Dieser Leitfaden hilft Ihnen beim Zusammenstellen und Testen einer Entwicklervorschauversion des RHEL AI-Produkts.
Willkommen zur Red Hat Enterprise Linux AI Developer Preview! Dieser Leitfaden soll Ihnen die RHEL AI Developer Preview-Funktionen vorstellen. Erwarten Sie wie bei anderen Developer Previews Änderungen an diesen Arbeitsabläufen, zusätzliche Automatisierung und Vereinfachung sowie eine Erweiterung der Funktionen, Hardware- und Software-Supportversionen, Leistungsverbesserungen (und andere Optimierungen) vor der GA.
RHEL AI ist ein Open-Source-Produkt, das Folgendes umfasst:
Notiz
RHEL AI ist auf Serverplattformen und Workstations mit separaten GPUs ausgerichtet. Für Laptops verwenden Sie bitte das Upstream-InstructLab.
Hier ist eine Liste von Servern, die von Red Hat-Ingenieuren für die Arbeit mit der RHEL AI Developer Preview validiert wurden. Wir gehen davon aus, dass aktuelle Systeme, die für die Ausführung von RHEL 9 zertifiziert sind, mit aktuellen Rechenzentrums-GPUs wie den unten aufgeführten, mit dieser Entwicklervorschau funktionieren werden.
| GPU-Anbieter/Spezifikationen | RHEL AI Dev Preview |
|---|---|
| Dell (4) NVIDIA H100 | Ja |
IBM GX3 Instanzen | Ja |
| Lenovo (8) AMD MI300x | Ja |
| AWS p4- und p5-Instanzen (NVIDIA) | Laufend |
| Intel | Laufend |
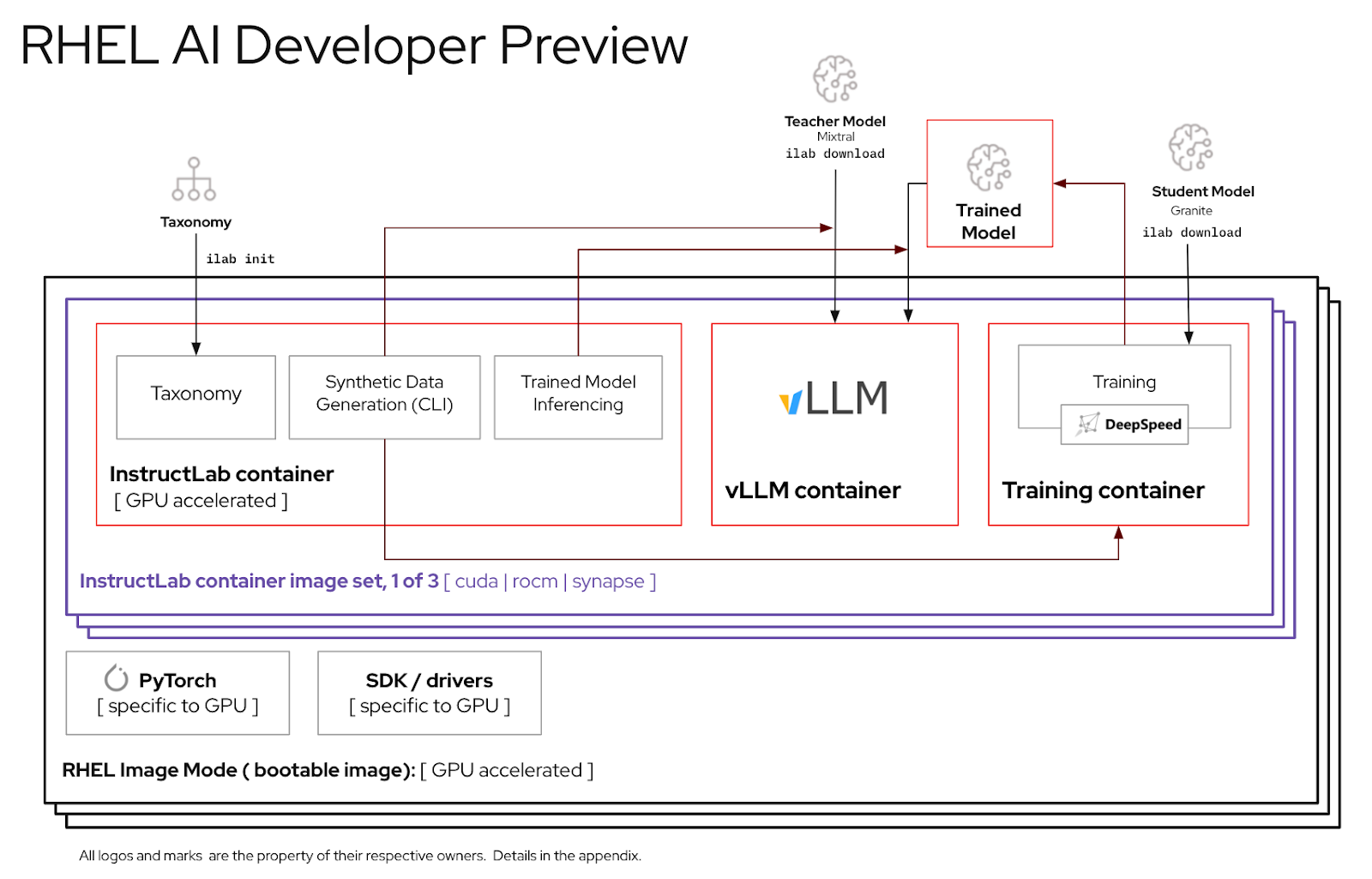
Für ein optimales Erlebnis mit der RHEL AI-Entwicklervorschau haben wir einen beschnittenen Taxonomiebaum in den InstructLab-Container eingefügt. Dadurch kann die Validierungsschulung in einem angemessenen Zeitrahmen auf einem einzigen Server abgeschlossen werden.
