

Neuer Roboter in der Stadt: SO-100

Wir haben gerade ein neues Tutorial zum Bau eines günstigeren Roboters zum Preis von 110 US-Dollar pro Arm hinzugefügt!
Bringen Sie ihm neue Fähigkeiten bei, indem Sie ihm ein paar Bewegungen mit nur einem Laptop zeigen.
Dann sehen Sie zu, wie Ihr selbstgebauter Roboter autonom agiert?
Folgen Sie dem Link zum vollständigen Tutorial für SO-100.
LeRobot: Hochmoderne KI für die Robotik in der realen Welt
? Ziel von LeRobot ist es, Modelle, Datensätze und Werkzeuge für die reale Robotik in PyTorch bereitzustellen. Ziel ist es, die Hürde für den Einstieg in die Robotik zu senken, sodass jeder einen Beitrag leisten und vom Austausch von Datensätzen und vorab trainierten Modellen profitieren kann.
? LeRobot enthält hochmoderne Ansätze, die sich nachweislich auf die reale Welt übertragen lassen, wobei der Schwerpunkt auf Nachahmungslernen und Verstärkungslernen liegt.
? LeRobot bietet bereits eine Reihe vorab trainierter Modelle, Datensätze mit von Menschen gesammelten Demonstrationen und Simulationsumgebungen für den Einstieg, ohne einen Roboter zusammenbauen zu müssen. In den kommenden Wochen ist geplant, die kostengünstigsten und leistungsfähigsten Roboter auf dem Markt immer stärker für die reale Robotik zu unterstützen.
? LeRobot hostet vorab trainierte Modelle und Datensätze auf dieser Hugging Face-Community-Seite: Huggingface.co/lerobot
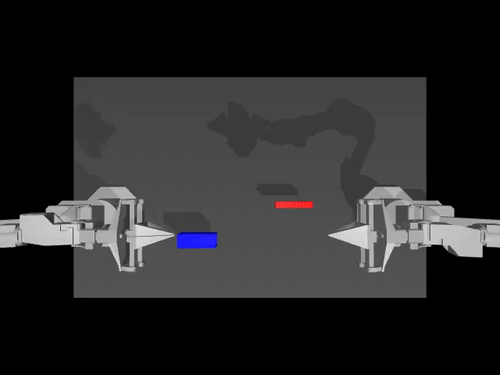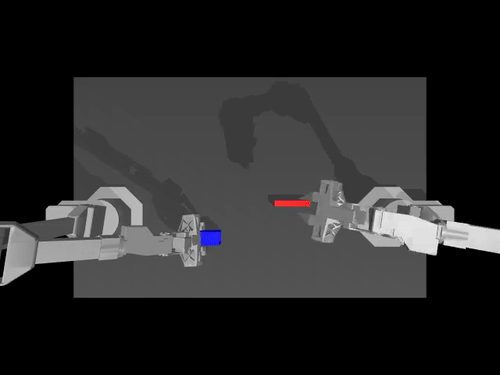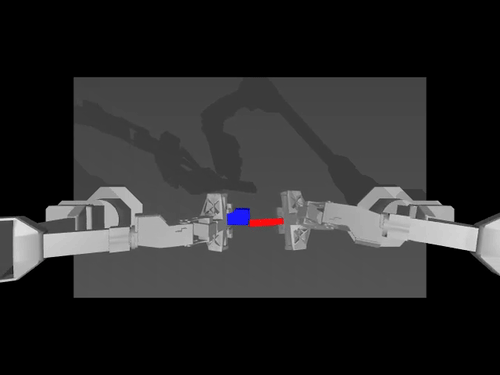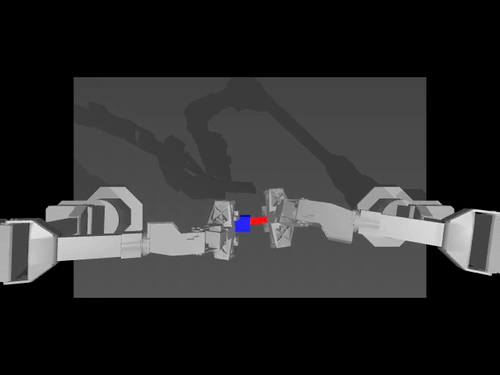 |  |  |
| ACT-Richtlinie zu ALOHA env | TDMPC-Richtlinie für die SimXArm-Umgebung | Verbreitungspolitik für PushT env |
Laden Sie unseren Quellcode herunter:
git clone https://github.com/huggingface/lerobot.git
cd lerobot Erstellen Sie eine virtuelle Umgebung mit Python 3.10 und aktivieren Sie diese, z. B. mit miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobotInstallieren? LeRobot:
pip install -e .HINWEIS: Abhängig von Ihrer Plattform müssen Sie möglicherweise
cmakeundbuild-essentialinstallieren, um einige unserer Abhängigkeiten zu erstellen, wenn bei diesem Schritt Build-Fehler auftreten. Unter Linux:sudo apt-get install cmake build-essential
Für Simulationen ? LeRobot verfügt über Turnhallenumgebungen, die als Extras installiert werden können:
Um beispielsweise ? LeRobot mit Aloha und Pusht, verwenden Sie:
