Großer Sprachmodellkurs
? Folge mir auf X • ? Umarmendes Gesicht • Blog • ? Praktisches GNN
Das LLM-Studium gliedert sich in drei Teile:
- ? LLM Fundamentals umfasst grundlegende Kenntnisse über Mathematik, Python und neuronale Netze.
- ?? Der LLM-Wissenschaftler konzentriert sich auf den Aufbau der bestmöglichen LLMs unter Verwendung der neuesten Techniken.
- ? Der Schwerpunkt des LLM-Ingenieurs liegt auf der Erstellung und Bereitstellung LLM-basierter Anwendungen.
Für eine interaktive Version dieses Kurses habe ich zwei LLM-Assistenten erstellt, die Fragen beantworten und Ihr Wissen auf personalisierte Weise testen:
- ? HuggingChat Assistant : Kostenlose Version mit Mixtral-8x7B.
- ? ChatGPT-Assistent : Erfordert ein Premium-Konto.
Notizbücher
Eine Liste von Notizbüchern und Artikeln zu großen Sprachmodellen.
Werkzeuge
| Notizbuch | Beschreibung | Notizbuch |
|---|
| ? LLM AutoEval | Bewerten Sie Ihre LLMs automatisch mit RunPod | |
| ? LazyMergekit | Führen Sie Modelle mit MergeKit ganz einfach mit einem Klick zusammen. | |
| ? LazyAxolotl | Optimieren Sie Modelle in der Cloud mit Axolotl mit einem Klick. | |
| ⚡ AutoQuant | Quantisieren Sie LLMs in den Formaten GGUF, GPTQ, EXL2, AWQ und HQQ mit einem Klick. | |
| ? Modell-Stammbaum | Visualisieren Sie den Stammbaum der zusammengeführten Modelle. | |
| ZeroSpace | Erstellen Sie automatisch eine Gradio-Chat-Schnittstelle mit einer kostenlosen ZeroGPU. | |
Feinabstimmung
| Notizbuch | Beschreibung | Artikel | Notizbuch |
|---|
| Optimieren Sie Llama 2 mit QLoRA | Schritt-für-Schritt-Anleitung zur überwachten Feinabstimmung von Llama 2 in Google Colab. | Artikel | |
| Optimieren Sie CodeLlama mit Axolotl | End-to-End-Anleitung zum hochmodernen Tool zur Feinabstimmung. | Artikel | |
| Feinabstimmung von Mistral-7b mit QLoRA | Überwachte die Feinabstimmung von Mistral-7b in einem kostenlosen Google Colab mit TRL. | | |
| Feinabstimmung des Mistral-7b mit DPO | Steigern Sie die Leistung überwachter, fein abgestimmter Modelle mit DPO. | Artikel | |
| Optimieren Sie Llama 3 mit ORPO | Günstigere und schnellere Feinabstimmung in einem Schritt mit ORPO. | Artikel | |
| Optimieren Sie Lama 3.1 mit Unsloth | Hocheffiziente überwachte Feinabstimmung in Google Colab. | Artikel | |
Quantisierung
| Notizbuch | Beschreibung | Artikel | Notizbuch |
|---|
| Einführung in die Quantisierung | Optimierung großer Sprachmodelle mithilfe der 8-Bit-Quantisierung. | Artikel | |
| 4-Bit-Quantisierung mit GPTQ | Quantisieren Sie Ihre eigenen Open-Source-LLMs, um sie auf Verbraucherhardware auszuführen. | Artikel | |
| Quantisierung mit GGUF und llama.cpp | Quantisieren Sie Llama 2-Modelle mit llama.cpp und laden Sie GGUF-Versionen auf den HF Hub hoch. | Artikel | |
| ExLlamaV2: Die schnellste Bibliothek zum Ausführen von LLMs | Quantisieren Sie EXL2-Modelle, führen Sie sie aus und laden Sie sie auf den HF Hub hoch. | Artikel | |
Andere
| Notizbuch | Beschreibung | Artikel | Notizbuch |
|---|
| Dekodierungsstrategien in großen Sprachmodellen | Eine Anleitung zur Textgenerierung von der Strahlsuche bis zur Kernprobenahme | Artikel | |
| Verbessern Sie ChatGPT mit Knowledge Graphs | Erweitern Sie die Antworten von ChatGPT mit Wissensdiagrammen. | Artikel | |
| LLMs mit MergeKit zusammenführen | Erstellen Sie ganz einfach Ihre eigenen Modelle, keine GPU erforderlich! | Artikel | |
| Erstellen Sie MoEs mit MergeKit | Kombinieren Sie mehrere Experten in einem einzigen frankenMoE | Artikel | |
| Entzensieren Sie jedes LLM mit Abliteration | Feinabstimmung ohne Umschulung | Artikel | |
? LLM-Grundlagen
In diesem Abschnitt werden grundlegende Kenntnisse über Mathematik, Python und neuronale Netze vermittelt. Möglicherweise möchten Sie hier nicht beginnen, sondern bei Bedarf darauf zurückgreifen.
Abschnitt umschalten
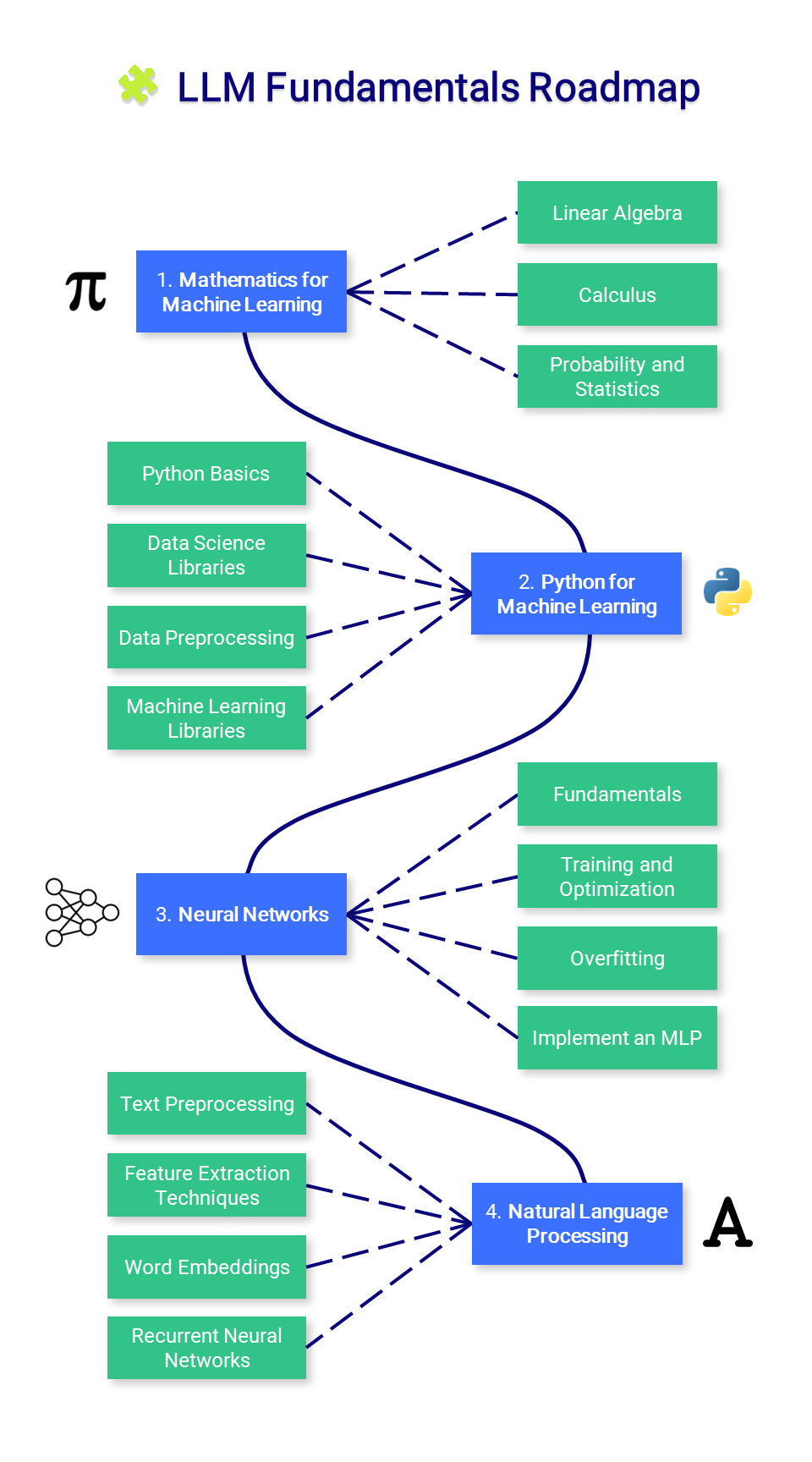
1. Mathematik für maschinelles Lernen
Bevor Sie maschinelles Lernen beherrschen, ist es wichtig, die grundlegenden mathematischen Konzepte zu verstehen, die diesen Algorithmen zugrunde liegen.
