EasyDetect
1.0.0

Ein benutzerfreundliches multimodales Halluzinationserkennungs-Framework für MLLMs
Danksagung • Benchmark • Demo • Übersicht • ModelZoo • Installation • Schnellstart • Zitat
Anerkennung
Überblick
Einheitliche multimodale Halluzination
Datensatz: MHaluBench-Statistik
Rahmen: UniHD-Illustration
ModelZoo
Installation
⏩Schnellstart
Zitat
17.05.2024 Der Artikel Unified Hallucination Detection for Multimodal Large Language Models wird von der ACL 2024-Hauptkonferenz angenommen.
21.04.2024 Wir ersetzen alle Basismodelle in der Demo durch unsere eigenen trainierten Modelle und verkürzen so die Inferenzzeit erheblich.
21.04.2024 Wir veröffentlichen unser Open-Source-Halluzinationserkennungsmodell HalDet-LLAVA, das in den Versionen Huggingface, Modelscope und Wisemodel heruntergeladen werden kann.
10.02.2024 Wir veröffentlichen die EasyDetect-Demo .
05.02.2024 Wir veröffentlichen das Papier: „Unified Hallucination Detection for Multimodal Large Language Models“ mit einem neuen Benchmark MHaluBench! Wir freuen uns über Kommentare oder Diskussionen zu diesem Thema :)
20.10.2023 Das EasyDetect-Projekt wurde gestartet und befindet sich in der Entwicklung.
Ein Teil der Umsetzung dieses Projekts wurde durch die zugehörigen Halluzinations-Toolkits, darunter FactTool, Woodpecker und andere, unterstützt und inspiriert. Dieses Repository profitiert auch vom öffentlichen Projekt von mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO und MAERec. Wir folgen der gleichen Lizenz für Open-Sourcing und danken ihnen für ihre Beiträge zur Community.
EasyDetect ist ein systematisches Paket, das als benutzerfreundliches Framework zur Halluzinationserkennung für multimodale große Sprachmodelle (MLLMs) wie GPT-4V, Gemini und LlaVA in Ihren Forschungsexperimenten vorgeschlagen wird.
Eine Voraussetzung für eine einheitliche Erkennung ist die kohärente Kategorisierung der Hauptkategorien von Halluzinationen innerhalb von MLLMs. Unser Artikel untersucht oberflächlich die folgende Halluzinationstaxonomie aus einer einheitlichen Perspektive:


Abbildung 1: Die einheitliche multimodale Halluzinationserkennung zielt darauf ab, Halluzinationen mit Modalitätskonflikten auf verschiedenen Ebenen wie Objekt, Attribut und Szenentext sowie mit Fakten widersprüchliche Halluzinationen sowohl in Bild-zu-Text als auch in Text-zu-Bild zu identifizieren und zu erkennen Generation.
Modalitätskonfliktierende Halluzination. MLLMs generieren manchmal Ausgaben, die mit Eingaben anderer Modalitäten in Konflikt stehen, was zu Problemen wie falschen Objekten, Attributen oder Szenentexten führt. Ein Beispiel in der obigen Abbildung (a) umfasst ein MLLM, das die Uniform eines Athleten ungenau beschreibt und einen Konflikt auf Attributebene darstellt, da MLLMs nur begrenzt in der Lage sind, eine feinkörnige Text-Bild-Ausrichtung zu erreichen.
Faktenwidersprüchliche Halluzination. Ergebnisse von MLLMs können etabliertem Faktenwissen widersprechen. Bild-zu-Text-Modelle können Erzählungen erzeugen, die vom tatsächlichen Inhalt abweichen, indem sie irrelevante Fakten einbeziehen, während Text-zu-Bild-Modelle möglicherweise visuelle Darstellungen erzeugen, die das in Textaufforderungen enthaltene Faktenwissen nicht widerspiegeln. Diese Diskrepanzen unterstreichen den Kampf der MLLMs um die Wahrung der sachlichen Konsistenz, was eine erhebliche Herausforderung in diesem Bereich darstellt.
