DALLE2 pytorch
1.15.6
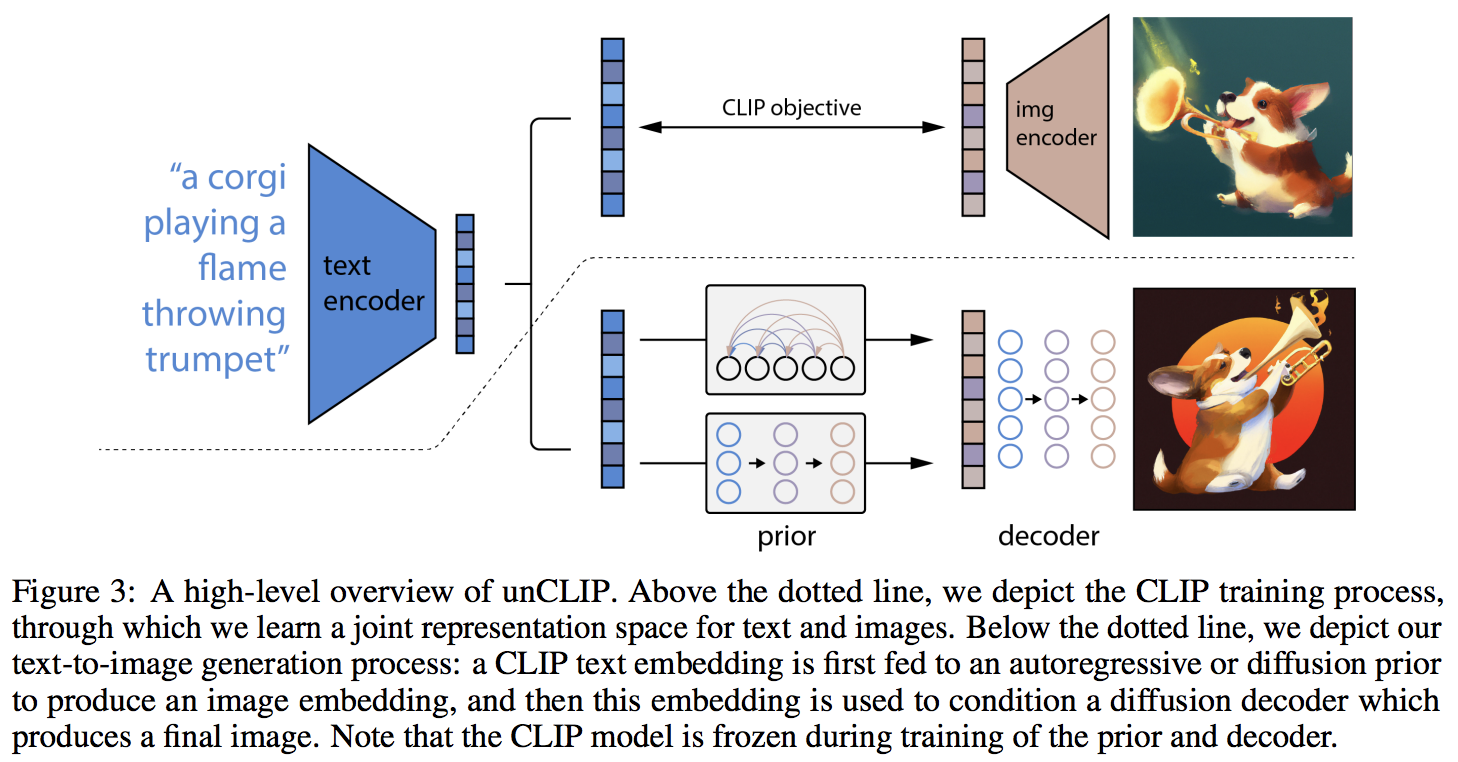
Implementierung von DALL-E 2, dem aktualisierten neuronalen Netzwerk zur Text-zu-Bild-Synthese von OpenAI, in Pytorch.