Formel: Eine einzelne GPU kann ca. 250 Samples pro Minute trainieren. Wenn Sie über 8 GPUs und 10.000 Samples verfügen, ist mit einer langen Laufzeit zu rechnen
Am Ende dieser Übung werden Sie Folgendes haben:
bootc ist ein transaktionales, direktes Betriebssystem, das mithilfe von OCI/Docker-Container-Images Bereitstellungen und Aktualisierungen durchführt. bootc ist die Schlüsselkomponente in einer umfassenderen Mission bootfähiger Container.
Das ursprüngliche Docker-Containermodell, bei dem „Ebenen“ zur Modellierung von Anwendungen verwendet wurden, war äußerst erfolgreich. Dieses Projekt zielt darauf ab, die gleiche Technik auf bootfähige Hostsysteme anzuwenden – unter Verwendung von Standard-OCI/Docker-Containern als Transport- und Bereitstellungsformat für Basisbetriebssystem-Updates.
Das Container-Image beinhaltet einen Linux-Kernel (z. B. in /usr/lib/modules ), der zum Booten verwendet wird. Zur Laufzeit auf einem Zielsystem läuft der Basis-Userspace standardmäßig nicht selbst in einem Container. Wenn beispielsweise systemd verwendet wird, fungiert systemd wie gewohnt als pid1 – es gibt keinen „äußeren“ Prozess.
Im folgenden Beispiel trägt der Bootc-Container die Bezeichnung Node Base Image :
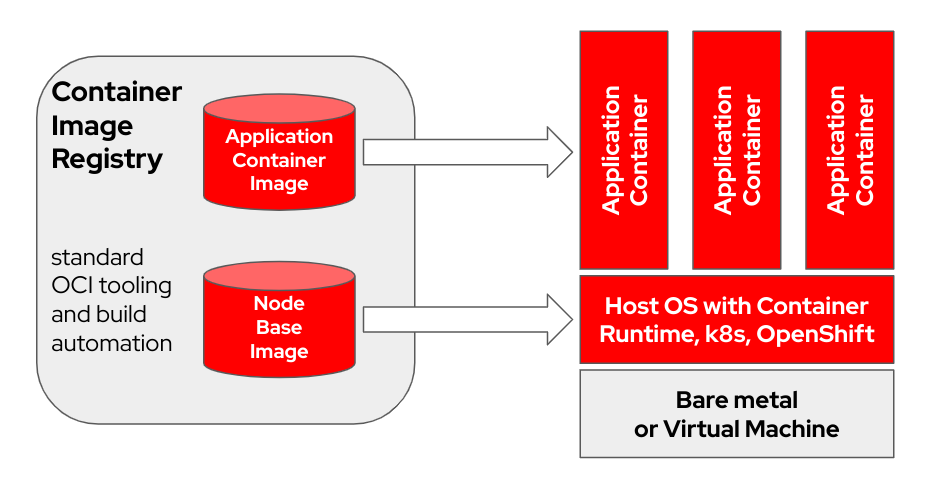
Abhängig von der Hardware Ihres Build-Hosts und der Geschwindigkeit Ihrer Internetverbindung kann das Erstellen und Hochladen von Container-Images bis zu 2 Stunden dauern.
