Transformer Architectures From Scratch
1.0.0
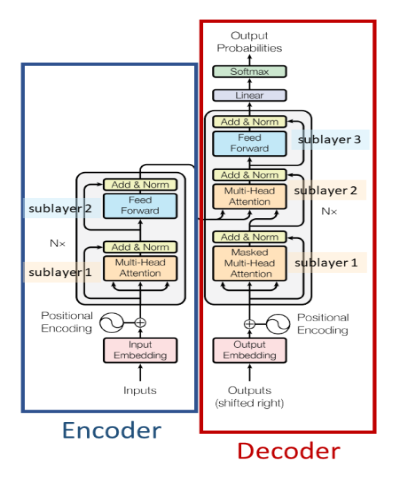
Eine auf Selbstaufmerksamkeit basierende Encoder-Decoder-Architektur. Es wird hauptsächlich für verwendet
Papier – https://arxiv.org/abs/1706.03762
Eine auf Selbstaufmerksamkeit basierende Encoder-Architektur. Es wird hauptsächlich für verwendet
Papier – https://arxiv.org/abs/1810.04805
Ein auf Selbstaufmerksamkeit basierendes Decoder-basiertes autoregressives Modell. Es wird hauptsächlich für verwendet
Papier – https://paperswithcode.com/method/gpt
Ein auf Selbstaufmerksamkeit basierendes, auf einem Decoder basierendes autoregressives Modell mit einer geringfügigen Änderung in der Architektur, das auf einem größeren Textkorpus als GPT-1 trainiert wurde. Es wird hauptsächlich für verwendet
Papier – https://d4mucfpksywv.cloudfront.net/better-Language-Models/Language-Models.pdf
Eine hochmoderne, auf Selbstaufmerksamkeit basierende Encoder-Architektur für Computer-Vision-Anwendungen. Es wird hauptsächlich für verwendet
Papier – https://arxiv.org/abs/2006.03677
Eine auf Selbstaufmerksamkeit basierende Encoder-Decoder-Architektur mit einer linearen Zeitkomplexität, anders als der Transformator, der eine quadratische Zeitkomplexität aufweist. Es wird meistens verwendet
Papier – https://arxiv.org/abs/2009.14794


