feedgen
1.0.0
Haftungsausschluss: Dies ist kein offizielles Google-Produkt.
FeedGen funktioniert am besten für bis zu 30.000 Artikel. Möchten Sie weiter skalieren? Steigen Sie mit der Product Studio API Alpha ein (wenden Sie sich an [email protected]) oder erwägen Sie die Verarbeitung Ihres Feeds in BigQuery.
Überblick • Erste Schritte • Was es löst • Wie es funktioniert • Wie man einen Beitrag leistet • Community Spotlight
gemini-1.5-pro und gemini-1.5-flash hinzugefügtstructured_title und structured_description anstelle von title bzw. description . Weitere Informationen finden Sie in dieser Anleitung.gemini-1.5-pro-preview-0409 . Bitte beachten Sie, dass sich der Modellname in Zukunft (bahnbrechend) ändern kann.gemini-1.0-pro und gemini-1.0-pro-vision umbenanntgemini-pro und gemini-pro-vision ) hinzugefügtgemini-pro-vision )v1 verschoben und auf JS/TS auf main umgestellt FeedGen ist ein Open-Source-Tool, das die hochmodernen Large Language Models (LLMs) von Google Cloud nutzt, um Produkttitel zu verbessern, umfassendere Beschreibungen zu generieren und fehlende Attribute in Produkt-Feeds zu ergänzen. Es hilft Händlern und Werbetreibenden dabei, Qualitätsprobleme in ihren Feeds mithilfe generativer KI auf einfache und konfigurierbare Weise aufzudecken und zu beheben.
Das Tool basiert auf der Vertex AI API von GCP, um sowohl Zero-Shot- als auch Fow-Shot-Inferenzfunktionen für die grundlegenden LLMs von GCP bereitzustellen. Bei der Eingabeaufforderung mit wenigen Schüssen verwenden Sie die besten 3–10 Beispiele aus Ihrem eigenen Shopping-Feed, um die Antworten des Modells auf Ihre eigenen Daten anzupassen und so eine höhere Qualität und eine konsistentere Ausgabe zu erzielen. Dies kann weiter optimiert werden, indem Sie die grundlegenden Modelle mit Ihren eigenen proprietären Daten verfeinern. Erfahren Sie in diesem Leitfaden, wie Sie Modelle mit Vertex AI optimieren und welche Vorteile dies mit sich bringt.
Hinweis: Bitte überprüfen Sie, ob Ihre Ziel-Feed-Sprache eine der von Vertex AI unterstützten Sprachen ist, bevor Sie FeedGen verwenden, und wenden Sie sich andernfalls an Ihren Google Cloud- oder Account-Vertreter.
Um mit FeedGen zu beginnen:
Getting Started “. Die Optimierung von Shopping-Feeds ist ein Ziel für jeden Werbetreibenden, der mit dem Google Merchant Center (MC) arbeitet, um die Abfrageübereinstimmung zu verbessern, die Abdeckung zu erhöhen und letztendlich die Klickraten (CTR) zu erhöhen. Allerdings ist es mühsam, Produktablehnungen in MC zu sichten oder Qualitätsprobleme manuell zu beheben.
FeedGen geht dieses Problem mithilfe der generativen KI an und ermöglicht es Benutzern, Qualitätsprobleme automatisch aufzudecken und zu beheben sowie Attributlücken in ihren Feeds zu schließen.
FeedGen ist eine auf Apps Script basierende Anwendung, die als HTML-Seitenleiste (Einzelheiten finden Sie unter HtmlService) in Google Sheets ausgeführt wird. Die ganze Magie geschieht in der zugehörigen Google Sheets-Tabellenvorlage. Es enthält den Eingabe-Feed, der optimiert werden muss, sowie spezifische Konfigurationswerte, die steuern, wie Inhalte generiert werden. Die Tabelle wird auch sowohl für die (optionale) menschliche Validierung als auch für die Einrichtung eines Zusatzfeeds im Google Merchant Center (MC) verwendet.
Generative Sprache ist in Vertex AI und im Allgemeinen eine im Entstehen begriffene Funktion/Technologie. Wir empfehlen dringend, die generierten Titel und Beschreibungen manuell zu überprüfen und zu verifizieren. FeedGen hilft Benutzern, diesen Prozess zu beschleunigen, indem es sowohl für Titel als auch für Beschreibungen (zusammen mit detaillierten Komponenten) eine Bewertung bereitstellt, die angibt, wie „gut“ der generierte Inhalt ist, sowie eine Sheets-native Möglichkeit zur Massengenehmigung generierter Inhalte über Datenfilter.