m5.xlarge mit GP3-Speicher)quay.io oder eine andere Image-Registrierung. Registrieren Sie den Host (Wie registriere ich ein RHEL-System und abonniere es beim Red Hat-Kundenportal mit dem Red Hat Subscription-Manager?)
sudo subscription-manager register --username < username > --password < password >Installieren Sie die erforderlichen Pakete
sudo dnf install git make podman buildah lorax -yKlonen Sie das RHEL AI Developer Preview-Git-Repository
git clone https://github.com/RedHatOfficial/rhelai-dev-preview Authentifizieren Sie sich mit Ihrem redhat.com -Konto bei der Red Hat-Registrierung (Red Hat Container Registry Authentication).
podman login registry.redhat.io --username < username > --password < password >
podman login --get-login registry.redhat.io
Your_login_here Stellen Sie sicher, dass Sie über einen SSH-Schlüssel auf dem Build-Host verfügen. Dies wird während der Erstellung des Treiber-Toolkit-Images verwendet. (Verwenden von ssh-keygen und Teilen für die schlüsselbasierte Authentifizierung unter Linux | Sysadmin aktivieren)
RHEL AI enthält eine Reihe von Makefiles, um die Erstellung der Container-Images zu erleichtern. Abhängig von der Hardware Ihres Build-Hosts und der Geschwindigkeit Ihrer Internetverbindung kann dies bis zu einer Stunde dauern.
Erstellen Sie das InstructLab NVIDIA-Container-Image.
make instruct-nvidia Erstellen Sie das vllm Container-Image.
make vllm Erstellen Sie das deepspeed Container-Image.
make deepspeed Erstellen Sie zuletzt das RHEL AI NVIDIA bootc Container-Image. Dies ist der „bootfähige“ Container im RHEL-Image-Modus. Wir betten die 3 Bilder oben in diesen Container ein.
make nvidia FROM=registry.redhat.io/rhel9/rhel-bootc:9.4 REGISTRY= < your-registry > REGISTRY_ORG= < your-org-name > Das resultierende Bild ist mit ${REGISTRY}/${REGISTRY_ORG}/nvidia-bootc:latest getaggt. Weitere Variablen und Beispiele finden Sie in der Schulung/README.
Schieben Sie das resultierende Image in Ihre Registrierung. Sie werden in einem nächsten Schritt in einer Kickstart-Datei auf diese URL verweisen.
podman push ${REGISTRY} / ${REGISTRY_ORG} /nvidia-bootc:latest
e.g. podman push quay.io/ < your-user-name > /nvidia-bootc.latestZu diesem Zeitpunkt verfügen Sie über ein bootfähiges RHEL AI-Container-Image, das auf einem physischen oder virtuellen Host installiert werden kann.
Anaconda ist das Red Hat Enterprise Linux-Installationsprogramm und ist in alle herunterladbaren RHEL-ISO-Images eingebettet. Die Hauptmethode zur Automatisierung der RHEL-Installation sind Skripte namens Kickstart. Weitere Informationen zu Anaconda und Kickstart finden Sie in diesen Dokumenten.
Mit RHEL 9.4 wurde kürzlich ein Kickstart-Befehl namens ostreecontainer eingeführt. Wir verwenden ostreecontainer um den bootfähigen nvidia-bootc -Container bereitzustellen, den Sie gerade über das Netzwerk in Ihre Registrierung übertragen haben.