Die einheitliche Erkennung multimodaler Halluzinationen erfordert die Überprüfung jedes Bild-Text-Paares a={v, x} , wobei v entweder die visuelle Eingabe bezeichnet, die einem MLLM bereitgestellt wird, oder die von ihm synthetisierte visuelle Ausgabe. Dementsprechend bezeichnet x die vom MLLM generierte Textantwort basierend auf v oder der textuellen Benutzerabfrage zur Synthese v . Innerhalb dieser Aufgabe kann jedes x mehrere Ansprüche enthalten, die als bezeichnet werden a festzustellen, ob sie „halluzinatorisch“ oder „nicht halluzinatorisch“ ist, und eine Begründung für ihre Urteile zu liefern. Die Erkennung von Texthalluzinationen durch LLMs bezeichnet in dieser Einstellung einen Unterfall, bei dem v null ist.
Um diesen Forschungsverlauf voranzutreiben, führen wir den Meta-Evaluierungs-Benchmark MHaluBench ein, der den Inhalt von der Bild-zu-Text- und Text-zu-Bild-Generierung umfasst und darauf abzielt, die Fortschritte bei multimodalen Halluzinationsdetektoren genau zu bewerten. Weitere statistische Details zu MHaluBench finden Sie in den folgenden Abbildungen.
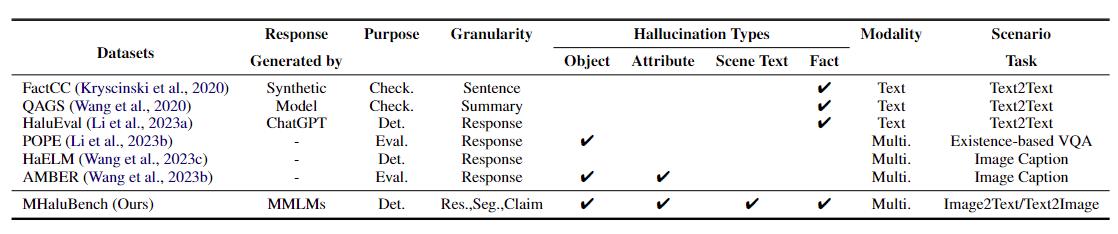
Tabelle 1: Ein Vergleich der Benchmarks im Hinblick auf bestehende Faktenprüfungen oder Halluzinationsbewertungen. "Überprüfen." zeigt die Überprüfung der sachlichen Konsistenz an, „Eval“. bezeichnet die Bewertung von Halluzinationen, die von verschiedenen LLMs erzeugt werden, und seine Reaktion basiert auf verschiedenen getesteten LLMs, während „Det.“ verkörpert die Bewertung der Fähigkeit eines Detektors, Halluzinationen zu erkennen.
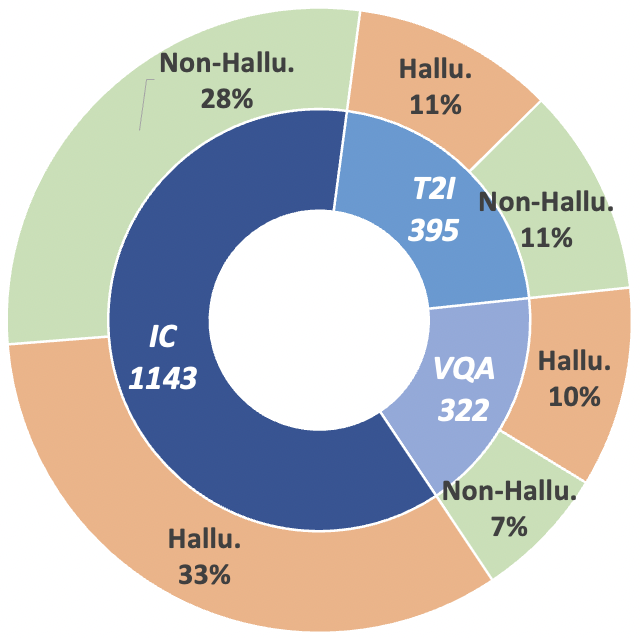
Abbildung 2: Datenstatistik auf Anspruchsebene von MHaluBench. „IC“ steht für Bildunterschrift und „T2I“ steht für Text-zu-Bild-Synthese.
