MyScaleDB
v1.8.0

Ermöglichen Sie jedem Entwickler die Erstellung produktionstauglicher GenAI-Anwendungen mit leistungsstarkem und vertrautem SQL.
MyScaleDB ist die SQL-Vektordatenbank, die es Entwicklern ermöglicht, produktionsbereite und skalierbare KI-Anwendungen mit vertrautem SQL zu erstellen. Es basiert auf ClickHouse und ist für KI-Anwendungen und -Lösungen optimiert, sodass Entwickler große Datenmengen effektiv verwalten und verarbeiten können.
Zu den wichtigsten Vorteilen der Verwendung von MyScaleDB gehören:
Vollständig SQL-kompatibel
Schnelle, leistungsstarke und effiziente Vektorsuche, gefilterte Suche und SQL-Vektor-Join-Abfragen.
Verwenden Sie SQL mit vektorbezogenen Funktionen, um mit MyScaleDB zu interagieren. Sie müssen keine komplexen neuen Tools oder Frameworks erlernen – bleiben Sie bei dem, was Sie kennen und lieben.
Produktionsbereit für KI-Anwendungen
Eine einheitliche und bewährte Plattform zur Verwaltung und Verarbeitung strukturierter Daten, Text-, Vektor-, JSON-, Geodaten-, Zeitreihendaten und mehr. Siehe unterstützte Datentypen und Funktionen
Verbesserte RAG-Genauigkeit durch Kombination von Vektoren mit umfangreichen Metadaten, Volltextsuche und Durchführung einer hochpräzisen, hocheffizienten gefilterten Suche in jedem Verhältnis 1 .
Unübertroffene Leistung und Skalierbarkeit
MyScaleDB nutzt modernste OLAP-Datenbankarchitektur und fortschrittliche Vektoralgorithmen für blitzschnelle Vektoroperationen.
Skalieren Sie Ihre Anwendungen mühelos und kostengünstig, wenn Ihre Daten wachsen.
MyScale Cloud bietet vollständig verwaltete MyScaleDB mit Premium-Funktionen für milliardenschwere Daten 2 . Im Vergleich zu spezialisierten Vektordatenbanken, die benutzerdefinierte APIs verwenden, ist MyScale leistungsfähiger, leistungsfähiger und kostengünstiger und gleichzeitig einfacher zu verwenden. Dadurch ist es für eine große Community von Programmierern geeignet. Darüber hinaus verbraucht MyScale im Vergleich zu integrierten Vektordatenbanken wie PostgreSQL mit pgvector oder ElasticSearch mit Vektorerweiterungen weniger Ressourcen und erreicht eine bessere Genauigkeit und Geschwindigkeit für strukturierte und vektorübergreifende Abfragen, wie z. B. gefilterte Suchen.
Vollständig SQL-kompatibel
Einheitliches strukturiertes und vektorisiertes Datenmanagement
Millisekundensuche auf Vektoren im Milliardenmaßstab
Äußerst zuverlässig und linear skalierbar
Leistungsstarke Textsuch- und Text/Vektor-Hybridsuchfunktionen
Komplexe SQL-Vektorabfragen
LLM-Beobachtbarkeit mit MyScale Telemetry
MyScale vereint drei Systeme: SQL-Datenbank/Data Warehouse, Vektordatenbank sowie Volltextsuchmaschine auf hocheffiziente Weise in einem System. Dies spart nicht nur Infrastruktur- und Wartungskosten, sondern ermöglicht auch gemeinsame Datenabfragen und -analysen.
