EasyOCR
v1.7.2
Einsatzbereite OCR mit über 80 unterstützten Sprachen und allen gängigen Schreibskripten, darunter: Latein, Chinesisch, Arabisch, Devanagari, Kyrillisch usw.
Probieren Sie die Demo auf unserer Website aus
Integriert in Huggingface Spaces ? mit Gradio. Probieren Sie die Web-Demo aus:
24. September 2024 – Version 1.7.2
Lesen Sie alle Versionshinweise



Mit pip installieren
Für die neueste stabile Version:
pip install easyocrFür die neueste Entwicklungsversion:
pip install git+https://github.com/JaidedAI/EasyOCR.git Hinweis 1: Für Windows installieren Sie bitte zuerst Torch und Torchvision, indem Sie den offiziellen Anweisungen hier https://pytorch.org folgen. Stellen Sie sicher, dass Sie auf der Pytorch-Website die richtige CUDA-Version auswählen. Wenn Sie nur im CPU-Modus arbeiten möchten, wählen Sie CUDA = None aus.
Hinweis 2: Wir stellen hier auch eine Docker-Datei zur Verfügung.
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )Die Ausgabe erfolgt in einem Listenformat. Jedes Element stellt einen Begrenzungsrahmen, den erkannten Text bzw. die Sicherheitsstufe dar.
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)] Hinweis 1: ['ch_sim','en'] ist die Liste der Sprachen, die Sie lesen möchten. Sie können mehrere Sprachen gleichzeitig übergeben, aber nicht alle Sprachen können zusammen verwendet werden. Englisch ist mit jeder Sprache kompatibel und Sprachen mit gemeinsamen Zeichen sind normalerweise miteinander kompatibel.
Hinweis 2: Anstelle des Dateipfads chinese.jpg können Sie auch ein OpenCV-Bildobjekt (Numpy-Array) oder eine Bilddatei als Bytes übergeben. Eine URL zu einem Rohbild ist ebenfalls akzeptabel.
Hinweis 3: Die Zeile „ reader = easyocr.Reader(['ch_sim','en']) dient zum Laden eines Modells in den Speicher. Es dauert einige Zeit, muss aber nur einmal ausgeführt werden.
Für eine einfachere Ausgabe können Sie auch detail=0 festlegen.
reader . readtext ( 'chinese.jpg' , detail = 0 )Ergebnis:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]Modellgewichte für die ausgewählte Sprache werden automatisch heruntergeladen oder Sie können sie manuell vom Modell-Hub herunterladen und im Ordner „~/.EasyOCR/model“ ablegen
Falls Sie keine GPU haben oder Ihre GPU über wenig Arbeitsspeicher verfügt, können Sie das Modell im Nur-CPU-Modus ausführen, indem Sie gpu=False hinzufügen.
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )Weitere Informationen finden Sie im Tutorial und in der API-Dokumentation.
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=TrueInformationen zum Erkennungsmodell finden Sie hier.
Informationen zum Erkennungsmodell (CRAFT) finden Sie hier.
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )Die Idee besteht darin, jedes hochmoderne Modell in EasyOCR einbinden zu können. Es gibt viele Genies, die versuchen, bessere Erkennungsmodelle zu entwickeln, aber wir versuchen hier nicht, Genies zu sein. Wir wollen ihre Werke einfach schnell der Öffentlichkeit zugänglich machen ... kostenlos. (Nun, wir glauben, dass die meisten Genies wollen, dass ihre Arbeit so schnell/groß wie möglich eine positive Wirkung hat.) Die Pipeline sollte in etwa wie das folgende Diagramm aussehen. Graue Steckplätze sind Platzhalter für austauschbare hellblaue Module.
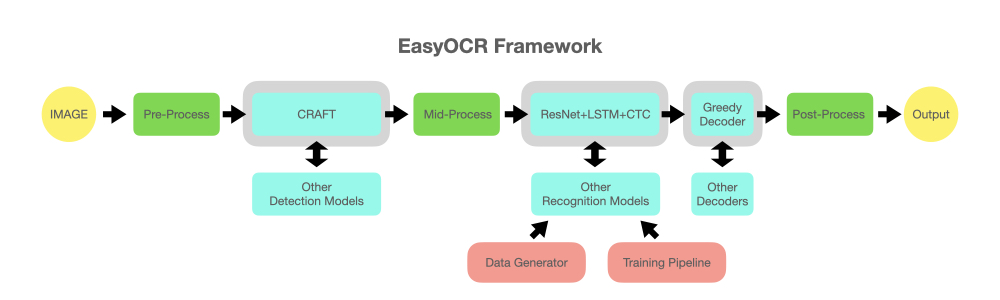
Dieses Projekt basiert auf Recherchen und Code aus mehreren Artikeln und Open-Source-Repositories.