Hier ist ein Beispiel einer Kickstart-Datei. Kopieren Sie es in eine Datei namens rhelai-dev-preview-bootc.ks und passen Sie es an Ihre Umgebung an:
# text
## customize this for your target system
# network --bootproto=dhcp --device=link --activate
## Basic partitioning
## customize this for your target system
# clearpart --all --initlabel --disklabel=gpt
# reqpart --add-boot
# part / --grow --fstype xfs
# ostreecontainer --url quay.io/<your-user-name>/nvidia-bootc:latest
# firewall --disabled
# services --enabled=sshd
## optionally add a user
# user --name=cloud-user --groups=wheel --plaintext --password
# sshkey --username cloud-user "ssh-ed25519 AAAAC3Nza....."
## if desired, inject an SSH key for root
# rootpw --iscrypted locked
# sshkey --username root "ssh-ed25519 AAAAC3Nza..."
# reboot
Laden Sie die „Boot-ISO“ von RHEL 9.4 herunter und verwenden Sie den Befehl mkksiso um den Kickstart in die RHEL-Boot-ISO einzubetten.
mkksiso rhelai-dev-preview-bootc.ks rhel-9.4-x86_64-boot.iso rhelai-dev-preview-bootc-ks.isoZu diesem Zeitpunkt sollten Sie Folgendes haben:
nvidia-bootc:latest : ein bootfähiges Container-Image mit Unterstützung für NVIDIA-GPUsrhelai-dev-preview-bootc.ks : eine Kickstart-Datei, die für die Bereitstellung von RHEL aus Ihrer Container-Registrierung auf Ihrem Zielsystem angepasst ist.rhelai-dev-preview-bootc-ks.iso : ein bootfähiges RHEL 9.4 ISO mit eingebettetem Kickstart. Booten Sie Ihr Zielsystem mit der Datei rhelai-dev-preview-bootc-ks.iso . Anaconda ruft das nvidia-bootc:latest-Image aus Ihrer Registrierung ab und stellt RHEL gemäß Ihrer Kickstart-Datei bereit.
Alternative : Die Kickstart-Datei kann über HTTP bereitgestellt werden. Bei der Installation über die Kernel-Befehlszeile und einen externen HTTP-Server – fügen Sie inst.ks=http(s)://kickstart/url/rhelai-dev-preview-bootc.ks hinzu
Bevor Sie die RHEL-KI-Umgebung verwenden, müssen Sie zwei Modelle herunterladen, die jeweils auf eine Schlüsselfunktion im High-Fidelity-Tuning-Prozess zugeschnitten sind. Granit wird als Schülermodell verwendet und ist dafür verantwortlich, das Training eines neuen, fein abgestimmten Modus zu erleichtern. Mixtral wird als Lehrermodell verwendet und ist für die Unterstützung der Generierungsphase des LAB-Prozesses verantwortlich, in der Fähigkeiten und Wissen gemeinsam genutzt werden, um einen umfangreichen Trainingsdatensatz zu erstellen.
