bertsearch
1.0.0
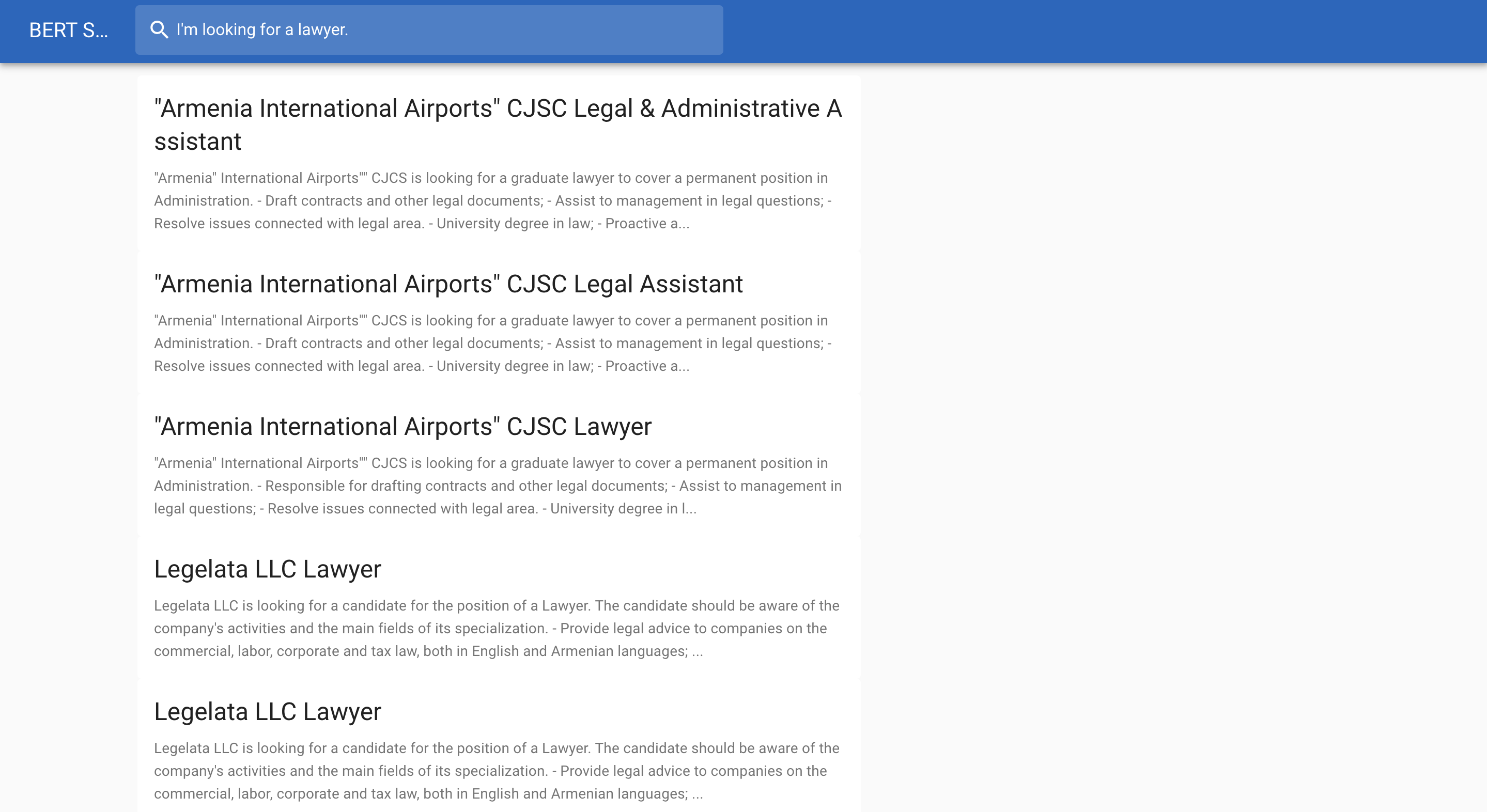
Nachfolgend finden Sie ein Beispiel für eine Jobsuche:
| BERT-Basis, ohne Gehäuse | 12 Schichten, 768 versteckt, 12 Köpfe, 110 Millionen Parameter |
| BERT-Groß, ohne Gehäuse | 24 Schichten, 1024 versteckt, 16 Köpfe, 340 Millionen Parameter |
| BERT-Basis, verpackt | 12 Schichten, 768 versteckt, 12 Köpfe, 110 Millionen Parameter |
| BERT-Groß, verpackt | 24 Schichten, 1024 versteckt, 16 Köpfe, 340 Millionen Parameter |
| BERT-Base, mehrsprachiges Gehäuse (Neu) | 104 Sprachen, 12 Ebenen, 768 versteckte Sprachen, 12 Köpfe, 110 Millionen Parameter |
| BERT-Base, mehrsprachiges Gehäuse (alt) | 102 Sprachen, 12 Ebenen, 768 versteckte Sprachen, 12 Köpfe, 110 Millionen Parameter |
| BERT-Base, Chinesisch | Vereinfachtes und traditionelles Chinesisch, 12 Ebenen, 768 versteckt, 12 Köpfe, 110 Millionen Parameter |
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zipSie müssen ein vorab trainiertes BERT-Modell und den Indexnamen von Elasticsearch als Umgebungsvariablen festlegen:
$ export PATH_MODEL=./cased_L-12_H-768_A-12
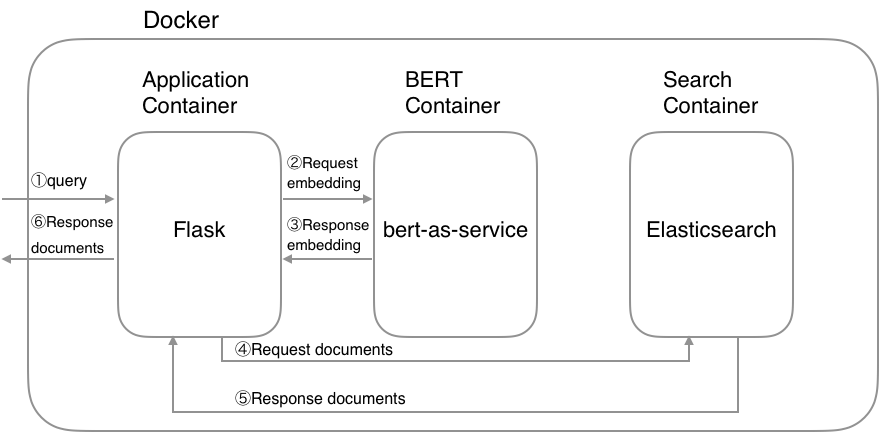
$ export INDEX_NAME=jobsearch$ docker-compose up ACHTUNG : Wenn möglich, weisen Sie der Docker-Speicherkonfiguration hohen Speicher (mehr als 8GB ) zu, da der BERT-Container viel Speicher benötigt.
Sie können die API zum Erstellen eines Index verwenden, um einem Elasticsearch-Cluster einen neuen Index hinzuzufügen. Beim Erstellen eines Index können Sie Folgendes angeben:
Wenn Sie beispielsweise einen jobsearch mit den Feldern title , text und text_vector erstellen möchten, können Sie den Index mit dem folgenden Befehl erstellen:
