marqo ecommerce embeddings
1.0.0
In dieser Arbeit stellen wir zwei hochmoderne Einbettungsmodelle für E-Commerce-Produkte vor: Marqo-Ecommerce-B und Marqo-Ecommerce-L.
Die Benchmarking-Ergebnisse zeigen, dass die Marqo-E-Commerce-Modelle bei verschiedenen Kennzahlen durchweg alle anderen Modelle übertrafen. Konkret erreichte marqo-ecommerce-L eine durchschnittliche Verbesserung von 17,6 % beim MRR und 20,5 % beim nDCG@10 im Vergleich zum derzeit besten Open-Source-Modell, ViT-SO400M-14-SigLIP über alle drei Aufgaben im marqo-ecommerce-hard Datensatz. Im Vergleich zum besten privaten Modell, Amazon-Titan-Multimodal , sahen wir eine durchschnittliche Verbesserung von 38,9 % bei MRR und 45,1 % bei nDCG@10 bei allen drei Aufgaben und 35,9 % bei Recall bei den Text-to-Image-Aufgaben in Der marqo-ecommerce-hard -Datensatz.
Weitere Benchmarking-Ergebnisse finden Sie unten.
Veröffentlichter Inhalt :
| Einbettungsmodell | #Params (m) | Dimension | Umarmendes Gesicht | Laden Sie .pt herunter | Einzelbatch-Textinferenz (A10g) | Einzel-Batch-Bildinferenz (A10g) |
|---|---|---|---|---|---|---|
| Marquo-Ecommerce-B | 203 | 768 | Marqo/marqo-ecommerce-embeddings-B | Link | 5,1 ms | 5,7 ms |
| Marquo-Ecommerce-L | 652 | 1024 | Marqo/marqo-ecommerce-embeddings-L | Link | 10,3 ms | 11,0 ms |
Informationen zum Laden der Modelle in OpenCLIP finden Sie weiter unten. Die Modelle werden auf Hugging Face gehostet und mit OpenCLIP geladen. Sie finden diesen Code auch in run_models.py .
pip install open_clip_torch
from PIL import Image
import open_clip
import requests
import torch
# Specify model from Hugging Face Hub
model_name = 'hf-hub:Marqo/marqo-ecommerce-embeddings-L'
model , preprocess_train , preprocess_val = open_clip . create_model_and_transforms ( model_name )
tokenizer = open_clip . get_tokenizer ( model_name )
# Preprocess the image and tokenize text inputs
# Load an example image from a URL
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw )
image = preprocess_val ( img ). unsqueeze ( 0 )
text = tokenizer ([ "dining chairs" , "a laptop" , "toothbrushes" ])
# Perform inference
with torch . no_grad (), torch . cuda . amp . autocast ():
image_features = model . encode_image ( image , normalize = True )
text_features = model . encode_text ( text , normalize = True )
# Calculate similarity probabilities
text_probs = ( 100.0 * image_features @ text_features . T ). softmax ( dim = - 1 )
# Display the label probabilities
print ( "Label probs:" , text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12]Informationen zum Laden der Modelle in Transformers finden Sie weiter unten. Die Modelle werden auf Hugging Face gehostet und mit Transformers geladen.
from transformers import AutoModel , AutoProcessor
import torch
from PIL import Image
import requests
model_name = 'Marqo/marqo-ecommerce-embeddings-L'
# model_name = 'Marqo/marqo-ecommerce-embeddings-B'
model = AutoModel . from_pretrained ( model_name , trust_remote_code = True )
processor = AutoProcessor . from_pretrained ( model_name , trust_remote_code = True )
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw ). convert ( "RGB" )
image = [ img ]
text = [ "dining chairs" , "a laptop" , "toothbrushes" ]
processed = processor ( text = text , images = image , padding = 'max_length' , return_tensors = "pt" )
processor . image_processor . do_rescale = False
with torch . no_grad ():
image_features = model . get_image_features ( processed [ 'pixel_values' ], normalize = True )
text_features = model . get_text_features ( processed [ 'input_ids' ], normalize = True )
text_probs = ( 100 * image_features @ text_features . T ). softmax ( dim = - 1 )
print ( text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12] Zur Auswertung kommt Generalized Contrastive Learning (GCL) zum Einsatz. Der folgende Code ist auch in scripts zu finden.
git clone https://github.com/marqo-ai/GCL
Installieren Sie die von GCL benötigten Pakete.