Settings .Access Tokens . Klicken Sie auf die Schaltfläche New token und geben Sie einen Namen ein. Für das neue Token sind lediglich Read erforderlich, da es nur zum Abrufen von Modellen verwendet wird. Auf diesem Bildschirm können Sie den Token-Inhalt generieren und den Text zur Authentifizierung speichern und kopieren. 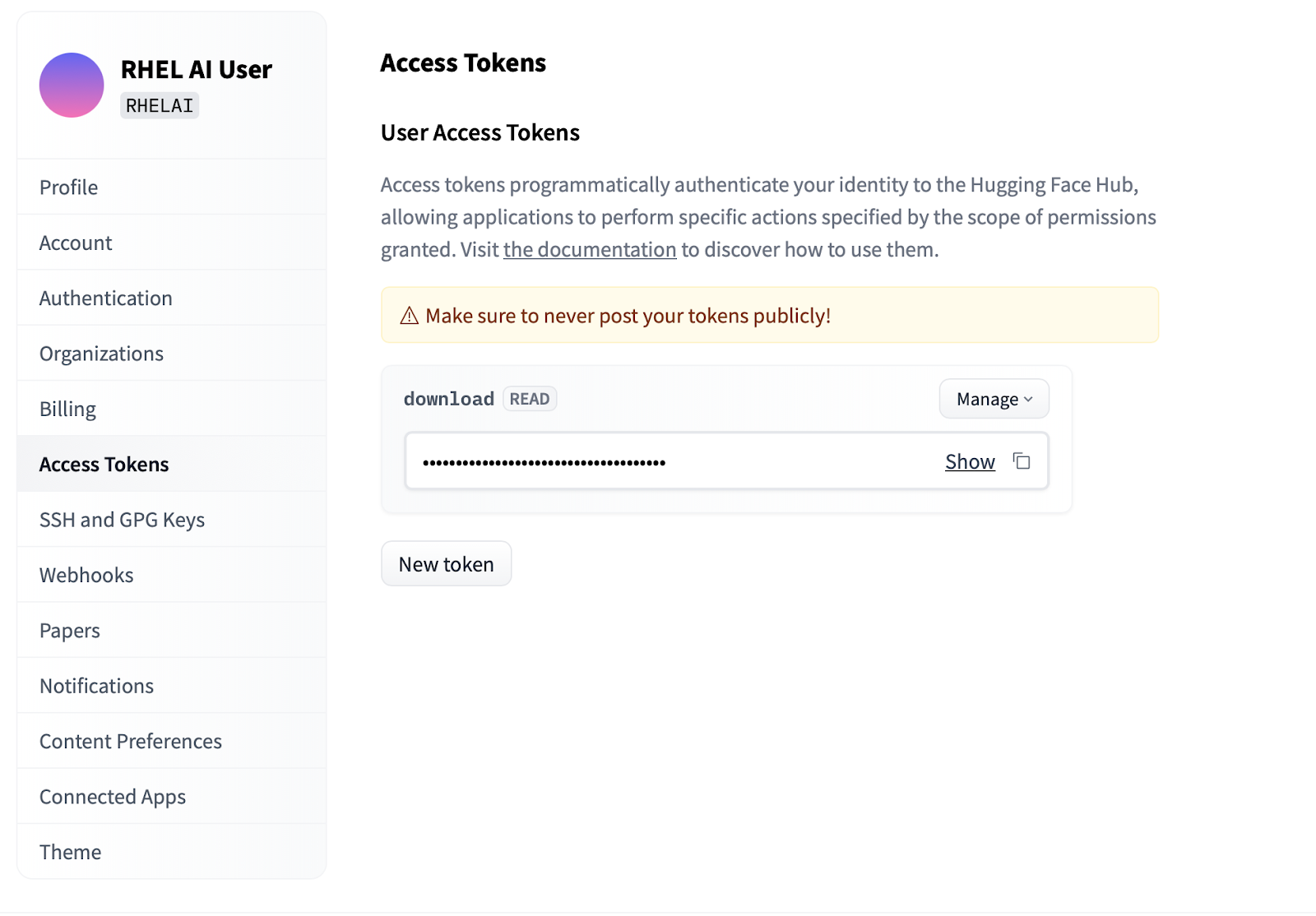
Die ilab Befehlszeilenschnittstelle, die Teil des InstructLab-Projekts ist, konzentriert sich auf die Ausführung leichter quantisierter Modelle auf PC-Geräten wie Laptops. Im Gegensatz dazu ermöglicht RHEL AI die Verwendung von High-Fidelity-Training unter Verwendung von Modellen mit voller Präzision. Aus Gründen der Vertrautheit spiegeln der Befehl und die Parameter den ilab -Befehl von InstructLab wider; Die unterstützende Implementierung ist jedoch sehr unterschiedlich.
In RHEL AI ist der
ilab-Befehl ein Wrapper , der als Front-End für eine auf dem RHEL AI-System vorgebündelte Containerarchitektur fungiert.
ilab BefehlszeilenschnittstelleDer erste Schritt besteht darin, ein neues Arbeitsverzeichnis für Ihr Projekt zu erstellen. Alles wird relativ zu diesem Arbeitsverzeichnis sein. Es enthält Ihre Modelle, Protokolle und Trainingsdaten.
mkdir my-project
cd my-project Der allererste ilab -Befehl, den Sie ausführen, richtet die Basisumgebung ein und lädt bei Bedarf auch das Taxonomie-Repository herunter. Dies wird für spätere Schritte benötigt und wird daher empfohlen.
ilab initDefinieren Sie eine Umgebungsvariable mithilfe des HF-Tokens, das Sie im obigen Abschnitt unter „Zugriffstokens“ erstellt haben.
export HF_TOKEN= < paste token value here > Laden Sie als Nächstes das IBM Granite-Basismodell herunter. Wichtig: Laden Sie nicht die „Labor“-Versionen des Modells herunter. Das Modell mit Granitbasis ist am effektivsten, wenn Sie ein High-Fidelity-Training durchführen.
ilab download --repository ibm/granite-7b-baseBefolgen Sie den gleichen Vorgang, um das Mixtral-Modell herunterzuladen.
