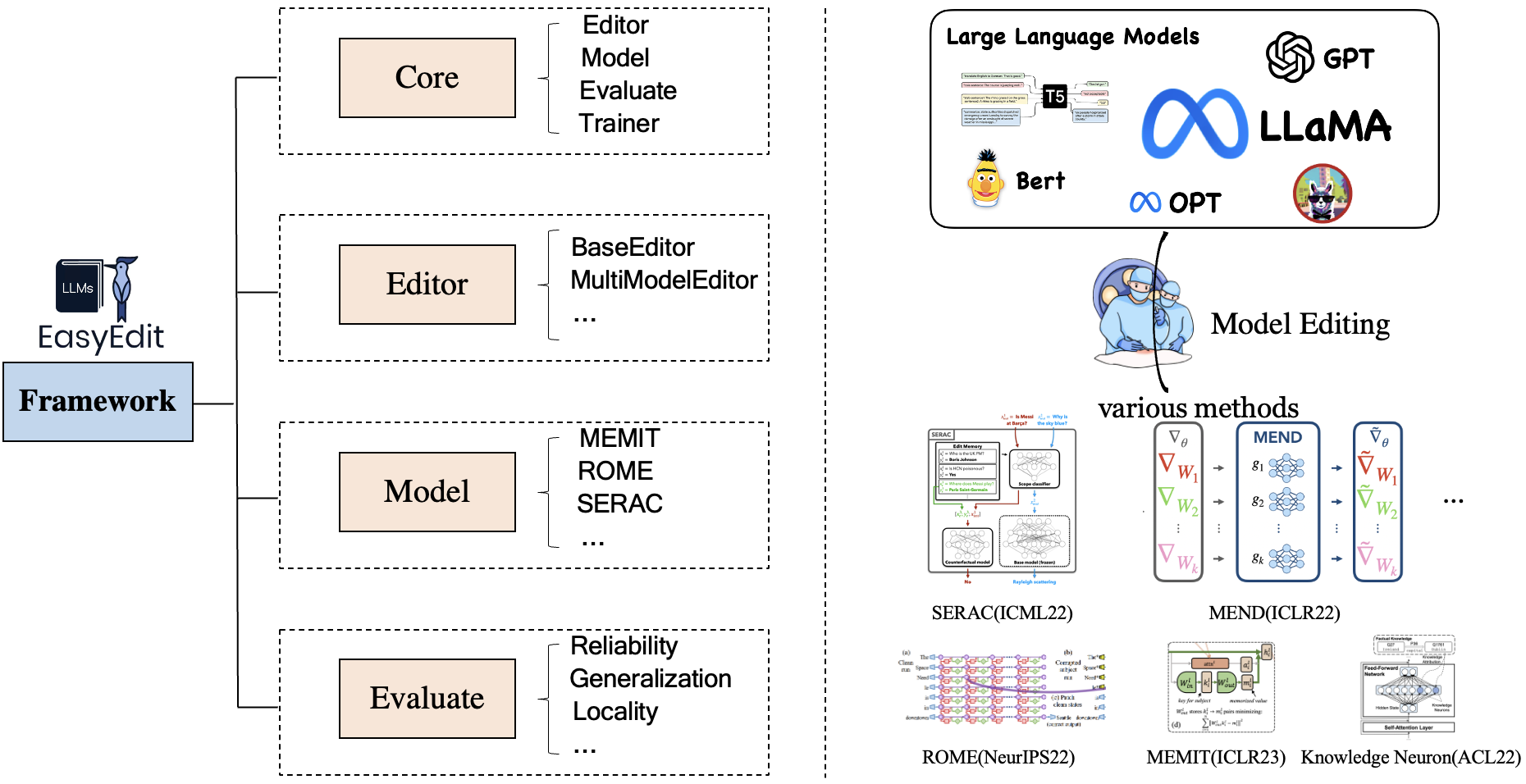
EasyEdit enthält ein einheitliches Framework für Editor , Methode und Evaluate , das jeweils das Bearbeitungsszenario, die Bearbeitungstechnik und die Bewertungsmethode darstellt.