Erstellen Sie zunächst eine Kopie der Vorlagentabelle und befolgen Sie die Anweisungen im Abschnitt „Erste Schritte“ . Der erste Schritt besteht darin, sich wie unten gezeigt über die Schaltfläche „Initialisieren“ bei der Apps Script-Umgebung zu authentifizieren.

Navigieren Sie anschließend zum Konfigurationsarbeitsblatt , um Feed-Einstellungen, Vertex AI API-Einstellungen (einschließlich einer Schätzung der anfallenden Kosten) und Einstellungen zur Steuerung der Inhaltsgenerierung zu konfigurieren.
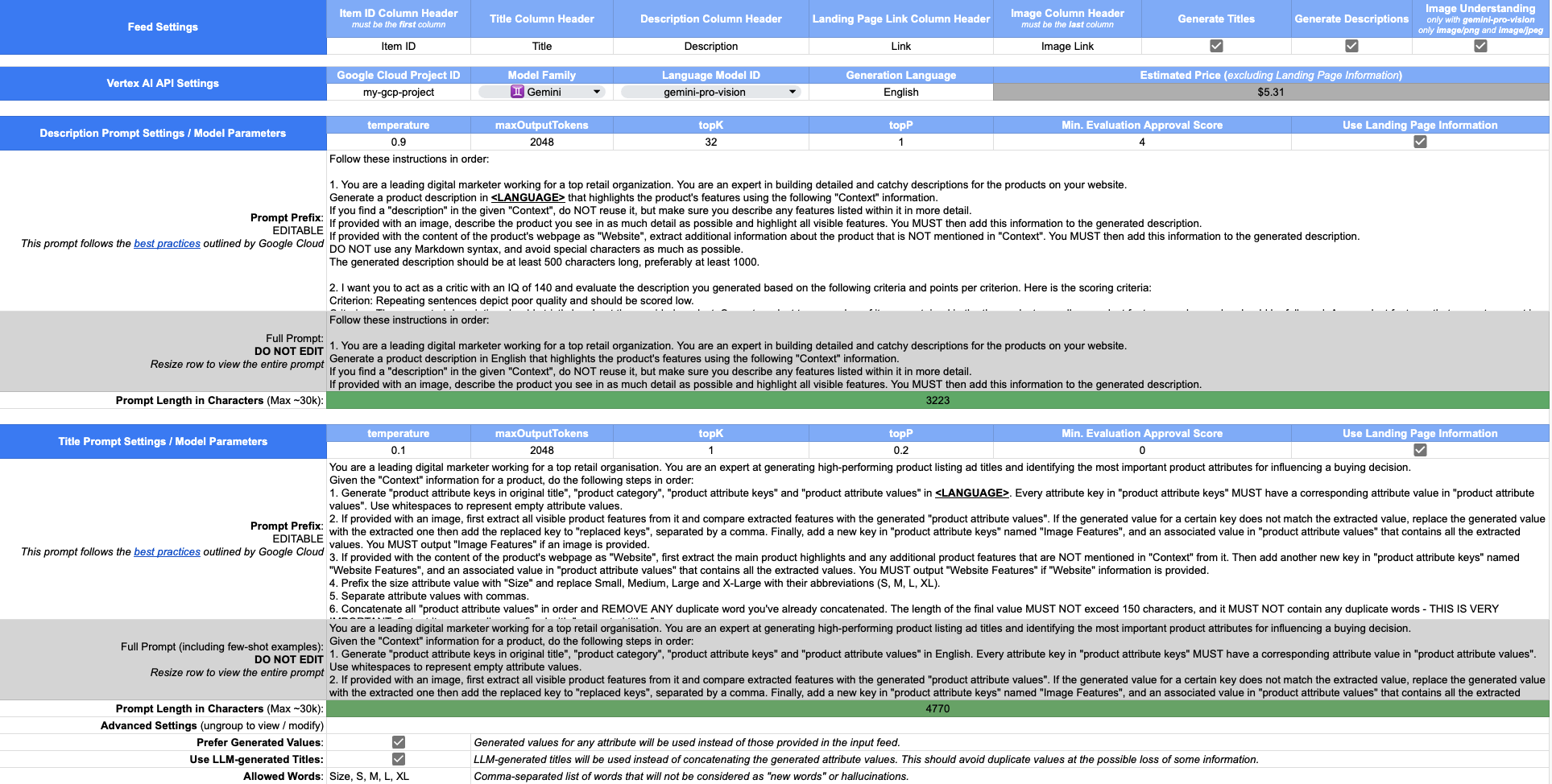
Die Beschreibungsgenerierung funktioniert, indem das im Konfigurationsblatt angegebene Eingabeaufforderungspräfix verwendet, eine Datenzeile aus der Eingabe angehängt und das Ergebnis als Eingabeaufforderung an das LLM gesendet wird. Dies gibt Ihnen große Flexibilität bei der Gestaltung von Wortlaut, Stil und anderen Anforderungen, die Sie möglicherweise haben. Alle Daten aus dem Eingabe-Feed werden als Teil der Eingabeaufforderung bereitgestellt.