- Lineare Algebra : Dies ist entscheidend für das Verständnis vieler Algorithmen, insbesondere derjenigen, die beim Deep Learning verwendet werden. Zu den Schlüsselkonzepten gehören Vektoren, Matrizen, Determinanten, Eigenwerte und Eigenvektoren, Vektorräume und lineare Transformationen.
- Analysis : Viele Algorithmen für maschinelles Lernen beinhalten die Optimierung kontinuierlicher Funktionen, was ein Verständnis von Ableitungen, Integralen, Grenzwerten und Reihen erfordert. Wichtig sind auch die Multivariablenrechnung und das Konzept der Gradienten.
- Wahrscheinlichkeit und Statistik : Diese sind entscheidend für das Verständnis, wie Modelle aus Daten lernen und Vorhersagen treffen. Zu den Schlüsselkonzepten gehören Wahrscheinlichkeitstheorie, Zufallsvariablen, Wahrscheinlichkeitsverteilungen, Erwartungen, Varianz, Kovarianz, Korrelation, Hypothesentests, Konfidenzintervalle, Maximum-Likelihood-Schätzung und Bayes'sche Schlussfolgerung.
Ressourcen:
- 3Blue1Brown – Die Essenz der linearen Algebra: Videoserie, die diesen Konzepten eine geometrische Anschauung verleiht.
- StatQuest mit Josh Starmer – Grundlagen der Statistik: Bietet einfache und klare Erklärungen für viele statistische Konzepte.
- AP Statistics Intuition von Frau Aerin: Liste mittlerer Artikel, die die Intuition hinter jeder Wahrscheinlichkeitsverteilung vermitteln.
- Immersive lineare Algebra: Eine weitere visuelle Interpretation der linearen Algebra.
- Khan Academy – Lineare Algebra: Ideal für Anfänger, da es die Konzepte auf sehr intuitive Weise erklärt.
- Khan Academy – Analysis: Ein interaktiver Kurs, der alle Grundlagen der Analysis abdeckt.
- Khan Academy – Wahrscheinlichkeit und Statistik: Liefert das Material in einem leicht verständlichen Format.
2. Python für maschinelles Lernen
Python ist eine leistungsstarke und flexible Programmiersprache, die sich dank ihrer Lesbarkeit, Konsistenz und ihrem robusten Ökosystem aus Data-Science-Bibliotheken besonders gut für maschinelles Lernen eignet.
- Python-Grundlagen : Die Python-Programmierung erfordert ein gutes Verständnis der grundlegenden Syntax, Datentypen, Fehlerbehandlung und objektorientierten Programmierung.
- Data Science-Bibliotheken : Dazu gehört die Vertrautheit mit NumPy für numerische Operationen, Pandas für die Datenmanipulation und -analyse, Matplotlib und Seaborn für die Datenvisualisierung.
- Datenvorverarbeitung : Dies umfasst die Skalierung und Normalisierung von Merkmalen, die Behandlung fehlender Daten, die Erkennung von Ausreißern, die kategoriale Datenkodierung und die Aufteilung der Daten in Trainings-, Validierungs- und Testsätze.
- Bibliotheken für maschinelles Lernen : Kenntnisse mit Scikit-learn, einer Bibliothek, die eine große Auswahl an überwachten und unüberwachten Lernalgorithmen bietet, sind von entscheidender Bedeutung. Es ist wichtig zu verstehen, wie Algorithmen wie lineare Regression, logistische Regression, Entscheidungsbäume, zufällige Wälder, k-nächste Nachbarn (K-NN) und K-Means-Clustering implementiert werden. Techniken zur Dimensionsreduktion wie PCA und t-SNE sind ebenfalls hilfreich für die Visualisierung hochdimensionaler Daten.
Ressourcen:
- Echtes Python: Eine umfassende Ressource mit Artikeln und Tutorials für Python-Konzepte für Anfänger und Fortgeschrittene.
- freeCodeCamp – Python lernen: Langes Video, das eine vollständige Einführung in alle Kernkonzepte von Python bietet.
- Python Data Science Handbook: Kostenloses digitales Buch, das eine großartige Ressource zum Erlernen von Pandas, NumPy, Matplotlib und Seaborn darstellt.
- freeCodeCamp – Machine Learning für alle: Praktische Einführung in verschiedene Machine-Learning-Algorithmen für Einsteiger.
- Udacity – Einführung in maschinelles Lernen: Kostenloser Kurs, der PCA und mehrere andere Konzepte des maschinellen Lernens behandelt.
3. Neuronale Netze
Neuronale Netze sind ein grundlegender Bestandteil vieler Modelle des maschinellen Lernens, insbesondere im Bereich Deep Learning. Um sie effektiv nutzen zu können, ist ein umfassendes Verständnis ihres Designs und ihrer Mechanik unerlässlich.
- Grundlagen : Dazu gehört das Verständnis der Struktur eines neuronalen Netzwerks wie Schichten, Gewichte, Vorspannungen und Aktivierungsfunktionen (Sigmoid, Tanh, ReLU usw.).