1. GoogleShopping-Text2Image-Abruf.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-title2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
2. GoogleShopping-Category2Image Retrieval.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-cat2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['query']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
3. AmazonProducts-Category2Image-Abruf.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/ap-title2image
mkdir -p $outdir
hfdataset=Marqo/amazon-products-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
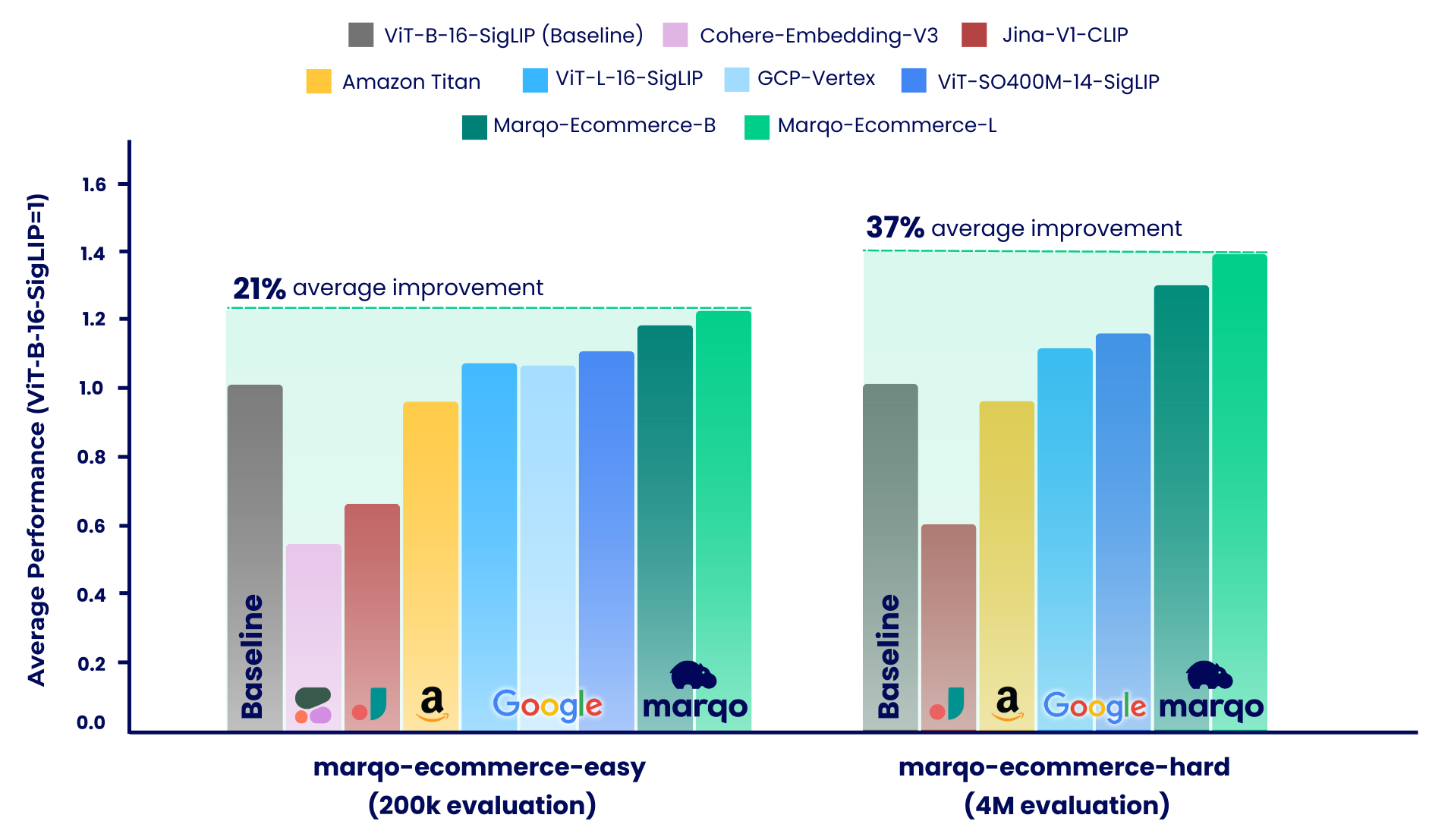
Unser Benchmarking-Prozess war in zwei unterschiedliche Systeme unterteilt, die jeweils unterschiedliche Datensätze von E-Commerce-Produktlisten verwendeten: marqo-ecommerce-hard und marqo-ecommerce-easy. Beide Datensätze enthielten Produktbilder und Text und unterschieden sich lediglich in der Größe. Der „einfache“ Datensatz ist etwa 10–30 Mal kleiner (200.000 vs. 4 Millionen Produkte) und für ratenbegrenzte Modelle konzipiert, insbesondere Cohere-Embeddings-v3 und GCP-Vertex (mit Grenzwerten von 0,66 U/s bzw. 2 U/s). Der „harte“ Datensatz stellt die wahre Herausforderung dar, da er vier Millionen E-Commerce-Produktlisten enthält und eher repräsentativ für reale E-Commerce-Suchszenarien ist.