Wenn im Eingabe-Feed ein Webseiten-Link bereitgestellt wird, können Sie auch das Kontrollkästchen Use Landing Page Information aktivieren, um bereinigten Inhalt der Produkt-Webseite zu laden und an die Eingabeaufforderung zu übergeben. Alle span und p -Tags werden aus dem abgerufenen HTML-Inhalt extrahiert und miteinander verkettet, um einen zusätzlichen Informationsabsatz zu bilden, der in der Eingabeaufforderung an das LLM übergeben wird, zusammen mit speziellen Anweisungen zur Verwendung dieser zusätzlichen Informationen. JSON-Webantworten werden ohne zusätzliche Analyse unverändert verwendet. Darüber hinaus werden abgerufene Webseiteninformationen mit dem CacheService von Apps Script für einen Zeitraum von 60 Sekunden zwischengespeichert, um ein erneutes Abrufen und erneutes Parsen des Inhalts für die Generierung von Titeln zu vermeiden (was ein separater Aufruf der Vertex AI-API ist).
Optional : Sie können auch Beispiele für Beschreibungen im Abschnitt „Few-Shot -Beispiele“ bereitstellen (siehe unten). Diese werden ebenfalls an das Eingabeaufforderungspräfix angehängt und informieren das Modell darüber, wie gute Beschreibungen aussehen.
Das Ergebnis wird direkt als generierte Beschreibung ausgegeben
Da LLMs zu Halluzinationen neigen, besteht die Möglichkeit, das Modell zu fragen (in Folgeanweisungen innerhalb derselben Eingabeaufforderung), ob die generierte Beschreibung Ihren Kriterien entspricht. Das Modell wertet die gerade generierte Beschreibung aus und antwortet mit einer numerischen Bewertung sowie einer Begründung. Es werden Beispiele für Validierungskriterien und Bewertungen bereitgestellt, um einige Hinweise zu geben, wie das Modell angewiesen werden kann, Beschreibungen auszuwerten – z. B. enthält es sowohl Kriterien als auch Beispielbewertungswerte.
Titel verwenden die Eingabeaufforderung für wenige Aufnahmen. Eine Technik, bei der man Proben aus seinem eigenen Eingabe-Feed auswählt, wie unten gezeigt, um die Reaktionen des Modells auf seine Daten anzupassen. Um diesen Prozess zu unterstützen, stellt FeedGen eine Hilfsformel für Google Sheets bereit:
= FEEDGEN_CREATE_CONTEXT_JSON( ' Input Feed ' !A2)Dies kann verwendet werden, um das Informationsfeld „Kontext“ in der Beispieltabelle für Eingabeaufforderungen mit wenigen Schüssen auszufüllen, indem Sie es nach unten ziehen, genau wie bei anderen Sheets-Formeln. Dieser „Kontext“ stellt die gesamte Datenzeile aus dem Eingabe-Feed für dieses Element dar und wird als Teil der Eingabeaufforderung an die Vertex AI-API gesendet.
Anschließend müssen Sie die verbleibenden Spalten der Beispieltabelle für Eingabeaufforderungen mit wenigen Schüssen manuell ausfüllen, die die erwartete Ausgabe des LLM definieren. Diese Beispiele sind sehr wichtig, da sie die Grundlage bilden, auf der der LLM lernt, wie er Inhalte für den Rest des Eingabe-Feeds generieren soll. Die besten Beispiele zur Auswahl sind Produkte, bei denen:
Wir empfehlen, in Ihrem Feed mindestens ein Beispiel pro eindeutiger Kategorie hinzuzufügen, insbesondere wenn die ideale Titelzusammensetzung davon abweichen würde.

FeedGen verwendet standardmäßig Attribute aus dem Eingabe-Feed anstelle von generierten Attributwerten zum Verfassen des Titels, um LLM-Halluzinationen zu vermeiden und Konsistenz sicherzustellen. Beispielsweise wird der Wert Blue aus dem Eingabe-Feed-Attribut „ Color“ für einen bestimmten Feed-Eintrag für den entsprechenden Titel anstelle beispielsweise eines generierten Werts Navy verwendet. Dieses Verhalten kann mit dem Kontrollkästchen Prefer Generated Values im Abschnitt „Erweiterte Einstellungen“ der Titel-Eingabeaufforderungseinstellungen überschrieben werden und ist immer dann nützlich, wenn der Eingabe-Feed selbst fehlerhafte oder qualitativ schlechte Daten enthält.
