GraphGPT: Graphenlernen mit generativen vorab trainierten Transformatoren
Dieses Repository ist die offizielle Implementierung von „GraphGPT: Graph Learning with Generative Pre-trained Transformers“ in PyTorch.
GraphGPT: Graphenlernen mit generativen vorab trainierten Transformatoren
Qifang Zhao, Weidong Ren, Tianyu Li, Xiaoxiao Xu, Hong Liu
Aktualisieren:
13.10.2024
- v0.4.0 veröffentlicht. Weitere Informationen finden Sie in
CHANGELOG.md . - Erreichen von SOTA in 3 großen OGB-Datensätzen:
- PCQM4M-v2 (kein 3D): 0,0802 (vorheriger SOTA 0,0821)
- ogbl-ppa: 68,76 (vorheriger SOTA 65,24)
- ogbl-citation2: 91,15 (vorheriger SOTA 90,72)
18.08.2024
- v0.3.1 veröffentlicht. Weitere Informationen finden Sie in
CHANGELOG.md .
07.09.2024
- v0.3.0 veröffentlicht.
19.03.2024
- v0.2.0 veröffentlicht.
- Implementieren Sie
permute_nodes für Datensätze im Kartenstil auf Diagrammebene, um die Variationen von Euler-Pfaden zu erhöhen und bessere und robustere Ergebnisse zu erzielen. - Fügen Sie
StackedGSTTokenizer hinzu, damit Semantik-Tokens (dh Knoten-/Kantenattribute) zusammen mit Struktur-Tokens gestapelt werden können und die Länge der Sequenz erheblich reduziert wird. - Refaktorierungscodes.
23.01.2024
- v0.1.1, Fehler im common-io-Paket beheben.
01.03.2024
- Erstveröffentlichung von Codes.
Zukünftige Richtungen
Skalierungsgesetz: Was ist die Skalierungsgrenze von GraphGPT-Modellen?
- Wie wir wissen, kann mit Textdaten trainiertes GPT auf Hunderte Milliarden Parameter skaliert werden und seine Leistungsfähigkeit ständig verbessern.
- Textdaten können Billionen von Token bereitstellen, sind sehr komplex und verfügen über viel Wissen, einschließlich sozialem und natürlichem Wissen.
- Im Gegensatz dazu enthalten Diagrammdaten ohne Knoten-/Kantenattribute nur Strukturinformationen, die im Vergleich zu Textdaten recht begrenzt sind. Die meisten versteckten Informationen (z. B. Grad, Anzahl der Unterstrukturen usw.) hinter der Struktur können mit Paketen wie networkx genau berechnet werden. Daher sind Informationen aus der Diagrammstruktur möglicherweise nicht in der Lage, die Skalierung der Modellgröße auf Milliarden von Parametern zu unterstützen.
- Unsere vorläufigen Experimente mit verschiedenen großen Diagrammdatensätzen zeigen, dass wir GraphGPT bei verbesserter Leistung auf bis zu 400 Millionen Parameter skalieren können. Aber wir können die Ergebnisse nicht weiter verbessern. Es könnte an unseren unzureichenden Experimenten liegen. Es ist jedoch möglich, dass dies auf die inhärenten Einschränkungen von Diagrammdaten zurückzuführen ist.
- Große Diagrammdatensätze (entweder ein großes Diagramm oder große Mengen kleiner Diagramme) mit Knoten-/Kantenattributen können uns möglicherweise genügend Informationen liefern, um ein großes GraphGPT-Modell zu trainieren. Dennoch reicht ein Diagrammdatensatz möglicherweise nicht aus und wir müssen möglicherweise verschiedene Diagrammdatensätze sammeln, um einen GraphGPT zu trainieren.
- Das Problem besteht hier darin, einen universellen Tokenizer für Kanten-/Knotenattribute aus verschiedenen Diagrammdatensätzen zu definieren.
Hochwertige Diagrammdaten: Was sind hochwertige Diagrammdaten für das Training eines GraphGPT für allgemeine Aufgaben?
- Wenn wir beispielsweise ein Modell für alle Arten von Aufgaben zum Verständnis und zur Generierung von Molekülen trainieren möchten, welche Art von Daten sollen wir dann verwenden?