- Training und Optimierung : Machen Sie sich mit Backpropagation und verschiedenen Arten von Verlustfunktionen wie Mean Squared Error (MSE) und Cross-Entropy vertraut. Verstehen Sie verschiedene Optimierungsalgorithmen wie Gradient Descent, Stochastic Gradient Descent, RMSprop und Adam.
- Überanpassung : Verstehen Sie das Konzept der Überanpassung (bei der ein Modell bei Trainingsdaten gut, bei unsichtbaren Daten jedoch schlecht abschneidet) und lernen Sie verschiedene Regularisierungstechniken (Abbruch, L1/L2-Regularisierung, frühes Stoppen, Datenerweiterung) kennen, um dies zu verhindern.
- Implementieren Sie ein Multilayer Perceptron (MLP) : Erstellen Sie mit PyTorch ein MLP, auch als vollständig verbundenes Netzwerk bekannt.
Ressourcen:
- 3Blue1Brown – Aber was ist ein neuronales Netzwerk?: Dieses Video gibt eine intuitive Erklärung neuronaler Netzwerke und ihrer inneren Funktionsweise.
- freeCodeCamp – Deep Learning Crash Course: Dieses Video führt effizient in alle wichtigen Konzepte des Deep Learning ein.
- Fast.ai – Praktisches Deep Learning: Kostenloser Kurs für Personen mit Programmiererfahrung, die etwas über Deep Learning lernen möchten.
- Patrick Loeber – PyTorch-Tutorials: Videoreihe für absolute Anfänger zum Erlernen von PyTorch.
4. Verarbeitung natürlicher Sprache (NLP)
NLP ist ein faszinierender Zweig der künstlichen Intelligenz, der die Lücke zwischen menschlicher Sprache und maschinellem Verständnis schließt. Von der einfachen Textverarbeitung bis zum Verständnis sprachlicher Nuancen spielt NLP in vielen Anwendungen wie Übersetzung, Stimmungsanalyse, Chatbots und vielem mehr eine entscheidende Rolle.
- Textvorverarbeitung : Lernen Sie verschiedene Schritte zur Textvorverarbeitung wie Tokenisierung (Aufteilen von Text in Wörter oder Sätze), Wortstammbildung (Reduzieren von Wörtern auf ihre Stammform), Lemmatisierung (ähnlich der Wortstammbildung, berücksichtigt aber den Kontext), Stoppwortentfernung usw.
- Techniken zur Merkmalsextraktion : Machen Sie sich mit Techniken zum Konvertieren von Textdaten in ein Format vertraut, das von Algorithmen für maschinelles Lernen verstanden werden kann. Zu den wichtigsten Methoden gehören Bag-of-Words (BoW), Term Frequency-Inverse Document Frequency (TF-IDF) und N-Gramm.
- Worteinbettungen : Worteinbettungen sind eine Art der Wortdarstellung, die es ermöglicht, dass Wörter mit ähnlicher Bedeutung ähnliche Darstellungen haben. Zu den wichtigsten Methoden gehören Word2Vec, GloVe und FastText.
- Rekurrente neuronale Netzwerke (RNNs) : Verstehen Sie die Funktionsweise von RNNs, einer Art neuronales Netzwerk, das für die Arbeit mit Sequenzdaten entwickelt wurde. Entdecken Sie LSTMs und GRUs, zwei RNN-Varianten, die langfristige Abhängigkeiten lernen können.
Ressourcen:
- RealPython – NLP mit spaCy in Python: Ausführlicher Leitfaden zur spaCy-Bibliothek für NLP-Aufgaben in Python.
- Kaggle – NLP-Leitfaden: Ein paar Notizbücher und Ressourcen für eine praktische Erklärung von NLP in Python.
- Jay Alammar – Die Illustration Word2Vec: Eine gute Referenz, um die berühmte Word2Vec-Architektur zu verstehen.
- Jake Tae – PyTorch RNN von Grund auf: Praktische und einfache Implementierung von RNN-, LSTM- und GRU-Modellen in PyTorch.
- Colahs Blog – LSTM-Netzwerke verstehen: Ein eher theoretischer Artikel über das LSTM-Netzwerk.
?? Der LLM-Wissenschaftler
Dieser Abschnitt des Kurses konzentriert sich darauf, zu lernen, wie man mit den neuesten Techniken die bestmöglichen LLMs erstellt.
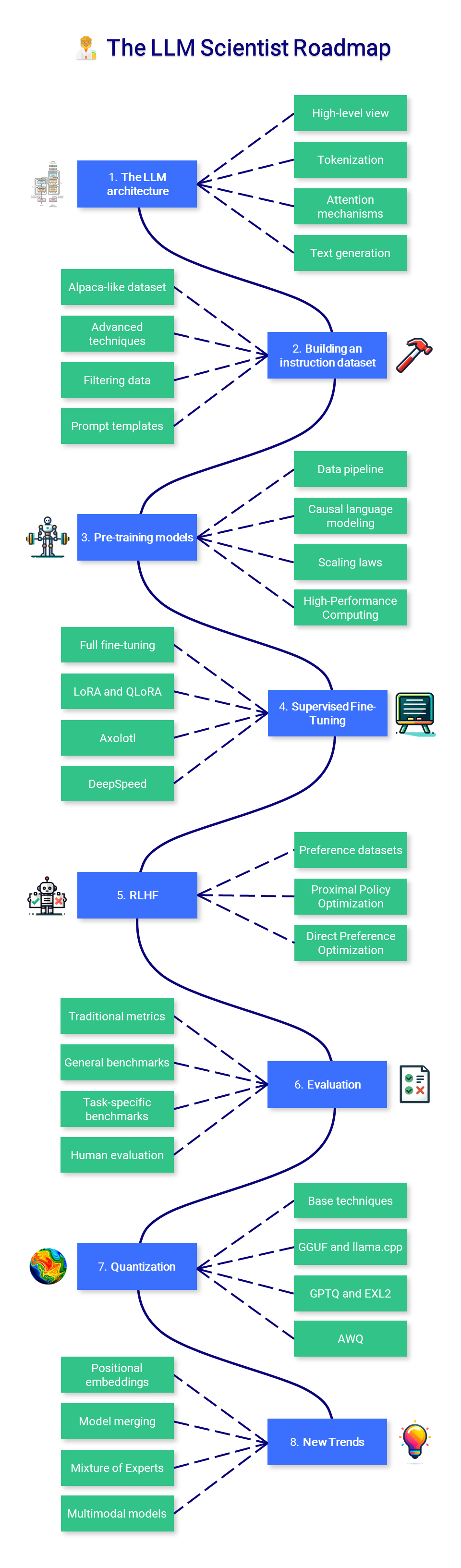
1. Die LLM-Architektur
Obwohl keine tiefgreifenden Kenntnisse über die Transformer-Architektur erforderlich sind, ist es wichtig, ein gutes Verständnis ihrer Eingaben (Tokens) und Ausgaben (Logits) zu haben. Der Vanille-Aufmerksamkeitsmechanismus ist eine weitere wichtige Komponente, die es zu beherrschen gilt, da später verbesserte Versionen davon eingeführt werden.
