L2MAC
1.0.0
Pionierarbeit für das erste praktische LLM-basierte Allzweck-Automatik-Computer-Framework mit gespeicherten Programmen (von Neumann-Architektur) in einem LLM-basierten Multi-Agenten-System zur Lösung komplexer Aufgaben durch die Generierung umfangreicher und konsistenter Ausgaben, unabhängig von der festen Kontextfensterbeschränkung des LLM .
? Mai. 7. - 11. 2024: Wir werden L2MAC auf der International Conference on Learning Representations (ICLR) 2024 vorstellen. Treffen Sie uns bei ICLR in Wien, Österreich! Bitte kontaktieren Sie mich unter sih31 (at) cam.ac.uk, damit wir uns treffen können. Virtuelle Treffen sind ebenfalls möglich!
? April. 23. 2024: L2MAC ist mit der veröffentlichten ersten Version vollständig Open-Source.
16. Januar 2024: Der Beitrag L2MAC: Large Language Model Automatic Computer for Extensive Code Generation wird zur Präsentation auf der ICLR 2024 angenommen!
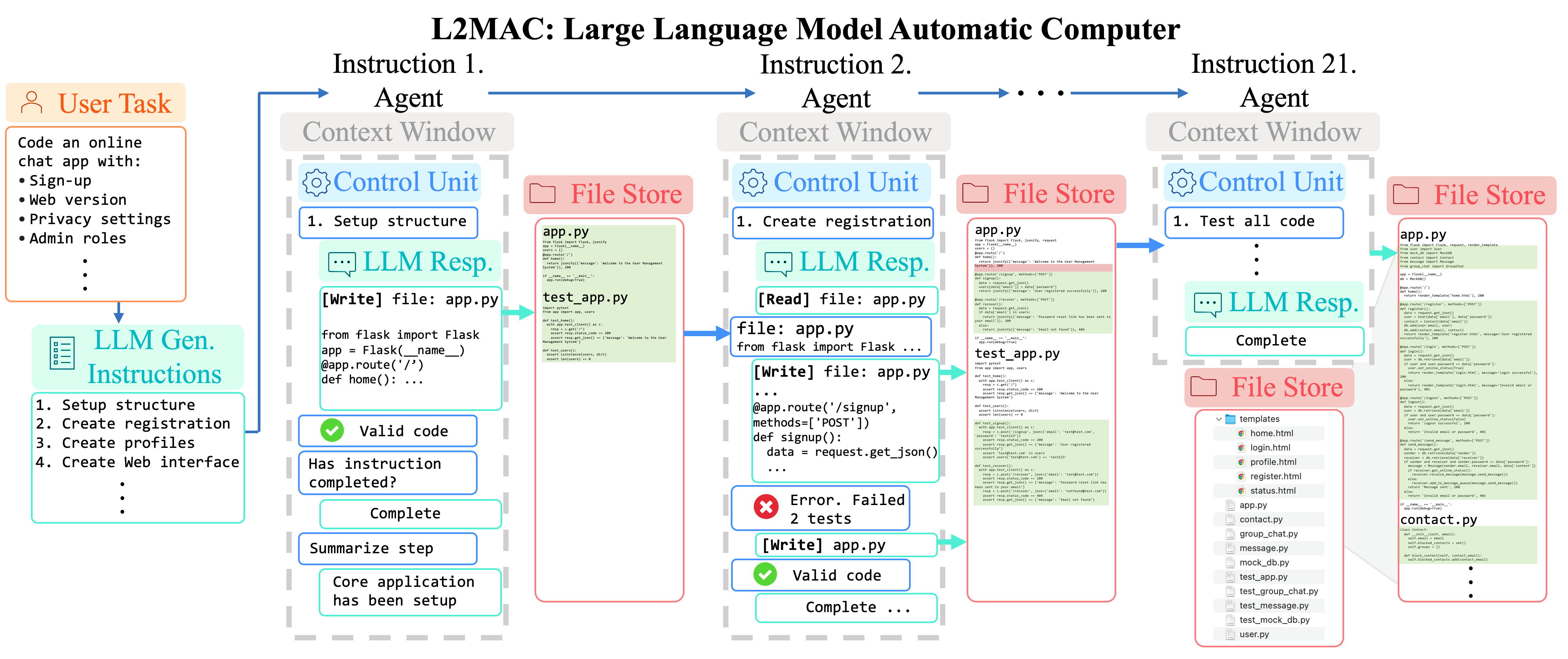
LLM-Automatic Computer (L2MAC)-Instanziierung zum Codieren einer großen komplexen Codebasis für eine gesamte Anwendung basierend auf einer einzigen Benutzeraufforderung . Hier stellen wir L2MAC zusätzliche Tools zur Verfügung, um den Code auf Syntaxfehler zu prüfen und etwaige Unit-Tests durchzuführen, falls vorhanden.
Stellen Sie sicher, dass Python 3.7+ auf Ihrem System installiert ist. Sie können dies überprüfen, indem Sie Folgendes verwenden:
python --version. Sie können Conda wie folgt verwenden:conda create -n l2mac python=3.9 && conda activate l2mac
pip install --upgrade l2mac
# or `pip install --upgrade git+https://github.com/samholt/l2mac`
# or `git clone https://github.com/samholt/l2mac && cd l2mac && pip install --upgrade -e .`Eine ausführliche Installationsanleitung finden Sie unter Installation
Sie können die Konfiguration von L2MAC starten, indem Sie den folgenden Befehl ausführen oder manuell die Datei ~/.L2MAC/config.yaml erstellen:
# Check https://samholt.github.io/L2MAC/guide/get_started/configuration.html for more details
l2mac --init-config # it will create ~/.l2mac/config.yaml, just modify it to your needs Sie können ~/.l2mac/config.yaml gemäß dem Beispiel und Dokument konfigurieren:
llm :
api_type : " openai " # or azure etc. Check ApiType for more options
model : " gpt-4-turbo-preview " # or "gpt-4-turbo"
base_url : " https://api.openai.com/v1 " # or forward url / other llm url
api_key : " YOUR_API_KEY "Nach der Installation können Sie die L2MAC-CLI verwenden
l2mac " Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid. " # this will create a codebase repo in ./workspaceoder nutzen Sie es als Bibliothek
from l2mac import generate_codebase
codebase : dict = generate_codebase ( "Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid." )
print ( codebase ) # it will print the codebase (repo) complete with all the files as a dictionary, and produce a local codebase folder in ./workspace? Treten Sie unserem Discord-Kanal bei! Ich freue mich darauf, Sie dort zu sehen! ?