- Aus unserer vorläufigen Untersuchung geht hervor, dass wir ZINC (4,6 Mio.) und CEPDB (2,3 Mio.) zum Vortraining hinzufügen und bei der Feinabstimmung von PCQM4M-v2 für die Homo-Lumo-Lückenvorhersageaufgabe keine Gewinne feststellen konnten. Die möglichen Gründe könnten wie folgt sein:
- #Struktur# Das Diagrammmuster hinter dem Moleküldiagramm ist relativ einfach.
- Diagrammmuster wie Ketten oder 5/6-Knoten-Ringe sind sehr verbreitet.
- Durchschnittlich 2 Kanten pro Knoten, was bedeutet, dass Atome im Durchschnitt 2 Bindungen haben.
- #Semantik# Die chemischen Regeln für den Aufbau organischer kleiner Moleküle sind einfach: Das Kohlenstoffatom hat 4 Bindungen, das Stickstoffatom hat 3 Bindungen, das Sauerstoffatom hat 2 Bindungen und das Wasserstoffatom hat 1 Bindung und so weiter. Einfach ausgedrückt: Solange die Bindungszahlen der Atome erfüllt sind, können wir beliebige Moleküle erzeugen.
- Die Regeln sowohl der Struktur als auch der Semantik sind so einfach, dass selbst ein mittelgroßes Modell aus dem mittelgroßen Datensatz lernen kann. Das Hinzufügen zusätzlicher Daten hilft also nicht. Wir trainieren kleine/mittlere/Basis-/große Modelle vorab mit 3,7 Millionen Moleküldaten, und ihre Verluste liegen sehr nahe beieinander, was auf begrenzte Gewinne durch die Vergrößerung der Modellgrößen in der Vortrainingsphase hinweist.
- Zweitens: Welche Art von Daten sollen wir verwenden, wenn wir ein Modell für beliebige Arten von Aufgaben zum Verständnis der Graphstruktur trainieren möchten?
- Sollen wir echte Diagrammdaten aus sozialen Netzwerken, Zitiernetzwerken usw. verwenden oder nur synthetische Diagrammdaten wie zufällige Erdos-Renyi-Diagramme?
- Unsere vorläufigen Experimente zeigen, dass die Verwendung von Zufallsgraphen zum Vorabtraining von GraphGPT für das Modell hilfreich ist, um Graphstrukturen zu verstehen, aber es ist instabil. Wir vermuten, dass es mit den Verteilungen der Graphstrukturen in den Phasen vor dem Training und der Feinabstimmung zusammenhängt. Wenn sie beispielsweise eine ähnliche Anzahl von Kanten pro Knoten und eine ähnliche Anzahl von Knoten haben, funktioniert das Vortrainings- und Feinabstimmungsparadigma gut.
- #Universalität# Wie trainiert man also ein GraphGPT-Modell, um jede Graphstruktur universell zu verstehen?
- Dies geht auf frühere Fragen zum Skalierungsgesetz zurück: Was sind die richtigen und qualitativ hochwertigen Diagrammdaten, um GraphGPT weiter zu skalieren, damit es verschiedene Diagrammaufgaben gut erledigen kann?
Few-Shot: Kann GraphGPT die Few-Shot-Fähigkeit erlangen?
- Wie können die Trainingsdaten nach Möglichkeit so gestaltet werden, dass GraphGPT sie lernen kann?
- Aus unseren vorläufigen Experimenten mit dem PCQM4M-v2-Datensatz lassen sich zahlreiche Schusslernfähigkeiten beobachten! Das heißt aber nicht, dass es nicht möglich ist. Es könnte folgende Gründe haben:
- Das Modell ist nicht groß genug. Wir verwenden ein Basismodell mit ~100 Millionen Parametern.
- Die Trainingsdaten reichen nicht aus. Wir verwenden nur 3,7 Mio. Moleküle, wodurch nur begrenzte Token für das Training bereitgestellt werden.
- Das Format der Trainingsdaten ist nicht für das Modell geeignet, um die Fähigkeit zu wenigen Schüssen zu erlangen.
