Copulas
v0.12.0 - 2024-11-12
Dieses Repository ist Teil des Synthetic Data Vault Project, einem Projekt von DataCebo.

Copulas ist eine Python-Bibliothek zur Modellierung multivariater Verteilungen und deren Stichprobenziehung mithilfe von Copula-Funktionen. Verwenden Sie bei einer gegebenen Tabelle mit numerischen Daten Copulas, um die Verteilung zu lernen und neue synthetische Daten zu generieren, die denselben statistischen Eigenschaften folgen.
Hauptmerkmale:
Modellieren Sie multivariate Daten. Wählen Sie aus einer Vielzahl univariater Verteilungen und Copulas – einschließlich archimedischer Copulas, Gaußscher Copulas und Vine Copulas.
Vergleichen Sie reale und synthetische Daten visuell, nachdem Sie Ihr Modell erstellt haben. Visualisierungen sind als 1D-Histogramme, 2D-Streudiagramme und 3D-Streudiagramme verfügbar.
Auf gelernte Parameter zugreifen und diese bearbeiten. Mit vollständigem Zugriff auf die Interna des Modells können Sie die Parameter nach Ihren Wünschen einstellen oder anpassen.
Installieren Sie die Copulas-Bibliothek mit pip oder conda.
pip install copulasconda install -c conda-forge copulasBeginnen Sie mit der Verwendung eines Demodatensatzes. Dieser Datensatz enthält 3 numerische Spalten.
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()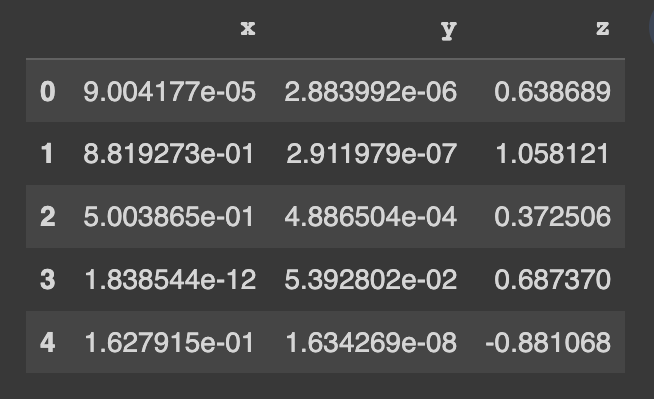
Modellieren Sie die Daten mithilfe einer Copula und erstellen Sie daraus synthetische Daten. Die Copulas-Bibliothek bietet viele Optionen, darunter Gaussian Copula, Vine Copulas und Archimedian Copulas.
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))Visualisieren Sie die realen und synthetischen Daten nebeneinander. Machen wir das in 3D, also sehen Sie sich unseren vollständigen Datensatz an.
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )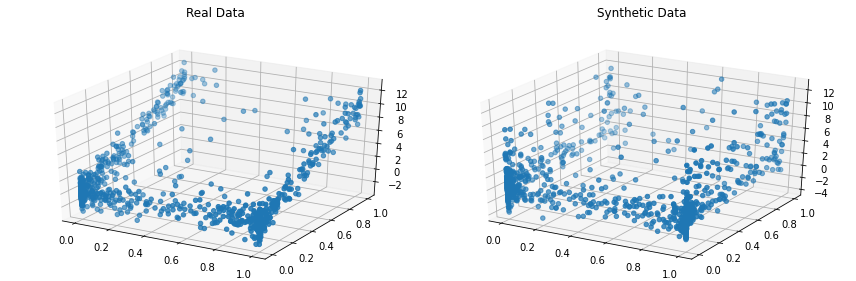
Klicken Sie unten, um den Code selbst auf einem Colab Notebook auszuführen und neue Funktionen zu entdecken.
Erfahren Sie mehr über die Copulas-Bibliothek auf unserer Dokumentationsseite.
Fragen oder Probleme? Treten Sie unserem Slack-Kanal bei, um mehr über Copulas und synthetische Daten zu diskutieren. Wenn Sie einen Fehler finden oder eine Funktionsanfrage haben, können Sie auch ein Problem auf unserem GitHub eröffnen.
Möchten Sie einen Beitrag zu Copulas leisten? Lesen Sie unseren Beitragsleitfaden, um loszulegen.
Das Open-Source-Projekt Copulas startete erstmals 2018 im Data to AI Lab am MIT. Vielen Dank an unser Team von Mitwirkenden, die die Bibliothek im Laufe der Jahre aufgebaut und gepflegt haben!
Mitwirkende anzeigen

Das Synthetic Data Vault-Projekt wurde erstmals 2016 im Data to AI Lab des MIT ins Leben gerufen. Nach vier Jahren Forschung und Zusammenarbeit mit Unternehmen gründeten wir 2020 DataCebo mit dem Ziel, das Projekt auszubauen. Heute ist DataCebo stolzer Entwickler von SDV, dem größten Ökosystem für die Generierung und Auswertung synthetischer Daten. Es beherbergt mehrere Bibliotheken, die synthetische Daten unterstützen, darunter:
Beginnen Sie mit der Nutzung des SDV-Pakets – einer vollständig integrierten Lösung und Ihrem One-Stop-Shop für synthetische Daten. Oder nutzen Sie die eigenständigen Bibliotheken für spezifische Anforderungen.


