YAYI2
1.0.0

[README] [?HF Repo] [?Webversion]
Chinesisch |. Englisch
[28.03.2024] Alle Modelle und Daten werden in die Magic Community hochgeladen.
[22.12.2023] Wir haben den technischen Bericht YAYI 2: Multilingual Open-Source Large Language Models veröffentlicht.
YAYI 2 ist ein von Zhongke Wenge entwickeltes Open-Source-Großsprachenmodell der neuen Generation , einschließlich Basis- und Chat-Versionen, mit einer Parametergröße von 30B. YAYI2-30B ist ein großes Sprachmodell, das auf Transformer basiert und für das Vortraining einen hochwertigen, mehrsprachigen Korpus von mehr als 2 Billionen Token verwendet. Für allgemeine und domänenspezifische Anwendungsszenarien verwenden wir Millionen von Anweisungen zur Feinabstimmung und verwenden Lernmethoden zur Verstärkung des menschlichen Feedbacks, um das Modell besser an menschlichen Werten auszurichten.
Das Open-Source-Modell ist dieses Mal das YAYI2-30B-Basismodell. Wir hoffen, die Entwicklung der chinesischen Open-Source-Community für vorab trainierte Großmodelle durch die Open Source von Yayi-Großmodellen zu fördern und aktiv dazu beizutragen. Durch Open Source arbeiten wir mit jedem Partner zusammen, um das Yayi-Ökosystem für große Modelle aufzubauen.
Weitere technische Details finden Sie in unserem technischen Bericht YAYI 2: Mehrsprachige Open-Source-Modelle für große Sprachen.
| Name des Datensatzes | Größe | ? HF-Modellidentifikation | Adresse herunterladen | Magisches Modelllogo | Adresse herunterladen |
|---|---|---|---|---|---|
| YAYI2 Pretrain-Daten | 500G | wenge-research/yayi2_pretrain_data | Datensatz-Download | wenge-research/yayi2_pretrain_data | Datensatz-Download |
| Modellname | Kontextlänge | ? HF-Modellidentifikation | Adresse herunterladen | Magisches Modelllogo | Adresse herunterladen |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | Wenge-Research/yayi2-30b | Modell-Download | Wenge-Research/yayi2-30b | Modell-Download |
| YAYI2-30B-Chat | 4096 | wenge-research/yayi2-30b-chat | Demnächst erhältlich... |
Wir haben Auswertungen für mehrere Benchmark-Datensätze durchgeführt, darunter C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval und MBPP. Wir untersuchten die Leistung des Modells in Bezug auf Sprachverständnis, Fachwissen, mathematisches Denken, logisches Denken und Codegenerierung. Das YAYI 2-Modell zeigt deutliche Leistungsverbesserungen gegenüber Open-Source-Modellen ähnlicher Größe.
| Fachwissen | Mathe | logisches Denken | Code | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Modell | C-Bewertung(Wert) | MMLU | AGIEval | CMMLU | GAOKAO-Bank | GSM8K | MATHE | BBH | HumanEval | MBPP |
| 5-Schuss | 5-Schuss | 3/0-Schuss | 5-Schuss | 0-Schuss | 8/4-Schuss | 4-Schuss | 3-Schuss | 0-Schuss | 3-Schuss | |
| MPT-30B | - | 46.9 | 33.8 | - | - | 15.2 | 3.1 | 38,0 | 25.0 | 32.8 |
| Falcon-40B | - | 55.4 | 37,0 | - | - | 19.6 | 5.5 | 37.1 | 0,6 | 29.8 |
| LLaMA2-34B | - | 62,6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33,0 |
| Baichuan2-13B | 59,0 | 59,5 | 37.4 | 61.3 | 45.6 | 52.6 | 10.1 | 49,0 | 17.1 | 30.8 |
| Qwen-14B | 71,7 | 67,9 | 51.9 | 70.2 | 62,5 | 61,6 | 25.2 | 53,7 | 32.3 | 39.8 |
| PraktikantLM-20B | 58,8 | 62.1 | 44.6 | 59,0 | 45,5 | 52.6 | 7.9 | 52,5 | 25.6 | 35.6 |
| Aquila2-34B | 98,5 | 76,0 | 43,8 | 78,5 | 37.8 | 50,0 | 17.8 | 42,5 | 0,0 | 41,0 |
| Yi-34B | 81,8 | 76,3 | 56,5 | 82,6 | 68,3 | 67,6 | 15.9 | 66,4 | 26.2 | 38.2 |
| YAYI2-30B | 80,9 | 80,5 | 62,0 | 84,0 | 64,4 | 71.2 | 14.8 | 54,5 | 53.1 | 45,8 |
Wir haben unsere Evaluierung mit dem Quellcode durchgeführt, der vom OpenCompass Github-Repository bereitgestellt wurde. Für Vergleichsmodelle listen wir deren Bewertungsergebnisse auf der OpenCompass-Liste mit Stand vom 15. Dezember 2023. Für andere Modelle, die nicht an der Evaluierung auf der OpenCompass-Plattform teilgenommen haben, darunter MPT, Falcon und LLaMa 2, haben wir die von LLaMA 2 gemeldeten Ergebnisse übernommen.