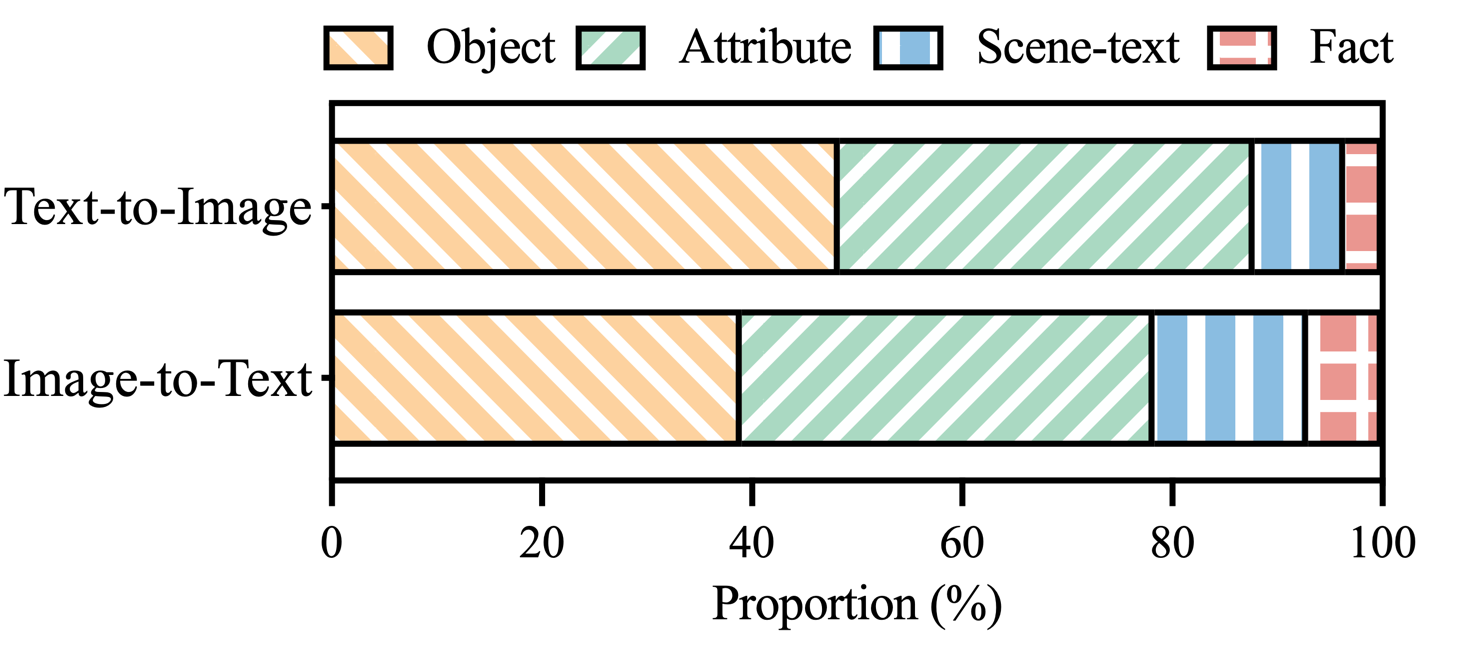
Abbildung 3: Verteilung der Halluzinationskategorien innerhalb der mit Halluzinationen gekennzeichneten Behauptungen von MHaluBench.
Um die wichtigsten Herausforderungen bei der Halluzinationserkennung anzugehen, stellen wir in Abbildung 4 ein einheitliches Framework vor, das die multimodale Halluzinationserkennung sowohl für Bild-zu-Text- als auch für Text-zu-Bild-Aufgaben systematisch angeht. Unser Framework nutzt die domänenspezifischen Stärken verschiedener Tools, um multimodale Beweise zur Bestätigung von Halluzinationen effizient zu sammeln.