Jedes Wissensbearbeitungsszenario besteht aus drei Komponenten:
Editor : wie BaseEditor ( Factual Knowledge and Generation Editor) für LM, MultiModalEditor ( MultiModal Knowledge ).Method : Die verwendete spezifische Wissensbearbeitungstechnik (z. B. ROME , MEND usw.).Evaluate : Metriken zur Bewertung der Wissensbearbeitungsleistung.Reliability , Generalization , Locality , PortabilityDie derzeit unterstützten Wissensbearbeitungstechniken sind wie folgt:
Hinweis 1: Aufgrund der eingeschränkten Kompatibilität dieses Toolkits werden einige Wissensbearbeitungsmethoden, einschließlich T-Patcher, KE, CaliNet, nicht unterstützt.
Hinweis 2: Ebenso wird die MALMEN-Methode aus den gleichen Gründen nur teilweise unterstützt und wird weiterhin verbessert.
Sie können je nach Ihren spezifischen Anforderungen verschiedene Bearbeitungsmethoden wählen.
| Verfahren | T5 | GPT-2 | GPT-J | GPT-NEO | Lama | Baichuan | ChatGLM | InternLM | Qwen | Mistral |
|---|---|---|---|---|---|---|---|---|---|---|
| FT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| AdaLoRA | ✅ | ✅ | ||||||||
| SERAC | ✅ | ✅ | ✅ | ✅ | ||||||
| IKE | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| HEILEN | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| KN | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ROM | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| r-ROM | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| MEMIT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| EMMET | ✅ | ✅ | ✅ | |||||||
| ANMUT | ✅ | ✅ | ✅ | |||||||
| MELO | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| AnweisenBearbeiten | ✅ | ✅ | ||||||||
| DINM | ✅ | ✅ | ✅ | |||||||
| WEISE | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| AlphaEdit | ✅ | ✅ | ✅ |
❗️❗️ Wenn Sie Mistral verwenden möchten, aktualisieren Sie bitte die
transformers-Bibliothek manuell auf Version 4.34.0. Sie können den folgenden Code verwenden:pip install transformers==4.34.0.
| Arbeiten | Beschreibung | Weg |
|---|---|---|
| AnweisenBearbeiten | InstructEdit: Anweisungsbasierte Wissensbearbeitung für große Sprachmodelle | Schnellstart |
| DINM | Entgiftung großer Sprachmodelle durch Wissensbearbeitung | Schnellstart |
| WEISE | WISE: Überdenken des Wissensspeichers für die lebenslange Modellbearbeitung großer Sprachmodelle | Schnellstart |
| KonzeptBearbeiten | Bearbeiten von konzeptionellem Wissen für große Sprachmodelle | Schnellstart |
| MMBearbeiten | Können wir multimodale große Sprachmodelle bearbeiten? | Schnellstart |
| PersönlichkeitBearbeiten | Bearbeiten der Persönlichkeit für große Sprachmodelle | Schnellstart |
| PROMPT | PROMPT-basierte Wissensbearbeitungsmethoden | Schnellstart |
Benchmark: KnowEdit [Hugging Face][WiseModel][ModelScope]
❗️❗️ Zu beachten ist, dass KnowEdit durch die Neuorganisation und Erweiterung bestehender Datensätze erstellt wird, darunter WikiBio , ZsRE , WikiData Counterfact , WikiData Recent , convsent und Sanitation , um eine umfassende Bewertung für die Wissensbearbeitung durchzuführen. Besonderer Dank geht an die Ersteller und Betreuer dieser Datensätze.
Bitte beachten Sie, dass Counterfact und WikiData Counterfact nicht derselbe Datensatz sind.
| Aufgabe | Wissenseinbringung | Wissensmodifikation | Wissenslöschung | |||
|---|---|---|---|---|---|---|
| Datensätze | Wiki aktuell | ZsRE | WikiBio | WikiData- Kontrafakt | Zustimmung | Hygiene |
| Typ | Tatsache | Beantwortung von Fragen | Halluzination | Kontrafakt | Gefühl | Unerwünschte Informationen |
| # Zug | 570 | 10.000 | 592 | 1.455 | 14.390 | 80 |
| # Prüfen | 1.266 | 1301 | 1.392 | 885 | 800 | 80 |
Wir stellen detaillierte Skripte zur Verfügung, mit denen Benutzer KnowEdit einfach verwenden können. Weitere Informationen finden Sie in den Beispielen.