Wir stellen einfache Beispiele zur Verfügung, um zu veranschaulichen, wie YAYI2-30B schnell für Inferenzen verwendet werden kann. Dieses Beispiel kann auf einem einzelnen A100/A800 ausgeführt werden.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envBitte beachten Sie, dass für dieses Projekt Python 3.8 oder höher erforderlich ist.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))Bei Ihrem ersten Besuch muss das Modell heruntergeladen und geladen werden, was einige Zeit dauern kann.
Dieses Projekt unterstützt die Feinabstimmung von Anweisungen basierend auf dem verteilten Trainingsframework Deepspeed. Konfigurieren Sie die Umgebung und führen Sie das entsprechende Skript aus, um die Feinabstimmung der vollständigen Parameter oder die LoRA-Feinabstimmung zu starten.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps Datenformat: Siehe data/yayi_train_example.json , eine Standard "conversations" JSON-Datei. Jedes Datenelement besteht aus "system" und "conversations" , wobei "system" die globalen Rolleneinstellungsinformationen ist und eine leere Zeichenfolge sein kann. "conversations" sind mehrere Dialogrunden zwischen menschlichen und Yayi-Charakteren.
Betriebsanweisungen: Führen Sie den folgenden Befehl aus, um die Feinabstimmung der vollständigen Parameter des Yayi-Modells zu starten. Dieser Befehl unterstützt das Training mit mehreren Maschinen und mehreren Karten. Es wird empfohlen, eine Hardwarekonfiguration mit 16 * A100 (80 G) oder höher zu verwenden.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True Oder starten Sie über die Befehlszeile:
bash scripts/start.sh Bitte beachten Sie, dass Sie, wenn Sie die ChatML-Vorlage zur Feinabstimmung von Anweisungen verwenden müssen, --module training.trainer_yayi2 im Befehl in --module training.trainer_chatml ändern können. Wenn Sie die Chat-Vorlage anpassen müssen, können Sie diese ändern das System in der Chat-Vorlage von trainer_chatml.py Spezielle Token-Definitionen für die drei Rollen , Benutzer und Assistent. Das