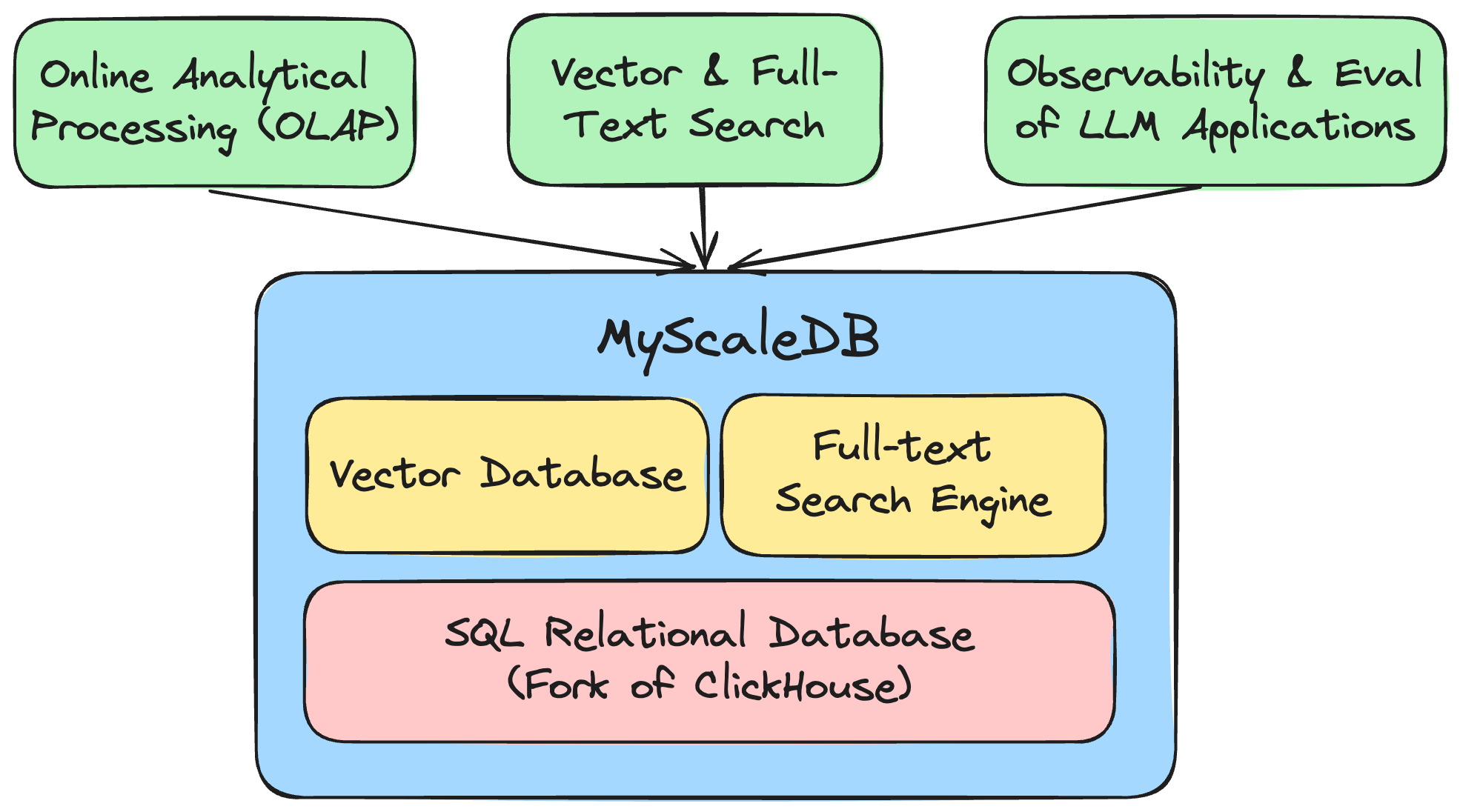
Weitere Informationen zu den einzigartigen Funktionen und Vorteilen von MyScale finden Sie in unserer Dokumentation und in unseren Blogs. Unser Open-Source-Benchmark bietet einen detaillierten Vergleich mit anderen Vektordatenbankprodukten.