Yannic Kilcher Zusammenfassung | AssemblyAI-Erklärer
Die wichtigste Neuerung scheint eine zusätzliche Indirektionsebene mit dem vorherigen Netzwerk (sei es ein autoregressiver Transformator oder ein Diffusionsnetzwerk) zu sein, die eine Bildeinbettung basierend auf der Texteinbettung von CLIP vorhersagt. Konkret wird dieses Repository nur das Diffusion-Prior-Netzwerk aufbauen, da es die leistungsstärkste Variante ist (die aber übrigens einen Kausaltransformator als Rauschunterdrückungsnetzwerk beinhaltet?)
Dieses Modell ist derzeit SOTA für Text-zu-Bild.
Bitte treten Sie bei, wenn Sie daran interessiert sind, bei der Replikation mit der LAION-Community zu helfen | Yannic-Interview
Seit dem 23.05.22 ist es nicht mehr SOTA. SOTA wird hier sein. Jax-Versionen sowie Text-zu-Video-Projekte werden in Richtung der Imagen-Architektur verlagert, da diese viel einfacher ist.
Eine Forschungsgruppe hat den Code in diesem Repository verwendet, um vorab eine funktionale Diffusion für ihre CLIP-Generationen zu trainieren. Werden ihre Arbeit teilen, sobald sie ihren Vorabdruck veröffentlichen. Dies und Katherines eigene Experimente bestätigen die Feststellung von OpenAI, dass der zusätzliche Prior die Generationenvielfalt erhöht.
In meinem Versuchsaufbau für Oxford-Blumen wurde nun überprüft, dass der Decoder für die bedingungslose Erzeugung funktioniert. Zwei Forscher haben ebenfalls bestätigt, dass Decoder für sie funktioniert.

fortlaufend mit 21.000 Schritten
Justin Pinkney hat die Diffusion zuvor erfolgreich im Repository für seine Text-zu-Bild-Anwendung CLIP to Stylegan2 trainiert
Romain hat das Training mit den verfügbaren Skripten ohne Probleme auf 800 GPUs ausgeweitet
Ohne die Hilfe von wäre diese Bibliothek nicht in diesen funktionsfähigen Zustand gelangt
... und viele andere. Danke schön!
$ pip install dalle2-pytorchDas Training von DALLE-2 erfolgt in drei Schritten, wobei das Training von CLIP am wichtigsten ist
Um CLIP zu trainieren, können Sie entweder das x-clip-Paket verwenden oder dem LAION-Discord beitreten, wo bereits viele Replikationsbemühungen im Gange sind.
Dieses Repository demonstriert zunächst die Integration mit x-clip
import torch
from dalle2_pytorch import CLIP
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 1 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 1 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
use_all_token_embeds = True , # whether to use fine-grained contrastive learning (FILIP)
decoupled_contrastive_learning = True , # use decoupled contrastive learning (DCL) objective function, removing positive pairs from the denominator of the InfoNCE loss (CLOOB + DCL)
extra_latent_projection = True , # whether to use separate projections for text-to-image vs image-to-text comparisons (CLOOB)
use_visual_ssl = True , # whether to do self supervised learning on images
visual_ssl_type = 'simclr' , # can be either 'simclr' or 'simsiam', depending on using DeCLIP or SLIP
use_mlm = False , # use masked language learning (MLM) on text (DeCLIP)
text_ssl_loss_weight = 0.05 , # weight for text MLM loss
image_ssl_loss_weight = 0.05 # weight for image self-supervised learning loss
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train
loss = clip (
text ,
images ,
return_loss = True # needs to be set to True to return contrastive loss
)
loss . backward ()
# do the above with as many texts and images as possible in a loopAnschließend müssen Sie den Decoder trainieren, der lernt, Bilder basierend auf der Bilderinbettung zu generieren, die vom oben trainierten CLIP stammt
import torch
from dalle2_pytorch import Unet , Decoder , CLIP
# trained clip from step 1
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 1 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 1 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# unet for the decoder
unet = Unet (
dim = 128 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 )
). cuda ()
# decoder, which contains the unet and clip
decoder = Decoder (
unet = unet ,
clip = clip ,
timesteps = 100 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
# mock images (get a lot of this)
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into decoder
loss = decoder ( images )
loss . backward ()
# do the above for many many many many steps
# then it will learn to generate images based on the CLIP image embeddingsZum Schluss der Hauptbeitrag des Papiers. Das Repository bietet das Diffusions-Prioritätsnetzwerk. Es nimmt die CLIP-Texteinbettungen und versucht, die CLIP-Bildeinbettungen zu generieren. Auch hier benötigen Sie den trainierten CLIP aus dem ersten Schritt
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior , CLIP
# get trained CLIP from step one
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
). cuda ()
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed text and images into diffusion prior network
loss = diffusion_prior ( text , images )
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddingsIn dem Artikel verwendeten sie tatsächlich eine kürzlich entdeckte Technik von Jonathan Ho selbst (ursprünglicher Autor von DDPMs, der in DALL-E v2 verwendeten Kerntechnik) für die Synthese hochauflösender Bilder.