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
" settings " : {
" number_of_shards " : 2,
" number_of_replicas " : 1
},
" mappings " : {
" dynamic " : " true " ,
" _source " : {
" enabled " : " true "
},
" properties " : {
" title " : {
" type " : " text "
},
" text " : {
" type " : " text "
},
" text_vector " : {
" type " : " dense_vector " ,
" dims " : 768
}
}
}
} ACHTUNG : Der dims Wert von text_vector muss mit den Dims eines vorab trainierten BERT-Modells übereinstimmen.
Sobald Sie einen Index erstellt haben, können Sie ein Dokument indizieren. Hier geht es darum, Ihr Dokument mithilfe von BERT in einen Vektor umzuwandeln. Der resultierende Vektor wird im Feld text_vector gespeichert. Lassen Sie uns Ihre Daten in ein JSON-Dokument konvertieren:
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
" Title " , " Description "
" Saleswoman " , " lorem ipsum "
" Software Developer " , " lorem ipsum "
" Chief Financial Officer " , " lorem ipsum "
" General Manager " , " lorem ipsum "
" Network Administrator " , " lorem ipsum "Nach Abschluss des Skripts können Sie ein JSON-Dokument wie folgt erhalten:
# documents.jsonl
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Saleswoman" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Software Developer" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Chief Financial Officer" , "text_vector" : [...]}
...Nachdem Sie Ihre Daten in JSON konvertiert haben, können Sie dem angegebenen Index ein JSON-Dokument hinzufügen und es durchsuchbar machen.
$ python example/index_documents.pyGehen Sie zu http://127.0.0.1:5000.