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| Datensatz | Umarmendes Gesicht | WiseModel | ModelScope | Beschreibung |
|---|---|---|---|---|
| CKnowEdit | [Umarmendes Gesicht] | [WiseModel] | [ModelScope] | Datensatz zur Bearbeitung des chinesischen Wissens |
CKnowEdit ist ein hochwertiger chinesischsprachiger Datensatz zur Wissensbearbeitung, der stark durch die chinesische Sprache geprägt ist und dessen Daten aus chinesischen Wissensdatenbanken stammen. Es wurde sorgfältig entwickelt, um die Nuancen und Herausforderungen, die das Verständnis der chinesischen Sprache durch aktuelle LLM-Studierende mit sich bringt, tiefer zu erkennen und eine solide Ressource für die Verfeinerung chinesischspezifischer Kenntnisse innerhalb von LLM-Studiengängen bereitzustellen.
Die Feldbeschreibungen für die Daten in CKnowEdit lauten wie folgt:
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| Datensatz | Google Drive | BaiduNetDisk | Beschreibung |
|---|---|---|---|
| ZsRE plus | [Google Drive] | [BaiduNetDisk] | Frage-Antwort-Datensatz mit Fragenumformulierungen |
| Kontrafakt plus | [Google Drive] | [BaiduNetDisk] | Kontrafaktischer Datensatz mit Entitätsersetzung |
Wir stellen ZSRE- und Counterfact-Datensätze zur Verfügung, um die Wirksamkeit der Wissensbearbeitung zu überprüfen. Sie können sie hier herunterladen. [Google Drive], [BaiduNetDisk].
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse| Datensatz | Google Drive | HuggingFace-Datensatz | Beschreibung |
|---|---|---|---|
| KonzeptBearbeiten | [Google Drive] | [HuggingFace-Datensatz] | Datensatz zur Bearbeitung konzeptionellen Wissens |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
Konzeptspezifische Bewertungsmetriken
Instance Change : Erfassen der Feinheiten dieser Änderungen auf InstanzebeneConcept Consistency : die semantische Ähnlichkeit der generierten Konzeptdefinition | Datensatz | Google Drive | BaiduNetDisk | Beschreibung |
|---|---|---|---|
| E-IC | [Google Drive] | [BaiduNetDisk] | Datensatz zum Bearbeiten von Bildunterschriften |
| E-VQA | [Google Drive] | [BaiduNetDisk] | Datensatz zur Bearbeitung von Visual Question Answering |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| Datensatz | HuggingFace-Datensatz | Beschreibung |
|---|---|---|
| SafeEdit | [HuggingFace-Datensatz] | Datensatz zur Entgiftung von LLMs |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
Entgiftende spezifische Bewertungsmetriken
Defense Duccess (DS) : Die Entgiftungserfolgsrate des bearbeiteten LLM für gegnerische Eingaben (Angriffsaufforderung + schädliche Frage), die zum Modifizieren des LLM verwendet wird.Defense Generalization (DG) : Die Entgiftungserfolgsrate von bearbeitetem LLM für böswillige Eingaben außerhalb der Domäne.General Performance : die Nebenwirkungen für die Leistung unabhängiger Aufgaben. | Verfahren | Beschreibung | GPT-2 | Lama |
|---|---|---|---|
| IKE | In-Context Learning (ICL) Bearbeiten | [Colab-gpt2] | [Colab-Lama] |
| ROM | Neuronen lokalisieren und dann bearbeiten | [Colab-gpt2] | [Colab-Lama] |
| MEMIT | Neuronen lokalisieren und dann bearbeiten | [Colab-gpt2] | [Colab-Lama] |
Hinweis: Bitte verwenden Sie Python 3.9+ für EasyEdit. Um zu beginnen, installieren Sie einfach conda und führen Sie Folgendes aus:
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txtUnsere Ergebnisse basieren alle auf der Standardkonfiguration
| Lama-2-7B | chatglm2 | gpt-j-6b | gpt-xl | |
|---|---|---|---|---|
| FT | 60 GB | 58 GB | 55 GB | 7 GB |
| SERAC | 42 GB | 32 GB | 31 GB | 10 GB |
| IKE | 52 GB | 38 GB | 38 GB | 10 GB |
| HEILEN | 46 GB | 37 GB | 37 GB | 13 GB |
| KN | 42 GB | 39 GB | 40 GB | 12 GB |
| ROM | 31 GB | 29 GB | 27 GB | 10 GB |
| MEMIT | 33 GB | 31 GB | 31 GB | 11 GB |
| AdaLoRA | 29 GB | 24 GB | 25 GB | 8 GB |
| ANMUT | 27 GB | 23 GB | 6 GB | |
| WEISE | 34 GB | 27 GB | 7 GB |
Bearbeiten Sie große Sprachmodelle (LLMs) in etwa 5 Sekunden
Das folgende Beispiel zeigt Ihnen, wie Sie die Bearbeitung mit EasyEdit durchführen. Weitere Beispiele und Tutorials finden Sie unter Beispiele
BaseEditorist die Klasse für die sprachmodale Wissensbearbeitung. Sie können die geeignete Bearbeitungsmethode basierend auf Ihren spezifischen Anforderungen auswählen.