Folgende ist ein Beispiel für eine ChatML-Vorlage. Wenn diese Vorlage oder eine benutzerdefinierte Vorlage während des Trainings verwendet wird, muss sie auch während der Inferenz konsistent sein.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh In der Vortrainingsphase haben wir nicht nur Internetdaten verwendet, um die Sprachfähigkeiten des Modells zu trainieren, sondern auch allgemeine ausgewählte Daten und Domänendaten hinzugefügt, um die beruflichen Fähigkeiten des Modells zu verbessern. Die Datenverteilung ist wie folgt: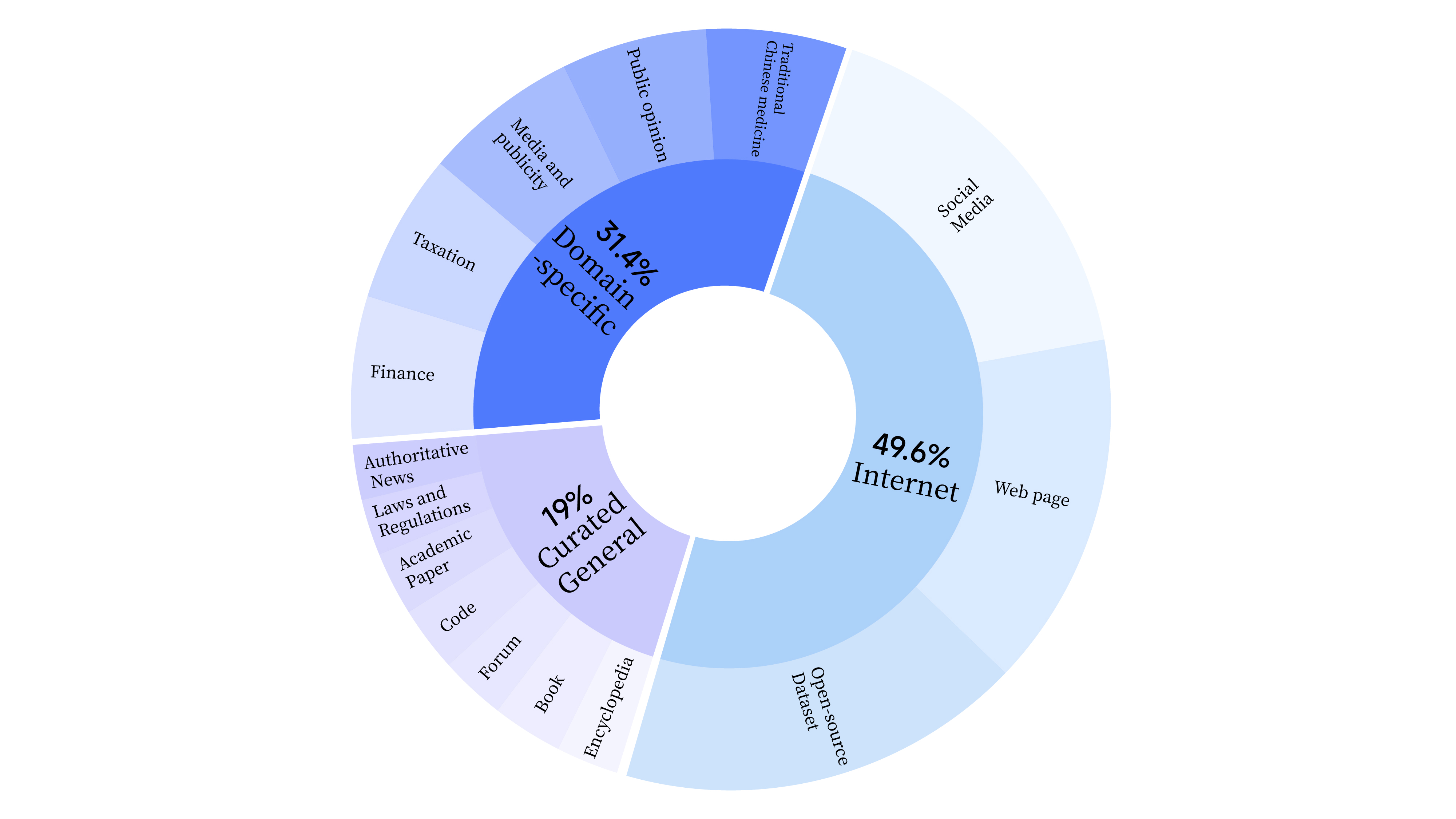
Wir haben eine Reihe von Datenverarbeitungspipelines aufgebaut, um die Datenqualität in allen Aspekten zu verbessern, einschließlich vier Modulen: Standardisierung, heuristische Bereinigung, mehrstufige Deduplizierung und Toxizitätsfilterung. Wir haben insgesamt 240 TB Rohdaten gesammelt und nach der Vorverarbeitung blieben nur 10,6 TB hochwertige Daten übrig. Der Gesamtprozess ist wie folgt: 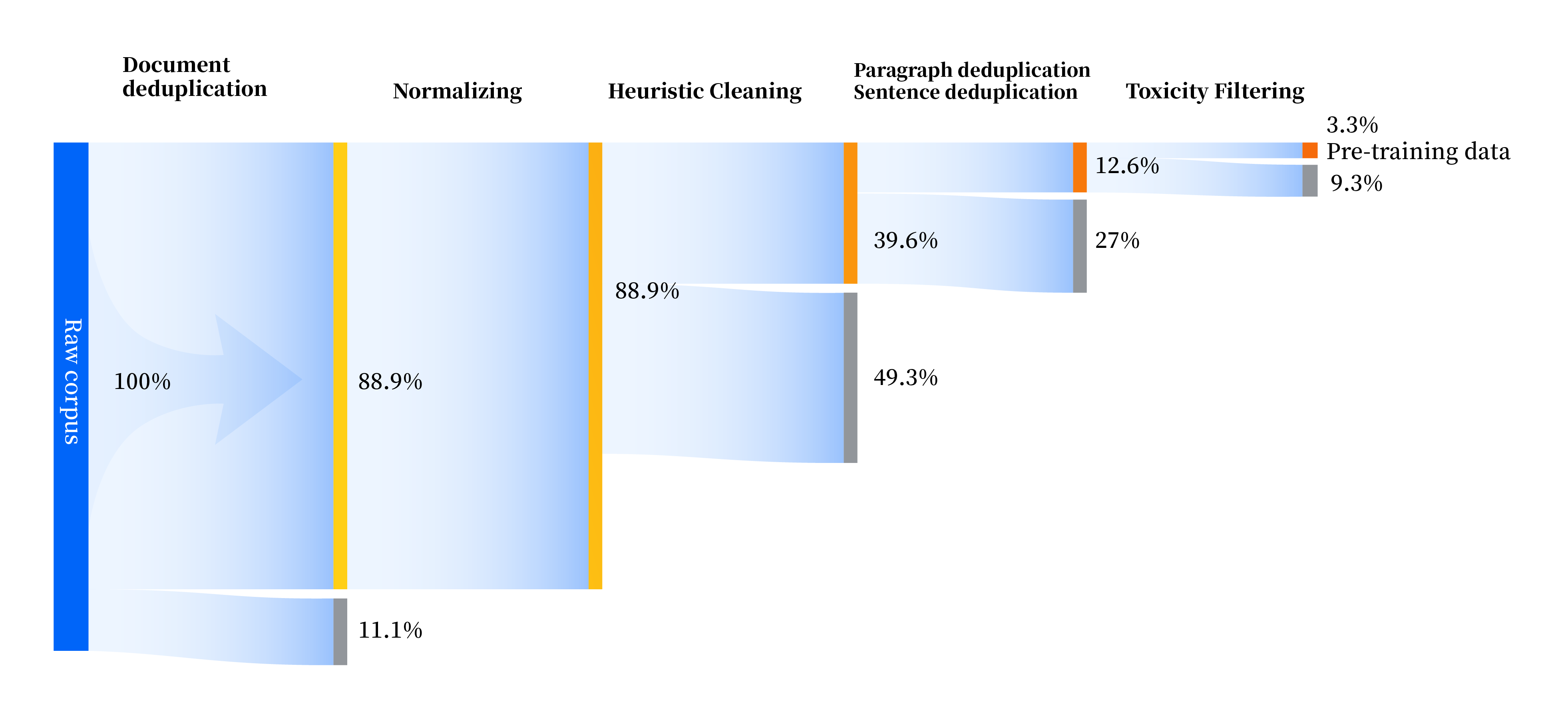