pip install -e " .[aloha, pusht] "Um Gewichtungen und Verzerrungen für die Experimentverfolgung zu verwenden, melden Sie sich mit an
wandb login(Hinweis: Sie müssen auch WandB in der Konfiguration aktivieren. Siehe unten.)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
Sehen Sie sich Beispiel 1 an, das die Verwendung unserer Datensatzklasse veranschaulicht, die automatisch Daten vom Hugging Face-Hub herunterlädt.
Sie können Episoden auch lokal aus einem Datensatz auf dem Hub visualisieren, indem Sie unser Skript über die Befehlszeile ausführen:
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 oder aus einem Datensatz in einem lokalen Ordner mit der Stammumgebungsvariablen DATA_DIR (im folgenden Fall wird der Datensatz in ./my_local_data_dir/lerobot/pusht gesucht)
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 Es öffnet rerun.io und zeigt die Kamerastreams, Roboterzustände und Aktionen an, etwa so:
Unser Skript kann auch Datensätze visualisieren, die auf einem entfernten Server gespeichert sind. Weitere Anweisungen finden Sie unter python lerobot/scripts/visualize_dataset.py --help .
LeRobotDataset -Format Ein Datensatz im LeRobotDataset -Format ist sehr einfach zu verwenden. Es kann aus einem Repository auf dem Hugging Face-Hub oder einem lokalen Ordner einfach mit z. B. dataset = LeRobotDataset("lerobot/aloha_static_coffee") geladen werden und kann wie jeder Hugging Face- und PyTorch-Datensatz indiziert werden. Zum Beispiel ruft dataset[0] einen einzelnen zeitlichen Rahmen aus dem Datensatz ab, der Beobachtung(en) und eine Aktion als PyTorch-Tensoren enthält, die bereit sind, einem Modell zugeführt zu werden.
Eine Besonderheit von LeRobotDataset besteht darin, dass wir, anstatt einen einzelnen Frame anhand seines Index abzurufen, mehrere Frames basierend auf ihrer zeitlichen Beziehung zum indizierten Frame abrufen können, indem wir delta_timestamps auf eine Liste relativer Zeiten in Bezug auf den indizierten Frame festlegen. Beispielsweise kann man mit delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} für einen gegebenen Index 4 Frames abrufen: 3 „vorherige“ Frames 1 Sekunde, 0,5 Sekunden und 0,2 Sekunden vor dem indizierten Frame und dem indizierten Frame selbst (entsprechend dem 0-Eintrag). Weitere Details zu delta_timestamps finden Sie im Beispiel 1_load_lerobot_dataset.py.