- Allgemeine Ansicht : Sehen Sie sich noch einmal die Encoder-Decoder-Transformer-Architektur an, und genauer gesagt die reine Decoder-GPT-Architektur, die in jedem modernen LLM verwendet wird.
- Tokenisierung : Verstehen Sie, wie Rohtextdaten in ein Format konvertiert werden, das das Modell verstehen kann. Dazu gehört die Aufteilung des Textes in Token (normalerweise Wörter oder Unterwörter).
- Aufmerksamkeitsmechanismen : Machen Sie sich mit der Theorie hinter Aufmerksamkeitsmechanismen vertraut, einschließlich Selbstaufmerksamkeit und skalierter Skalarproduktaufmerksamkeit, die es dem Modell ermöglichen, sich bei der Erzeugung einer Ausgabe auf verschiedene Teile der Eingabe zu konzentrieren.
- Textgenerierung : Erfahren Sie mehr über die verschiedenen Möglichkeiten, wie das Modell Ausgabesequenzen generieren kann. Zu den gängigen Strategien gehören Greedy Decoding, Beam Search, Top-K-Sampling und Kernsampling.
Referenzen :
- Der illustrierte Transformer von Jay Alammar: Eine visuelle und intuitive Erklärung des Transformer-Modells.
- Der illustrierte GPT-2 von Jay Alammar: Noch wichtiger als der vorherige Artikel ist, dass er sich auf die GPT-Architektur konzentriert, die der von Llama sehr ähnlich ist.
- Visuelle Einführung in Transformers von 3Blue1Brown: Einfache, leicht verständliche visuelle Einführung in Transformers
- LLM-Visualisierung von Brendan Bycroft: Unglaubliche 3D-Visualisierung dessen, was in einem LLM passiert.
- nanoGPT von Andrej Karpathy: Ein 2 Stunden langes YouTube-Video zur Neuimplementierung von GPT von Grund auf (für Programmierer).
- Aufmerksamkeit? Aufmerksamkeit! von Lilian Weng: Stellen Sie das Bedürfnis nach Aufmerksamkeit auf formellere Weise vor.
- Dekodierungsstrategien in LLMs: Bereitstellung von Code und einer visuellen Einführung in die verschiedenen Dekodierungsstrategien zur Textgenerierung.
2. Erstellen eines Anweisungsdatensatzes
Während es einfach ist, Rohdaten von Wikipedia und anderen Websites zu finden, ist es schwierig, Paare von Anweisungen und Antworten in freier Wildbahn zu sammeln. Wie beim traditionellen maschinellen Lernen hat die Qualität des Datensatzes direkten Einfluss auf die Qualität des Modells, weshalb sie möglicherweise die wichtigste Komponente im Feinabstimmungsprozess ist.
- Alpaka-ähnlicher Datensatz : Generieren Sie synthetische Daten von Grund auf mit der OpenAI API (GPT). Sie können Seeds und Systemaufforderungen angeben, um einen vielfältigen Datensatz zu erstellen.
- Fortgeschrittene Techniken : Erfahren Sie, wie Sie vorhandene Datensätze mit Evol-Instruct verbessern und hochwertige synthetische Daten wie in den Orca- und Phi-1-Artikeln generieren.
- Daten filtern : Traditionelle Techniken mit Regex, Entfernen von Beinahe-Duplikaten, Fokussierung auf Antworten mit einer hohen Anzahl von Token usw.
- Eingabeaufforderungsvorlagen : Es gibt keine wirkliche Standardmethode zum Formatieren von Anweisungen und Antworten. Deshalb ist es wichtig, die verschiedenen Chat-Vorlagen wie ChatML, Alpaca usw. zu kennen.
Referenzen :
- Vorbereiten eines Datensatzes für die Unterrichtsoptimierung von Thomas Capelle: Erkundung der Alpaca- und Alpaca-GPT4-Datensätze und deren Formatierung.
- Generieren eines klinischen Anweisungsdatensatzes von Solano Todeschini: Tutorial zum Erstellen eines synthetischen Anweisungsdatensatzes mit GPT-4.
- GPT 3.5 für die Nachrichtenklassifizierung von Kshitiz Sahay: Verwenden Sie GPT 3.5, um einen Anweisungsdatensatz zur Feinabstimmung von Llama 2 für die Nachrichtenklassifizierung zu erstellen.
- Datensatzerstellung zur Feinabstimmung von LLM: Notizbuch, das einige Techniken zum Filtern eines Datensatzes und zum Hochladen des Ergebnisses enthält.
- Chat-Vorlage von Matthew Carrigan: Hugging Faces Seite über Eingabeaufforderungsvorlagen
3. Modelle vor dem Training
Die Vorschulung ist ein sehr langer und kostspieliger Prozess, weshalb dies nicht der Schwerpunkt dieses Kurses ist. Es ist gut, ein gewisses Maß an Verständnis dafür zu haben, was während des Vortrainings passiert, praktische Erfahrung ist jedoch nicht erforderlich.
- Datenpipeline : Für das Vortraining sind riesige Datensätze erforderlich (z. B. wurde Llama 2 mit 2 Billionen Token trainiert), die gefiltert, tokenisiert und mit einem vordefinierten Vokabular zusammengestellt werden müssen.
- Kausale Sprachmodellierung : Lernen Sie den Unterschied zwischen kausaler und maskierter Sprachmodellierung sowie die in diesem Fall verwendete Verlustfunktion kennen. Erfahren Sie für eine effiziente Vorschulung mehr über Megatron-LM oder gpt-neox.
- Skalierungsgesetze : Die Skalierungsgesetze beschreiben die erwartete Modellleistung basierend auf der Modellgröße, der Datensatzgröße und der für das Training verwendeten Rechenmenge.
- Hochleistungsrechnen : Das liegt hier nicht im Rahmen, aber mehr Wissen über HPC ist von grundlegender Bedeutung, wenn Sie planen, Ihr eigenes LLM von Grund auf zu erstellen (Hardware, verteilte Arbeitslast usw.).
Referenzen :
- LLMDataHub von Junhao Zhao: Kuratierte Liste von Datensätzen für Vortraining, Feinabstimmung und RLHF.
- Trainieren eines kausalen Sprachmodells von Grund auf mit Hugging Face: Trainieren Sie ein GPT-2-Modell von Grund auf mit der Transformers-Bibliothek vor.
- TinyLlama von Zhang et al.: Schauen Sie sich dieses Projekt an, um ein gutes Verständnis dafür zu bekommen, wie ein Llama-Modell von Grund auf trainiert wird.
- Kausale Sprachmodellierung durch Hugging Face: Erklären Sie den Unterschied zwischen kausaler und maskierter Sprachmodellierung und wie Sie ein DistilGPT-2-Modell schnell verfeinern können.
- Chinchillas wilde Implikationen von Nostalgebraist: Besprechen Sie die Skalierungsgesetze und erklären Sie, was sie für LLMs im Allgemeinen bedeuten.