ClickHouse ist eine beliebte Open-Source-Analysedatenbank, die sich aufgrund ihrer spaltenbasierten Speicherung mit erweiterter Komprimierung, Skip-Indizierung und SIMD-Verarbeitung hervorragend für die Verarbeitung und Analyse großer Datenmengen eignet. Im Gegensatz zu Transaktionsdatenbanken wie PostgreSQL und MySQL, die Zeilenspeicher und Hauptoptimierungen für die Transaktionsverarbeitung verwenden, verfügt ClickHouse über deutlich schnellere Analyse- und Datenscangeschwindigkeiten.
Eine der Schlüsseloperationen bei der Kombination von strukturierter und Vektorsuche ist die gefilterte Suche, bei der zuerst nach anderen Attributen gefiltert und dann die Vektorsuche für die verbleibenden Daten durchgeführt wird. Spaltenspeicherung und Vorfilterung sind entscheidend für die Gewährleistung einer hohen Genauigkeit und Leistung bei der gefilterten Suche. Aus diesem Grund haben wir uns entschieden, MyScaleDB auf ClickHouse aufzubauen.
Während wir die Ausführungs- und Speicher-Engine von ClickHouse in vielerlei Hinsicht modifiziert haben, um schnelle und kostengünstige SQL-Vektorabfragen zu gewährleisten, wurden viele der Funktionen (#37893, #38048, #37859, #56728, #58223) im Zusammenhang mit der allgemeinen SQL-Verarbeitung geändert hat einen Beitrag zur Open-Source-Community von ClickHouse geleistet.
Die einfachste Möglichkeit, MyScaleDB zu verwenden, besteht darin, eine Instanz im MyScale Cloud-Dienst zu erstellen. Sie können mit einem kostenlosen Pod beginnen, der 5 Mio. 768D-Vektoren unterstützt. Melden Sie sich hier an und schauen Sie sich MyScaleDB QuickStart an, um weitere Anweisungen zu erhalten.
Um eine MyScaleDB-Instanz schnell zum Laufen zu bringen, ziehen Sie einfach das neueste Docker-Image herunter und führen Sie es aus:
docker run --name myscaledb --net=host myscale/myscaledb:1.8.0
Hinweis: Die Standardkonfiguration von Myscale erlaubt nur den Zugriff auf die lokale Host-IP. Für die Startmethode „Docker Run“ müssen Sie
--net=hostangeben, um auf Dienste zuzugreifen, die im Docker-Modus auf dem aktuellen Knoten bereitgestellt werden.
Dadurch wird eine MyScaleDB-Instanz mit dem default und ohne Passwort gestartet. Anschließend können Sie mit clickhouse-client eine Verbindung zur Datenbank herstellen:
docker exec -it myscaledb clickhouse-client
Verwenden Sie die folgende empfohlene Verzeichnisstruktur und den Speicherort der Datei docker-compose.yaml :
> Baum myscaledb
myscaledb
├── docker-compose.yaml
└── Bände
└── Konfig
└── Benutzer.d
└── custom_users_config.xml
3 Verzeichnisse, 2 Dateien Definieren Sie die Konfiguration für Ihre Bereitstellung. Wir empfehlen, mit der folgenden Konfiguration in Ihrer docker-compose.yaml Datei zu beginnen, die Sie je nach Ihren spezifischen Anforderungen anpassen können:
Version: '3.7'services: myscaledb:image: myscale/myscaledb:1.8.0tty: trueports:
