Ein Tool zur Thesaurus-Erweiterung mithilfe von Label-Propagation-Methoden. Aus einem Textkorpus und einem vorhandenen Thesaurus werden Vorschläge zur Erweiterung der vorhandenen Synonymsätze generiert. Dieses Tool wurde im Rahmen der Masterarbeit „ Label Propagation for Tax Law Thesaurus Extension “ am Lehrstuhl „Software Engineering für Wirtschaftsinformatik (sebis)“ der Technischen Universität München (TUM) entwickelt.
Zusammenfassung der Abschlussarbeit. Mit der zunehmenden Digitalisierung muss das Informationsabrufsystem mit zunehmenden Mengen digitalisierter Inhalte umgehen. Anbieter juristischer Inhalte investieren viel Geld in den Aufbau domänenspezifischer Ontologien wie Thesauri, um eine deutlich erhöhte Anzahl relevanter Dokumente abzurufen. Seit 2002 wurden viele Methoden zur Etikettenweitergabe entwickelt, um beispielsweise Gruppen ähnlicher Knoten in Diagrammen zu identifizieren. Die Etikettenweitergabe ist eine Familie graphbasierter, halbüberwachter Algorithmen für maschinelles Lernen. In dieser Arbeit werden wir die Eignung von Label-Propagation-Methoden zur Erweiterung eines Thesaurus aus dem Steuerrechtsbereich testen. Der Graph, auf dem die Etikettenweitergabe angewendet wird, ist ein Ähnlichkeitsgraph, der aus Worteinbettungen erstellt wird. Wir decken den Prozess von Anfang bis Ende ab und führen mehrere Parameterstudien durch, um die Auswirkungen bestimmter Hyperparameter auf die Gesamtleistung zu verstehen. Die Ergebnisse werden dann in manuellen Studien ausgewertet und mit einem Basisansatz verglichen.
Das Tool wurde mithilfe der folgenden Pipes- und Filterarchitektur implementiert:
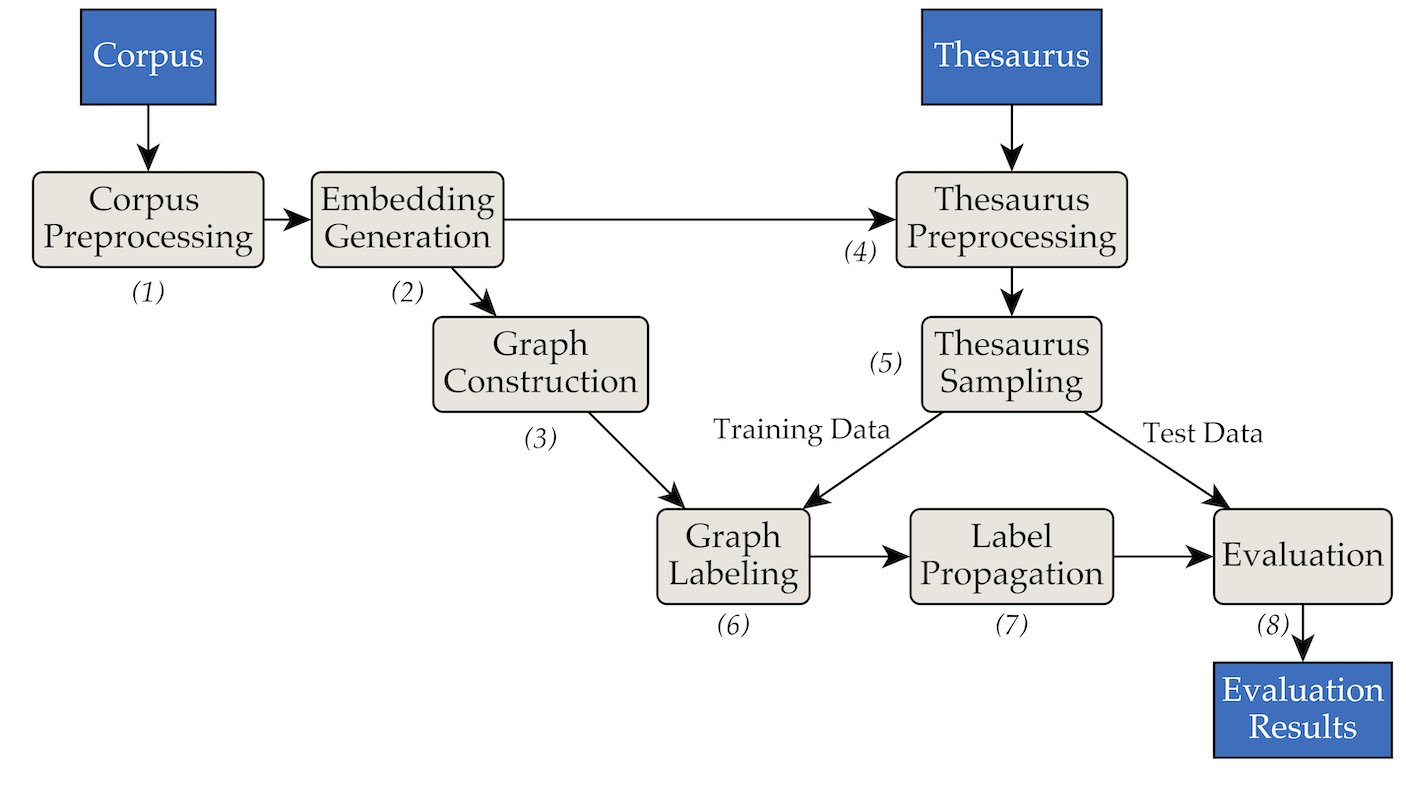
pipenv (Installationsanleitung).pipenv install . data/RW40jsons und den Thesaurus in data/german_relat_pretty-20180605.json . Informationen zu den erwarteten Dateiformaten finden Sie unter Phase1.py und Phase4.py.output/<PHASE_FOLDER>/<DATE> gespeichert. Am wichtigsten sind 08_propagation_evaluation und XX_runs . In 08_propagation_evaluation werden die Auswertungsstatistiken als stats.json zusammen mit einer Tabelle gespeichert, die Vorhersagen, Trainings- und Testsätze enthält ( main.txt , in den anderen Skripten am häufigsten als df_evaluation bezeichnet). In XX_runs wird das Protokoll eines Laufs gespeichert. Wenn mehrere Läufe über multi_runs.py ausgelöst wurden (jeder mit einem anderen Trainings-/Testsatz), werden die kombinierten Statistiken aller einzelnen Läufe ebenfalls als all_stats.json gespeichert. Über purew2v_parameter_studies.py kann die Synset-Vektor-Baseline ausgeführt werden, die wir in unserer Arbeit eingeführt haben. Es erfordert eine Reihe von Worteinbettungen und eine oder mehrere Thesaurus-Trainings-/Testaufteilungen. Ein Beispiel finden Sie unter „sample_commands.md“.
In ipynbs haben wir einige beispielhafte Jupyter-Notebooks bereitgestellt, mit denen (a) Statistiken, (b) Diagramme und (c) die Excel-Dateien für die manuellen Auswertungen erstellt wurden. Sie können sie erkunden, indem Sie pipenv shell ausführen und dann Jupyter mit jupyter notebook starten.
main.py oder multi_run.py angegeben werden.