Wenn Sie Fragen oder Feedback zu diesem Projekt haben, können Sie sich gerne an uns wenden. Wir freuen uns sehr über Ihre Vorschläge!
Wir werden alle Fragen innerhalb von 2-3 Werktagen beantworten.
Um über die neuesten Forschungs- und Entwicklungsergebnisse auf dem Laufenden zu bleiben, folgen Sie @samianholt auf Twitter.
Um L2MAC in Publikationen zu zitieren, verwenden Sie bitte den folgenden BibTeX-Eintrag.
@inproceedings {
holt2024lmac,
title = { L2{MAC}: Large Language Model Automatic Computer for Unbounded Code Generation } ,
author = { Samuel Holt and Max Ruiz Luyten and Mihaela van der Schaar } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=EhrzQwsV4K }
}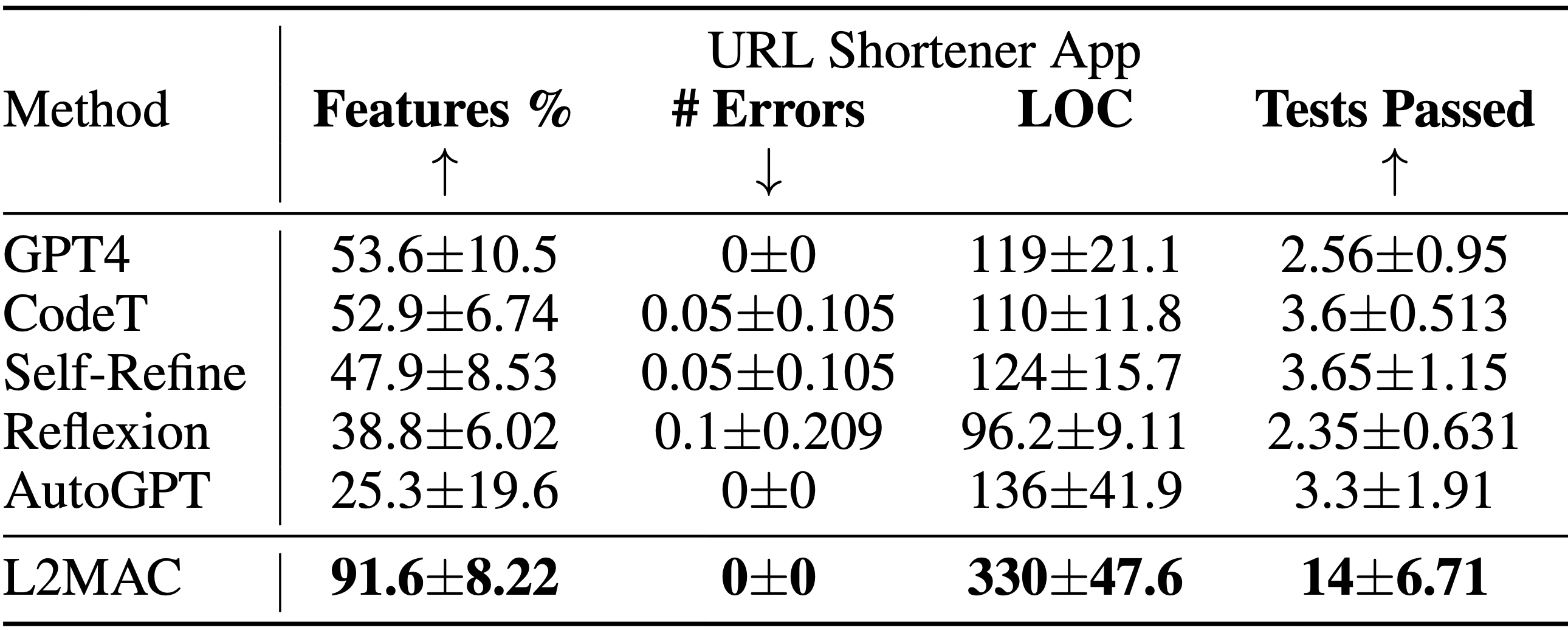
LLM-Automatic Computer (L2MAC)-Instanziierung zum Codieren einer großen komplexen Codebasis für eine gesamte Anwendung basierend auf einer einzigen Benutzeraufforderung . Die Ergebnisse der Systementwurfsaufgabe zur Codebasisgenerierung zeigen den Prozentsatz der angegebenen Funktionsmerkmale, die vollständig implementiert sind ( Features % ), die Anzahl der syntaktischen Fehler im generierten Code ( # Errors ), die Anzahl der Codezeilen ( LOC ) und die Anzahl der Bestehen von Tests ( Tests bestanden ). L2MAC implementiert den höchsten Prozentsatz an benutzerdefinierten Aufgabenfunktionsanforderungen über alle Aufgaben hinweg vollständig, indem es voll funktionsfähigen Code generiert, der minimale syntaktische Fehler und eine hohe Anzahl von selbst generierten Komponententests aufweist, und ist daher auf dem neuesten Stand der Technik Generierung großer Ausgabecodebasen und ähnlich wettbewerbsfähig für die Generierung großer Ausgabeaufgaben. Die Ergebnisse werden über 10 zufällig ausgewählte Samen gemittelt.