- BLOOM von BigScience: Begriffsseite, die beschreibt, wie das BLOOM-Modell erstellt wurde, mit vielen nützlichen Informationen über den technischen Teil und die aufgetretenen Probleme.
- OPT-175 Logbook von Meta: Recherchieren Sie Protokolle, die zeigen, was schief gelaufen ist und was richtig gelaufen ist. Nützlich, wenn Sie planen, ein sehr großes Sprachmodell (in diesem Fall 175B Parameter) vorab zu trainieren.
- LLM 360: Ein Framework für Open-Source-LLMs mit Trainings- und Datenvorbereitungscode, Daten, Metriken und Modellen.
4. Überwachte Feinabstimmung
Vorab trainierte Modelle werden nur auf die nächste Token-Vorhersageaufgabe trainiert, weshalb sie keine hilfreichen Assistenten sind. Mit SFT können Sie sie anpassen, um auf Anweisungen zu reagieren. Darüber hinaus können Sie Ihr Modell anhand beliebiger Daten (privat, von GPT-4 nicht sichtbar usw.) verfeinern und verwenden, ohne für eine API wie die von OpenAI bezahlen zu müssen.
- Vollständige Feinabstimmung : Vollständige Feinabstimmung bezieht sich auf das Training aller Parameter im Modell. Es handelt sich nicht um eine effiziente Technik, sie führt jedoch zu etwas besseren Ergebnissen.
- LoRA : Eine Parameter-effiziente Technik (PEFT), die auf Low-Rank-Adaptern basiert. Anstatt alle Parameter zu trainieren, trainieren wir nur diese Adapter.
- QLoRA : Ein weiteres auf LoRA basierendes PEFT, das auch die Gewichte des Modells in 4 Bit quantisiert und ausgelagerte Optimierer einführt, um Speicherspitzen zu verwalten. Kombinieren Sie es mit Unsloth, um es effizient auf einem kostenlosen Colab-Notebook auszuführen.
- Axolotl : Ein benutzerfreundliches und leistungsstarkes Feinabstimmungstool, das in vielen hochmodernen Open-Source-Modellen verwendet wird.
- DeepSpeed : Effizientes Vortraining und Feinabstimmung von LLMs für Multi-GPU- und Multi-Node-Einstellungen (implementiert in Axolotl).
Referenzen :
- Der LLM-Trainingsleitfaden für Anfänger von Alpin: Überblick über die wichtigsten Konzepte und Parameter, die bei der Feinabstimmung von LLMs zu berücksichtigen sind.
- LoRA-Einblicke von Sebastian Raschka: Praktische Einblicke in LoRA und wie man die besten Parameter auswählt.
- Optimieren Sie Ihr eigenes Llama 2-Modell: Praktisches Tutorial zur Feinabstimmung eines Llama 2-Modells mithilfe von Hugging Face-Bibliotheken.
- Padding Large Language Models von Benjamin Marie: Best Practices zum Padding von Trainingsbeispielen für kausale LLMs
- Ein Anfängerleitfaden zur LLM-Feinabstimmung: Tutorial zur Feinabstimmung eines CodeLlama-Modells mit Axolotl.
5. Präferenzausrichtung
Nach der überwachten Feinabstimmung ist RLHF ein Schritt, der verwendet wird, um die Antworten des LLM an die menschlichen Erwartungen anzupassen. Die Idee besteht darin, Präferenzen aus menschlichem (oder künstlichem) Feedback zu lernen, das genutzt werden kann, um Vorurteile abzubauen, Modelle zu zensieren oder sie sinnvoller zu gestalten. Es ist komplexer als SFT und wird oft als optional angesehen.
- Präferenzdatensätze : Diese Datensätze enthalten typischerweise mehrere Antworten mit einer bestimmten Rangfolge, was ihre Erstellung schwieriger macht als Anweisungsdatensätze.
- Proximale Richtlinienoptimierung : Dieser Algorithmus nutzt ein Belohnungsmodell, das vorhersagt, ob ein bestimmter Text von Menschen hoch bewertet wird. Diese Vorhersage wird dann verwendet, um das SFT-Modell mit einer Strafe basierend auf der KL-Divergenz zu optimieren.
- Direkte Präferenzoptimierung : DPO vereinfacht den Prozess, indem es ihn als Klassifizierungsproblem umformuliert. Es verwendet ein Referenzmodell anstelle eines Belohnungsmodells (kein Training erforderlich) und erfordert nur einen Hyperparameter, wodurch es stabiler und effizienter wird.
Referenzen :
- Distilabel von Argilla: Hervorragendes Tool zum Erstellen eigener Datensätze. Es wurde speziell für Präferenzdatensätze entwickelt, kann aber auch SFT durchführen.
- Eine Einführung in das Training von LLMs mit RLHF von Ayush Thakur: Erklären Sie, warum RLHF wünschenswert ist, um Voreingenommenheit zu reduzieren und die Leistung in LLMs zu steigern.
- Illustration RLHF von Hugging Face: Einführung in RLHF mit Belohnungsmodelltraining und Feinabstimmung mit Reinforcement Learning.
- Präferenzoptimierungs-LLMs durch Hugging Face: Vergleich der DPO-, IPO- und KTO-Algorithmen zur Durchführung der Präferenzausrichtung.
- LLM-Training: RLHF und seine Alternativen von Sebastian Rashcka: Überblick über den RLHF-Prozess und Alternativen wie RLAIF.
- Feinabstimmung von Mistral-7b mit DPO: Tutorial zur Feinabstimmung eines Mistral-7b-Modells mit DPO und zur Reproduktion von NeuralHermes-2.5.
6. Bewertung
Die Evaluierung von LLMs ist ein unterbewerteter Teil der Pipeline, der zeitaufwändig und mäßig zuverlässig ist. Ihre nachgelagerte Aufgabe sollte vorgeben, was Sie bewerten möchten, aber denken Sie immer an das Goodhart-Gesetz: „Wenn eine Maßnahme zu einem Ziel wird, ist sie keine gute Maßnahme mehr.“
- Traditionelle Metriken : Metriken wie Ratlosigkeit und BLEU-Score sind nicht mehr so beliebt wie früher, weil sie in den meisten Kontexten fehlerhaft sind. Es ist immer noch wichtig, sie zu verstehen und zu wissen, wann sie angewendet werden können.
- Allgemeine Benchmarks : Basierend auf dem Language Model Evaluation Harness ist das Open LLM Leaderboard der wichtigste Benchmark für allgemeine LLMs (wie ChatGPT). Es gibt andere beliebte Benchmarks wie BigBench, MT-Bench usw.
- Aufgabenspezifische Benchmarks : Für Aufgaben wie Zusammenfassung, Übersetzung und Beantwortung von Fragen gibt es spezielle Benchmarks, Metriken und sogar Subdomänen (medizinisch, finanziell usw.), wie z. B. PubMedQA für die Beantwortung biomedizinischer Fragen.
- Menschliche Bewertung : Die zuverlässigste Bewertung ist die Akzeptanzrate durch Benutzer oder durch Menschen vorgenommene Vergleiche. Die Protokollierung des Benutzerfeedbacks zusätzlich zu den Chat-Spuren (z. B. mithilfe von LangSmith) hilft dabei, potenzielle Verbesserungsbereiche zu identifizieren.
