LVBench
1.0.0
[Projektseite] [ arXiv Paper] [ Datensatz][? Bestenliste][? Huggingface-Rangliste]
LVBench ist ein Benchmark zur Bewertung und Verbesserung der Fähigkeiten multimodaler Modelle beim Verstehen und Extrahieren von Informationen aus langen Videos mit einer Dauer von bis zu zwei Stunden.
2024.08.2 Wir haben die LVBench-Bestenliste auf Huggingface Spaces eingerichtet! Werfen Sie einen Blick auf die Bestenliste.
2024.06.11 Wir haben LVBench veröffentlicht, einen neuen Maßstab für das Verständnis langer Videos!
LVBench ist ein Benchmark zur Bewertung der Fähigkeiten von Modellen beim Verständnis langer Videos. Wir haben umfangreiche lange Videodaten aus öffentlichen Quellen gesammelt und durch eine Mischung aus manuellem Aufwand und Modellunterstützung kommentiert. Unser Benchmark bietet eine solide Grundlage für das Testen von Modellen in erweiterten zeitlichen Kontexten und gewährleistet eine qualitativ hochwertige Bewertung durch sorgfältige menschliche Annotation und mehrstufige Qualitätskontrolle.
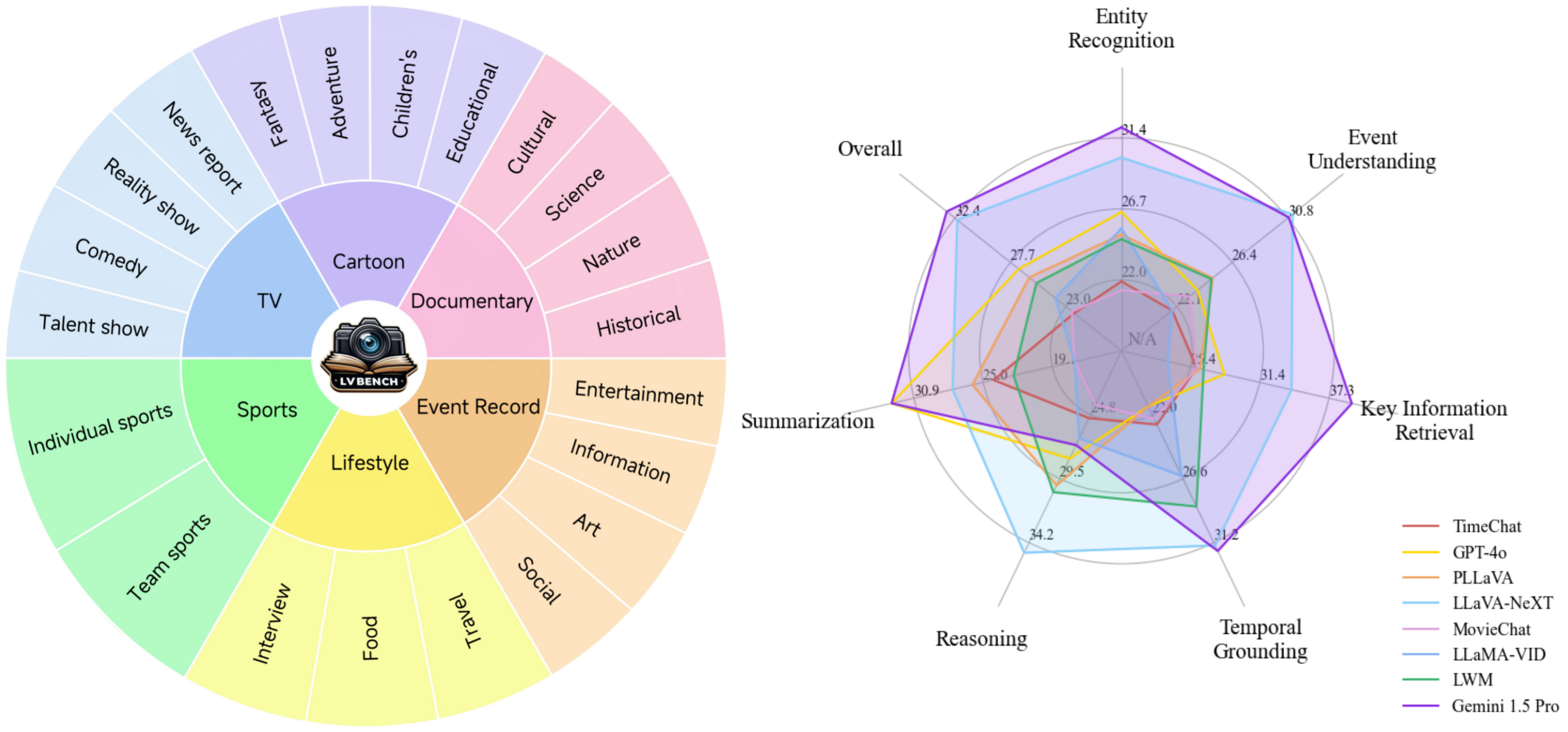
Kernfunktionen : Sechs Kernfunktionen für langes Videoverständnis, die die Erstellung komplexer und herausfordernder Fragen für eine umfassende Modellbewertung ermöglichen.