Dies kann innerhalb dieses Rahmens problemlos verwendet werden
import torch
from dalle2_pytorch import Unet , Decoder , CLIP
# trained clip from step 1
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# 2 unets for the decoder (a la cascading DDPM)
unet1 = Unet (
dim = 32 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 )
). cuda ()
unet2 = Unet (
dim = 32 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
# decoder, which contains the unet(s) and clip
decoder = Decoder (
clip = clip ,
unet = ( unet1 , unet2 ), # insert both unets in order of low resolution to highest resolution (you can have as many stages as you want here)
image_sizes = ( 256 , 512 ), # resolutions, 256 for first unet, 512 for second. these must be unique and in ascending order (matches with the unets passed in)
timesteps = 1000 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
# mock images (get a lot of this)
images = torch . randn ( 4 , 3 , 512 , 512 ). cuda ()
# feed images into decoder, specifying which unet you want to train
# each unet can be trained separately, which is one of the benefits of the cascading DDPM scheme
loss = decoder ( images , unet_number = 1 )
loss . backward ()
loss = decoder ( images , unet_number = 2 )
loss . backward ()
# do the above for many steps for both unets Schließlich werden die DALL-E2-Bilder aus Text generiert. Fügen Sie den trainierten DiffusionPrior sowie den Decoder ein (der CLIP , den Kausaltransformator und unet(s) umschließt).
from dalle2_pytorch import DALLE2
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
# send the text as a string if you want to use the simple tokenizer from DALLE v1
# or you can do it as token ids, if you have your own tokenizer
texts = [ 'glistening morning dew on a flower petal' ]
images = dalle2 ( texts ) # (1, 3, 256, 256)Das ist es!
Sehen wir uns das gesamte Skript unten an
import torch
from dalle2_pytorch import DALLE2 , DiffusionPriorNetwork , DiffusionPrior , Unet , Decoder , CLIP
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train
loss = clip (
text ,
images ,
return_loss = True
)
loss . backward ()
# do above for many steps ...
# prior networks (with transformer)
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 1000 ,
sample_timesteps = 64 ,
cond_drop_prob = 0.2
). cuda ()
loss = diffusion_prior ( text , images )
loss . backward ()
# do above for many steps ...
# decoder (with unet)
unet1 = Unet (
dim = 128 ,
image_embed_dim = 512 ,
text_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
cond_on_text_encodings = True # set to True for any unets that need to be conditioned on text encodings
). cuda ()
unet2 = Unet (
dim = 16 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
decoder = Decoder (
unet = ( unet1 , unet2 ),
image_sizes = ( 128 , 256 ),
clip = clip ,
timesteps = 100 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
for unet_number in ( 1 , 2 ):
loss = decoder ( images , text = text , unet_number = unet_number ) # this can optionally be decoder(images, text) if you wish to condition on the text encodings as well, though it was hinted in the paper it didn't do much
loss . backward ()
# do above for many steps
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
images = dalle2 (
[ 'cute puppy chasing after a squirrel' ],
cond_scale = 2. # classifier free guidance strength (> 1 would strengthen the condition)
)
# save your image (in this example, of size 256x256)Alles in dieser Readme-Datei sollte fehlerfrei laufen
Sie können den Decoder auch auf Bilder trainieren, die größer sind als die Größe (z. B. 512 x 512), bei der CLIP trainiert wurde (256 x 256). Die Größe der Bilder wird für die Bildeinbettungen auf die CLIP-Bildauflösung geändert
Für den Laien keine Sorge, die gesamte Schulung wird in einem CLI-Tool automatisiert, zumindest für Schulungen in kleinem Umfang.