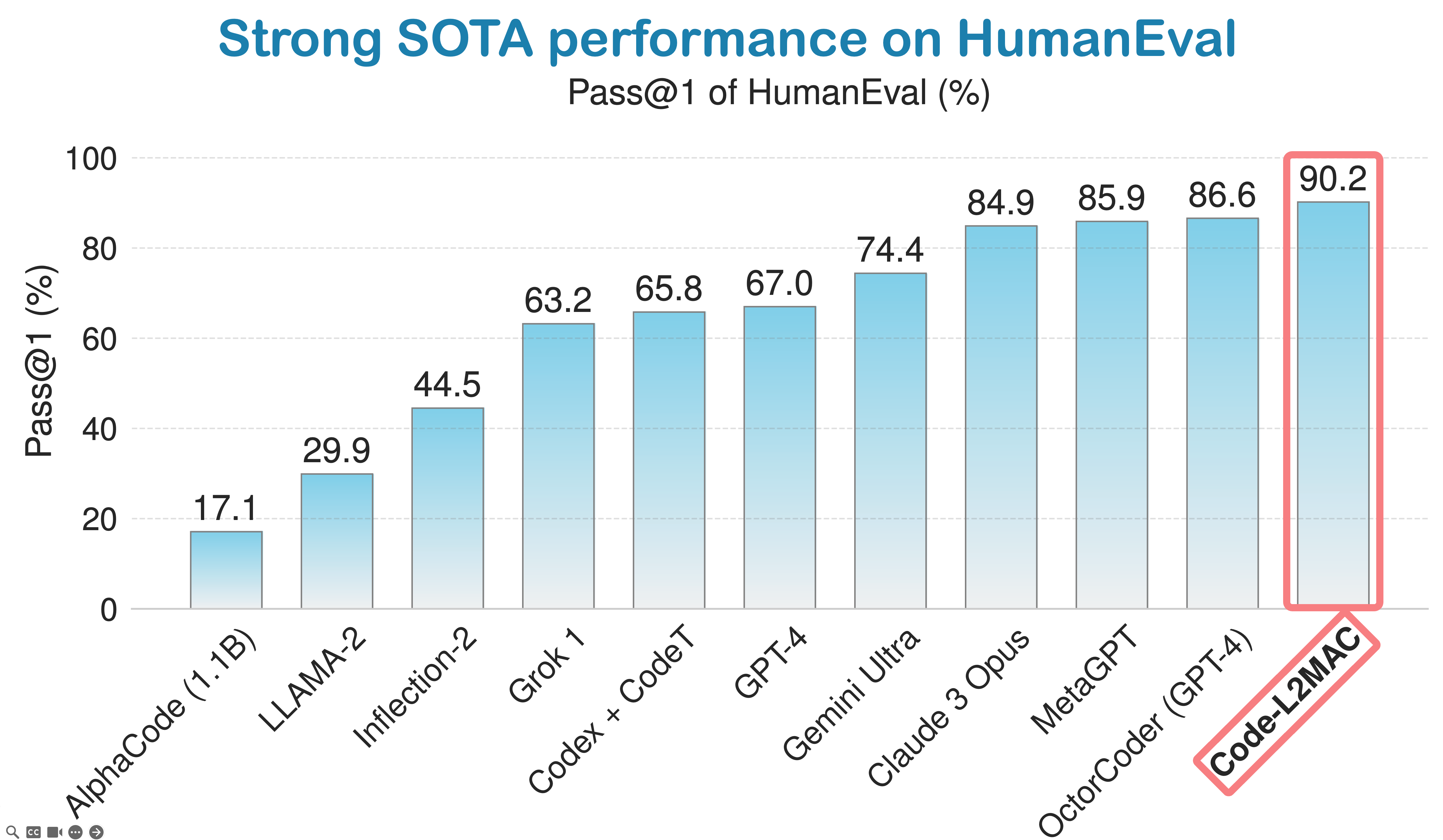
LLM-Automatic Computer (L2MAC) erzielt eine starke Leistung beim HumanEval-Coding-Benchmark und ist derzeit der drittbeste KI-Codierungsagent der Welt auf der globalen Bestenliste von HumanEval nach Industriestandard für Codierung.
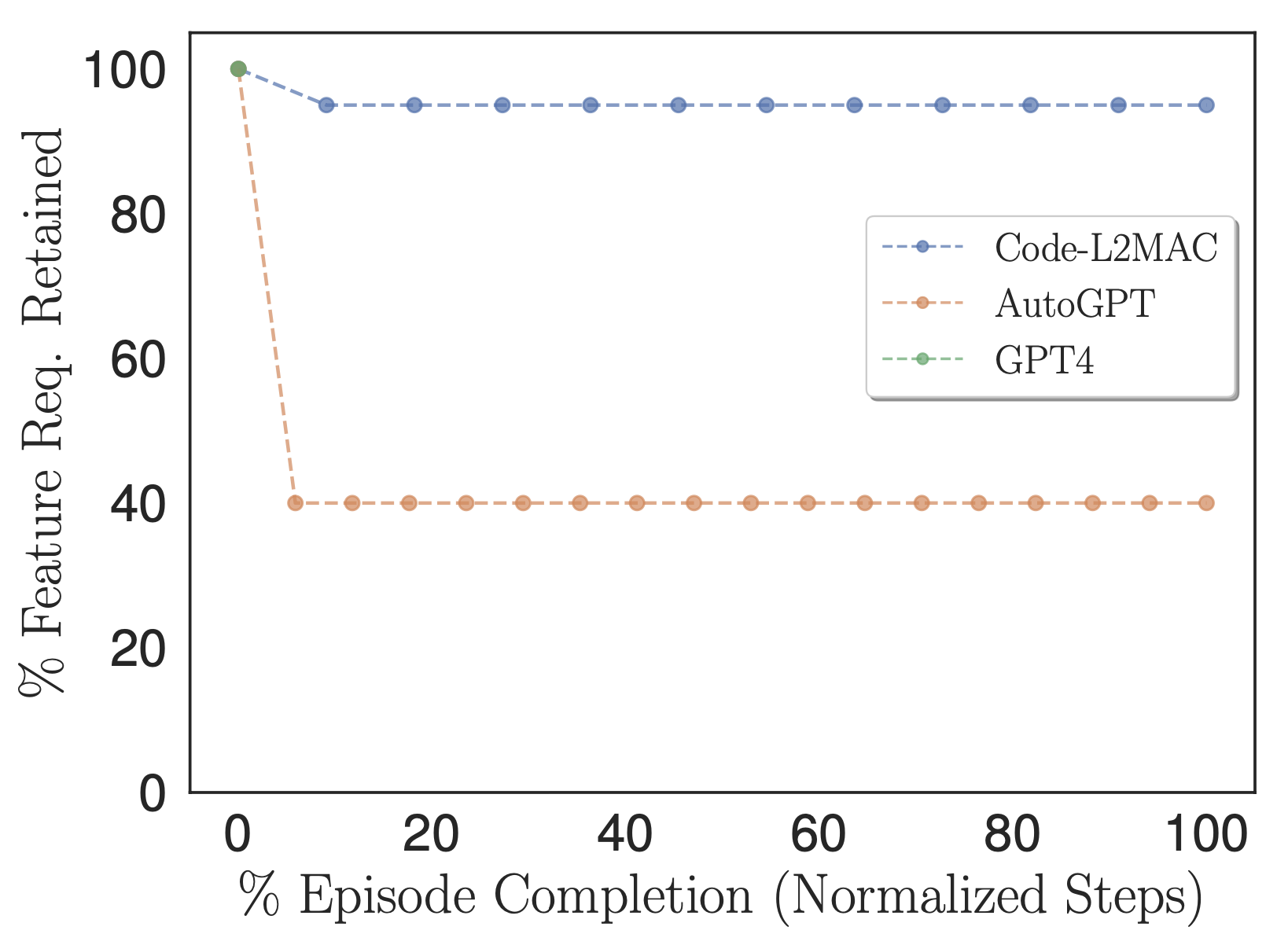
Prozentsatz der vom Benutzer angegebenen Funktionsanforderungen, die in den Methodenaufgabenanweisungen beibehalten und im Kontext verwendet werden.
Um zu untersuchen, ob die verglichenen Methoden während des Betriebs die Informationen in ihrem Kontext enthalten, um die Aufgabe direkt abzuschließen, haben wir unsere Metrik „Features %“ angepasst, um die Anzahl der benutzerdefinierten Aufgabenfunktionsanforderungen zu zählen, die stattdessen in den Aufgabenanweisungen der Methoden beibehalten werden, d. h. diese Anweisungen, die schließlich während des Betriebs in sein Kontextfenster eingespeist werden, wie in der obigen Abbildung