Als ich mich mit der Kryptographie beschäftigte, stieß ich auf ein Video der Khan Academy, das mein Interesse an den Mängeln der berüchtigten Caesar-Chiffre weckte.
Wenn Sie einen langen Brief oder eine E-Mail auf Englisch schreiben, hinterlassen Sie unbeabsichtigt einen Fingerabdruck. Wenn Sie eine von Ihnen geschriebene Nachricht scannen und die Häufigkeit jedes Buchstabens zählen, werden Sie ein ziemlich konsistentes Muster finden. „e“ wird höchstwahrscheinlich der am häufigsten vorkommende Buchstabe in der gesamten Nachricht sein. Ich habe eine zufällige Fabel aus dem Internet genommen, um dies zu testen, und das Ergebnis, das ich erzielt habe, war das, was man davon erwarten konnte. „e“ war tatsächlich der beliebteste Buchstabe. Diese Tatsache gilt für jede Nachricht, die lang genug ist.
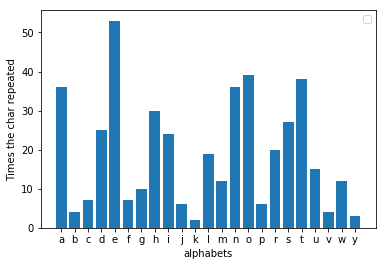
Der Fehler, den Al-Kindi feststellte, bestand darin, dass bei der Analyse der Häufigkeit der verschlüsselten Nachricht jetzt am häufigsten ein anderer Buchstabe vorkommt. Wenn Sie überprüfen, wie weit der Buchstabe von der Drei verschoben ist, können Sie den Wert ermitteln, durch den die Nachricht ersetzt wird. Wenn beispielsweise „h“ der beliebteste Buchstabe in der verschlüsselten Nachricht ist, betrug die Verschiebung wahrscheinlich drei. Durch Umkehren der Verschiebung könnten wir nun leicht die ursprüngliche Nachricht erhalten. Wenn Sie in decoder.py eine verschlüsselte Datei eingeben, wird die Nachricht entschlüsselt und gedruckt. Ich habe dieselbe Fabel verschlüsselt, indem ich die Alphabete um drei Buchstaben verschoben habe, und es stellte sich heraus, dass „h“ hier tatsächlich der beliebteste Buchstabe ist.
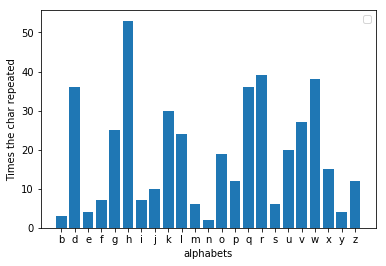
Um die Ergebnisse meiner Chiffre zu reproduzieren und sie mit anderen Nachrichten zu untersuchen, müssen Sie zusätzlich zu Python auch Matplotlib installiert haben.
pip install matplotlib tunDenken Sie daran : Der Decoder arbeitet nach dem Prinzip der Linguistik und Statistik. Je länger die Nachricht ist, desto genauer ist das Ergebnis.
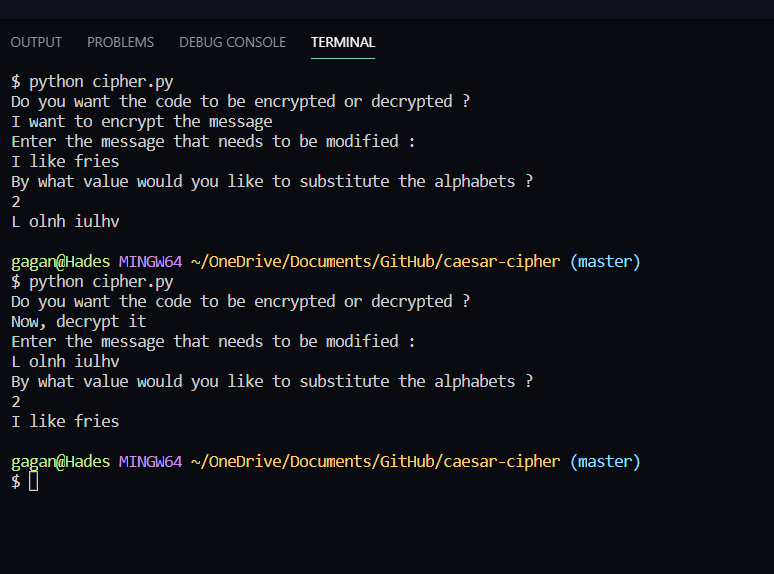
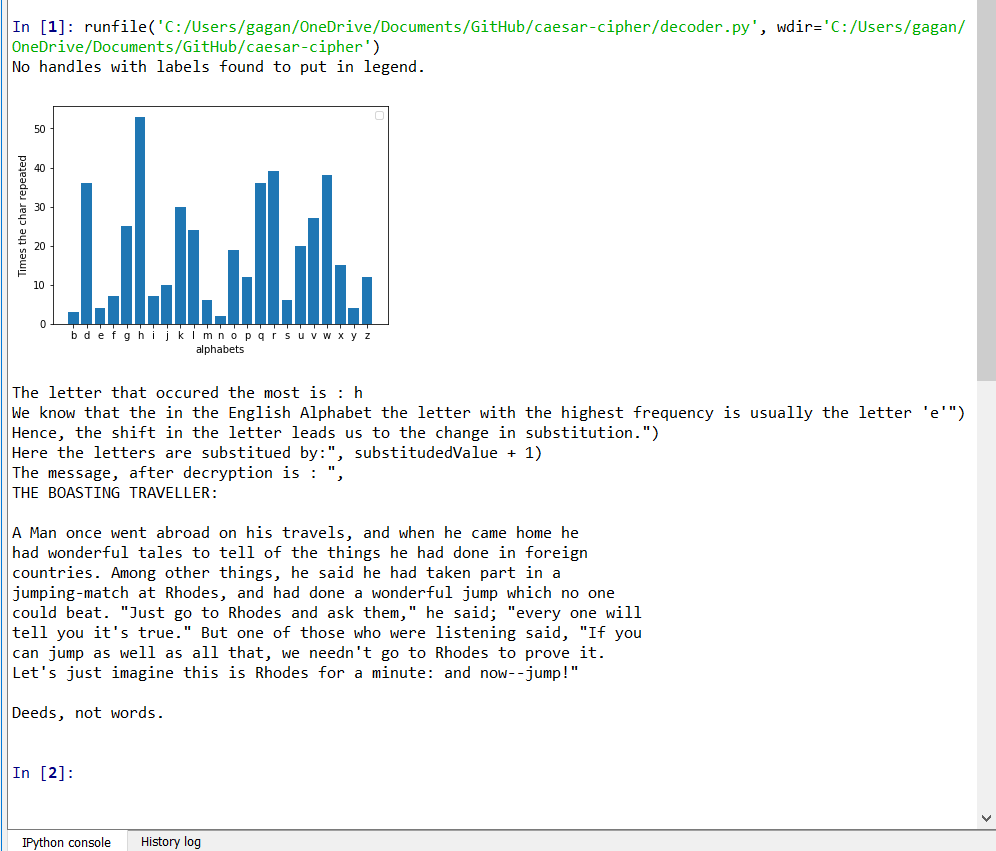
Gagan Devagiri © MIT