- '8123:8123' - '9000:9000' - '8998:8998' - '9363:9363' - '9116:9116'networks: myscaledb_network:ipv4_address: 10.0.0.2volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/data:/var/lib/clickhouse - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/log:/var/log/clickhouse-server - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/config/users.d/custom_users_config.xml:/etc/clickhouse-server/users.d/custom_users_config.xmldeploy: resources:limits: cpus: "16.00" Speicher: 32Gbnetworks: myscaledb_network: Treiber: Bridgeipam: Treiber: Standardkonfiguration:
- Subnetz: 10.0.0.0/24 custom_users_config.xml :
<clickhouse>
<Benutzer>
<Standard>
<Passwort></Passwort>
<Netzwerke>
<ip>::1</ip>
<ip>127.0.0.1</ip>
<ip>10.0.0.0/24</ip>
</networks>
<profile>Standard</profile>
<quota>Standard</quota>
<access_management>1</access_management>
</default>
</users>
</clickhouse>Hinweis: Mit der Konfiguration „custom_users_config“ können Sie den Standardbenutzer für den Zugriff auf die Datenbank auf dem Knoten verwenden, auf dem der Datenbankdienst mithilfe von Docker Compose bereitgestellt wird. Wenn Sie auf anderen Knoten auf den Datenbankdienst zugreifen möchten, empfiehlt es sich, einen Benutzer anzulegen, der über andere IPs erreichbar ist. Detaillierte Einstellungen finden Sie unter: MyScaleDB Benutzer erstellen. Sie können auch die Konfigurationsdatei von MyScaleDB anpassen. Kopieren Sie das Verzeichnis
/etc/clickhouse-serveraus Ihremmyscaledb-Container auf Ihr lokales Laufwerk, ändern Sie die Konfiguration und fügen Sie eine Verzeichniszuordnung zur Dateidocker-compose.yamlhinzu, damit die Konfiguration wirksam wird:- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/config:/etc/clickhouse-server
Verwenden Sie den folgenden Befehl, um es zum Laufen zu bringen:
cd myscaledb Docker komponieren -d
Greifen Sie mit dem folgenden Befehl auf die MyScaleDB-Befehlszeilenschnittstelle zu.
docker exec -it myscaledb-myscaledb-1 clickhouse-client
Sie können jetzt SQL-Anweisungen ausführen. Siehe Ausführen von SQL-Abfragen.
Die unterstützte Build-Umgebung ist Ubuntu 22.04 mit LLVM 15.0.7.
Bitte sehen Sie sich den Skriptordner an.
Beispielverwendung:
LLVM_VERSION=15 sudo -E bash scripts/install_deps.sh Sudo apt-get -y installiere Rustc Cargo Yasm bash scripts/config_on_linux.sh Bash-Skripte/build_on_linux.sh
Die resultierenden ausführbaren Dateien befinden sich in MyScaleDB/build/programs/* .
Informationen zum Erstellen einer SQL-Tabelle mit Vektorindex und zum Durchführen einer Vektorsuche finden Sie in der Dokumentation zur Vektorsuche. Es wird empfohlen TYPE SCANN anzugeben, wenn Sie einen Vektorindex in Open Source MyScaleDB erstellen.
-- Erstellen Sie eine Tabelle mit body_vector der Länge 384CREATE TABLE default.wiki_abstract (`id` UInt64,`body` String,`title` String,`url` String,`body_vector` Array(Float32),CONSTRAINT check_length CHECK length(body_vector) = 384) ENGINE = MergeTreeORDER BY id;