Unter der Haube nutzt das LeRobotDataset -Format mehrere Möglichkeiten zur Serialisierung von Daten, deren Verständnis hilfreich sein kann, wenn Sie vorhaben, intensiver mit diesem Format zu arbeiten. Wir haben versucht, ein flexibles und dennoch einfaches Datensatzformat zu erstellen, das die meisten Arten von Merkmalen und Besonderheiten abdeckt, die beim verstärkenden Lernen und in der Robotik, in der Simulation und in der realen Welt vorhanden sind, mit einem Schwerpunkt auf Kameras und Roboterzuständen, aber leicht auf andere Arten von Sinneseindrücken erweiterbar Eingaben, solange sie durch einen Tensor dargestellt werden können.
Hier sind die wichtigen Details und die interne Strukturorganisation eines typischen LeRobotDataset das mit dataset = LeRobotDataset("lerobot/aloha_static_coffee") instanziiert wird. Die genauen Merkmale ändern sich von Datensatz zu Datensatz, nicht jedoch die Hauptaspekte:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
Ein LeRobotDataset wird mit mehreren weit verbreiteten Dateiformaten für jeden seiner Teile serialisiert, nämlich:
safetensor Tensor-Serialisierungsformat gespeichertsafetensor Tensor-Serialisierungsformat gespeichert wurden Der Datensatz kann nahtlos vom HuggingFace-Hub hochgeladen/heruntergeladen werden. Um an einem lokalen Datensatz zu arbeiten, können Sie die Umgebungsvariable DATA_DIR auf Ihren Stammdatensatzordner festlegen, wie im obigen Abschnitt zur Datensatzvisualisierung dargestellt.
Schauen Sie sich Beispiel 2 an, das zeigt, wie Sie eine vorab trainierte Richtlinie vom Hugging Face-Hub herunterladen und eine Bewertung in der entsprechenden Umgebung durchführen.
Wir stellen außerdem ein leistungsfähigeres Skript zur Verfügung, um die Auswertung über mehrere Umgebungen hinweg während desselben Rollouts zu parallelisieren. Hier ist ein Beispiel mit einem vorab trainierten Modell, das auf lerobot/diffusion_pusht gehostet wird:
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10Hinweis: Nachdem Sie Ihre eigene Richtlinie trainiert haben, können Sie die Prüfpunkte neu bewerten mit:
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model Weitere Anweisungen finden Sie unter python lerobot/scripts/eval.py --help .
Schauen Sie sich Beispiel 3 an, das zeigt, wie Sie ein Modell mithilfe unserer Kernbibliothek in Python trainieren, und Beispiel 4, das zeigt, wie Sie unser Trainingsskript über die Befehlszeile verwenden.
Im Allgemeinen können Sie unser Schulungsskript verwenden, um jede Richtlinie einfach zu trainieren. Hier ist ein Beispiel für das Training der ACT-Richtlinie für von Menschen gesammelte Flugbahnen in der Aloha-Simulationsumgebung für die Einfügungsaufgabe:
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human Das Experimentverzeichnis wird automatisch generiert und in Ihrem Terminal gelb angezeigt. Es sieht aus wie outputs/train/2024-05-05/20-21-12_aloha_act_default . Sie können ein Experimentverzeichnis manuell angeben, indem Sie dieses Argument zum Python-Befehl train.py hinzufügen:
hydra.run.dir=your/new/experiment/dir Im Experimentverzeichnis gibt es einen Ordner namens checkpoints , der die folgende Struktur hat:
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step Um das Training von einem Kontrollpunkt aus fortzusetzen, können Sie diese zum Python-Befehl train.py hinzufügen:
hydra.run.dir=your/original/experiment/dir resume=trueEs lädt die vorab trainierten Modell-, Optimierer- und Scheduler-Zustände für das Training. Weitere Informationen finden Sie hier in unserem Tutorial zur Trainingswiederaufnahme.
Um wandb zum Protokollieren von Trainings- und Bewertungskurven zu verwenden, stellen Sie sicher, dass Sie wandb login als einmaligen Einrichtungsschritt ausgeführt haben. Wenn Sie dann den obigen Trainingsbefehl ausführen, aktivieren Sie WandB in der Konfiguration, indem Sie Folgendes hinzufügen:
wandb.enable=trueEin Link zu den Wandb-Protokollen für den Lauf wird ebenfalls in Gelb in Ihrem Terminal angezeigt. Hier ist ein Beispiel dafür, wie sie in Ihrem Browser aussehen. Bitte lesen Sie hier auch die Erklärung einiger häufig verwendeter Metriken in Protokollen.

