self instruct
1.0.0
Dieses Repository enthält Code und Daten für das Self-Instruct-Papier, eine Methode zum Ausrichten vorab trainierter Sprachmodelle an Anweisungen.
Self-Instruct ist ein Framework, das Sprachmodellen dabei hilft, ihre Fähigkeit zu verbessern, Anweisungen in natürlicher Sprache zu befolgen. Dies geschieht, indem die eigenen Generationen des Modells verwendet werden, um eine große Sammlung von Lehrdaten zu erstellen. Mit Self-Instruct ist es möglich, die Befehlsfolgefähigkeiten von Sprachmodellen zu verbessern, ohne auf umfangreiche manuelle Anmerkungen angewiesen zu sein.
In den letzten Jahren besteht ein wachsendes Interesse an der Erstellung von Modellen, die Anweisungen in natürlicher Sprache befolgen können, um ein breites Spektrum an Aufgaben auszuführen. Diese als „anweisungsabgestimmte“ Sprachmodelle bekannten Modelle haben die Fähigkeit zur Verallgemeinerung auf neue Aufgaben bewiesen. Ihre Leistung hängt jedoch stark von der Qualität und Quantität der von Menschen geschriebenen Instruktionsdaten ab, die zu ihrer Ausbildung verwendet werden, was in ihrer Vielfalt und Kreativität begrenzt sein kann. Um diese Einschränkungen zu überwinden, ist es wichtig, alternative Ansätze zur Überwachung von anweisungsabgestimmten Modellen und zur Verbesserung ihrer Fähigkeiten zur Befolgung von Anweisungen zu entwickeln.
Der Self-Instruct-Prozess ist ein iterativer Bootstrapping-Algorithmus, der mit einem Seed-Set manuell geschriebener Anweisungen beginnt und diese verwendet, um das Sprachmodell dazu zu veranlassen, neue Anweisungen und entsprechende Eingabe-Ausgabe-Instanzen zu generieren. Diese Generationen werden dann gefiltert, um minderwertige oder ähnliche Generationen zu entfernen, und die resultierenden Daten werden wieder dem Aufgabenpool hinzugefügt. Dieser Vorgang kann mehrmals wiederholt werden, was zu einer großen Sammlung von Unterrichtsdaten führt, die zur Feinabstimmung des Sprachmodells verwendet werden können, um Anweisungen effektiver zu befolgen.
Hier ist eine Übersicht über Self-Instruct:
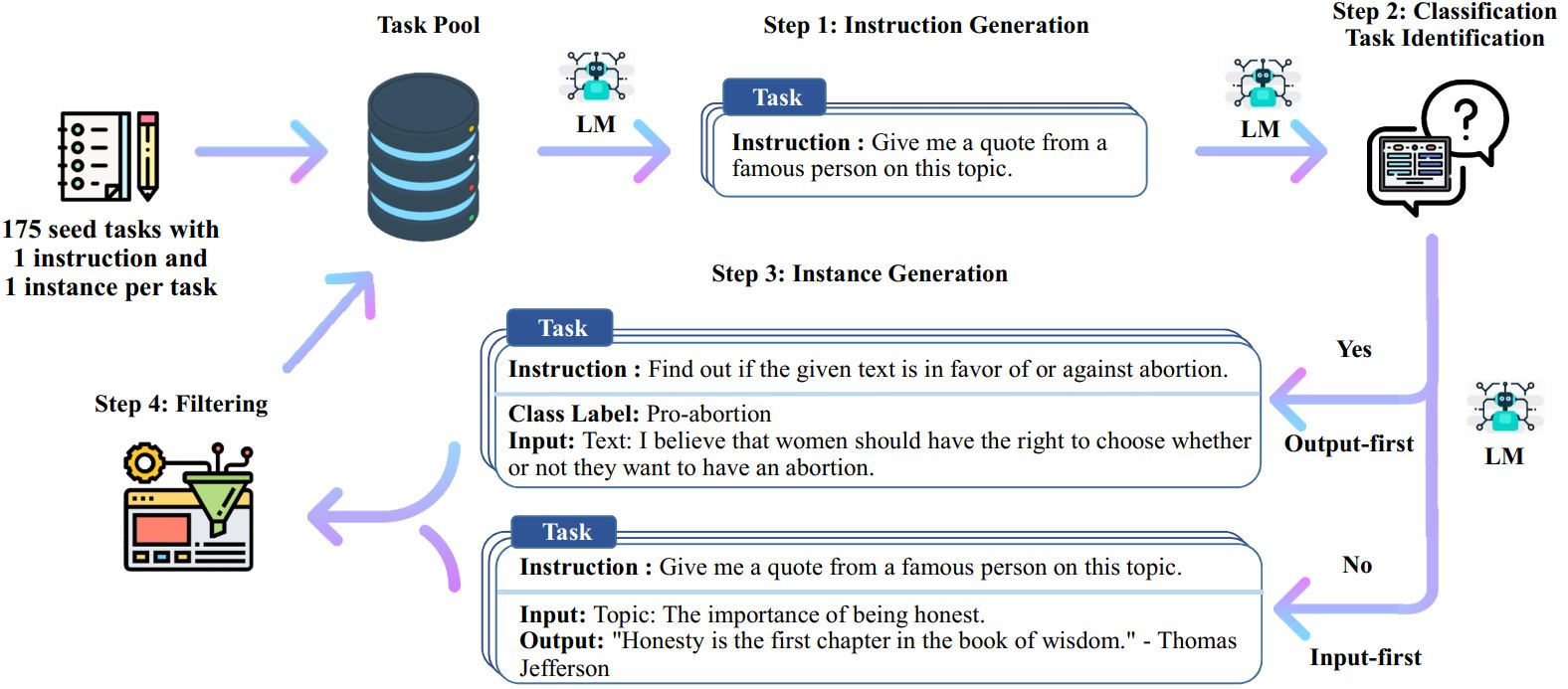
* Diese Arbeit ist noch in Bearbeitung. Wir können den Code und die Daten aktualisieren, wenn wir Fortschritte machen. Bitte seien Sie vorsichtig bei der Versionskontrolle.
