tiny cuda nn
Version 1.6
Dabei handelt es sich um ein kleines, eigenständiges Framework zum Trainieren und Abfragen neuronaler Netze. Vor allem enthält es ein blitzschnelles „vollständig verschmolzenes“ mehrschichtiges Perzeptron (technisches Papier), eine vielseitige Hash-Kodierung mit mehreren Auflösungen (technisches Papier) sowie Unterstützung für verschiedene andere Eingabekodierungen, Verluste und Optimierer.
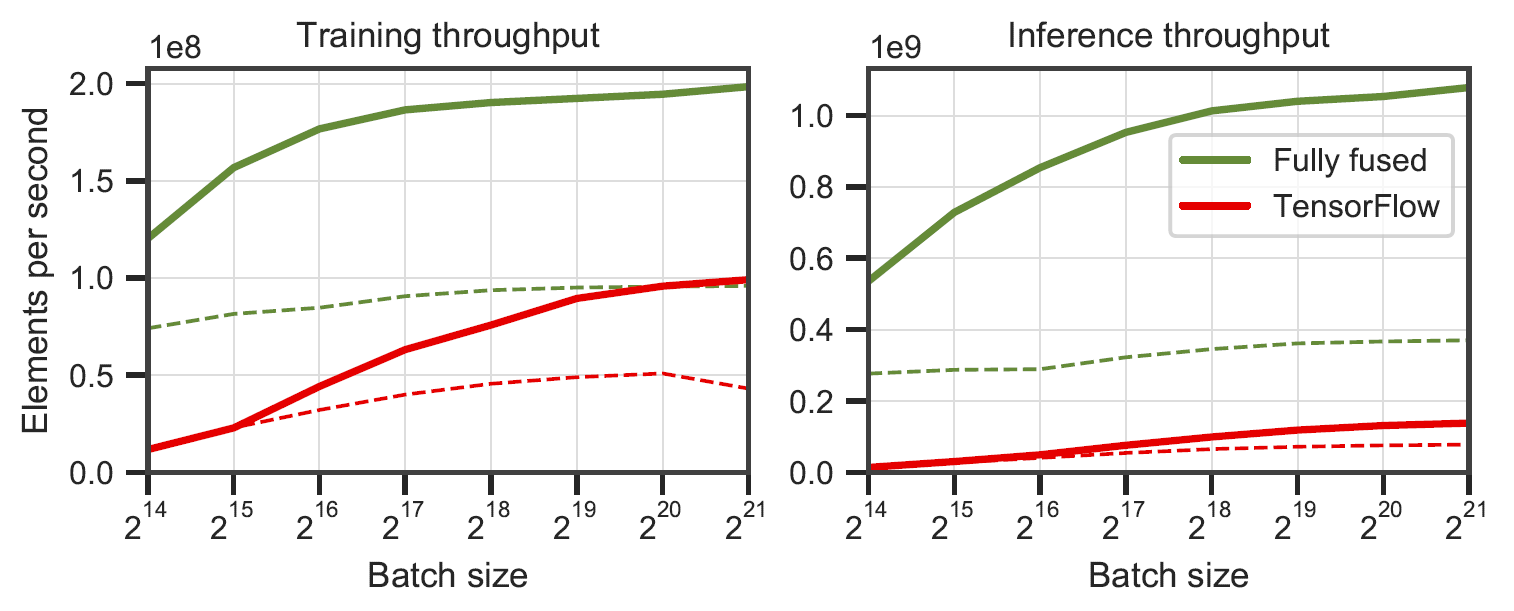 Vollständig verschmolzene Netzwerke im Vergleich zu TensorFlow v2.5.0 mit XLA. Gemessen an mehrschichtigen Perzeptronen mit einer Breite von 64 (durchgezogene Linie) und 128 (gestrichelte Linie) Neuronen auf einem RTX 3090. Generiert von
Vollständig verschmolzene Netzwerke im Vergleich zu TensorFlow v2.5.0 mit XLA. Gemessen an mehrschichtigen Perzeptronen mit einer Breite von 64 (durchgezogene Linie) und 128 (gestrichelte Linie) Neuronen auf einem RTX 3090. Generiert von benchmarks/bench_ours.cu und benchmarks/bench_tensorflow.py unter Verwendung von data/config_oneblob.json .