Die gesamte Deep-Learning-Ausführung basiert auf Pytorch. ❤️
Die Erkennungsausführung verwendet den CRAFT-Algorithmus aus diesem offiziellen Repository und deren Artikel (Danke @YoungminBaek von @clovaai). Wir verwenden auch ihr vorab trainiertes Modell. Das Trainingsskript wird von @gmuffiness bereitgestellt.
Das Erkennungsmodell ist ein CRNN (Papier). Es besteht aus drei Hauptkomponenten: Merkmalsextraktion (wir verwenden derzeit Resnet) und VGG, Sequenzkennzeichnung (LSTM) und Dekodierung (CTC). Die Trainingspipeline für die Erkennungsausführung ist eine modifizierte Version des Deep-Text-Recognition-Benchmark-Frameworks. (Danke @ku21fan von @clovaai) Dieses Repository ist ein Juwel, das mehr Anerkennung verdient.
Der Beam-Suchcode basiert auf diesem Repository und seinem Blog. (Danke @githubharald)
Die Datensynthese basiert auf TextRecognitionDataGenerator. (Danke @Belval)
Und eine gute Lektüre über CTC von destill.pub finden Sie hier.
Lassen Sie uns gemeinsam die Menschheit voranbringen, indem wir KI für alle verfügbar machen!
3 Möglichkeiten, einen Beitrag zu leisten:
Coder: Bitte senden Sie eine PR für kleine Fehler/Verbesserungen. Besprechen Sie größere Probleme mit uns, indem Sie zunächst ein Problem eröffnen. Es gibt eine Liste möglicher Fehler/Verbesserungsprobleme mit dem Tag „PR WILLKOMMEN“.
Benutzer: Sagen Sie uns, welchen Nutzen EasyOCR für Sie/Ihre Organisation hat, um die Weiterentwicklung zu fördern. Veröffentlichen Sie auch Fehlerfälle im Abschnitt „Probleme“, um zur Verbesserung zukünftiger Modelle beizutragen.
Technologieführer/Guru: Wenn Sie diese Bibliothek nützlich fanden, verbreiten Sie sie bitte weiter! (Siehe Yann Lecuns Beitrag über EasyOCR)
Um eine neue Sprache anzufordern, müssen Sie eine PR mit den beiden folgenden Dateien senden:
Wenn Ihre Sprache einzigartige Elemente enthält (z. B. 1. Arabisch: Zeichen ändern ihre Form, wenn sie aneinandergefügt werden + Schreiben von rechts nach links 2. Thailändisch: Einige Zeichen müssen über der Linie stehen und andere darunter), informieren Sie uns bitte optimal über Ihre Fähigkeiten und/oder geben Sie nützliche Links. Es ist wichtig, auf die Details zu achten, um ein System zu schaffen, das wirklich funktioniert.
Bitte haben Sie schließlich Verständnis dafür, dass unsere Priorität auf populären Sprachen oder Sprachgruppen liegen muss, die große Teile ihrer Zeichen miteinander teilen (teilen Sie uns auch mit, ob dies auf Ihre Sprache zutrifft). Wir benötigen mindestens eine Woche, um ein neues Modell zu entwickeln, sodass Sie möglicherweise eine Weile warten müssen, bis das neue Modell veröffentlicht wird.
Siehe Liste der Sprachen in der Entwicklung
Aufgrund begrenzter Ressourcen wird ein Problem, das älter als 6 Monate ist, automatisch geschlossen. Bitte öffnen Sie ein Problem erneut, wenn es kritisch ist.
Für den Enterprise-Support bietet Jaided AI einen umfassenden Service für benutzerdefinierte OCR-/KI-Systeme von der Implementierung über die Schulung/Feinabstimmung bis hin zur Bereitstellung. Klicken Sie hier, um mit uns Kontakt aufzunehmen.