Verschiedene Daten : Eine vielfältige Auswahl an langen Videodaten, die im Durchschnitt fünfmal länger sind als die längsten vorhandenen Datensätze und verschiedene Kategorien abdecken.
Hochwertige Anmerkungen : Zuverlässiger Benchmark mit sorgfältiger menschlicher Anmerkung und mehrstufigen Qualitätskontrollprozessen.

Unser Datensatz steht unter der CC-BY-NC-SA-4.0-Lizenz.
LVBench wird nur für akademische Forschung verwendet. Eine kommerzielle Nutzung in jeglicher Form ist untersagt. Wir besitzen nicht das Urheberrecht an Rohvideodateien.
Wenn es einen Verstoß in LVBench gibt, wenden Sie sich bitte an [email protected] oder äußern Sie direkt ein Problem. Wir werden es dann umgehend entfernen.
Installieren Sie zuerst video2dataset:
pip video2dataset installieren Pip Transformer-Engine deinstallieren
Dann sollten Sie video_info.meta.jsonl von Huggingface herunterladen und im data ablegen.
Jeder Eintrag in der Datei video_info.meta.jsonl verfügt über ein Schlüsselfeld, das der ID eines YouTube-Videos entspricht. Mit dieser ID können Nutzer das entsprechende Video herunterladen. Alternativ können Benutzer das von uns bereitgestellte Download-Skript download.sh zum Herunterladen verwenden:
CD-Skripte bash download.sh
Nach der Ausführung werden die Videodateien im Verzeichnis script/videos gespeichert.
pip install -e .
(Hinweis: Wenn Sie die Auswertung schnell ausprobieren möchten, können Sie mit scripts/construct_random_answers.py eine zufällige Antwortdatei vorbereiten.)
CD-Skripte Python test_acc.py
Nach der Ausführung erhalten Sie eine Evaluierungsergebnisdatei result.json im scripts . Sie können die Ergebnisse an die Bestenliste senden.