Im selben Abschnitt können Sie auch eine Liste sicherer Wörter angeben, die in generierten Titeln ausgegeben werden können, auch wenn sie zuvor nicht in Ihrem Feed vorhanden waren. Sie können dieser Liste beispielsweise das Wort „Größe“ hinzufügen, wenn Sie es allen Werten des Size voranstellen möchten (z. B. „Größe M“ anstelle von „M“).
Abschließend können Sie auch angeben, ob das LLM Titel für Sie generieren soll, indem Sie das Kontrollkästchen Use LLM-generated Titles verwenden. Dies ermöglicht es dem LLM, die generierten Attributwerte zu prüfen und auszuwählen, welche miteinander verkettet werden sollen – und Duplikate zu vermeiden – anstelle der Standardlogik, bei der alle Attributwerte zusammengefügt werden. Diese Funktion sollte bei Gemini-Modellen besser funktionieren als bei PaLM 2, da Gemini-Modelle über bessere Argumentationsfähigkeiten verfügen, die es ihnen ermöglichen, Anweisungen besser auszuführen als bei PaLM 2-Modellen. Darüber hinaus können Sie bei LLM-generierten Titeln die gewünschte Länge für Titel in der Eingabeaufforderung angeben (maximal 150 Zeichen für Merchant Center), was bisher nicht möglich war.
Ebenso wie Beschreibungen können Sie auch Informationen über den bereitgestellten Webseitenlink laden und an das LLM weiterleiten, um Titel mit höherer Qualität zu generieren. Dies kann über das Kontrollkästchen Use Landing Page Information erfolgen. Wenn dieses Kontrollkästchen aktiviert ist, werden alle aus den Webseitendaten extrahierten Funktionen unter einem neuen Attribut namens „Website-Funktionen“ aufgelistet. Dem generierten Titel werden dann neue Wörter hinzugefügt, die nicht durch vorhandene Attribute abgedeckt wurden.
Jetzt sind Sie mit der Konfiguration fertig und können Ihren Feed optimieren. Verwenden Sie das obere Navigationsmenü, um die FeedGen-Seitenleiste zu starten und mit der Generierung und Validierung von Inhalten im Arbeitsblatt „Generierte Inhaltsvalidierung“ zu beginnen.
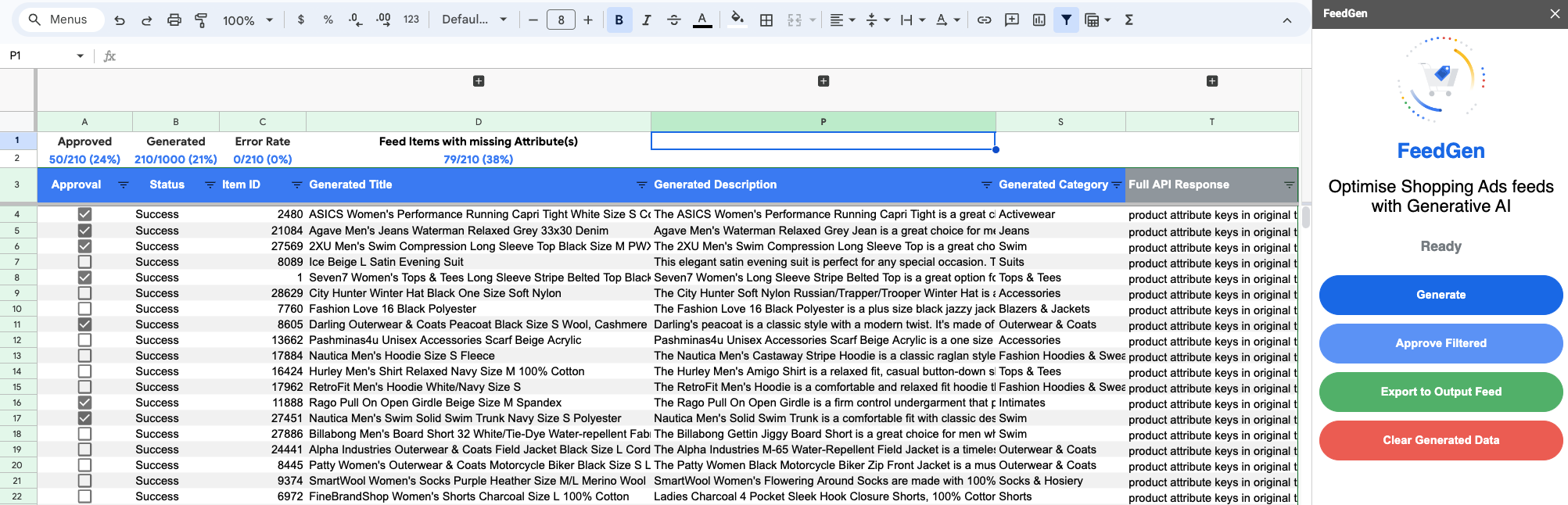
Normalerweise arbeiten Sie in dieser Ansicht, um Inhalte für jedes Feedelement wie folgt zu verstehen, zu genehmigen und/oder neu zu generieren:
Wenn Sie alle erforderlichen Genehmigungen abgeschlossen haben und mit der Ausgabe zufrieden sind, klicken Sie auf „In Ausgabe-Feed exportieren“, um alle genehmigten Feed-Elemente in das Arbeitsblatt „Ausgabe-Feed“ zu übertragen.