Referenzen :
- Perplexity von Modellen fester Länge von Hugging Face: Übersicht über Perplexity mit Code zur Implementierung mit der Transformers-Bibliothek.
- BLEU auf eigene Gefahr von Rachael Tatman: Überblick über den BLEU-Score und seine vielen Probleme mit Beispielen.
- Eine Umfrage zur Bewertung von LLMs von Chang et al.: Umfassender Artikel darüber, was zu bewerten ist, wo zu bewerten ist und wie zu bewerten ist.
- Chatbot Arena Leaderboard von lmsys: Elo-Bewertung von Allzweck-LLMs, basierend auf von Menschen durchgeführten Vergleichen.
7. Quantisierung
Quantisierung ist der Prozess der Konvertierung der Gewichte (und Aktivierungen) eines Modells mit einer geringeren Genauigkeit. Beispielsweise können mit 16 Bit gespeicherte Gewichte in eine 4-Bit-Darstellung umgewandelt werden. Diese Technik wird immer wichtiger, um die mit LLMs verbundenen Rechen- und Speicherkosten zu reduzieren.
- Basistechniken : Lernen Sie die verschiedenen Präzisionsstufen (FP32, FP16, INT8 usw.) und die Durchführung einer naiven Quantisierung mit Absmax- und Nullpunkttechniken.
- GGUF und llama.cpp : Ursprünglich für die Ausführung auf CPUs konzipiert, haben sich llama.cpp und das GGUF-Format zu den beliebtesten Tools für die Ausführung von LLMs auf Consumer-Hardware entwickelt.
- GPTQ und EXL2 : GPTQ und insbesondere das EXL2-Format bieten eine unglaubliche Geschwindigkeit, können aber nur auf GPUs ausgeführt werden. Es dauert auch lange, bis Modelle quantisiert sind.
- AWQ : Dieses neue Format ist genauer als GPTQ (geringere Verwirrung), verbraucht aber viel mehr VRAM und ist nicht unbedingt schneller.
Referenzen :
- Einführung in die Quantisierung: Überblick über Quantisierung, Absmax- und Nullpunktquantisierung sowie LLM.int8() mit Code.
- Quantisierung von Llama-Modellen mit llama.cpp: Tutorial zur Quantisierung eines Llama-2-Modells mit llama.cpp und dem GGUF-Format.
- 4-Bit-LLM-Quantisierung mit GPTQ: Tutorial zur Quantisierung eines LLM mithilfe des GPTQ-Algorithmus mit AutoGPTQ.
- ExLlamaV2: Die schnellste Bibliothek zum Ausführen von LLMs: Anleitung zum Quantisieren eines Mistral-Modells mithilfe des EXL2-Formats und zum Ausführen mit der ExLlamaV2-Bibliothek.
- Aktivierungsbewusste Gewichtsquantisierung von FriendliAI verstehen: Überblick über die AWQ-Technik und ihre Vorteile.
8. Neue Trends
- Positionseinbettungen : Erfahren Sie, wie LLMs Positionen kodieren, insbesondere relative Positionskodierungsschemata wie RoPE. Implementieren Sie YaRN (multipliziert die Aufmerksamkeitsmatrix mit einem Temperaturfaktor) oder ALiBi (Aufmerksamkeitsstrafe basierend auf der Token-Distanz), um die Kontextlänge zu erweitern.
- Zusammenführen von Modellen : Das Zusammenführen trainierter Modelle ist zu einer beliebten Methode zur Erstellung leistungsstarker Modelle ohne Feinabstimmung geworden. Die beliebte Mergekit-Bibliothek implementiert die beliebtesten Merge-Methoden wie SLERP, DARE und TIES.
- Mischung aus Experten : Mixtral hat die MoE-Architektur dank seiner hervorragenden Leistung wieder populär gemacht. Parallel dazu entstand in der OSS-Community eine Art frankenMoE durch die Zusammenführung von Modellen wie Phixtral, einer günstigeren und leistungsfähigeren Option.
- Multimodale Modelle : Diese Modelle (wie CLIP, Stable Diffusion oder LLaVA) verarbeiten mehrere Arten von Eingaben (Text, Bilder, Audio usw.) mit einem einheitlichen Einbettungsraum, der leistungsstarke Anwendungen wie Text-zu-Bild freischaltet.
Referenzen :
- Erweiterung des RoPE durch EleutherAI: Artikel, der die verschiedenen Positionskodierungstechniken zusammenfasst.
- YaRN verstehen von Rajat Chawla: Einführung in YaRN.
- LLMs mit Mergekit zusammenführen: Tutorial zum Zusammenführen von Modellen mit Mergekit.
- Expertenmischung erklärt von Hugging Face: Ausführlicher Leitfaden über MoEs und ihre Funktionsweise.
- Große multimodale Modelle von Chip Huyen: Überblick über multimodale Systeme und die jüngste Geschichte dieses Fachgebiets.
? Der LLM-Ingenieur
In diesem Abschnitt des Kurses geht es darum, zu lernen, wie man LLM-basierte Anwendungen erstellt, die in der Produktion verwendet werden können, wobei der Schwerpunkt auf der Erweiterung und Bereitstellung von Modellen liegt.
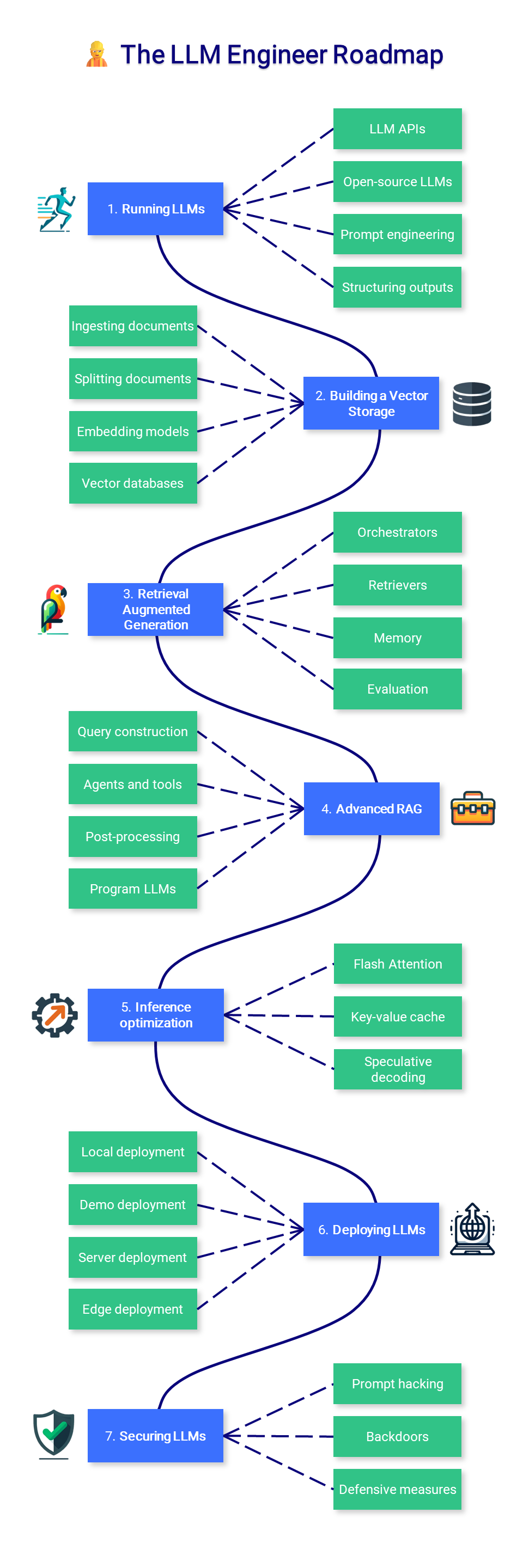
1. LLMs ausführen
Der Betrieb von LLMs kann aufgrund hoher Hardwareanforderungen schwierig sein. Abhängig von Ihrem Anwendungsfall möchten Sie ein Modell möglicherweise einfach über eine API (wie GPT-4) nutzen oder es lokal ausführen. In jedem Fall können zusätzliche Eingabeaufforderungs- und Anleitungstechniken die Ausgabe Ihrer Anwendungen verbessern und einschränken.