Winzige neuronale CUDA-Netzwerke verfügen über eine einfache C++/CUDA-API:
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);Wir stellen eine Beispielanwendung bereit, bei der eine Bildfunktion (x,y) -> (R,G,B) gelernt wird. Es kann über ausgeführt werden
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.jsonAlle paar Trainingsschritte wird ein Bild erstellt. Alle 1000 Schritte sollten bei der Standardkonfiguration auf einer RTX 4090 etwas mehr als 1 Sekunde dauern.
| 10 Schritte | 100 Schritte | 1000 Schritte | Referenzbild |
|---|---|---|---|
 |  |  |  |
n_neurons reduzieren oder stattdessen CutlassMLP verwenden (bessere Kompatibilität, aber langsamer).Wenn Sie Linux verwenden, installieren Sie die folgenden Pakete
sudo apt-get install build-essential git Wir empfehlen außerdem, CUDA in /usr/local/ zu installieren und die CUDA-Installation zu Ihrem PATH hinzuzufügen. Wenn Sie beispielsweise CUDA 11.4 haben, fügen Sie Folgendes zu Ihrer ~/.bashrc hinzu
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " Beginnen Sie mit dem Klonen dieses Repositorys und aller seiner Submodule mit dem folgenden Befehl:
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nnVerwenden Sie dann CMake, um das Projekt zu erstellen: (unter Windows muss dies in einer Entwickler-Eingabeaufforderung erfolgen)
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j Wenn die Kompilierung aus unerklärlichen Gründen fehlschlägt oder länger als eine Stunde dauert, ist möglicherweise nicht mehr genügend Arbeitsspeicher vorhanden. Versuchen Sie in diesem Fall, den obigen Befehl ohne -j auszuführen.
tiny-cuda-nn wird mit einer PyTorch-Erweiterung geliefert, die die Verwendung der schnellen MLPs und Eingabekodierungen innerhalb eines Python-Kontexts ermöglicht. Diese Bindungen können deutlich schneller sein als vollständige Python-Implementierungen; insbesondere für die Multiauflösungs-Hash-Kodierung.
Der Overhead von Python/PyTorch kann dennoch umfangreich sein, wenn die Batch-Größe klein ist. Bei einer Batchgröße von 64 KB ist das gebündelte
mlp_learning_an_image-Beispiel beispielsweise über PyTorch etwa 2x langsamer als natives CUDA. Bei einer Stapelgröße von 256 KB und höher (Standard) liegt die Leistung deutlich näher.
Beginnen Sie mit der Einrichtung einer Python 3.X-Umgebung mit einer aktuellen, CUDA-fähigen Version von PyTorch. Dann rufen Sie an
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torchWenn Sie alternativ von einem lokalen Klon von tiny-cuda-nn installieren möchten, rufen Sie auf
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py installBei Erfolg können Sie tiny-cuda-nn- Modelle wie im folgenden Beispiel verwenden:
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network ) Ein Beispiel finden Sie samples/mlp_learning_an_image_pytorch.py .
Im Folgenden finden Sie eine Zusammenfassung der Komponenten dieses Frameworks. Die JSON-Dokumentation listet Konfigurationsoptionen auf.