Überblick:

Wir schlagen GraphGPT vor, ein neuartiges Modell für das Graphenlernen durch selbstüberwachte generative Pre-Training Graph Eulerian Transformers (GET). Wir stellen zunächst GET vor, das aus einem Vanilla-Transformer-Encoder/Decoder-Backbone und einer Transformation besteht, die jeden Graphen oder abgetasteten Untergraphen in eine Folge von Token umwandelt, die den Knoten, die Kante und die Attribute reversibel unter Verwendung des Eulerschen Pfads darstellen. Dann trainieren wir das GET entweder mit der NTP-Aufgabe (Next-Token-Prediction) oder der SMTP-Aufgabe (Scheduled Masked-Token-Prediction) vor. Abschließend optimieren wir das Modell mit den überwachten Aufgaben. Dieses intuitive und dennoch effektive Modell erzielt bessere oder ähnliche Ergebnisse als die modernsten Methoden für die Aufgaben auf Graphen-, Kanten- und Knotenebene auf dem groß angelegten molekularen Datensatz PCQM4Mv2, dem Protein-Protein-Assoziationsdatensatz ogbl-ppa , Zitationsnetzwerk-Datensatz ogbl-citation2 und der ogbn-proteins-Datensatz aus dem Open Graph Benchmark (OGB). Darüber hinaus ermöglicht uns das generative Vortraining, GraphGPT mit bis zu 2B+ Parametern bei konstant steigender Leistung zu trainieren, was über die Möglichkeiten von GNNs und früheren Graphtransformatoren hinausgeht.
Diagramm zu Sequenzen
Nach der Konvertierung eulerisierter Diagramme in Sequenzen gibt es verschiedene Möglichkeiten, Knoten- und Kantenattribute an die Sequenzen anzuhängen. Wir nennen diese Methoden short , long und prolonged .
Wir eulerisieren den gegebenen Graphen zunächst und wandeln ihn dann in eine äquivalente Sequenz um. Und dann indizieren wir die Knoten zyklisch neu.
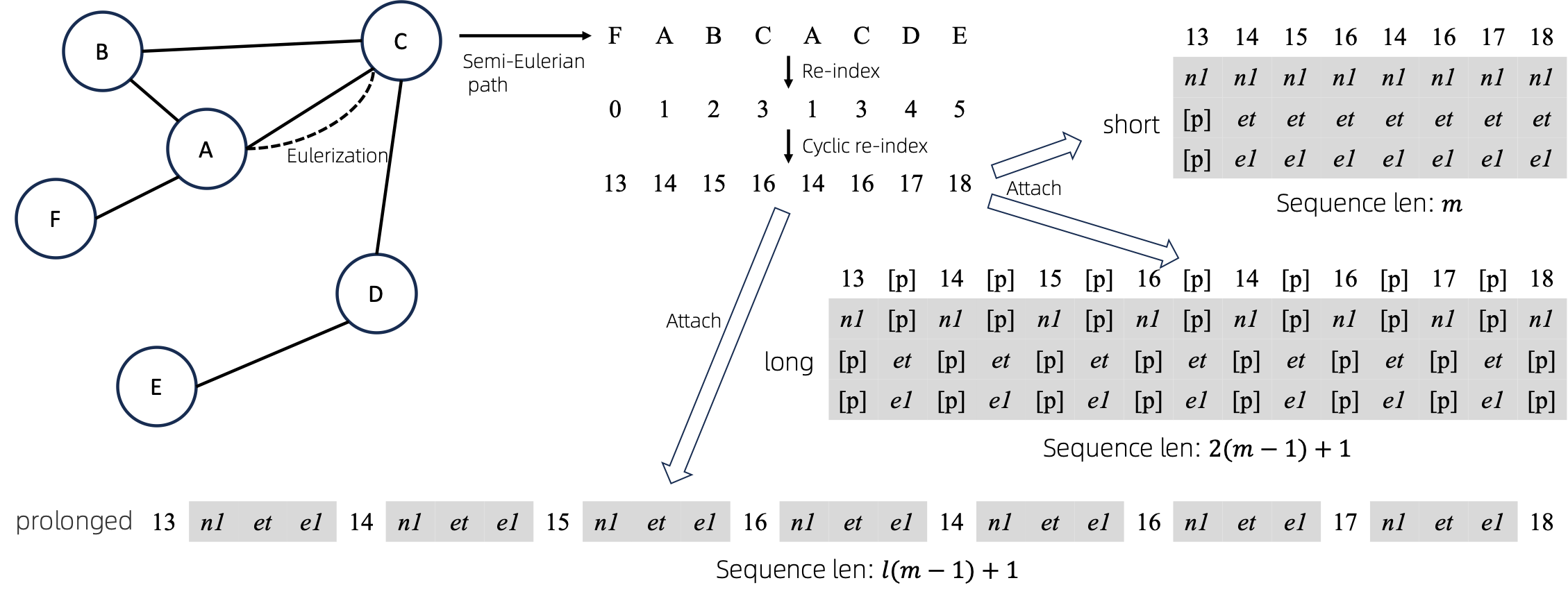
Angenommen, das Diagramm verfügt über ein Knotenattribut und ein Kantenattribut. Dann sind oben die Methoden short , long und prolong dargestellt.