dargestellt. Empirisch beobachten wir, dass L2MAC in der Lage ist, eine große Anzahl benutzerdefinierter Aufgabenfunktionsanforderungen in seinem Prompt-Programm beizubehalten und anweisungsorientierte Aufgaben mit langer Laufzeit auszuführen. Wir stellen fest, dass AutoGPT zunächst auch die vom Benutzer angegebenen Aufgabenfunktionsanforderungen in Aufgabenanweisungen übersetzt. Dies geschieht jedoch mit höherer Komprimierung, wodurch die Informationen zu einer Beschreibung mit lediglich sechs Sätzen zusammengefasst werden. Dieser Prozess führt zum Verlust wichtiger Aufgabeninformationen, die für die korrekte Erledigung der gesamten Aufgabe erforderlich sind, sodass diese mit der detaillierten, vom Benutzer angegebenen Aufgabe übereinstimmen.
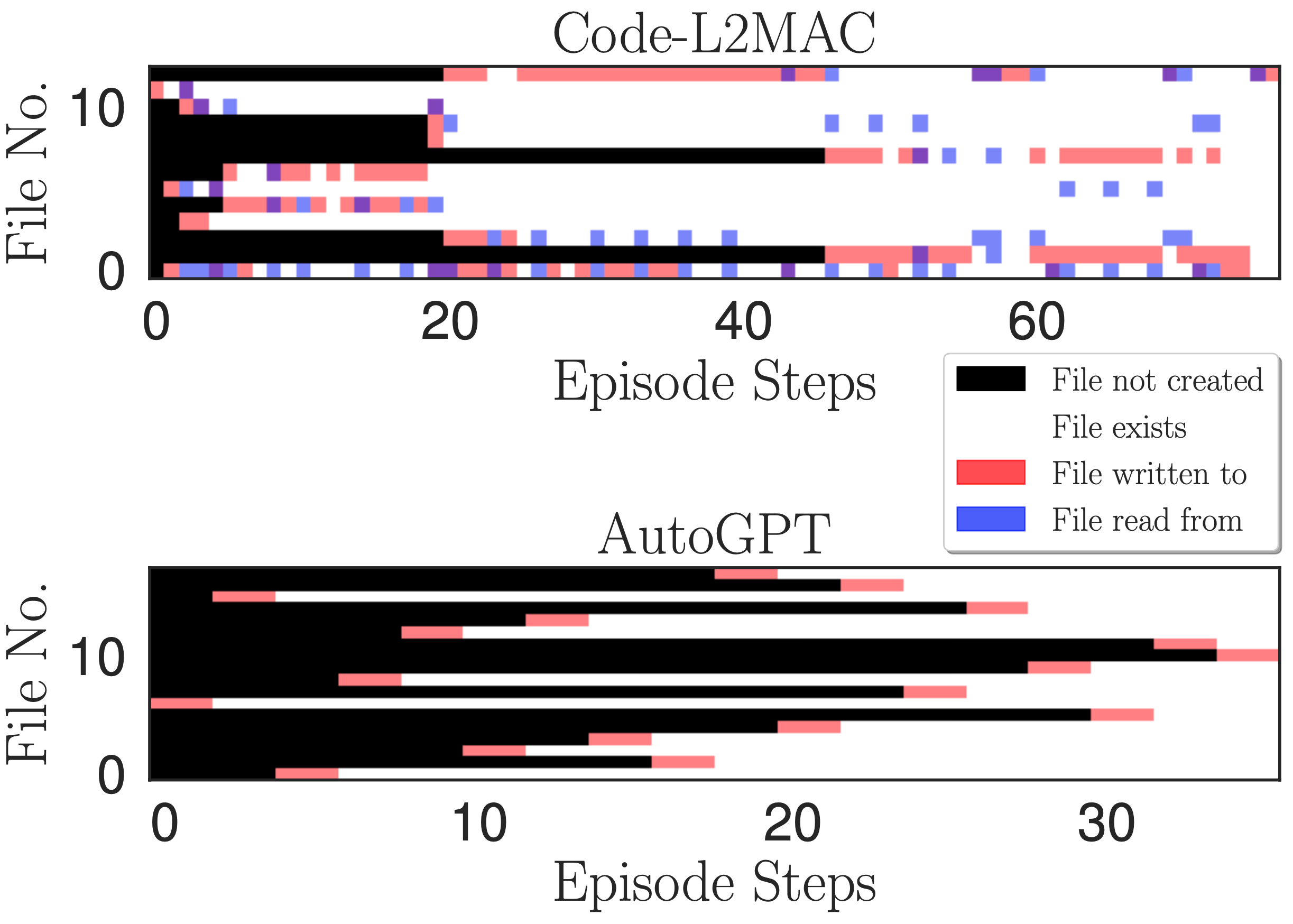
Heatmap des Dateizugriffs. Zeigt das Lesen, Schreiben und die Erstellung von Dateien bei jedem Schreibvorgangsschritt während einer Episode für die Online-Chat-App-Aufgabe an.