– Daten aus Parkettdateien auf S3 einfügenINSERT INTO default.wiki_abstract SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_with_vector.parquet','Parquet'); – Erstellen Sie einen SCANN-Vektorindex mit Kosinus-Metrik in der Tabelle „body_vectorALTER“. default.wiki_abstract ADD VECTOR INDEX vec_idx body_vector TYPE SCANN('metric_type=Cosine'); Indexfortschritt wird zu „Built“ SELECT * FROM system.vector_indices;- Führen Sie eine Vektorsuche durch und geben Sie die Top-5-Ergebnisse zurück. AUSWÄHLEN Ausweis, Titel, distance(body_vector, [-0.052, -0.0146, -0.0677, -0.0256, -0.0395, -0.0381, -0.025, 0.0911, -0.0429, -0.0592, 0.0017, -0.0358, -0.0464, -0,0189, -0,0192, 0,0544, -0,0022, -0,0292, -0,0474, -0,0286, 0,0746, -0,013, -0,0217, -0,0246, -0,0169, 0,0495, -0,0947, 0,0139, 0,0445, -0,0262, -0,0049, 0,0506, 0,004, 0,0276, 0,0063, -0,0643, 0,0059, -0,0229, -0,0315, 0,0549, 0,1427, 0,0079, 0,011, -0,0036, -0,0617, 0,0155, -0,0607, 0,0258, -0,0205, 0,0008, -0,0547, 0,0329, -0,0522, -0,0347, 0,0921, 0,0139, -0,013, 0,0716, -0,0165, 0,0257, -0,0071, 0,0084, -0,0653, 0,0091, 0,0544, -0,0192, -0,0169, -0,0017, -0,0304, 0,0427, -0,0389, 0,0921, -0,0622, -0,0196, 0,0025, 0,0214, 0,0259, -0,0493, -0,0211, -0,119, -0,0736, -0,1545, -0,0578, -0,0145, 0,0138, 0,0478, -0,0451, -0,0332, 0,0799, 0,0001, -0,0737, 0,0427, 0,0517, 0,0102, 0,0386, 0,0233, 0,0425, -0,0279, -0,0529, 0,0744, -0,0305, -0,026, 0,1229, -0,002, 0,0038, -0,0491, 0,0352, 0,0027, -0,056, -0,1044, 0,123, -0,0184, 0,1148, -0,0189, 0,0412, -0,0347, -0,0569, -0,0119, 0,0098, -0,0016, 0,0451, 0,0273, 0,0436, 0,0082, 0,0166, -0,0989, 0,0747, -0,0, 0,0306, -0,0717, -0,007, 0,0665, 0,0452, 0,0123, -0,0238, 0,0512, -0,0116, 0,0517, 0,0288, -0,0013, 0,0176, 0,0762, 0,1284, -0,031, 0,0891, -0,0286, 0,0132, 0,003, 0,0433, 0,0102, -0,0209, -0,0459, -0,0312, -0,0387, 0,0201, -0,027, 0,0243, 0,0713, 0,0359, -0,0674, -0,0747, -0,0147, 0,0489, -0,0092, -0,018, 0,0236, 0,0372, -0,0071, -0,0513, -0,0396, -0,0316, -0,0297, -0,0385, -0,062, 0,0465, 0,0539, -0,033, 0,0643, 0,061, 0,0062, 0,0245, 0,0868, 0,0523, -0,0253, 0,0157, 0,0266, 0,0124, 0,1382, -0,0107, 0,0835, -0,1057, -0,0188, -0,0786, 0,057, 0,0707, -0,0185, 0,0708, 0,0189, -0,0374, -0,0484, 0,0089, 0,0247, 0,0255, -0,0118, 0,0739, 0,0114, -0,0448, -0,016, -0,0836, 0,0107, 0,0067, -0,0535, -0,0186, -0,0042, 0,0582, -0,0731, -0,0593, 0,0299, 0,0004, -0,0299, 0,0128, -0,0549, 0,0493, 0,0, -0,0419, 0,0549, -0,0315, 0,1012, 0,0459, -0,0628, 0,0417, -0,0153, 0,0471, -0,0301, -0,0615, 0,0137, -0,0219, 0,0735, 0,083, 0,0114, -0,0326, -0,0272, 0,0642, -0,0203, 0,0557, -0,0579, 0,0883, 0,0719, 0,0007, 0,0598, -0,0431, -0,0189, -0,0593, -0,0334, 0,02, -0,0371, -0,0441, 0,0407, -0,0805, 0,0058, 0,1039, 0,0534, 0,0495, -0,0325, 