AttackVLM
1.0.0
[Projektseite] | [Folien] | [arXiv] | [Daten-Repository]
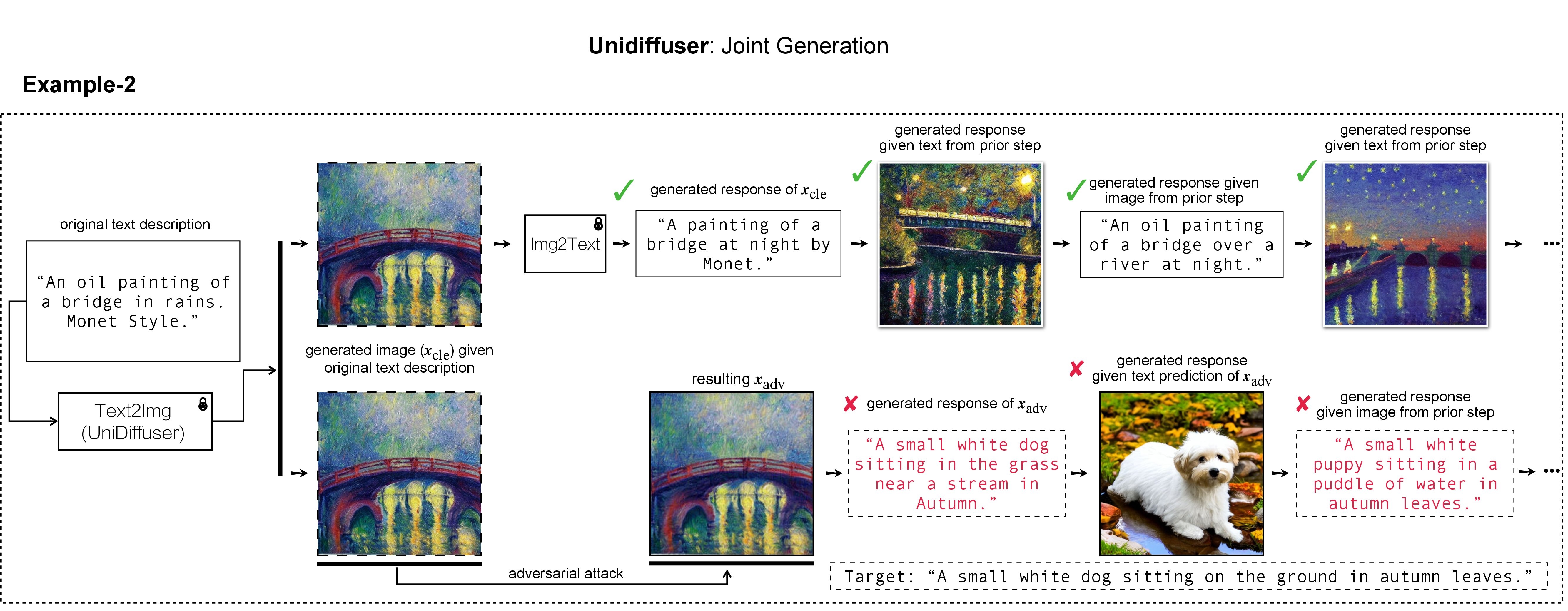
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

In unserer Arbeit verwendeten wir DALL-E, Midjourney und Stable Diffusion für die Zielbilderzeugung und -demonstration. Für die groß angelegten Experimente verwenden wir Stable Diffusion zur Zielbilderzeugung. Um Stable Diffusion zu installieren, initiieren wir unsere Conda-Umgebung nach latenten Diffusionsmodellen. Eine geeignete Basis-Conda-Umgebung namens ldm kann erstellt und aktiviert werden mit:
conda env create -f environment.yaml
conda activate ldm
Beachten Sie, dass wir uns bei verschiedenen Opfermodellen an deren offiziellen Implementierungen und Conda-Umgebungen orientieren.
 Wie in unserem Artikel erläutert, nutzen wir für einen flexiblen gezielten Angriff ein vorab trainiertes Text-zu-Bild-Modell, um ein Zielbild mit einer einzelnen Bildunterschrift als Zieltext zu generieren. Somit können Sie auf diese Weise den gezielten Angriffstitel selbst festlegen!
Wie in unserem Artikel erläutert, nutzen wir für einen flexiblen gezielten Angriff ein vorab trainiertes Text-zu-Bild-Modell, um ein Zielbild mit einer einzelnen Bildunterschrift als Zieltext zu generieren. Somit können Sie auf diese Weise den gezielten Angriffstitel selbst festlegen!