In den obigen Abbildungen stellen n1 , n2 und e1 die Token der Knoten- und Kantenattribute dar und [p] stellt das Fülltoken dar.
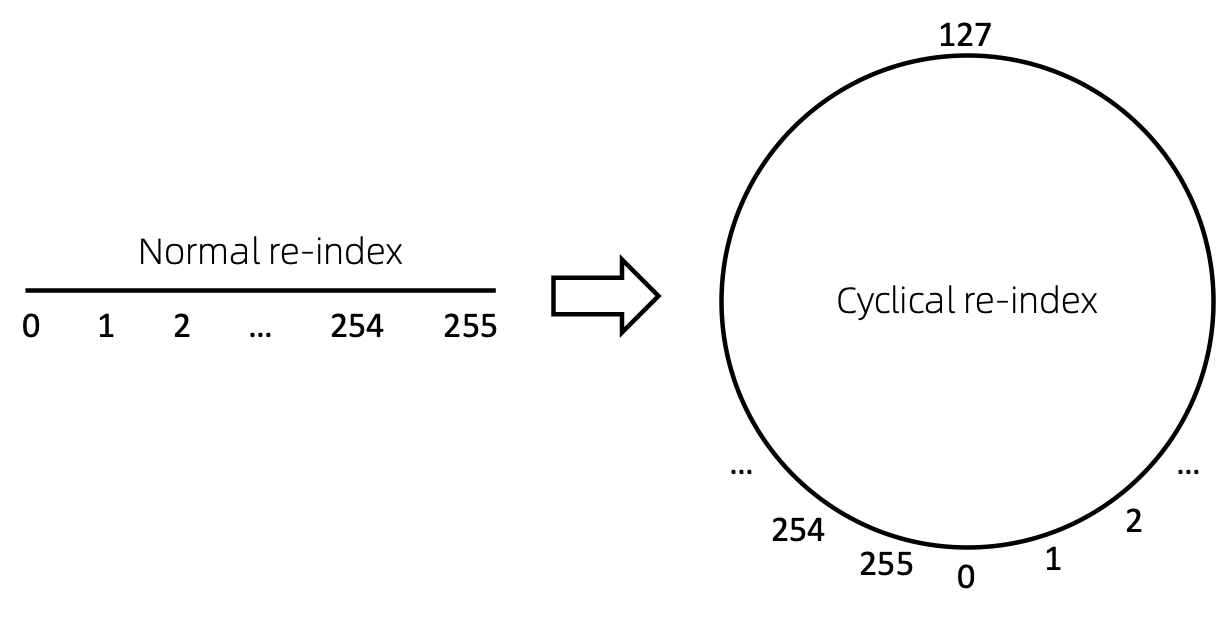
Zyklische Neuindizierung des Knotens
Eine einfache Möglichkeit, die Knotenfolge neu zu indizieren, besteht darin, bei 0 zu beginnen und schrittweise 1 hinzuzufügen. Auf diese Weise werden Token kleiner Indizes ausreichend trainiert, große Indizes jedoch nicht. Um dies zu überwinden, schlagen wir cyclical re-index vor, die mit einer Zufallszahl im angegebenen Bereich, beispielsweise [0, 255] , beginnt und um 1 erhöht wird. Nach Erreichen der Grenze, z. B. 255 , ist der nächste Knotenindex 0 .
Ergebnisse
Veraltet. Wird bald aktualisiert.