ilab download --repository mistralai/Mixtral-8x7B-Instruct-v0.1Nachdem Sie nun Ihr Projekt initialisiert und Ihre ersten Modelle heruntergeladen haben, beobachten Sie die Verzeichnisstruktur Ihres Projekts
my-project/
├─ models/
├─ generated/
├─ taxonomy/
├─ training/
├─ training_output/
├─ cache/
| Ordner | Zweck |
|---|---|
| Modelle | Enthält alle Sprachmodelle, einschließlich der gespeicherten Ausgabe derjenigen, die Sie mit RHEL AI generieren |
| generiert | Generierte Datenausgabe aus der Generierungsphase, basierend auf Änderungen am Taxonomie-Repository |
| Taxonomie | Fähigkeits- oder Wissensdaten, die von der LAB-Methode verwendet werden, um synthetische Daten für das Training zu generieren |
| Ausbildung | Konvertierte Startdaten, um den Trainingsprozess zu erleichtern |
| training_output | Alle vorübergehenden Ausgaben des Trainingsprozesses, einschließlich Protokolle und Probenkontrollpunkte während des Flugs |
| Cache | Ein interner Cache, der von den Modelldaten verwendet wird |
Der nächste Schritt besteht darin, neue Kenntnisse oder Fähigkeiten in das Taxonomie-Repo einzubringen. Weitere Informationen und Beispiele dazu finden Sie in der InstructLab-Dokumentation. Wir haben hier auch eine Reihe von Laborübungen.
Mit den hinzugefügten zusätzlichen Taxonomiedaten ist es nun möglich, neue synthetische Daten zu generieren, um schließlich ein neues Modell zu trainieren. Allerdings muss vor Beginn der Generierung zunächst ein Lehrermodell gestartet werden, um den Generator bei der Erstellung neuer Daten zu unterstützen. Führen Sie in einer separaten Terminalsitzung den Befehl „serve“ aus und warten Sie, bis der VLLM-Start abgeschlossen ist. Beachten Sie, dass dieser Vorgang mehrere Minuten dauern kann
ilab serve
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit) Da VLLM nun den Lehrermodus bedient, kann der Generierungsprozess mit dem ilab Generate-Befehl gestartet werden. Dieser Vorgang nimmt einige Zeit in Anspruch und gibt bei der Aktualisierung kontinuierlich die Gesamtzahl der generierten Anweisungen aus. Der Standardwert beträgt 5000 Anweisungen, Sie können dies jedoch mit der Option --num-instructions anpassen.
ilab generate Q> How do cytokines influence the outcome of certain diseases involving tonsils?
A> The outcome of infectious, autoimmune, or malignant diseases affecting tonsils may be influenced by the overall balance of production profiles of pro-inflammatory and anti-inflammatory cytokines. Determining cytokine profiles in tonsil studies is essential for understanding the causes and underlying mechanisms of these disorders.
35%|████████████████████████████████████████▉
Zusätzlich zu den aktuellen Daten, die während der Generierung auf dem Bildschirm ausgegeben werden, wird eine vollständige Ausgabe im generierten Ordner aufgezeichnet. Vor dem Training wird empfohlen, diese Ausgabe zu überprüfen, um sicherzustellen, dass sie den Erwartungen entspricht. Wenn es nicht zufriedenstellend ist, versuchen Sie, die Taxonomie zu ändern oder neue Beispiele zu erstellen und sie erneut auszuführen.
less generated/generated_Mixtral * .jsonSobald die generierten Daten zufriedenstellend sind, kann der Trainingsprozess beginnen. Schließen Sie jedoch zunächst die VLLM-Instanz in der Terminalsitzung, die zur Generierung gestartet wurde.
CTRL+C
INFO: Application shutdown complete.
INFO: Finished server process [1]
Möglicherweise erhalten Sie eine Python-KeyboardInterrupt-Ausnahme und einen Stack-Trace. Dies kann getrost ignoriert werden.