In beiden Szenarien wurden die Modelle mit drei verschiedenen Aufgaben verglichen:
Marqo-Ecommerce-Hard untersucht die umfassende Bewertung, die anhand des gesamten 4-Millionen-Datensatzes durchgeführt wurde, und hebt die robuste Leistung unserer Modelle in einem realen Kontext hervor.
GoogleShopping-Text2Image-Abruf.
| Einbettungsmodell | Karte | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marquo-Ecommerce-L | 0,682 | 0,878 | 0,683 | 0,726 |
| Marquo-Ecommerce-B | 0,623 | 0,832 | 0,624 | 0,668 |
| ViT-SO400M-14-SigLip | 0,573 | 0,763 | 0,574 | 0,613 |
| ViT-L-16-SigLip | 0,540 | 0,722 | 0,540 | 0,577 |
| ViT-B-16-SigLip | 0,476 | 0,660 | 0,477 | 0,513 |
| Amazon-Titan-MultiModal | 0,475 | 0,648 | 0,475 | 0,509 |
| Jina-V1-CLIP | 0,285 | 0,402 | 0,285 | 0,306 |
GoogleShopping-Category2Image Retrieval.
| Einbettungsmodell | Karte | P@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marquo-Ecommerce-L | 0,463 | 0,652 | 0,822 | 0,666 |
| Marquo-Ecommerce-B | 0,423 | 0,629 | 0,810 | 0,644 |
| ViT-SO400M-14-SigLip | 0,352 | 0,516 | 0,707 | 0,529 |
| ViT-L-16-SigLip | 0,324 | 0,497 | 0,687 | 0,509 |
| ViT-B-16-SigLip | 0,277 | 0,458 | 0,660 | 0,473 |
| Amazon-Titan-MultiModal | 0,246 | 0,429 | 0,642 | 0,446 |
| Jina-V1-CLIP | 0,123 | 0,275 | 0,504 | 0,294 |
AmazonProducts-Text2Image-Abruf.