In unseren Experimenten verwenden wir Stable Diffusion, DALL-E oder Midjourney als Text-zu-Bild-Generatoren. Hier verwenden wir Stable Diffusion zur Demonstration (Danke für Open-Sourcing!).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
Bereiten Sie dann die vollständigen gezielten Untertitel von MS-COCO vor oder laden Sie unsere bearbeitete und bereinigte Version herunter:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
und verschieben Sie es nach ./stable-diffusion/ . In Experimenten kann man eine Teilmenge von COCO-Untertiteln (z. B. 10 , 100 , 1K , 10K , 50K ) für den gegnerischen Angriff zufällig auswählen. Nehmen wir zum Beispiel an, wir hätten zufällig 10K COCO-Untertitel als Zieltext c_tar ausgewählt und in der folgenden Datei gespeichert:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
Die gezielten Bilder h_ξ(c_tar) können über Stable Diffusion abgerufen werden, indem die Textaufforderung aus den COCO-Sample-Beschriftungen mit dem folgenden Skript und txt2img_coco.py gelesen wird (bitte verschieben Sie txt2img_coco.py nach ./stable-diffusion/ , beachten Sie, dass Hyperparameter sein können nach Ihren Wünschen angepasst):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
wobei das Cckpt von Stable Diffusion v1 bereitgestellt wird und hier heruntergeladen werden kann: sd-v1-4-full-ema.ckpt.
Weitere Implementierungsdetails der Text-zu-Bild-Generierung durch Stable Diffusion finden Sie HIER.
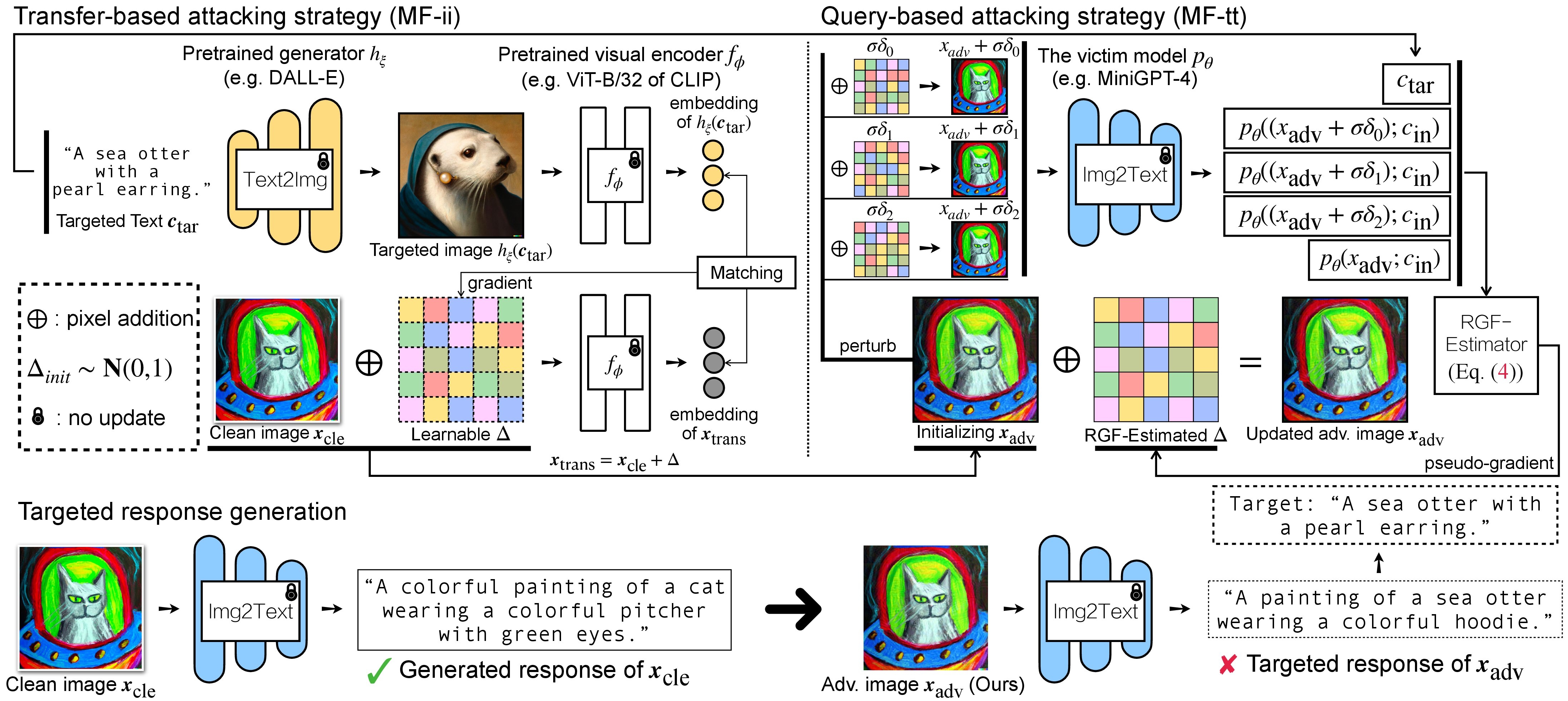
Es gibt zwei Schritte des gegnerischen Angriffs auf VLMs: (1) eine übertragungsbasierte Angriffsstrategie und (2) eine abfragebasierte Angriffsstrategie unter Verwendung von (1) als Initialisierung. Informationen zu BLIP/BLIP-2/Img2Prompt-Modellen finden Sie unter ./LAVIS_tool . Hier verwenden wir Unidiffuser als Beispiel.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
Erstellen Sie dann eine geeignete Conda-Umgebung mit dem Namen unidiffuser indem Sie die Schritte HIER befolgen, und bereiten Sie die entsprechenden Modellgewichte vor (wir verwenden uvit_v1.pth als Gewicht von U-ViT).