Die Verlustkurve des YAYI 2-Modells ist in der folgenden Abbildung dargestellt: 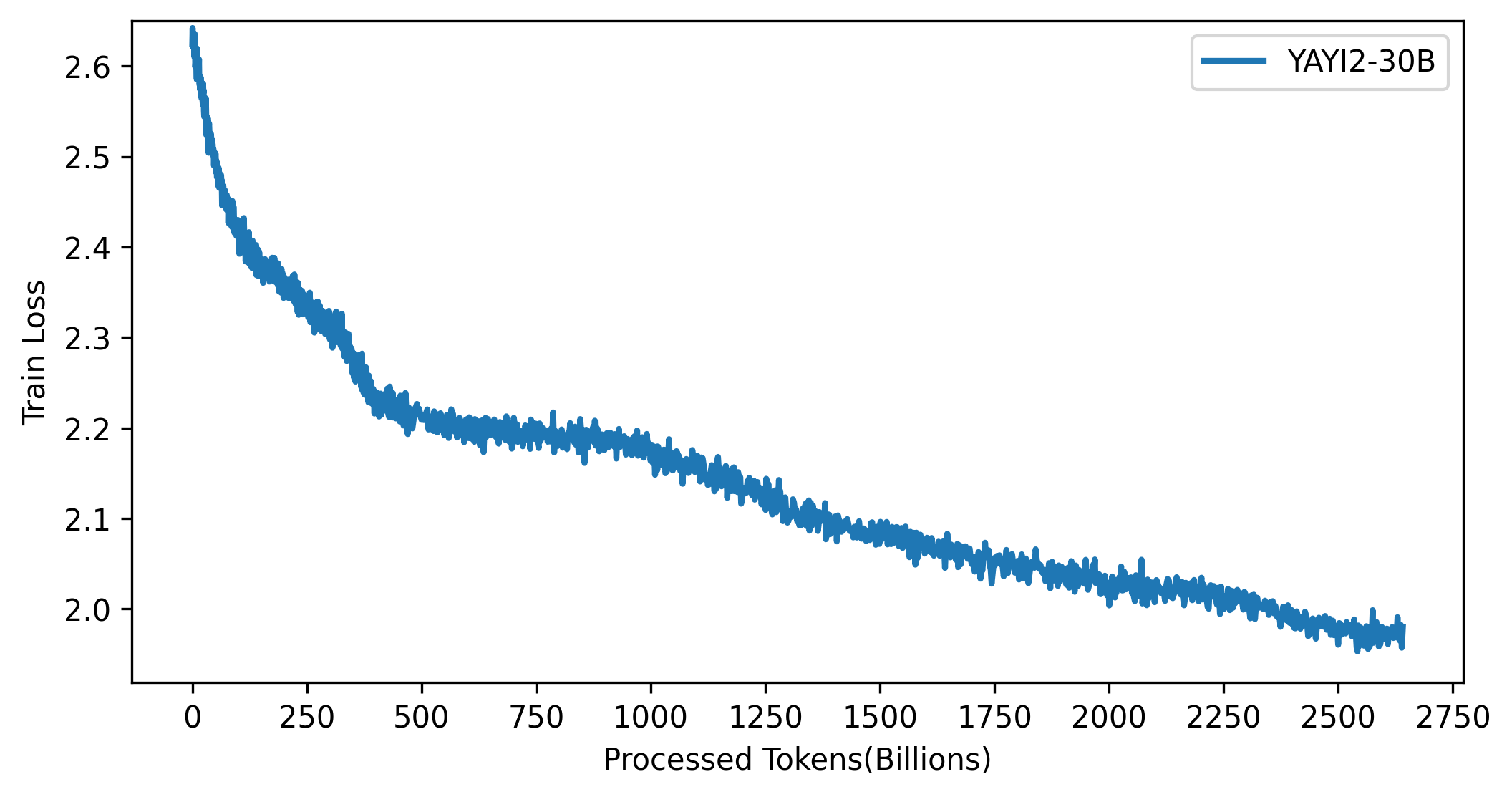
Der Code in diesem Projekt ist Open Source und entspricht dem Apache-2.0-Protokoll. Die Nutzung des YAYI 2-Modells und der Daten durch die Community muss der „Yayi YAYI 2 Model Community-Lizenzvereinbarung“ entsprechen. Wenn Sie die Modelle der YAYI 2-Serie oder deren Derivate für kommerzielle Zwecke nutzen müssen, füllen Sie bitte die „Informationen zur kommerziellen Registrierung des YAYI 2-Modells“ aus und senden Sie diese an [email protected]. Wir werden Sie innerhalb von 3 Werktagen nach Erhalt der E-Mail kontaktieren . Die Prüfung erfolgt täglich. Nach bestandener Prüfung erhalten Sie eine kommerzielle Lizenz. Bitte halten Sie sich bei der Nutzung strikt an die entsprechenden Inhalte der „YAYI 2 Model Commercial License Agreement“.
Wenn Sie unser Modell in Ihrer Arbeit verwenden, zitieren Sie bitte unseren Artikel:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