| Netzwerke | ||
|---|---|---|
| Vollständig verschmolzenes MLP | src/fully_fused_mlp.cu | Blitzschnelle Implementierung kleiner mehrschichtiger Perzeptrone (MLPs). |
| CUTLASS MLP | src/cutlass_mlp.cu | MLP basiert auf den GEMM-Routinen von CUTLASS. Langsamer als vollständig abgesichert, bewältigt aber größere Netzwerke und ist dennoch einigermaßen schnell. |
| Eingabekodierungen | ||
|---|---|---|
| Zusammengesetzt | include/tiny-cuda-nn/encodings/composite.h | Ermöglicht das Erstellen mehrerer Kodierungen. Kann beispielsweise zum Aufbau der Neural Radiance Caching-Kodierung verwendet werden [Müller et al. 2021]. |
| Frequenz | include/tiny-cuda-nn/encodings/frequency.h | NeRFs [Mildenhall et al. 2020] Die Positionskodierung wird auf alle Dimensionen gleichermaßen angewendet. |
| Netz | include/tiny-cuda-nn/encodings/grid.h | Kodierung basierend auf trainierbaren Multiauflösungsgittern. Wird für Instant Neural Graphics Primitives verwendet [Müller et al. 2022]. Die Raster können durch Hashtabellen, dichten Speicher oder gekachelten Speicher unterstützt werden. |
| Identität | include/tiny-cuda-nn/encodings/identity.h | Lässt Werte unberührt. |
| Oneblob | include/tiny-cuda-nn/encodings/oneblob.h | Aus Neural Importance Sampling [Müller et al. 2019] und Neural Control Variates [Müller et al. 2020]. |
| Sphärische Harmonische | include/tiny-cuda-nn/encodings/spherical_harmonics.h | Eine Frequenzraumkodierung, die sich eher für Richtungsvektoren als für komponentenweise eignet. |
| TriangleWave | include/tiny-cuda-nn/encodings/triangle_wave.h | Kostengünstige Alternative zur NeRF-Kodierung. Wird beim Caching neuronaler Strahlung verwendet [Müller et al. 2021]. |
| Verluste | ||
|---|---|---|
| L1 | include/tiny-cuda-nn/losses/l1.h | Standard-L1-Verlust. |
| Relatives L1 | include/tiny-cuda-nn/losses/l1.h | Relativer L1-Verlust, normalisiert durch die Netzwerkvorhersage. |
| KARTE | include/tiny-cuda-nn/losses/mape.h | Mittlerer absoluter prozentualer Fehler (MAPE). Dasselbe wie Relative L1, jedoch durch das Ziel normalisiert. |
| SMAPE | include/tiny-cuda-nn/losses/smape.h | Symmetrischer mittlerer absoluter prozentualer Fehler (SMAPE). Dasselbe wie Relative L1, jedoch normalisiert durch den Mittelwert der Vorhersage und des Ziels. |
| L2 | include/tiny-cuda-nn/losses/l2.h | Standard-L2-Verlust. |
| Relatives L2 | include/tiny-cuda-nn/losses/relative_l2.h | Relativer L2-Verlust, normalisiert durch die Netzwerkvorhersage [Lehtinen et al. 2018]. |
| Relative L2-Leuchtdichte | include/tiny-cuda-nn/losses/relative_l2_luminance.h | Wie oben, jedoch normalisiert durch die Luminanz der Netzwerkvorhersage. Gilt nur, wenn die Netzwerkvorhersage RGB ist. Wird beim Caching neuronaler Strahlung verwendet [Müller et al. 2021]. |
| Kreuzentropie | include/tiny-cuda-nn/losses/cross_entropy.h | Standard-Kreuzentropieverlust. Gilt nur, wenn es sich bei der Netzwerkvorhersage um eine PDF-Datei handelt. |
| Varianz | include/tiny-cuda-nn/losses/variance_is.h | Standardvarianzverlust. Gilt nur, wenn es sich bei der Netzwerkvorhersage um eine PDF-Datei handelt. |
| Optimierer | ||
|---|---|---|
| Adam | include/tiny-cuda-nn/optimizers/adam.h | Implementierung von Adam [Kingma und Ba 2014], verallgemeinert auf AdaBound [Luo et al. 2019]. |
| Nowograd | include/tiny-cuda-nn/optimizers/lookahead.h | Umsetzung von Novograd [Ginsburg et al. 2019]. |
| SGD | include/tiny-cuda-nn/optimizers/sgd.h | Standardmäßiger stochastischer Gradientenabstieg (SGD). |