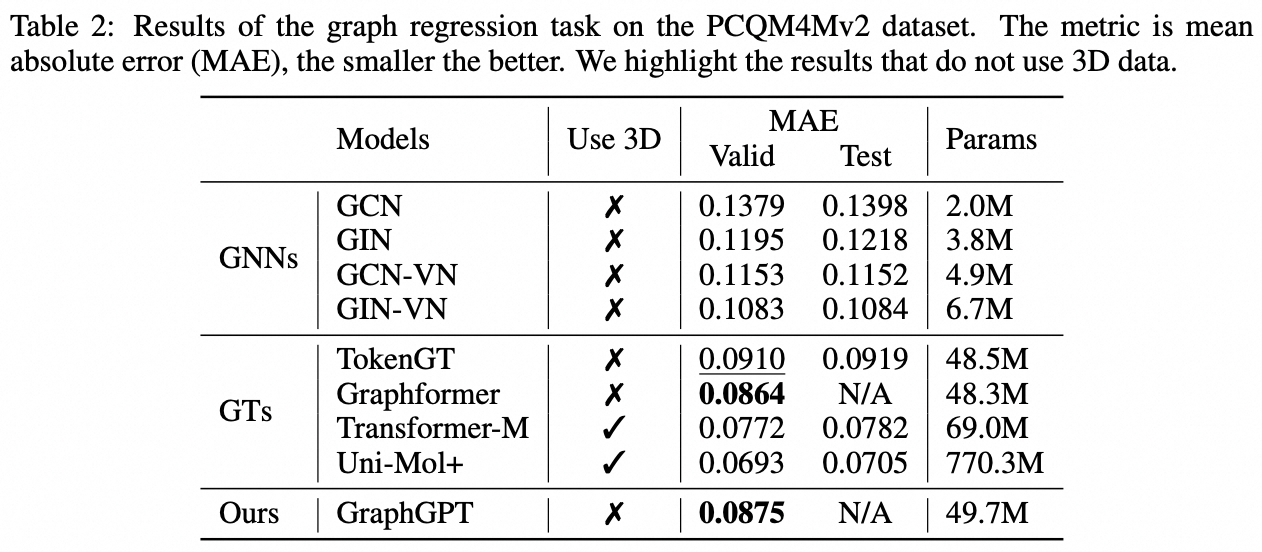
Aufgabe auf Diagrammebene: PCQM4M-v2-Datensatz
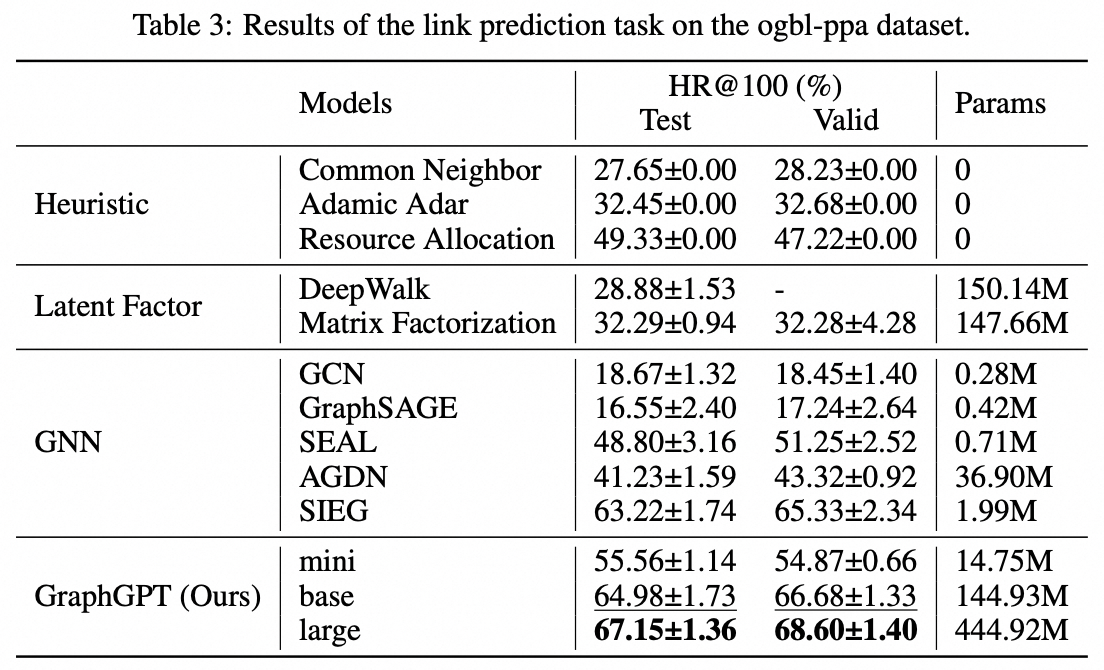
Edge-Level-Aufgabe: ogbl-ppa-Datensatz
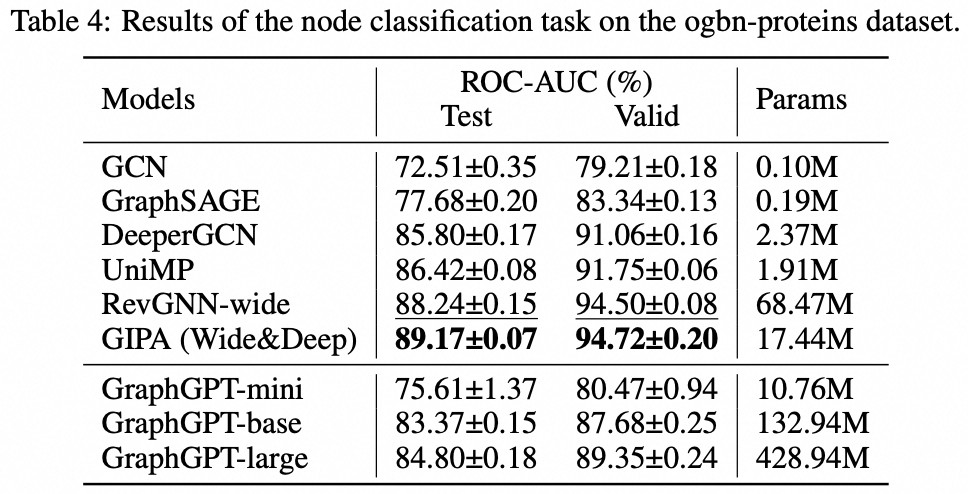
Aufgabe auf Knotenebene: Ogbn-Protein-Datensatz
Installation
- Klonen Sie dieses Repository
git clone https://github.com/alibaba/graph-gpt.git
- Installieren Sie die Abhängigkeiten in „requirements.txt“ (mit Anaconda, getestet mit py38, pytorch-1131 und CUDA-11.7, 11.8 und 12.1 auf GPU V100 und A100)
conda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc
Datensätze
Die Datensätze werden mit dem Python-Paket OGB heruntergeladen.
Wenn Sie Skripte in ./examples ausführen, wird der Datensatz automatisch heruntergeladen.
Allerdings ist der Datensatz PCQM4M-v2 riesig und das Herunterladen und Vorverarbeiten könnte problematisch sein. Wir empfehlen cd ./src/utils/ und python dataset_utils.py um den Datensatz separat herunterzuladen und vorzuverarbeiten.
Laufen
- Vortrainieren: Ändern Sie Parameter in
./examples/graph_lvl/pcqm4m_v2_pretrain.sh , z. B. dataset_name , model_name , batch_size , workerCount usw., und führen Sie dann ./examples/graph_lvl/pcqm4m_v2_pretrain.sh aus, um das Modell mit PCQM4M-v2 vorab zu trainieren Datensatz.- Um das Spielzeugbeispiel auszuführen, führen Sie
./examples/toy_examples/reddit_pretrain.sh direkt aus.
- Feinabstimmung: Ändern Sie Parameter in