Dank der Modularität und Flexibilität von EasyEdit können Sie es problemlos zum Bearbeiten von Modellen verwenden.
Schritt 1: Definieren Sie ein PLM als zu bearbeitendes Objekt. Wählen Sie das zu bearbeitende PLM aus. EasyEdit unterstützt Teilmodelle ( T5 , GPTJ , GPT-NEO , LlaMA bisher), die auf HuggingFace abrufbar sind. Das entsprechende Konfigurationsdateiverzeichnis ist hparams/YUOR_METHOD/YOUR_MODEL.YAML , z. B. hparams/MEND/gpt2-xl.yaml . Legen Sie den entsprechenden model_name fest, um das Objekt für die Wissensbearbeitung auszuwählen.
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingSchritt 2: Wählen Sie die entsprechende Wissensbearbeitungsmethode
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )Schritt 3: Geben Sie den Bearbeitungsdeskriptor und das Bearbeitungsziel an
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ] Schritt 4: Kombinieren Sie sie zu einem BaseEditor EasyEdit bietet eine einfache und einheitliche Möglichkeit, Editor zu initiieren, wie zum Beispiel Huggingface: from_hparams .
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )Schritt 5: Bereitstellen der Daten für die Auswertung. Beachten Sie, dass die Daten für Portabilität und Lokalität beide optional sind (auf „Keine“ gesetzt, nur für die grundlegende Auswertung der Bearbeitungserfolgsrate). Das Datenformat für beide ist ein Diktat . Für jede Messdimension müssen Sie die entsprechende Eingabeaufforderung und die entsprechende Grundwahrheit angeben. Hier ist ein Beispiel der Daten:
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}Im obigen Beispiel bewerten wir die Leistung der Bearbeitungsmethoden zu „Nachbarschaft“ und „Ablenkung“.
Schritt 6: Bearbeitung und Auswertung abgeschlossen! Wir können die Bearbeitung und Bewertung Ihres zu bearbeitenden Modells durchführen. Die edit gibt eine Reihe von Metriken im Zusammenhang mit dem Bearbeitungsprozess sowie die geänderten Modellgewichte zurück. [ sequential_edit=True für kontinuierliche Bearbeitung]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelDie maximale Eingabelänge für EasyEdit beträgt 512. Wenn diese Länge überschritten wird, wird der Fehler „CUDA-Fehler: Geräteseitiges Assert ausgelöst“ angezeigt. Sie können die maximale Länge in der folgenden Datei ändern:LINK
Schritt 7: RollBack Wenn Sie bei der sequentiellen Bearbeitung mit dem Ergebnis einer Ihrer Bearbeitungen nicht zufrieden sind und Ihre vorherigen Bearbeitungen nicht verlieren möchten, können Sie die Rollback-Funktion verwenden, um Ihre vorherige Bearbeitung rückgängig zu machen. Derzeit unterstützen wir nur die GRACE-Methode. Alles, was Sie tun müssen, ist eine einzige Codezeile und den edit_key, um Ihre Bearbeitung rückgängig zu machen.
editor.rolllback('edit_key')
In EasyEdit verwenden wir standardmäßig target_new als edit_key
Wir geben die Rückgabemetriken als dict an, einschließlich Modellvorhersageauswertungen vor und nach der Bearbeitung. Für jede Bearbeitung werden die folgenden Messwerte enthalten:
rewrite_acc rephrase_acc locality portablility 