| Shampoo | include/tiny-cuda-nn/optimizers/shampoo.h | Implementierung des Shampoo-Optimierers 2. Ordnung [Gupta et al. 2018] mit selbst entwickelten Optimierungen sowie denen von Anil et al. [2020]. |
| Durchschnitt | include/tiny-cuda-nn/optimizers/average.h | Schließt einen weiteren Optimierer ein und berechnet einen linearen Durchschnitt der Gewichtungen über die letzten N Iterationen. Der Durchschnitt wird nur zur Schlussfolgerung verwendet (fließt nicht in das Training zurück). |
| Gestapelt | include/tiny-cuda-nn/optimizers/batched.h | Umschließt einen weiteren Optimierer und ruft den verschachtelten Optimierer einmal alle N Schritte auf dem gemittelten Gradienten auf. Hat den gleichen Effekt wie das Erhöhen der Stapelgröße, erfordert jedoch nur eine konstante Speichermenge. |
| Zusammengesetzt | include/tiny-cuda-nn/optimizers/composite.h | Ermöglicht die Verwendung mehrerer Optimierer für verschiedene Parameter. |
| EMA | include/tiny-cuda-nn/optimizers/average.h | Schließt einen weiteren Optimierer ein und berechnet einen exponentiellen gleitenden Durchschnitt der Gewichtungen. Der Durchschnitt wird nur zur Schlussfolgerung verwendet (fließt nicht in das Training zurück). |
| Exponentieller Verfall | include/tiny-cuda-nn/optimizers/exponential_decay.h | Umschließt einen weiteren Optimierer und führt einen stückweise konstanten exponentiellen Lernratenabfall durch. |
| Ausblick | include/tiny-cuda-nn/optimizers/lookahead.h | Umschließt einen weiteren Optimierer und implementiert den Lookahead-Algorithmus [Zhang et al. 2019]. |
Dieses Framework ist unter der BSD-3-Klausel-Lizenz lizenziert. Weitere Informationen finden Sie in LICENSE.txt .
Wenn Sie es in Ihrer Forschung verwenden, würden wir uns über eine Zitierung via freuen
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}Für geschäftliche Anfragen besuchen Sie bitte unsere Website und senden Sie das Formular ab: NVIDIA Research Licensing
Dieses Framework basiert unter anderem auf den folgenden Veröffentlichungen:
Sofortige neuronale Grafikprimitive mit einer Hash-Kodierung mit mehreren Auflösungen
Thomas Müller, Alex Evans, Christoph Schied, Alexander Keller
ACM Transactions on Graphics ( SIGGRAPH ), Juli 2022
Website / Papier / Code / Video / BibTeX
Extrahieren dreieckiger 3D-Modelle, Materialien und Beleuchtung aus Bildern
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, Sanja Fidler
CVPR (mündlich) , Juni 2022
Website / Papier / Video / BibTeX
Echtzeit-Caching der neuronalen Strahlung für die Pfadverfolgung
Thomas Müller, Fabrice Rousselle, Jan Novák, Alexander Keller
ACM Transactions on Graphics ( SIGGRAPH ), August 2021
Paper / AGB-Talk / Video / Interaktiver Ergebnis-Viewer / BibTeX
Sowie folgende Software:
NerfAcc: Eine allgemeine Toolbox zur NeRF-Beschleunigung
Ruilong Li, Matthew Tancik, Angjoo Kanazawa
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio: Ein Framework für die Entwicklung neuronaler Strahlungsfelder
Matthew Tancik*, Ethan Weber*, Evonne Ng*, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister, Angjoo Kanazawa
https://github.com/nerfstudio-project/nerfstudio
Wenn Ihre Publikation oder Software nicht aufgeführt ist, können Sie gerne eine Pull-Anfrage stellen.
Besonderer Dank geht an die NRC-Autoren für hilfreiche Diskussionen und an Nikolaus Binder für die Bereitstellung eines Teils der Infrastruktur dieses Frameworks sowie für seine Hilfe bei der Nutzung von TensorCores aus CUDA heraus.


