VideoMambaPro
1.0.0
Offizielle Implementierung von VideoMambaPro: Ein Sprung nach vorne für Mamba im Videoverständnis 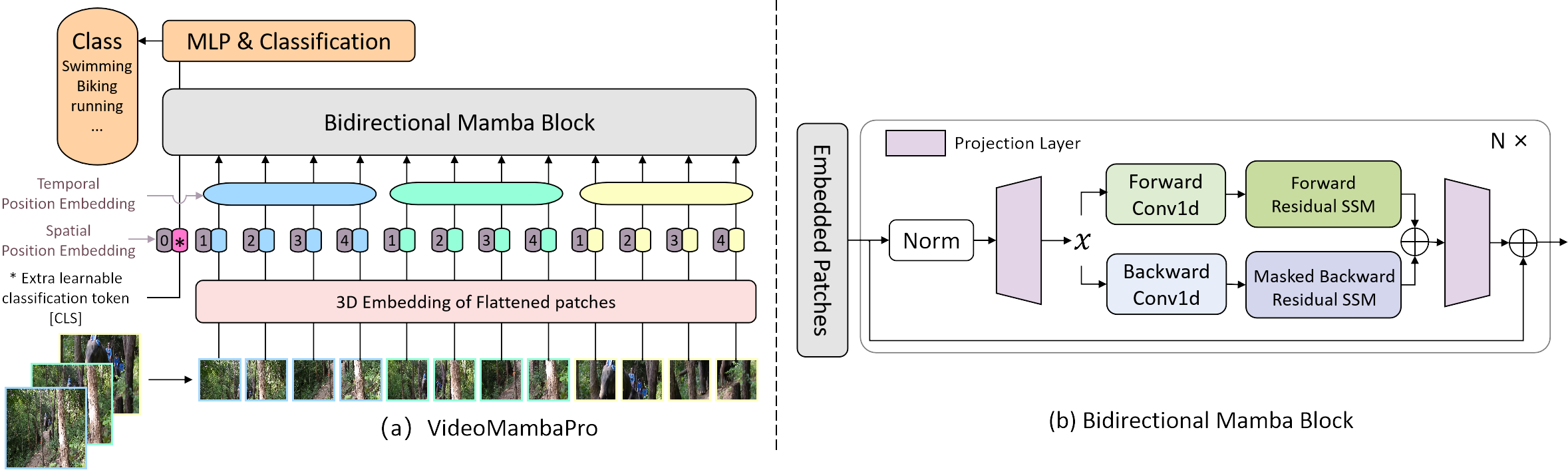
Wir untersuchen Ähnlichkeiten und Unterschiede zwischen Selbstaufmerksamkeit und Mamba aus der Perspektive des letzteren und zeigen die Einschränkungen von Mamba bei der Aufgabe des Videoverständnisses auf. Wir schlagen VideoMambaPro vor, das VideoMamba als Rückgrat verwendet, aber die Leistung bei der Aufgabe des Videoverständnisses erheblich verbessert und die Lücke zu Transformatoren verringert.
Die erforderlichen Pakete befinden sich in der Datei requirements.txt und Sie können den folgenden Befehl ausführen, um die Umgebung zu installieren
conda create -n videomambapro python=3.10
conda activate videomambapro
conda install cudatoolkit==11.8 -c nvidia
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
conda install -c "nvidia/label/cuda-11.8.0" cuda-nvcc
conda install packaging
pip install causal_conv1d==1.4.0 (we recommend to install through .whl file)
pip install mamba-ssm
pip install -r requirements.txt
Wir lesen und verarbeiten auf die gleiche Weise wie VideoMAE, jedoch mit einer anderen Konvention für das Format der Datenlistendatei.
Wir trainieren das Modell vorab auf dem ImageNet-1K-Datensatz, wobei das Modell eine Datenlistendatei mit dem folgenden Format lädt:
Frame_Folder_Pfad Total_Frames-Label
Es gibt zwei Implementierungen unseres Feinabstimmungsdatensatzes VideoClsDataset und RawFrameClsDataset , die Videodaten bzw. Rawframes-Daten unterstützen. Wobei SSV2 standardmäßig RawFrameClsDataset verwendet und die übrigen Datensätze VideoClsDataset verwenden.
VideoClsDataset lädt eine Datenlistendatei mit dem folgenden Format:
video_path-Label
während RawFrameClsDataset eine Datenlistendatei mit dem folgenden Format lädt:
Frame_Folder_Pfad Total_Frames-Label
Nachfolgend werden beispielsweise die Videodatenliste und die Rawframes-Datenliste angezeigt:
# The path prefix 'your_path' can be specified by `--data_root ${PATH_PREFIX}` in scripts when training or inferencing.
# k400 video data validation list
your_path/k400/jf7RDuUTrsQ.mp4 325
your_path/k400/JTlatknwOrY.mp4 233
your_path/k400/NUG7kwJ-614.mp4 103
your_path/k400/y9r115bgfNk.mp4 320
your_path/k400/ZnIDviwA8CE.mp4 244
...
# ssv2 rawframes data validation list
your_path/SomethingV2/frames/74225 62 140
your_path/SomethingV2/frames/116154 51 127
your_path/SomethingV2/frames/198186 47 173
your_path/SomethingV2/frames/137878 29 99
your_path/SomethingV2/frames/151151 31 166
...
Unser Projekt basiert zum fairen Vergleich auf VideoMamba. Um die Einschränkungen 1 und 2 in unserem Artikel zu lösen, ändern wir hauptsächlich die Pipeline von Mamba, indem wir die Diagonalmaske während des Rückwärts-SSM anwenden und eine Restverbindung auf den bidirektionalen SSM anwenden. Die verbleibende Verbindung von Ab wird in der Funktion selected_scan_ref in mamba/mamba_ssm/ops/selective_scan_interface.py realisiert, und die Schlüsseloption ist unten:
x = u[:, :, 0].unsqueeze(-1).expand(-1, -1, dstate)
x = deltaA[:, :, i] * x + deltaB_u[:, :, i]
Die Maskenzuweisung wird durch das Festlegen zweier selektiver Funktionen, nämlich selected_scan_ref und selected_scan_ref_sub, in mamba/mamba_ssm/ops/selective_scan_interface.py realisiert. Bei der Berechnung des bidirektionalen Mamba, z. B. in bimamba_inner_ref von mamba/mamba_ssm/ops/selective_scan_interface.py, ist der Schlüsselcode unten:
y = selective_scan_fn(x, delta, A, B, C, D, z=z, delta_bias=delta_bias, delta_softplus=True)
y_b = selective_scan_ref_sub(x.flip([-1]), delta.flip([-1]), A_b, B.flip([-1]), C.flip([-1]), D, z.flip([-1]), delta_bias, delta_softplus=True)
y = y + y_b.flip([-1])
Quelle: https://pan.baidu.com/s/1vJN_XTRct65cDA_0AB259g?pwd=ghqb Benutzername: ghqb