| Einbettungsmodell | Karte | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marquo-Ecommerce-L | 0,658 | 0,854 | 0,663 | 0,703 |
| Marquo-Ecommerce-B | 0,592 | 0,795 | 0,597 | 0,637 |
| ViT-SO400M-14-SigLip | 0,560 | 0,742 | 0,564 | 0,599 |
| ViT-L-16-SigLip | 0,544 | 0,715 | 0,548 | 0,580 |
| ViT-B-16-SigLip | 0,480 | 0,650 | 0,484 | 0,515 |
| Amazon-Titan-MultiModal | 0,456 | 0,627 | 0,457 | 0,491 |
| Jina-V1-CLIP | 0,265 | 0,378 | 0,266 | 0,285 |
Wie bereits erwähnt, war unser Benchmarking-Prozess in zwei unterschiedliche Szenarien unterteilt: marqo-ecommerce-hard und marqo-ecommerce-easy. In diesem Abschnitt wird Letzteres behandelt, das über einen 10- bis 30-mal kleineren Korpus verfügt und für die Aufnahme von Modellen mit begrenzter Rate konzipiert wurde. Wir werden uns die umfassende Bewertung ansehen, die mit den gesamten 200.000 Produkten in den beiden Datensätzen durchgeführt wurde. Zusätzlich zu den oben bereits getesteten Modellen umfassen diese Benchmarks auch Cohere-embedding-v3 und GCP-Vertex.
GoogleShopping-Text2Image-Abruf.
| Einbettungsmodell | Karte | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marquo-Ecommerce-L | 0,879 | 0,971 | 0,879 | 0,901 |
| Marquo-Ecommerce-B | 0,842 | 0,961 | 0,842 | 0,871 |
| ViT-SO400M-14-SigLip | 0,792 | 0,935 | 0,792 | 0,825 |
| GCP-Vertex | 0,740 | 0,910 | 0,740 | 0,779 |
| ViT-L-16-SigLip | 0,754 | 0,907 | 0,754 | 0,789 |
| ViT-B-16-SigLip | 0,701 | 0,870 | 0,701 | 0,739 |
| Amazon-Titan-MultiModal | 0,694 | 0,868 | 0,693 | 0,733 |
| Jina-V1-CLIP | 0,480 | 0,638 | 0,480 | 0,511 |
| Cohere-embedding-v3 | 0,358 | 0,515 | 0,358 | 0,389 |
GoogleShopping-Category2Image Retrieval.
| Einbettungsmodell | Karte | P@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marquo-Ecommerce-L | 0,515 | 0,358 | 0,764 | 0,590 |
| Marquo-Ecommerce-B | 0,479 | 0,336 | 0,744 | 0,558 |
| ViT-SO400M-14-SigLip | 0,423 | 0,302 | 0,644 | 0,487 |
| GCP-Vertex | 0,417 | 0,298 | 0,636 | 0,481 |
| ViT-L-16-SigLip | 0,392 | 0,281 | 0,627 | 0,458 |
| ViT-B-16-SigLip | 0,347 | 0,252 | 0,594 | 0,414 |
| Amazon-Titan-MultiModal | 0,308 | 0,231 | 0,558 | 0,377 |
| Jina-V1-CLIP | 0,175 | 0,122 | 0,369 | 0,229 |
| Cohere-embedding-v3 | 0,136 | 0,110 | 0,315 | 0,178 |
AmazonProducts-Text2Image-Abruf.
| Einbettungsmodell | Karte | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marquo-Ecommerce-L | 0,92 | 0,978 | 0,928 | 0,940 |
| Marquo-Ecommerce-B | 0,897 | 0,967 | 0,897 | 0,914 |
| ViT-SO400M-14-SigLip | 0,860 | 0,954 | 0,860 | 0,882 |
| ViT-L-16-SigLip | 0,842 | 0,940 | 0,842 | 0,865 |
| GCP-Vertex | 0,808 | 0,933 | 0,808 | 0,837 |
| ViT-B-16-SigLip | 0,797 | 0,917 | 0,797 | 0,825 |
| Amazon-Titan-MultiModal | 0,762 | 0,889 | 0,763 | 0,791 |
| Jina-V1-CLIP | 0,530 | 0,699 | 0,530 | 0,565 |
| Cohere-embedding-v3 | 0,433 | 0,597 | 0,433 | 0,465 |
@software{zhu2024marqoecommembed_2024,
author = {Tianyu Zhu and and Jesse Clark},
month = oct,
title = {{Marqo Ecommerce Embeddings - Foundation Model for Product Embeddings}},
url = {https://github.com/marqo-ai/marqo-ecommerce-embeddings/},
version = {1.0.0},
year = {2024}
}