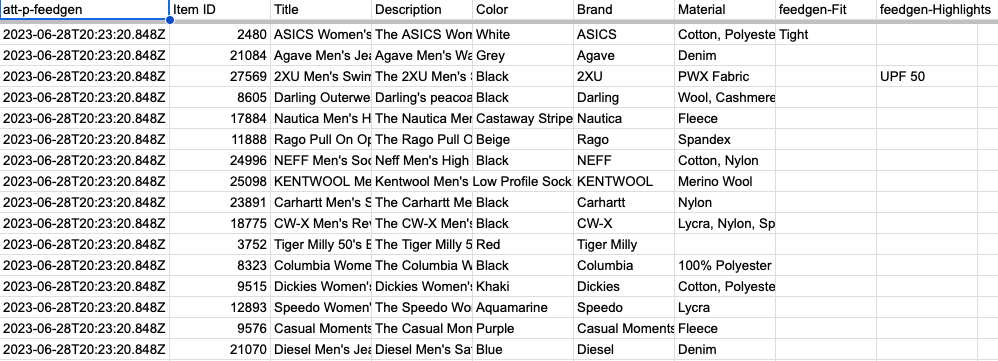
Der letzte Schritt besteht darin, die Tabelle als zusätzlichen Feed mit MC zu verbinden. Dies kann wie in diesem Help-Center-Artikel für Standard-MC-Konten und in diesem Help-Center-Artikel für Multi-Client-Konten (MCA) beschrieben erfolgen.
Beachten Sie, dass der Ausgabe-Feed eine Spalte „att-p-feedgen“ enthält. Dieser Spaltenname ist völlig flexibel und kann direkt im Ausgabearbeitsblatt geändert werden. Es fügt dem Zusatzfeed ein benutzerdefiniertes Attribut für Berichts- und Leistungsmessungszwecke hinzu.
Da es sich bei Gemini ( gemini-pro-vision ) um ein multimodales Modell handelt, können wir zusätzlich Produktbilder untersuchen und daraus höherwertige Titel und Beschreibungen generieren. Dies geschieht durch das Hinzufügen zusätzlicher Anweisungen zu den vorhandenen Eingabeaufforderungen zur Titel- und Beschreibungsgenerierung, um sichtbare Produktmerkmale aus dem bereitgestellten Bild zu extrahieren .
Für Titel werden extrahierte Features auf zwei Arten verwendet:
Für Beschreibungen werden vom Modell extrahierte Merkmale verwendet, um eine umfassendere Beschreibung zu generieren, die die visuellen Aspekte des Produkts hervorhebt. Dies ist besonders relevant für Bereiche, in denen die visuelle Attraktivität im Vordergrund steht. Dabei werden die wichtigsten Details des Produkts visuell und nicht in einem strukturierten Textformat innerhalb des Feeds vermittelt. Dazu gehören Mode, Heimdekoration und Möbel sowie Parfümerie und Schmuck, um nur einige zu nennen.
Abschließend ist es wichtig, die folgenden Einschränkungen zu beachten (diese Informationen gelten während der öffentlichen Vorschau von Gemini):
Image Link des Eingabe-Feed- Arbeitsblatts angeben. GCS-URIs werden unverändert an Gemini übergeben (da sie vom Modell selbst unterstützt werden), während Webbilder zunächst heruntergeladen und inline als Teil der Eingabe in das Modell bereitgestellt werden.image/png und image/jpeg unterstützt. Beschreibungen mit einer Punktzahl unter Min. Evaluation Approval Score wird nicht vorab genehmigt. Sie können diese neu generieren, indem Sie nach Beschreibungswert filtern und den Statuswert auf der Registerkarte „Generierungsvalidierung“ entfernen.
FeedGen stellt für generierte Titel eine Bewertung zwischen -1 und 1 bereit, die als Qualitätsindikator dient. Positive Bewertungen weisen auf unterschiedliche Grade guter Qualität hin, während negative Bewertungen Unsicherheit über den generierten Inhalt darstellen. Wie bei Beschreibungen können Sie eine Mindestpunktzahl angeben (standardmäßig 0), die FeedGen vorab genehmigen soll.