Wir möchten während der Ausführung einer Aufgabenanweisung verstehen, ob L2MAC die vorhandenen generierten Codedateien innerhalb der Codebasis verstehen kann – die vor vielen Anweisungen erstellt worden sein könnten – und durch sein Verständnis neue Dateien erstellen kann, die mit der Codebasis in Zusammenhang stehen Vorhandene Dateien aktualisieren und vor allem vorhandene Codedateien aktualisieren, wenn neue Funktionen implementiert werden. Um Erkenntnisse zu gewinnen, zeichnen wir in der obigen Abbildung eine Heatmap des Lesens, Schreibens und der Erstellung von Dateien bei jedem Schreibvorgangsschritt während einer Episode. Wir stellen fest, dass L2MAC über ein Verständnis des vorhandenen generierten Codes verfügt, das es ihm ermöglicht, vorhandene Codedateien zu aktualisieren, auch solche, die ursprünglich vor vielen Anweisungsschritten erstellt wurden, und die Dateien anzeigen kann, wenn dies nicht sicher ist, und die Dateien durch Schreiben in die Dateien zu aktualisieren. Im Gegensatz dazu schreibt AutoGPT Dateien oft nur einmal, nämlich bei der ersten Erstellung, und kann nur Dateien aktualisieren, von denen es weiß und die im aktuellen Kontextfenster beibehalten werden. Obwohl es auch über ein Tool zum Lesen von Dateien verfügt, vergisst es häufig die Dateien, die es vor vielen Iterationen erstellt hat, aufgrund seines Kontextfenster-Handhabungsansatzes, bei dem die ältesten Dialognachrichten in seinem Kontextfenster zusammengefasst werden, d. h. eine kontinuierliche verlustbehaftete Komprimierung des zuvor erzielten Fortschritts während des Betriebs zur Erledigung der Aufgabe.
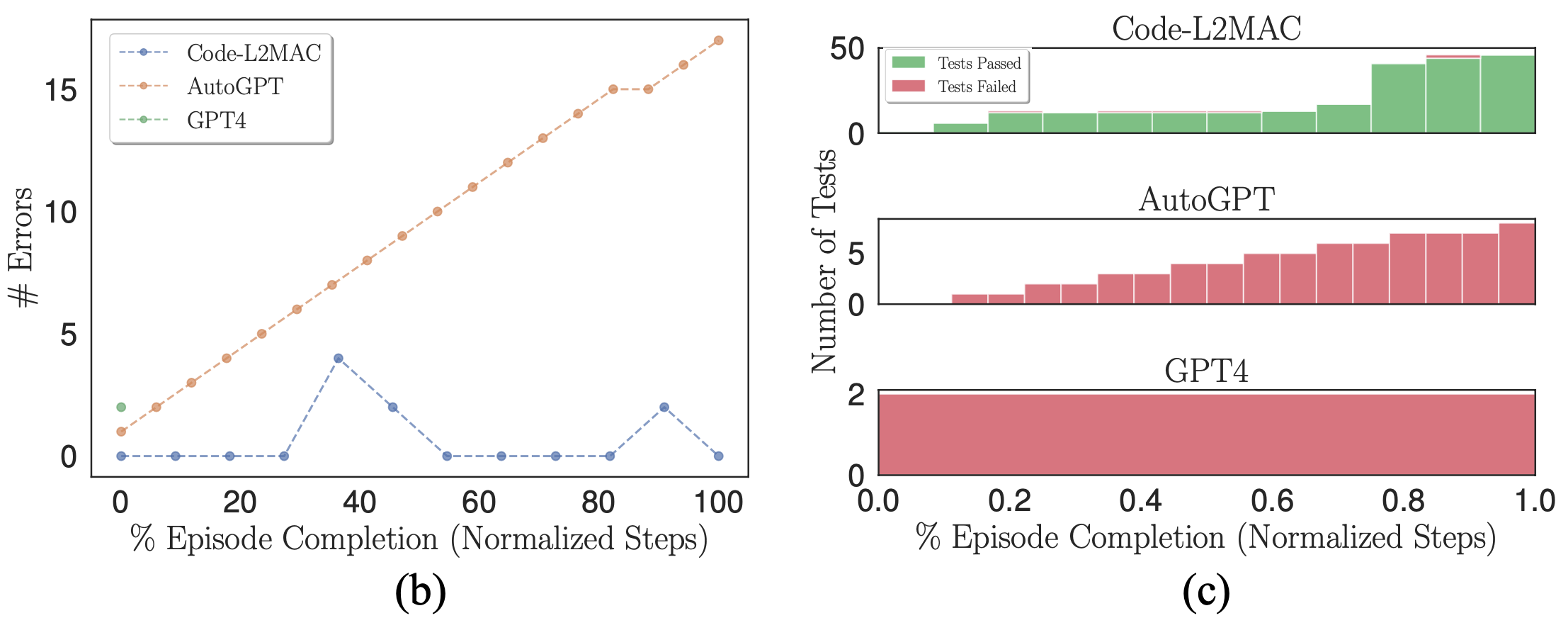
(b) Anzahl syntaktischer Fehler innerhalb der Codebasis. (c) Gestapelte Histogramme bestandener und nicht bestandener selbstgenerierter Komponententests.