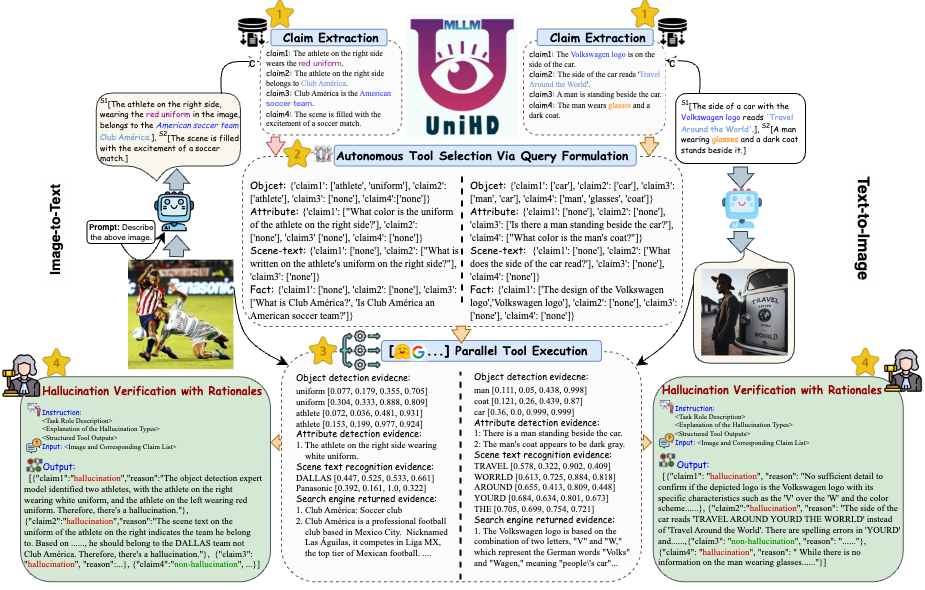
Abbildung 4: Die spezifische Darstellung von UniHD zur einheitlichen multimodalen Halluzinationserkennung.
Sie können zwei Versionen von HalDet-LLaVA, 7b und 13b, auf drei Plattformen herunterladen: HuggingFace, ModelScope und WiseModel.
| Umarmendes Gesicht | ModelScope | WiseModel |
|---|---|---|
| HalDet-llava-7b | HalDet-llava-7b | HalDet-llava-7b |
| HalDet-llava-13b | HalDet-llava-13b | HalDet-llava-13b |
Die Anspruchsebene ergibt sich aus dem Validierungsdatensatz
Selbsttest (GPT-4V) bedeutet, dass GPT-4V mit 0 oder 2 Fällen verwendet wird
UniHD (GPT-4V/GPT-4o) bedeutet die Verwendung von GPT-4V/GPT-4o mit 2-Schuss und Werkzeuginformationen
HalDet (LLAVA) bedeutet die Verwendung von LLAVA-v1.5, das auf unseren Zugdatensätzen trainiert wurde
| Aufgabentyp | Modell | Acc | Prec-Durchschn | Erinnern Sie sich an den Durchschnitt | Mac.F1 |
| Bild-zu-Text | Selbsttest 0 Schuss (GPV-4V) | 75.09 | 74,94 | 75,19 | 74,97 |
| Selbsttest 2 Schuss (GPV-4V) | 79,25 | 79.02 | 79.16 | 79.08 | |
| HalDet (LLAVA-7b) | 75.02 | 75.05 | 74,18 | 74,38 | |
| HalDet (LLAVA-13b) | 78.16 | 78,18 | 77,48 | 77,69 | |
| UniHD (GPT-4V) | 81,91 | 81,81 | 81,52 | 81,63 | |
| UniHD (GPT-4o) | 86.08 | 85,89 | 86.07 | 85,96 | |
| Text-zu-Bild | Selbsttest 0 Schuss (GPV-4V) | 76,20 | 79,31 | 75,99 | 75,45 |
| Selbsttest 2 Schuss (GPV-4V) | 80,76 | 81.16 | 80,69 | 80,67 | |
| HalDet (LLAVA-7b) | 67,35 | 69,31 | 67,50 | 66,62 | |
| HalDet (LLAVA-13b) | 74,74 | 76,68 | 74,88 | 74,34 | |
| UniHD (GPT-4V) | 85,82 | 85,83 | 85,83 | 85,82 | |
| UniHD (GPT-4o) | 89,29 | 89,28 | 89,28 | 89,28 |
Ausführlichere Informationen zu HalDet-LLaVA und dem Zugdatensatz finden Sie in der Readme-Datei.