0,0782, -0,0403, 0,0108, -0,0068, -0,0525, 0,0801, 0,0256, -0,0183, -0,0619, -0,0063, -0,0605, 0,0377, -0,0281, -0,0097, -0,0029, -0,106, 0,0465, -0,0033, -0,0308, 0,0357, 0,0156, -0,0406, -0,0308, 0,0013, 0,0458, 0,0231, 0,0207, -0,0828, -0,0573, 0,0298, -0,0381, 0,0935, -0,0498, -0,0979, -0,1452, 0,0835, -0,0973, -0,0172, 0,0003, 0,09, -0,0931, -0,0252, 0,008, -0,0441, -0,0938, -0,0021, 0,0885, 0,0088, 0,0034, -0,0049, 0,0217, 0,0584, -0,012, 0,059, 0,0146, -0,0, -0,0045, 0,0663, 0,0017, 0,0015, 0,0569, -0,0089, -0,0232, 0,0065, 0,0204, -0,0253, 0,1119, -0,036, 0,0125, 0,0531, 0,0584, -0,0101, -0,0593, -0,0577, -0,0656, -0,0396, 0,0525, -0,006, -0,0149, 0,003, -0,1009, -0,0281, 0,0311, -0,0088, 0,0441, -0,0056, 0,0715, 0,051, 0,0219, -0,0028, 0,0294, -0,0969, -0,0852, 0,0304, 0,0374, 0,1078, -0,0559, 0,0805, -0,0464, 0,0369, 0,0874, -0,0251, 0,0075, -0,0502, -0,0181, -0,1059, 0,0111, 0,0894, 0,0021, 0,0838, 0,0497, -0,0183, 0,0246, -0,004, -0,0828, 0,06, -0,1161, -0,0367, 0,0475, 0,0317]) AS distanceFROM default.wiki_abstractORDER BY distance ASCLIMIT 5;
Wir sind bestrebt, MyScaleDB kontinuierlich zu verbessern und weiterzuentwickeln, um den sich ständig ändernden Anforderungen der KI-Branche gerecht zu werden. Begleiten Sie uns auf dieser spannenden Reise und seien Sie Teil der Revolution im KI-Datenmanagement!
Zwietracht
Unterstützung
Erhalten Sie die neuesten MyScaleDB-Neuigkeiten oder -Updates
Folgen Sie @MyScaleDB auf Twitter
Folgen Sie @MyScale auf LinkedIn
Lesen Sie den MyScale-Blog
Invertierter Index und leistungsstarke Schlüsselwort-/Vektor-Hybridsuche (unterstützt seit 1.5)
Unterstützt weitere Speicher-Engines, z. B. ReplacingMergeTree (unterstützt seit 1.6)
LLM-Beobachtbarkeit mit MyScaleDB und MyScale Telemetry
Datenzentriertes LLM
Automatische Datenwissenschaft mit MyScaleDB
MyScaleDB ist unter der Apache-Lizenz, Version 2.0, lizenziert. Sehen Sie sich eine Kopie der Lizenzdatei an.
Wir danken besonders für diese Open-Source-Projekte, auf deren Grundlage wir MyScaleDB entwickelt haben:
ClickHouse – Ein kostenloses Analyse-DBMS für Big Data.
Faiss – Eine Bibliothek für die effiziente Ähnlichkeitssuche und Clusterung dichter Vektoren, von Meta's Fundamental AI Research.
hnswlib – Nur-Header-C++/Python-Bibliothek für schnelle ungefähre nächste Nachbarn.
ScaNN – Skalierbare Nearest Neighbors-Bibliothek von Google Research.
Tantivy – Eine von Apache Lucene inspirierte und in Rust geschriebene Volltextsuchmaschinenbibliothek.
Erfahren Sie hier, warum die Metadatenfilterung für die Verbesserung der RAG-Genauigkeit von entscheidender Bedeutung ist. ↩
Der MSTG-Algorithmus (Multi-scale Tree Graph) wird über MyScale Cloud bereitgestellt und erreicht eine hohe Datendichte mit festplattenbasierter Speicherung sowie eine bessere Indizierungs- und Suchleistung bei Vektordaten im Milliardenmaßstab. ↩