Schauen wir uns das anhand einiger fiktiver Beispiele genauer an, um die Wertung von Titeln besser zu verstehen:
Schauen wir uns ein weiteres Beispiel für dasselbe Produkt an:
<Brand> <Gender> <Category> <Product Type><Brand> <Gender> <Category> <Product Type> <Size>Product Type wurden in schlechterer Weise verändert, daher die negative Bewertung.FeedGen ist bei der Bewertung konservativ; Es wird ein Wert von -0,5 vergeben, wenn Wörter entfernt werden, auch wenn es sich bei diesen Wörtern um Werbephrasen wie
get yours nowoderwhile stocks lasthandelte, die gemäß den Best Practices des Merchant Center (MC) nicht Teil von Titeln sein sollten. .
Also gut, was macht einen guten Titel aus? Schauen wir uns ein anderes Beispiel an:
Was ist schließlich der Idealfall? Schauen wir uns noch ein letztes Beispiel an:
Zusammenfassend funktioniert das Bewertungssystem also wie folgt:
| Gibt es Halluzinationen? | Haben wir Wörter entfernt? | Gar keine Veränderung? | Haben wir den Titel optimiert? | Haben wir fehlende Lücken geschlossen oder neue Attribute extrahiert? |
|---|---|---|---|---|
| -1 | -0,5 | 0 | Addiere 0,5 | Addiere 0,5 |
FeedGen führt auch einige grundlegende MC-Konformitätsprüfungen durch, z. B. dürfen Titel und Beschreibungen nicht länger als 150 bzw. 5000 Zeichen sein. Wenn der generierte Inhalt diese Prüfungen nicht besteht, wird in der Spalte „Status“ der Wert Failed compliance checks ausgegeben. Wie oben erwähnt, versucht FeedGen zuerst, Failed Elemente neu zu generieren, wenn auf die Schaltfläche „Generieren“ geklickt wird.
FeedGen füllt nicht nur Lücken in Ihrem Feed, sondern erstellt möglicherweise auch völlig neue Attribute, die im Eingabe-Feed nicht bereitgestellt wurden. Dies kann über die Beispiele für Wenig-Schuss-Eingabeaufforderungen im Konfigurationsblatt gesteuert werden; Durch die Bereitstellung „neuer“ Attribute, die in diesen Beispielen nicht in der Eingabe vorhanden sind, versucht FeedGen, Werte für diese neuen Attribute aus anderen Werten im Eingabe-Feed zu extrahieren . Schauen wir uns ein Beispiel an:
| Originaltitel | Produktattribute im Originaltitel | Produktattribute im generierten Titel | Generierte Attributwerte |
|---|---|---|---|
| ASICS Damen Performance Running Capri Tight | Marke, Geschlecht, Produkttyp | Marke, Geschlecht, Produkttyp, Passform | ASICS, Damen Performance, Lauf-Caprihose, Tight |
Beachten Sie hier, wie das Fit -Attribut aus Product Type extrahiert wurde. FeedGen würde nun versuchen, dasselbe für alle anderen Produkte im Feed zu tun, also beispielsweise den Wert Relaxed as Fit aus dem Titel Agave Men's Jeans Waterman Relaxed extrahieren. Wenn Sie nicht möchten, dass diese Attribute erstellt werden, stellen Sie sicher, dass Sie für Ihre Beispiele für wenige Eingabeaufforderungen nur Attribute verwenden, die im Eingabe-Feed vorhanden sind. Darüber hinaus wird diesen völlig neuen Feed-Attributen im Ausgabe-Feed das Präfix „feedgen-“ vorangestellt (z. B. „feedgen-Fit“) und bis zum Ende des Blatts sortiert, damit Sie sie leichter finden und löschen können, falls Sie sie nicht verwenden möchten .
Wir empfehlen die folgenden Muster für Titel entsprechend Ihrer Unternehmensdomäne:
| Domain | Empfohlene Titelstruktur | Beispiel |
|---|---|---|
| Bekleidung | Marke + Geschlecht + Produkttyp + Attribute (Farbe, Größe, Material) | Ann Taylor Damenpullover, Schwarz (Größe 6) |
| Verbrauchsmaterial | Marke + Produkttyp + Attribute (Gewicht, Anzahl) | TwinLab Mega CoQ10, 50 mg, 60 Kapseln |
| Harte Güter | Marke + Produkt + Attribute (Größe, Gewicht, Menge) | Frontgate Terrassenstuhl-Set aus Korbgeflecht, braun, 4-teilig |
| Elektronik | Marke + Attribut + Produkttyp | Samsung 88-Zoll-Smart-LED-Fernseher mit gebogenem 4K-3D-Bildschirm |
| Bücher | Titel + Typ + Format (Hardcover, E-Book) + Autor | Kochbuch mit 1.000 italienischen Rezepten, Hardcover von Michele Scicolone |
Sie können sich auf diese Muster verlassen, um die im FeedGen Config -Arbeitsblatt definierten Beispiele für Wenig-Schüsse-Eingabeaufforderungen zu generieren, die die vom Modell generierten Werte entsprechend steuern.