conda activate unidiffuser
bash _train_adv_img_trans.sh
Die erstellten Adv-Bilder x_trans werden im Verzeichnis der in --output angegebenen dir of white-box transfer images gespeichert. Anschließend führen wir eine Bild-zu-Text-Umwandlung durch und speichern die generierte Antwort von x_trans. Dies kann erreicht werden durch:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
Dabei werden die generierten Antworten im dir of white-box transfer captions im .txt Format gespeichert. Wir werden sie zur Pseudogradientenschätzung mittels RGF-Schätzer verwenden.
MF-ii + MF-tt verwenden (z. B. 8 px). bash _train_trans_and_query_fixed_budget.sh
Wenn Sie andererseits einen auf Übertragung und Abfrage basierenden Angriff mit separatem Störungsbudget durchführen möchten, stellen wir zusätzlich ein Skript zur Verfügung:
bash _train_trans_and_query_more_budget.sh
Hier verwenden wir wandb , um den gleitenden Durchschnitt des CLIP-Scores (z. B. RN50, ViT-B/32, ViT-L/14 usw.) dynamisch zu überwachen, um die Ähnlichkeit zwischen (a) der generierten Antwort (von trans/ Abfragebilder) und (b) der vordefinierte Zieltext c_tar .
Ein Beispiel wie unten dargestellt, wobei die gepunktete Linie den gleitenden Durchschnitt des CLIP-Scores (von Bildunterschriften) nach der Abfrage angibt: 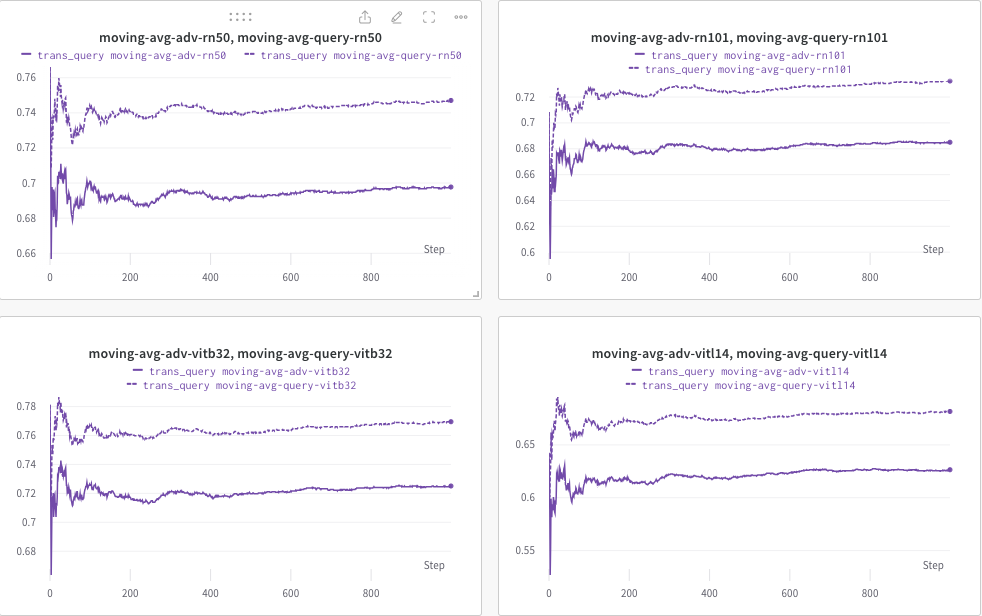
In der Zwischenzeit wird die Bildunterschrift nach der Abfrage gespeichert und das Verzeichnis kann mit --output angegeben werden.
Wenn Sie dieses Projekt für Ihre Forschung nützlich finden, ziehen Sie bitte die Zitierung unseres Artikels in Betracht:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
Inzwischen gibt es eine relevante Forschung, die darauf abzielt, ein Wasserzeichen in (multimodale) Diffusionsmodelle einzubetten:
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
Wir schätzen die wunderbare Basisimplementierung von MiniGPT-4, LLaVA, Unidiffuser, LAVIS und CLIP. Wir danken auch @MetaAI für die Open-Source-Bereitstellung ihrer LLaMA-Checkponts. Wir danken SiSi für die Bereitstellung einiger unterhaltsamer und visuell ansprechender Bilder, die @Midjourney im Rahmen unserer Recherche erstellt hat.