- LLM-APIs : APIs sind eine bequeme Möglichkeit, LLMs bereitzustellen. Dieser Raum ist zwischen privaten LLMs (OpenAI, Google, Anthropic, Cohere usw.) und Open-Source-LLMs (OpenRouter, Hugging Face, Together AI usw.) aufgeteilt.
- Open-Source-LLMs : Der Hugging Face Hub ist ein großartiger Ort, um LLMs zu finden. Sie können einige davon direkt in Hugging Face Spaces ausführen oder sie herunterladen und lokal in Apps wie LM Studio oder über die CLI mit llama.cpp oder Ollama ausführen.
- Prompt Engineering : Zu den gängigen Techniken gehören Zero-Shot-Prompting, Fence-Shot-Prompting, Chain of Thought und ReAct. Sie funktionieren besser mit größeren Modellen, können aber an kleinere angepasst werden.
- Ausgaben strukturieren : Viele Aufgaben erfordern eine strukturierte Ausgabe, etwa eine strikte Vorlage oder ein JSON-Format. Bibliotheken wie LMQL, Outlines, Guidance usw. können verwendet werden, um die Generierung zu steuern und eine bestimmte Struktur zu respektieren.
Referenzen :
- Führen Sie ein LLM lokal mit LM Studio aus von Nisha Arya: Kurzanleitung zur Verwendung von LM Studio.
- Prompt-Engineering-Leitfaden von DAIR.AI: Vollständige Liste von Prompt-Techniken mit Beispielen
- Outlines – Schnellstart: Liste der von Outlines ermöglichten geführten Generierungstechniken.
- LMQL – Überblick: Einführung in die LMQL-Sprache.
2. Aufbau eines Vektorspeichers
Das Erstellen eines Vektorspeichers ist der erste Schritt zum Aufbau einer RAG-Pipeline (Retrieval Augmented Generation). Dokumente werden geladen, aufgeteilt und relevante Teile werden verwendet, um Vektordarstellungen (Einbettungen) zu erstellen, die für die zukünftige Verwendung während der Inferenz gespeichert werden.
- Dokumente aufnehmen : Dokumentlader sind praktische Wrapper, die viele Formate verarbeiten können: PDF, JSON, HTML, Markdown usw. Sie können Daten auch direkt aus einigen Datenbanken und APIs (GitHub, Reddit, Google Drive usw.) abrufen.
- Aufteilen von Dokumenten : Textteiler zerlegen Dokumente in kleinere, semantisch sinnvolle Teile. Anstatt den Text nach n Zeichen zu teilen, ist es oft besser, ihn nach Kopfzeile oder rekursiv mit einigen zusätzlichen Metadaten zu teilen.
- Einbettungsmodelle : Einbettungsmodelle konvertieren Text in Vektordarstellungen. Es ermöglicht ein tieferes und differenzierteres Verständnis der Sprache, was für die Durchführung einer semantischen Suche unerlässlich ist.
- Vektordatenbanken : Vektordatenbanken (wie Chroma, Pinecone, Milvus, FAISS, Annoy usw.) dienen zum Speichern von Einbettungsvektoren. Sie ermöglichen das effiziente Abrufen von Daten, die einer auf Vektorähnlichkeit basierenden Abfrage „am ähnlichsten“ sind.
Referenzen :
- LangChain – Textsplitter: Liste der verschiedenen in LangChain implementierten Textsplitter.
- Sentence Transformers-Bibliothek: Beliebte Bibliothek zum Einbetten von Modellen.
- MTEB-Bestenliste: Bestenliste für Einbettungsmodelle.
- Die Top 5 Vektordatenbanken von Moez Ali: Ein Vergleich der besten und beliebtesten Vektordatenbanken.
3. Augmented Generation abrufen
Mit RAG rufen LLMs kontextbezogene Dokumente aus einer Datenbank ab, um die Genauigkeit ihrer Antworten zu verbessern. RAG ist eine beliebte Möglichkeit, das Wissen des Modells ohne Feinabstimmung zu erweitern.
- Orchestratoren : Orchestratoren (wie LangChain, LlamaIndex, FastRAG usw.) sind beliebte Frameworks, um Ihre LLMs mit Tools, Datenbanken, Speichern usw. zu verbinden und deren Fähigkeiten zu erweitern.
- Retriever : Benutzeranweisungen sind nicht für das Retrieval optimiert. Verschiedene Techniken (z. B. Multi-Query-Retriever, HyDE usw.) können angewendet werden, um sie umzuformulieren/erweitern und die Leistung zu verbessern.
- Erinnerung : Um sich frühere Anweisungen und Antworten zu merken, fügen LLMs und Chatbots wie ChatGPT diesen Verlauf zu ihrem Kontextfenster hinzu. Dieser Puffer kann durch Zusammenfassung (z. B. Verwendung eines kleineren LLM), einen Vektorspeicher + RAG usw. verbessert werden.
- Bewertung : Wir müssen sowohl den Dokumentenabruf (Kontextpräzision und Erinnerung) als auch die Generierungsphase (Treue und Antwortrelevanz) bewerten. Es kann mit den Tools Ragas und DeepEval vereinfacht werden.
Referenzen :
- Llamaindex – Allgemeine Konzepte: Die wichtigsten Konzepte, die Sie beim Bau von RAG-Pipelines kennen sollten.
- Pinecone – Retrieval Augmentation: Überblick über den Retrieval Augmentation-Prozess.
- LangChain – Fragen und Antworten mit RAG: Schritt-für-Schritt-Anleitung zum Aufbau einer typischen RAG-Pipeline.
- LangChain – Speichertypen: Liste verschiedener Speichertypen mit relevanter Verwendung.