Wir veröffentlichen einen Datensatz, der 52.000 Anweisungen enthält, gepaart mit 82.000 Instanzeingängen und -ausgängen. Diese Befehlsdaten können verwendet werden, um eine Befehlsoptimierung für Sprachmodelle durchzuführen und dafür zu sorgen, dass das Sprachmodell den Anweisungen besser folgt. Auf die gesamten modellgenerierten Daten kann in data/gpt3-generations/batch_221203/all_instances_82K.jsonl zugegriffen werden. Diese Daten (+ die 175 Seed-Aufgaben), neu formatiert im sauberen GPT3-Finetuning-Format (Eingabeaufforderung + Abschluss), werden in data/finetuning/self_instruct_221203 abgelegt. Sie können das Skript in ./scripts/finetune_gpt3.sh verwenden, um GPT3 anhand dieser Daten zu optimieren.
Hinweis : Diese Daten werden von einem Sprachmodell (GPT3) generiert und enthalten zwangsläufig einige Fehler oder Verzerrungen. Wir haben die Datenqualität von 200 zufälligen Anweisungen in unserem Artikel analysiert und festgestellt, dass 46 % der Datenpunkte möglicherweise Probleme aufweisen. Wir empfehlen Benutzern, diese Daten mit Vorsicht zu verwenden und neue Methoden zum Filtern oder Verbessern der Mängel vorzuschlagen.
Wir veröffentlichen außerdem einen neuen Satz von 252 von Experten geschriebenen Aufgaben und deren Anweisungen, die auf benutzerorientierten Anwendungen basieren (und nicht auf gut untersuchten NLP-Aufgaben). Diese Daten werden im Abschnitt zur menschlichen Bewertung des Selbstlernpapiers verwendet. Weitere Einzelheiten finden Sie in der README-Datei zur menschlichen Bewertung.
Um Self-Instruct-Daten mit Ihren eigenen Seed-Aufgaben oder anderen Modellen zu generieren, stellen wir hier unsere Skripte für die gesamte Pipeline als Open Source zur Verfügung. Unser aktueller Code wird nur auf dem GPT3-Modell getestet, auf das über die OpenAI-API zugegriffen werden kann.
Hier sind die Skripte zum Generieren der Daten:
# 1. Generieren Sie Anweisungen aus den Seed-Aufgaben./scripts/generate_instructions.sh# 2. Identifizieren Sie, ob die Anweisung eine Klassifizierungsaufgabe darstellt oder nicht./scripts/is_clf_or_not.sh# 3. Generieren Sie Instanzen für jede Anweisung./scripts/generate_instances. sh# 4. Filtern, Verarbeiten und Neuformatieren./scripts/prepare_for_finetuning.sh
Wenn Sie das Self-Instruct-Framework oder die Daten verwenden, können Sie uns gerne zitieren.
@misc{selfinstruct, title={Self-Instruct: Sprachmodell mit selbstgenerierten Anweisungen ausrichten}, Autor={Wang, Yizhong und Kordi, Yeganeh und Mishra, Swaroop und Liu, Alisa und Smith, Noah A. und Khashabi, Daniel und Hajishirzi, Hannaneh}, journal={arXiv preprint arXiv:2212.10560}, Jahr={2022}} 