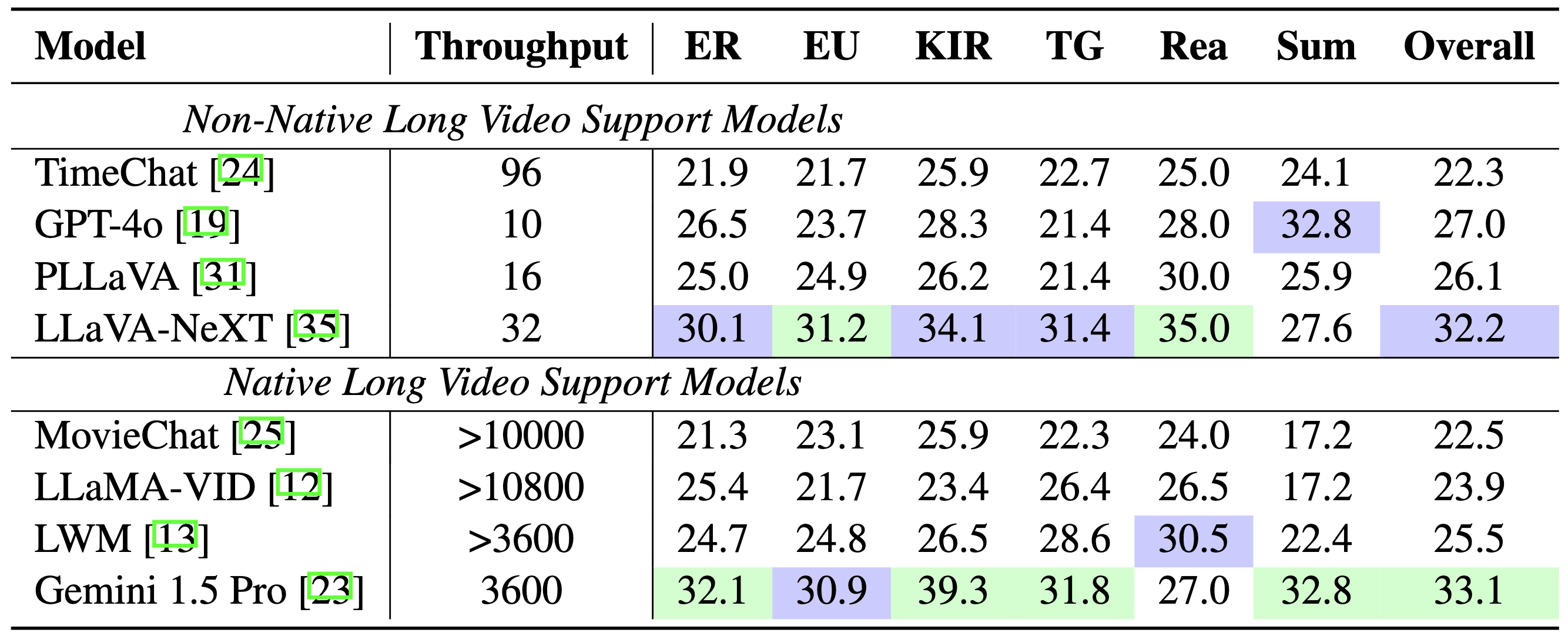
Modellvergleich:
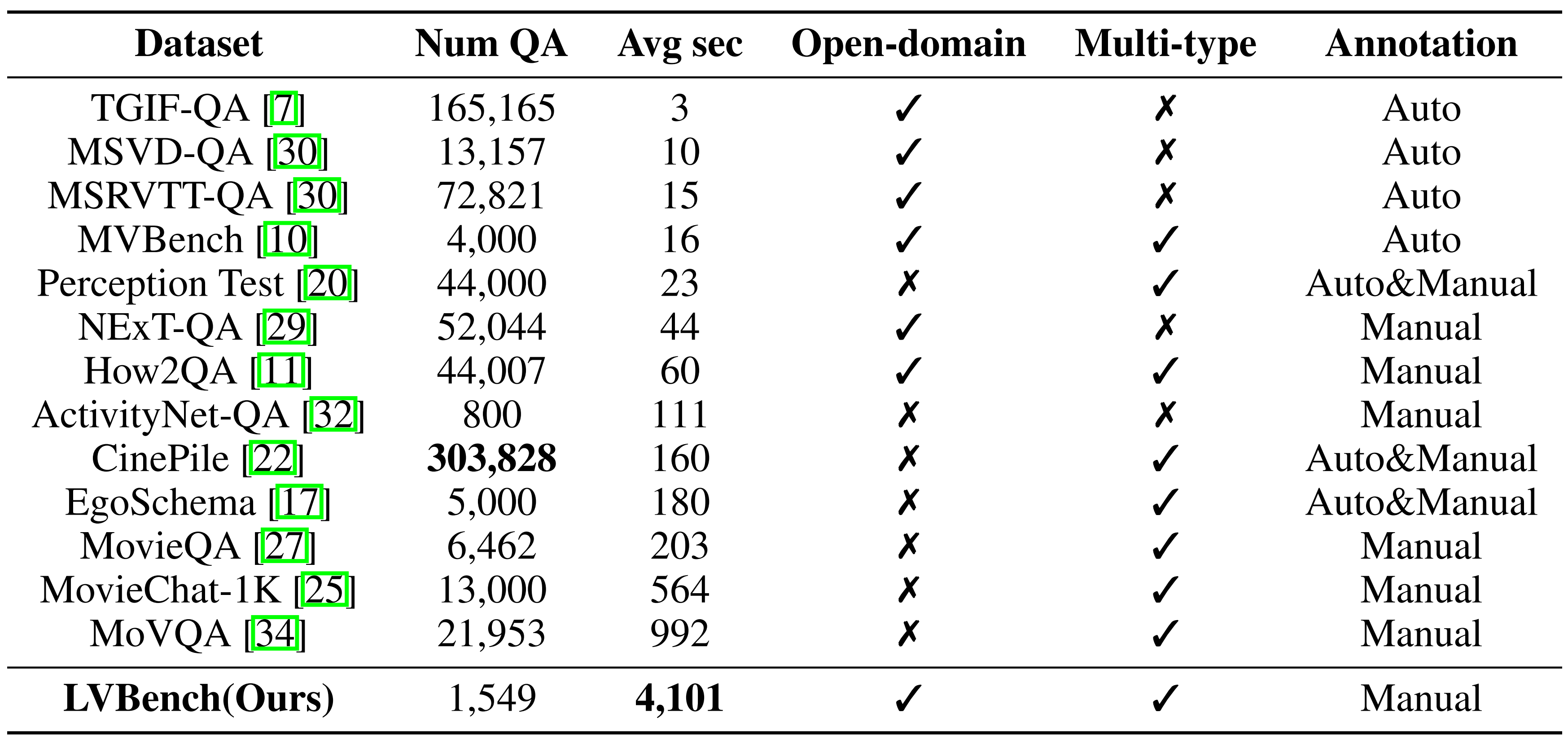
Benchmark-Vergleich:
Modell vs. Mensch:

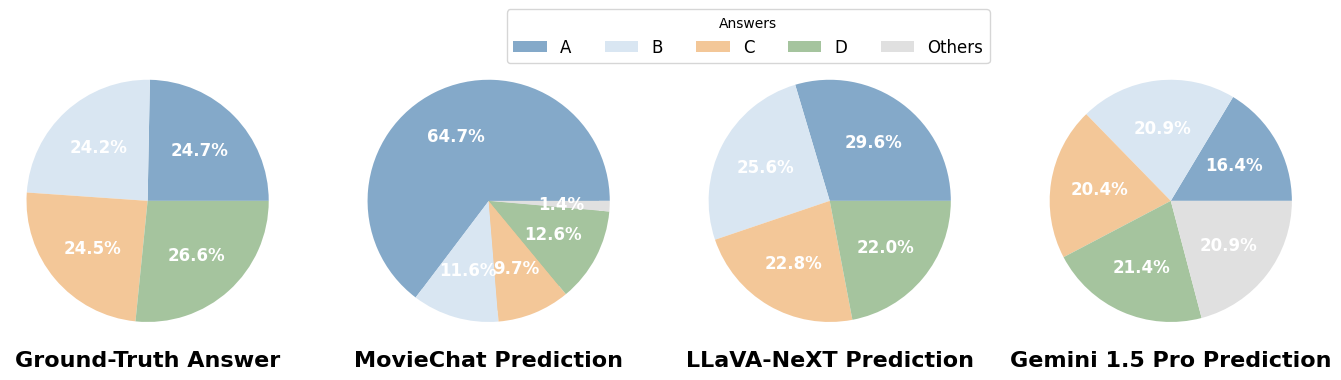
Antwortverteilung:
Wenn Sie unsere Arbeit für Ihre Forschung hilfreich finden, denken Sie bitte darüber nach, unsere Arbeit zu zitieren.
@misc{wang2024lvbench, title={LVBench: An Extreme Long Video Understanding Benchmark},
Autor={Weihan Wang und Zehai He und Wenyi Hong und Yean Cheng und Xiaohan Zhang und Ji Qi und Shiyu Huang und Bin Xu und Yuxiao Dong und Ming Ding und Jie Tang}, Jahr={2024}, eprint={2406.08035}, archivePrefix ={arXiv}, PrimaryClass={cs.CV}} 