Wenn ein probabilistisches Modell (LLM) als Generator für die Ausgabe von Code verwendet wird, können in seinen Ausgaben natürlich Fehler auftreten. Daher möchten wir überprüfen, ob die jeweiligen Benchmark-Methoden bei Auftreten von Fehlern die Codebasis fehlerkorrigieren können. In der obigen Abbildung (b) zeichnen wir die Anzahl der syntaktischen Fehler in der Codebasis während eines Laufs auf, bei dem Fehler gemacht werden. Wir stellen fest, dass L2MAC die zuvor generierte Codebasis, die Fehler enthält, korrekt korrigieren kann, was auf syntaktische Fehler in der zuletzt geschriebenen Datei oder auf andere Dateien zurückzuführen sein könnte, die von der zuletzt geschriebenen Datei abhängen und nun Fehler enthalten. Dazu wird die Fehlerausgabe angezeigt, wenn sie auftritt, und die Codebasis wird geändert, um den Fehler zu beheben, während gleichzeitig die aktuelle Anweisung ausgeführt wird. Im Gegensatz dazu kann AutoGPT nicht erkennen, wenn ein Fehler in der Codebasis gemacht wurde, und arbeitet weiter, was die Anzahl der Fehler, die sich innerhalb der Codebasis bilden, erhöhen kann.
Darüber hinaus generiert L2MAC neben dem Funktionscode auch Unit-Tests und verwendet diese als Fehlerprüfer, um die Funktionalitäten der Codebasis während der Generierung zu überprüfen. Mithilfe dieser Fehler kann die Codebasis so korrigiert werden, dass Unit-Tests bestanden werden, die nun nach der Aktualisierung eines Teils eines vorhandenen Codes fehlschlagen Datei. Wir zeigen dies in der obigen Abbildung (c) und stellen fest, dass AutoGPT zwar aufgefordert wird, auch Komponententests für den gesamten generierten Code zu schreiben, diese Tests jedoch nicht als Integritätsfehlerprüfung verwenden kann, was durch die Beobachtung, dass AutoGPT welche vergisst, noch verstärkt werden könnte Dateien, die zuvor erstellt wurden, und sind daher nicht in der Lage, die vorhandenen vergessenen Codedateien zu ändern, wenn neue Änderungen vorgenommen werden, was zu inkompatiblen Codedateien führt.
Wir präsentieren L2MAC, das erste LLM-basierte Allzweck-Computer-Framework für gespeicherte Programme, das LLMs effektiv und skalierbar um einen Speicher für lange Ausgabegenerierungsaufgaben erweitert, bei denen dies bisher nicht erfolgreich war. Insbesondere wenn L2MAC für lange Codegenerierungsaufgaben eingesetzt wird, übertrifft es bestehende Lösungen – und ist ein äußerst nützliches Werkzeug für die schnelle Entwicklung. Wir freuen uns über Beiträge und ermutigen Sie, das Projekt zu nutzen und zu zitieren. Klicken Sie hier, um loszulegen.
Wir bieten eine Galerie von Beispielanwendungen, die vollständig vom LLM Automatic Computer (L2MAC) über eine einzige Eingabeaufforderung erstellt wurden. L2MAC zeichnet sich dadurch aus, dass es große, komplexe Aufgaben löst, beispielsweise auf dem neuesten Stand der Technik bei der Generierung großer Codebasen ist, oder es kann sogar ganze Bücher schreiben, die alle die traditionellen Einschränkungen der festen Kontextfensterbeschränkung des LLM umgehen.
Geben Sie einfach l2mac "Create a beautiful, playable and simple snake game with pygame. Make the snake and food be aligned to the same 10-pixel grid." erhalten Sie eine vollständige Codebasis für ein vollständig spielbares Spiel, wie hier gezeigt.