./examples/graph_lvl/pcqm4m_v2_supervised.sh , z. B. dataset_name , model_name , batch_size , workerCount , pretrain_cpt usw., und führen Sie dann ./examples/graph_lvl/pcqm4m_v2_supervised.sh aus, um die Feinabstimmung mit nachgelagerten Aufgaben durchzuführen .- Um das Spielzeugbeispiel auszuführen, führen Sie
./examples/toy_examples/reddit_supervised.sh direkt aus.
Codenorm
Vorab festlegen
- Weitere Informationen finden Sie auf der offiziellen Website
-
.pre-commit-config.yaml : Erstellen Sie die Datei mit folgendem Inhalt für Python repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : black
-
pre-commit install : Installieren Sie Pre-Commit in Ihren Git-Hooks.- pre-commit wird jetzt bei jedem Commit ausgeführt.
- Jedes Mal, wenn Sie ein Projekt mit Pre-Commit klonen, sollte die Ausführung
pre-commit install immer das Erste sein, was Sie tun.
-
pre-commit run --all-files : Führt alle Pre-commit-Hooks in einem Repository aus -
pre-commit autoupdate : Aktualisieren Sie Ihre Hooks automatisch auf die neueste Version -
git commit -n : Überprüfungen vor dem Commit können mit dem Befehl für einen bestimmten Commit deaktiviert werden
Zitat
Wenn Sie diese Arbeit nützlich finden, zitieren Sie bitte folgende Dokumente:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}Kontakt
Qifang Zhao ([email protected])
Vielen Dank für Ihre Anregungen zu unserer Arbeit!
Lizenz
Veröffentlicht unter der MIT-Lizenz (siehe LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