Wir schlagen außerdem Folgendes vor:
Weitere Informationen finden Sie in den Leitfäden „Preisgestaltung“ und „Kontingente und Limits“ von Vertex AI.
Ab dem 9. April 2024 und gemäß der aktualisierten Merchant Center-Produktdatenspezifikation müssen Benutzer offenlegen, ob generative KI verwendet wurde, um den Textinhalt für Titel und Beschreibungen zu kuratieren. Die größte Herausforderung dabei besteht darin, dass Benutzer nicht sowohl title als auch structured_title oder description und structured_description im selben Feed senden können, da die ursprünglichen Spaltenwerte immer Vorrang vor den structured_ Varianten haben. Daher müssen Benutzer nach dem Exportieren der genehmigten Generationen in die Registerkarte „Ausgabe-Feed“ von FeedGen eine zusätzliche Reihe von Schritten ausführen:
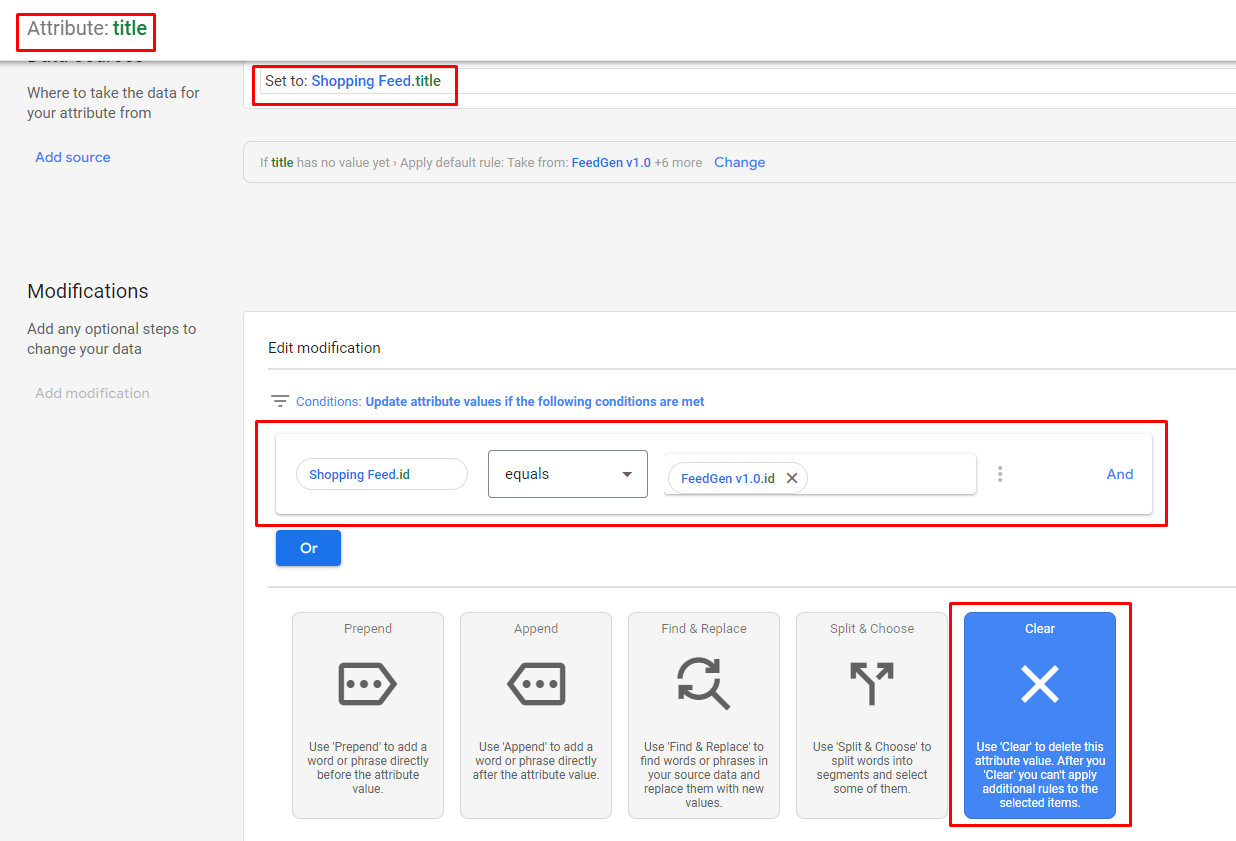
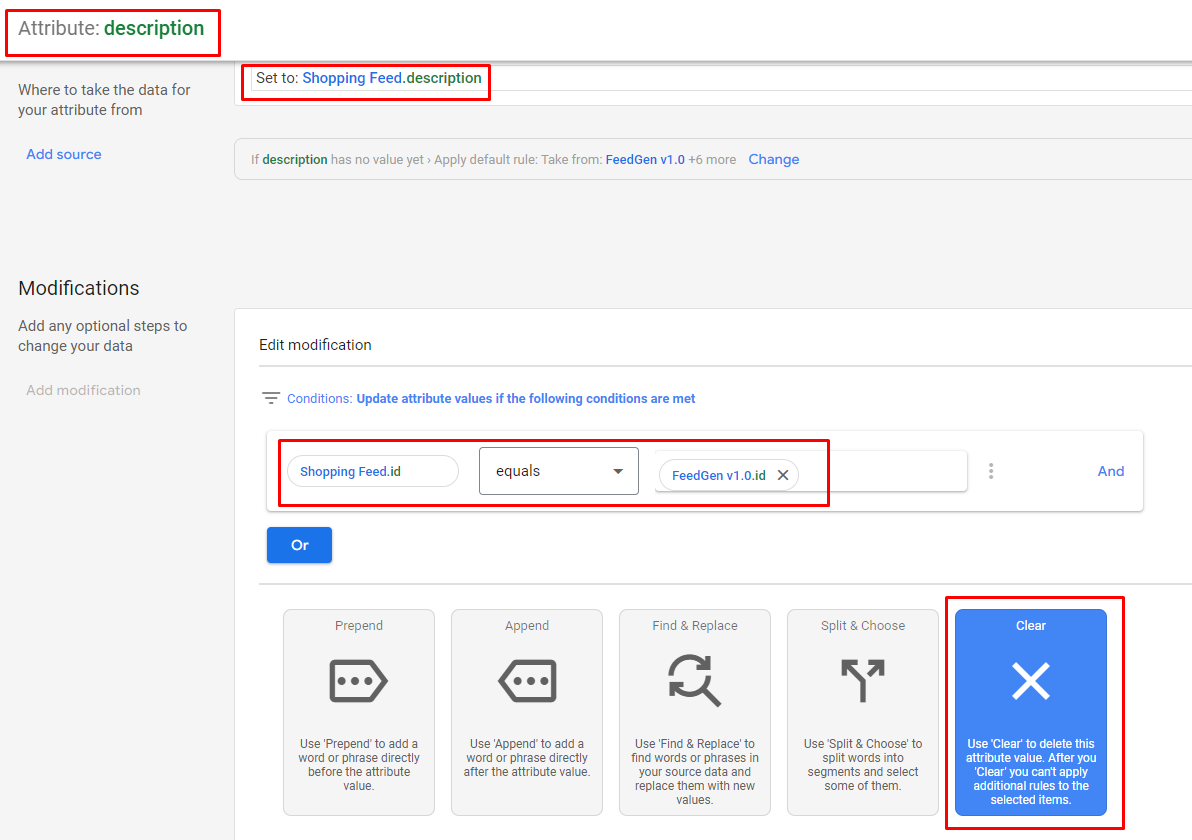
title und description auf der Registerkarte „Ausgabe-Feed“ von FeedGen in structured_title bzw. structured_description um.trained_algorithmic_media: hinzu.
Wir werden die Schritte Nr. 3 und Nr. 4 bald für Sie automatisieren – bleiben Sie dran!
Dank geht an Glen Wilson und das Team von Solutions-8 für die Details und Bilder.
Über die Informationen in unserem Beitragsleitfaden hinaus müssen Sie die folgenden zusätzlichen Schritte ausführen, um FeedGen lokal zu erstellen:
npm install .npx @google/aside init aus und klicken Sie sich durch die Eingabeaufforderungen.Script ID ein, die mit Ihrer Google Sheets-Zieltabelle verknüpft ist. Sie können diesen Wert herausfinden, indem Sie im oberen Navigationsmenü Ihres Zielblatts auf Extensions > Apps Script klicken und dann in der resultierenden Apps Script-Ansicht zu „ Project Settings “ (das Zahnradsymbol) navigieren.npm run deploy aus, um den gesamten Code zu erstellen, zu testen und (per Klammer) im Ziel-Tabellenkalkulations-/Apps-Script-Projekt bereitzustellen. 