Bei der Skalierung ist es wahrscheinlich, dass Sie Ihre Bilder und Texte zunächst in entsprechende Einbettungen vorverarbeiten, bevor Sie das vorherige Netzwerk trainieren. Sie können dies ganz einfach tun, indem Sie einfach image_embed , text_embed und optional text_encodings übergeben
Arbeitsbeispiel unten
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior , CLIP
# get trained CLIP from step one
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
). cuda ()
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2 ,
condition_on_text_encodings = False # this probably should be true, but just to get Laion started
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# precompute the text and image embeddings
# here using the diffusion prior class, but could be done with CLIP alone
clip_image_embeds = diffusion_prior . clip . embed_image ( images ). image_embed
clip_text_embeds = diffusion_prior . clip . embed_text ( text ). text_embed
# feed text and images into diffusion prior network
loss = diffusion_prior (
text_embed = clip_text_embeds ,
image_embed = clip_image_embeds
)
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddings Sie können auch komplett auf CLIP verzichten. In diesem Fall müssen Sie image_embed_dim bei der Initialisierung an DiffusionPrior übergeben
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
image_embed_dim = 512 , # this needs to be set
timesteps = 100 ,
cond_drop_prob = 0.2 ,
condition_on_text_encodings = False # this probably should be true, but just to get Laion started
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# precompute the text and image embeddings
# here using the diffusion prior class, but could be done with CLIP alone
clip_image_embeds = torch . randn ( 4 , 512 ). cuda ()
clip_text_embeds = torch . randn ( 4 , 512 ). cuda ()
# feed text and images into diffusion prior network
loss = diffusion_prior (
text_embed = clip_text_embeds ,
image_embed = clip_image_embeds
)
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddings Obwohl die Möglichkeit besteht, dass sie einen unveröffentlichten, leistungsfähigeren CLIP verwenden, können Sie einen der veröffentlichten verwenden, wenn Sie Ihren eigenen CLIP nicht von Grund auf trainieren möchten. Dies wird es der Community auch ermöglichen, die Schlussfolgerungen des Papiers schneller zu validieren.
Um einen vorab trainierten OpenAI CLIP zu verwenden, importieren Sie einfach OpenAIClipAdapter und übergeben Sie ihn wie folgt an den DiffusionPrior oder Decoder
import torch
from dalle2_pytorch import DALLE2 , DiffusionPriorNetwork , DiffusionPrior , Unet , Decoder , OpenAIClipAdapter
# openai pretrained clip - defaults to ViT-B/32
clip = OpenAIClipAdapter ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# prior networks (with transformer)
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2
). cuda ()
loss = diffusion_prior ( text , images )
loss . backward ()
# do above for many steps ...
# decoder (with unet)
unet1 = Unet (
dim = 128 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
text_embed_dim = 512 ,
cond_on_text_encodings = True # set to True for any unets that need to be conditioned on text encodings (ex. first unet in cascade)
). cuda ()
unet2 = Unet (
dim = 16 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
decoder = Decoder (
unet = ( unet1 , unet2 ),
image_sizes = ( 128 , 256 ),
clip = clip ,
timesteps = 1000 ,
sample_timesteps = ( 250 , 27 ),
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
for unet_number in ( 1 , 2 ):
loss = decoder ( images , text = text , unet_number = unet_number ) # this can optionally be decoder(images, text) if you wish to condition on the text encodings as well, though it was hinted in the paper it didn't do much
loss . backward ()
# do above for many steps
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
images = dalle2 (
[ 'a butterfly trying to escape a tornado' ],
cond_scale = 2. # classifier free guidance strength (> 1 would strengthen the condition)
)
# save your image (in this example, of size 256x256)Alternativ können Sie auch Open Clip verwenden
$ pip install open-clip-torchEx. unter Verwendung des von Romain trainierten SOTA Open Clip-Modells