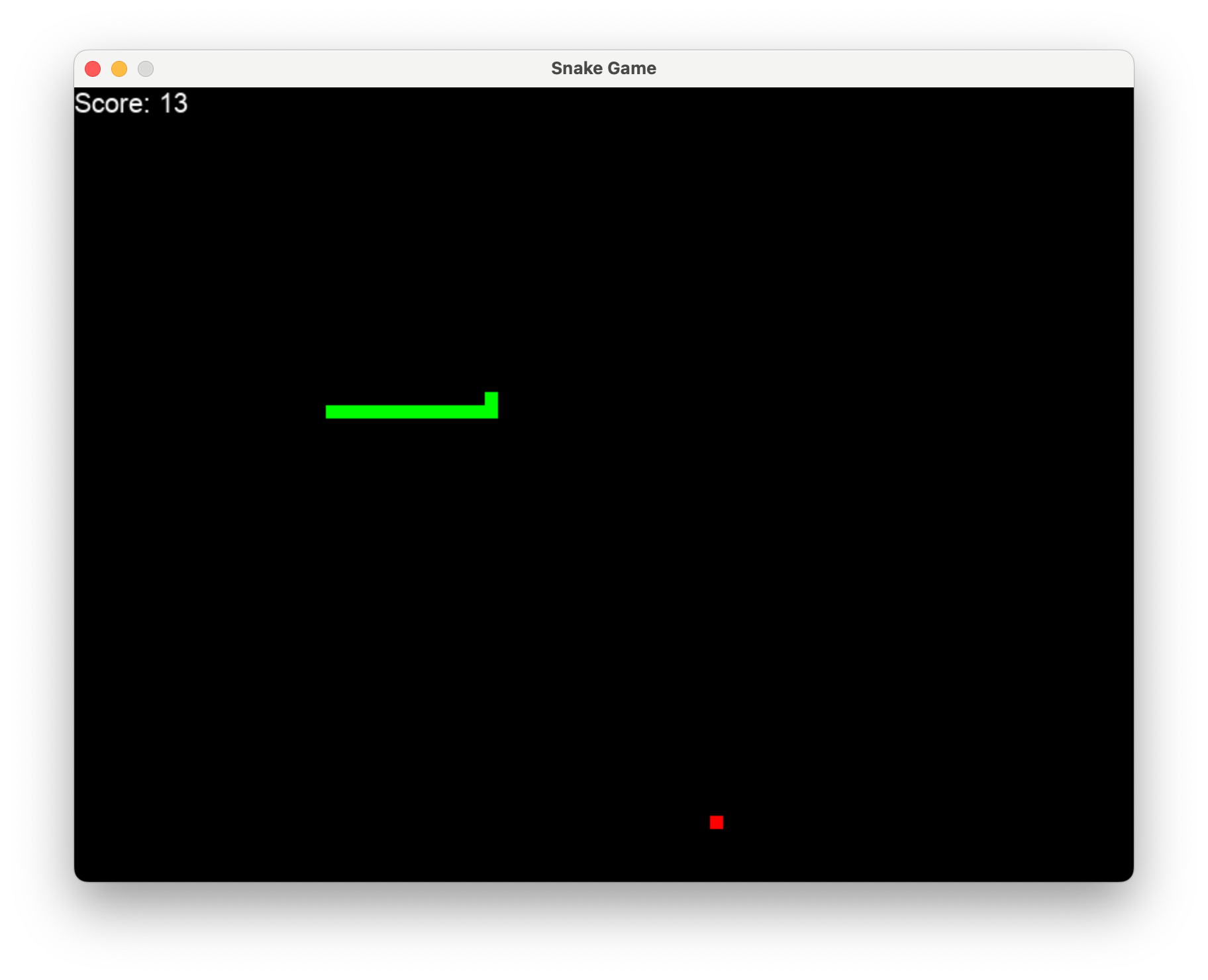
Klicken Sie hier für die vollständigen Dateien auf Github oder laden Sie sie hier herunter. Den Code und die Eingabeaufforderung zum Generieren finden Sie hier.
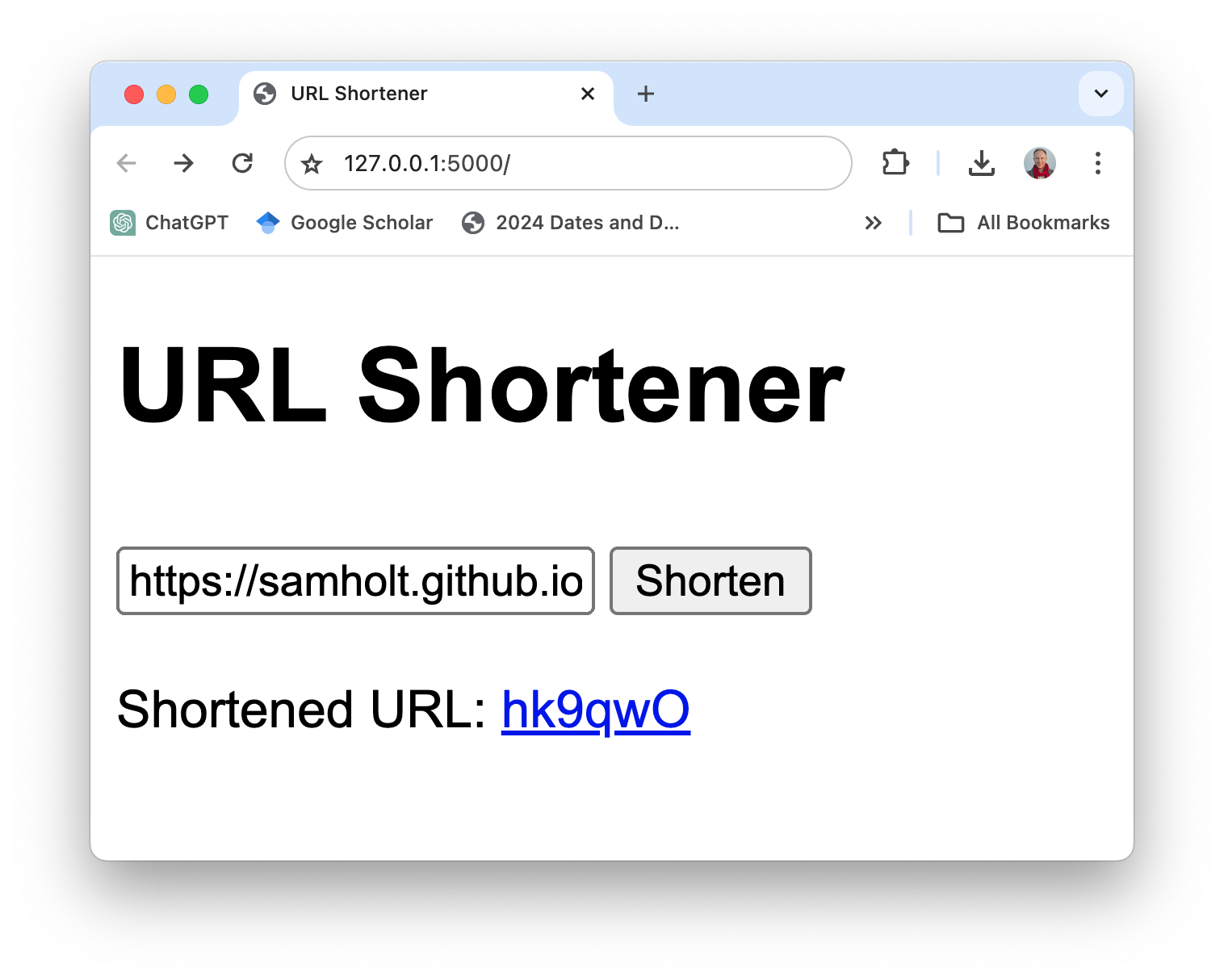
Klicken Sie hier für die vollständigen Dateien auf Github oder laden Sie sie hier herunter. Den Code und die Eingabeaufforderung zum Generieren finden Sie hier.