Hinweis: Aus Effizienzgründen wird während des Trainings jeder Kontrollpunkt anhand einer geringen Anzahl von Episoden bewertet. Sie können eval.n_episodes=500 verwenden, um mehr Episoden als standardmäßig auszuwerten. Oder Sie möchten nach dem Training Ihre besten Kontrollpunkte in weiteren Episoden neu bewerten oder die Bewertungseinstellungen ändern. Weitere Anweisungen finden Sie unter python lerobot/scripts/eval.py --help .
Wir haben unsere Konfigurationsdateien (zu finden unter lerobot/configs ) so organisiert, dass sie SOTA-Ergebnisse einer bestimmten Modellvariante in ihren jeweiligen Originalwerken reproduzieren. Einfach ausführen:
python lerobot/scripts/train.py policy=diffusion env=pushtreproduziert SOTA-Ergebnisse für die Diffusionsrichtlinie für die PushT-Aufgabe.
Vorgefertigte Richtlinien sowie Reproduktionsdetails finden Sie im Abschnitt „Modelle“ von https://huggingface.co/lerobot.
Wenn Sie dazu beitragen möchten? LeRobot, schauen Sie sich bitte unseren Beitragsleitfaden an.
Um einen Datensatz zum Hub hinzuzufügen, müssen Sie sich mit einem Schreibzugriffstoken anmelden, der aus den Hugging Face-Einstellungen generiert werden kann:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential Zeigen Sie dann auf Ihren Rohdatensatzordner (z. B. data/aloha_static_pingpong_test_raw ) und übertragen Sie Ihren Datensatz mit:
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5 Weitere Anweisungen finden Sie unter python lerobot/scripts/push_dataset_to_hub.py --help .
Wenn Ihr Datensatzformat nicht unterstützt wird, implementieren Sie Ihr eigenes in lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py indem Sie Beispiele wie pusht_zarr, umi_zarr, aloha_hdf5 oder xarm_pkl kopieren.
Sobald Sie eine Richtlinie trainiert haben, können Sie sie mit einer Hub-ID, die wie folgt aussieht: ${hf_user}/${repo_name} (z. B. lerobot/diffusion_pusht) auf den Hugging Face-Hub hochladen.
Sie müssen zunächst den Checkpoint-Ordner in Ihrem Experimentverzeichnis finden (z. B. „ outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 ). Darin gibt es ein pretrained_model -Verzeichnis, das Folgendes enthalten sollte:
config.json : Eine serialisierte Version der Richtlinienkonfiguration (gemäß der Datenklassenkonfiguration der Richtlinie).model.safetensors : Ein Satz von torch.nn.Module Parametern, gespeichert im Hugging Face Safetensors-Format.config.yaml : Eine konsolidierte Hydra-Trainingskonfiguration, die die Richtlinien-, Umgebungs- und Datensatzkonfigurationen enthält. Die Richtlinienkonfiguration sollte genau mit config.json übereinstimmen. Die Umgebungskonfiguration ist für jeden nützlich, der Ihre Richtlinie bewerten möchte. Die Datensatzkonfiguration dient lediglich als Papierspur zur Reproduzierbarkeit.Um diese auf den Hub hochzuladen, führen Sie Folgendes aus:
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_modelEin Beispiel dafür, wie andere Personen Ihre Richtlinie nutzen können, finden Sie unter eval.py.
Ein Beispiel für einen Codeausschnitt zum Profilieren der Bewertung einer Richtlinie:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function Wenn Sie möchten, können Sie diese Arbeit zitieren mit:
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}Wenn Sie außerdem eine bestimmte Richtlinienarchitektur, vorab trainierte Modelle oder Datensätze verwenden, wird empfohlen, die Originalautoren der Arbeit wie folgt zu zitieren:
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