Nachdem VLLM gestoppt und die neuen Daten generiert wurden, kann der Trainingsprozess mit dem Befehl ilab train gestartet werden. Standardmäßig speichert der Trainingsprozess nach jeweils 4999 Stichproben einen Modellprüfpunkt. Sie können dies mit dem Parameter --num-samples anpassen. Darüber hinaus läuft das Training standardmäßig über 10 Epochen, was auch mit dem Parameter --num-epochs angepasst werden kann. Im Allgemeinen sind mehr Epochen besser, aber ab einem bestimmten Punkt führen mehr Epochen zu einer Überanpassung. Normalerweise wird empfohlen, innerhalb von 10 oder weniger Epochen zu bleiben und verschiedene Stichprobenpunkte zu betrachten, um das beste Ergebnis zu erzielen.
ilab train --num-epochs 9 RunningAvgSamplesPerSec=149.4829861942806, CurrSamplesPerSec=161.99957513920629, MemAllocated=22.45GB, MaxMemAllocated=29.08GB
throughput: 161.84935045724643 samples/s, lr: 1.3454545454545455e-05, loss: 0.840185821056366 cuda_mem_allocated: 22.45188570022583 GB cuda_malloc_retries: 0 num_loss_counted_tokens: 8061.0 batch_size: 96.0 total loss: 0.8581467866897583
Epoch 1: 100%|█████████████████████████████████████████████████████████| 84/84 [01:09<00:00, 1.20it/s]
total length: 2527 num samples 15 - rank: 6 max len: 187 min len: 149
Sobald der Trainingsprozess abgeschlossen ist, werden die neuen Modelleinträge im Modellverzeichnis gespeichert und die Standorte auf dem Terminal ausgedruckt
Generated model in /root/workspace/models/tuned-0504-0051:
.
./samples_4992
./samples_9984
./samples_14976
./samples_19968
./samples_24960
./samples_29952
./samples_34944
./samples_39936
./samples_44928
./samples_49920
Derselbe ilab serve -Befehl kann verwendet werden, um das neue Modell bereitzustellen, indem die Option –model mit dem Namen und dem Beispiel übergeben wird
ilab serve --model tuned-0504-0051/samples_49920 Nachdem VLLM mit dem neuen Modell gestartet wurde, kann eine Chat-Sitzung gestartet werden, indem eine neue Terminalsitzung erstellt und derselbe Parameter --model an den Chat übergeben wird (Beachten Sie, dass Sie eine 404-Fehlermeldung erhalten, wenn dieser nicht übereinstimmt). Stellen Sie ihm eine Frage zu Ihren Taxonomiebeiträgen.
ilab chat --model tuned-0504-0051/samples_49920╭─────────────────────────────── system ────────────────────────────────╮
│ Welcome to InstructLab Chat w/ │
│ /INSTRUCTLAB/MODELS/TUNED-0504-0051/SAMPLES_49920 (type /h for help) │
╰───────────────────────────────────────────────────────────────────────╯
>>> What are tonsils ?
╭────────── /instructlab/models/tuned-0504-0051/samples_49920 ──────────╮
│ │
│ Tonsils are a type of mucosal lymphatic tissue found in the │
│ aerodigestive tracts of various mammals, including humans. In the │
│ human body, the tonsils play a crucial role in protecting the body │
│ from infections, particularly those caused by bacteria and viruses. │
╰─────────────────────────────────────────────── elapsed 0.469 seconds ─╯Um die Sitzung zu beenden, geben Sie
exitein
Das ist es! Der Zweck einer Entwicklervorschau besteht darin, unseren Benutzern frühzeitig Feedback zu geben. Wir sind uns bewusst, dass es möglicherweise Fehler gibt. Und wir wissen Ihre Zeit und Mühe zu schätzen, wenn Sie es bis hierher geschafft haben. Es besteht die Möglichkeit, dass Sie auf ein Problem stoßen oder eine Fehlerbehebung durchführen müssen. Wir empfehlen Ihnen, Fehlerberichte und Funktionsanfragen einzureichen und uns Fragen zu stellen. Wie das geht, erfahren Sie in den unten stehenden Kontaktinformationen. Danke schön!
$ sudo subscription-manager config --rhsm.manage_repos=1nvidia-smi um sicherzustellen, dass die Treiber funktionieren und die GPUs sehen könnennvtop (verfügbar in EPEL), um zu sehen, ob die GPUs verwendet werden (einige Codepfade verfügen über CPU-Fallback, was wir hier nicht wollen)make prune aus dem Unterverzeichnis „Training“ aus. Dadurch werden alte Build-Artefakte bereinigt.--no-cache an den Build-Prozess übergeben wird make nvidia-bootc CONTAINER_TOOL_EXTRA_ARGS= " --no-cache "TMPDIR erfolgen: make < platform > TMPDIR=/path/to/tmp