Geben Sie L2MAC einfach die Aufforderung, Write a complete recipe book for the following book title of "Twirls & Tastes: A Journey Through Italian Pasta". Description: "Twirls & Tastes" invites you on a flavorful expedition across Italy, exploring the diverse pasta landscape from the sun-drenched hills of Tuscany to the bustling streets of Naples. Discover regional specialties, learn the stories behind each dish, and master the art of pasta making with easy-to-follow recipes that promise to delight your senses. und es kann automatisch ein vollständiges Buch mit einer Länge von 26 Seiten erstellen.

Klicken Sie hier für das vollständige Buch; L2MAC produzierte den gesamten Text für das Buch und alle Bilder wurden mit DALLE erstellt.
Die vollständigen Ausgabetextdateien befinden sich auf Github. Sie können sie hier herunterladen. Den Code und die Eingabeaufforderung zum Generieren finden Sie hier.
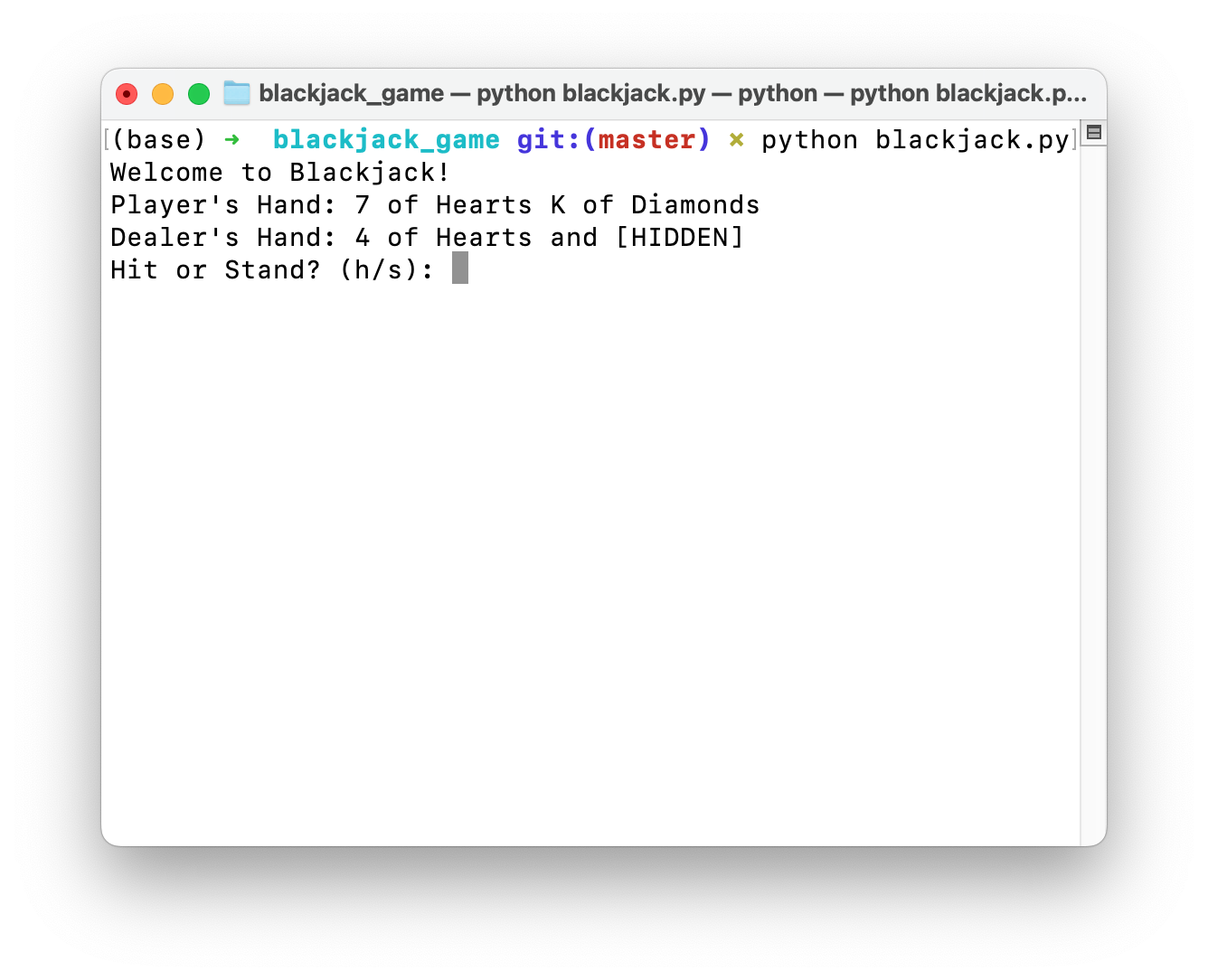
Klicken Sie hier für die vollständigen Dateien auf Github oder laden Sie sie hier herunter. Den Code und die Eingabeaufforderung zum Generieren finden Sie hier.
Wir sind aktiv auf der Suche nach Ihnen, um hier Ihre eigenen tollen Bewerbungen hochzuladen, indem Sie eine PR mit der von Ihnen erstellten Bewerbung einreichen, sie mit einem GitHub-Problem teilen oder sie auf dem Discord-Kanal teilen.