Installation für lokale Entwicklung:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
Installation für Werkzeuge (GroundingDINO und MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
Wir stellen Beispielcode zur Verfügung, damit Benutzer schnell mit EasyDetect beginnen können.
Benutzer können die Parameter von EasyDetect einfach in einer Yaml-Datei konfigurieren oder einfach schnell die Standardparameter in der von uns bereitgestellten Konfigurationsdatei verwenden. Der Pfad der Konfigurationsdatei lautet EasyDetect/pipeline/config/config.yaml
openai: api_key: Geben Sie Ihren OpenAI-API-Schlüssel ein
base_url: Geben Sie base_url ein, der Standardwert ist „Keine“.
Temperatur: 0,2
max_tokens: 1024tool:
discover:groundingdino_config: der Pfad von GroundingDINO_SwinT_OGC.pymodel_path: der Pfad vongroundingdino_swint_ogc.pthdevice: cuda:0BOX_TRESHOLD: 0.35TEXT_TRESHOLD: 0.25AREA_THRESHOLD: 0.001
ocr:dbnetpp_config: der Pfad von dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: der Pfad von dbnetpp.pthmaerec_config: der Pfad von maerec_b_union14m.pymaerec_path: der Pfad von maerec_b.pthdevice: cuda:0content: word.numbercachefiles_path: der Pfad der Cache-Dateien zum Speichern temporärer Bilder. BOX_TRESHOLD: 0,2TEXT_TRESHOLD: 0,25
google_serper:serper_api_key: Geben Sie Ihre Serper-API ein. Keysnippet_cnt: 10prompts:claim_generate:pipeline/prompts/claim_generate.yaml
query_generate: Pipeline/prompts/query_generate.yaml
Verifizieren: Pipeline/Prompts/verify.yamlBeispielcode
frompipeline.run_pipeline import *pipeline = Pipeline()text = „Das Café im Bild heißt „Hauptbahnhof““image_path = „./examples/058214af21a03013.jpg“type = „image-to-text“response,claim_list =pipeline .run(text=text, image_path=image_path, type=type)print(response)print(claim_list)
Bitte zitieren Sie unser Repository, wenn Sie EasyDetect in Ihrer Arbeit verwenden.
@article{chen23factchd, Autor = {Xiang Chen und Duanzheng Song und Honghao Gui und Chengxi Wang und Ningyu Zhang und Jiang Yong und Fei Huang und Chengfei Lv und Dan Zhang und Huajun Chen}, Titel = {FactCHD: Benchmarking Fact-Conflicting Hallucination Detection }, Zeitschrift = {CoRR}, Band = {abs/2310.12086}, Jahr = {2023}, url = {https://doi.org/10.48550/arXiv.2310.12086}, doi = {10.48550/ARXIV.2310.12086}, eprinttype = {arXiv}, eprint = {2310.12086}, biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}, bibsource = {dblp Informatik-Bibliographie, https://dblp.org}}@inproceedings{chen-etal-2024- unified-hallucination,title = „Unified Hallucination Detection for Multimodal Large Language Models“,author = „Chen, Xiang und Wang, Chenxi und Xue, Yida und Zhang, Ningyu und Yang, Xiaoyan und Li, Qiang und Shen, Yue und Liang, Lei und Gu, Jinjie und Chen, Huajun",editor = "Ku, Lun-Wei und Martins, Andre und Srikumar, Vivek" ,booktitle = „Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)“,month = aug,year = „2024“,address = „Bangkok, Thailand“,publisher = „Association for Computational Linguistics“,url = „https://aclanthology.org/2024.acl-long.178“,pages = „3235--3252“,
}Wir bieten eine langfristige Wartung an, um Fehler zu beheben, Probleme zu lösen und neue Anforderungen zu erfüllen. Wenn Sie also Probleme haben, wenden Sie sich bitte an uns.