- RAG-Pipeline – Metriken: Übersicht über die wichtigsten Metriken, die zur Bewertung von RAG-Pipelines verwendet werden.
4. Erweitertes RAG
Für reale Anwendungen können komplexe Pipelines, einschließlich SQL- oder Diagrammdatenbanken, sowie die automatische Auswahl relevanter Tools und APIs erforderlich sein. Diese erweiterten Techniken können eine Basislösung verbessern und zusätzliche Funktionen bereitstellen.
- Abfragekonstruktion : Strukturierte Daten, die in herkömmlichen Datenbanken gespeichert sind, erfordern eine bestimmte Abfragesprache wie SQL, Cypher, Metadaten usw. Wir können die Benutzeranweisung direkt in eine Abfrage übersetzen, um mit der Abfragekonstruktion auf die Daten zuzugreifen.
- Agenten und Tools : Agenten ergänzen LLMs, indem sie automatisch die relevantesten Tools auswählen, um eine Antwort zu liefern. Diese Tools können so einfach sein wie die Verwendung von Google oder Wikipedia oder komplexer wie ein Python-Interpreter oder Jira.
- Nachbearbeitung : Letzter Schritt, der die Eingaben verarbeitet, die dem LLM zugeführt werden. Es erhöht die Relevanz und Vielfalt der abgerufenen Dokumente durch Neuordnung, RAG-Fusion und Klassifizierung.
- Programm-LLMs : Frameworks wie DSPy ermöglichen es Ihnen, Eingabeaufforderungen und Gewichtungen basierend auf automatisierten Auswertungen auf programmatische Weise zu optimieren.
Referenzen :
- LangChain – Abfragekonstruktion: Blogbeitrag über verschiedene Arten der Abfragekonstruktion.
- LangChain – SQL: Tutorial zur Interaktion mit SQL-Datenbanken mit LLMs, einschließlich Text-to-SQL und einem optionalen SQL-Agenten.
- Pinecone – LLM-Agenten: Einführung in Agenten und Tools verschiedener Typen.
- LLM Powered Autonomous Agents von Lilian Weng: Mehr theoretischer Artikel über LLM-Agenten.
- LangChain – RAG von OpenAI: Überblick über die von OpenAI verwendeten RAG-Strategien, einschließlich Nachbearbeitung.
- DSPy in 8 Schritten: Allgemeiner Leitfaden zu DSPy mit Einführung in Module, Signaturen und Optimierer.
5. Inferenzoptimierung
Die Textgenerierung ist ein kostspieliger Prozess, der teure Hardware erfordert. Zusätzlich zur Quantisierung wurden verschiedene Techniken vorgeschlagen, um den Durchsatz zu maximieren und die Inferenzkosten zu reduzieren.
- Flash Attention : Optimierung des Aufmerksamkeitsmechanismus, um seine Komplexität von quadratisch in linear umzuwandeln und so sowohl das Training als auch die Schlussfolgerung zu beschleunigen.
- Schlüsselwert-Cache : Machen Sie sich mit dem Schlüsselwert-Cache und den Verbesserungen vertraut, die in Multi-Query Attention (MQA) und Grouped-Query Attention (GQA) eingeführt wurden.
- Spekulative Dekodierung : Verwenden Sie ein kleines Modell, um Entwürfe zu erstellen, die dann von einem größeren Modell überprüft werden, um die Textgenerierung zu beschleunigen.
Referenzen :
- GPU-Inferenz durch Hugging Face: Erklären Sie, wie Sie die Inferenz auf GPUs optimieren können.
- LLM-Inferenz von Databricks: Best Practices zur Optimierung der LLM-Inferenz in der Produktion.
- Optimierung von LLMs für Geschwindigkeit und Speicher durch Hugging Face: Erklären Sie drei Haupttechniken zur Optimierung von Geschwindigkeit und Speicher, nämlich Quantisierung, Flash Attention und Architekturinnovationen.
- Assisted Generation by Hugging Face: HFs Version der spekulativen Dekodierung. Es ist ein interessanter Blogbeitrag darüber, wie es mit Code funktioniert, um es zu implementieren.
6. Bereitstellung von LLMs
Die Bereitstellung von LLMs im großen Maßstab ist eine technische Meisterleistung, die mehrere GPU-Cluster erfordern kann. In anderen Szenarien können Demos und lokale Apps mit einer viel geringeren Komplexität realisiert werden.
- Lokale Bereitstellung : Datenschutz ist ein wichtiger Vorteil, den Open-Source-LLMs gegenüber privaten LLMs haben. Lokale LLM-Server (LM Studio, Ollama, oobabooga, kobold.cpp usw.) nutzen diesen Vorteil, um lokale Apps zu betreiben.
- Demo-Bereitstellung : Frameworks wie Gradio und Streamlit sind hilfreich, um Prototypen von Anwendungen zu erstellen und Demos zu teilen. Sie können sie auch problemlos online hosten, beispielsweise mit den umarmenden Gesichtsräumen.
- Serverbereitstellung : LLMs im Maßstab bereitstellen Cloud (siehe auch Skypilot) oder On-Prem-Infrastruktur und nutzen häufig optimierte Textgenerierungs-Frameworks wie TGI, VLLM usw.
- Edge-Bereitstellung : In eingeschränkten Umgebungen können Hochleistungs-Frameworks wie MLC LLM und MNN-LlM LLM in Webbrowsern, Android und iOS bereitstellen.
Referenzen :
- Streamlit - Erstellen Sie eine grundlegende LLM -App: Tutorial, um eine grundlegende Chatgpt -ähnliche App mit Streamlit zu erstellen.
- HF LLM -Inferenzbehälter: Bereitstellen von LLMs bei Amazon Sagemaker mit dem Inferenzbehälter von Hugging Face.
- Philschmid Blog von Philipp Schmid: Sammlung hochwertiger Artikel über die LLM-Bereitstellung mit Amazon Sagemaker.
- Optimierung der Latenz von Hamel Husain: Vergleich von TGI, VllM, Ctranslate2 und MLC in Bezug auf Durchsatz und Latenz.
7. Sicherung von LLMs
Zusätzlich zu herkömmlichen Sicherheitsproblemen im Zusammenhang mit Software haben LLMs aufgrund der Art und Weise, wie sie trainiert und ausgelöst werden, einzigartige Schwächen.
- Schnelles Hacken : Verschiedene Techniken im Zusammenhang mit dem schnellen Engineering, einschließlich der schnellen Einspritzung (zusätzliche Anweisung zum Entführen der Antwort des Modells), Daten/Eingabeaufforderung (Abrufen der ursprünglichen Daten/Eingabeaufforderung) und Jailbreaking (Handwerksanweisungen zur Umgehung der Sicherheitsfunktionen).
- Backdoors : Angriffsvektoren können auf die Trainingsdaten selbst abzielen, indem sie die Trainingsdaten (z. B. mit falschen Informationen) vergiften oder Hintertoors erstellen (geheime Trigger, um das Verhalten des Modells während der Inferenz zu ändern).
- Defensive Maßnahmen : Der beste Weg, um Ihre LLM -Anwendungen zu schützen, besteht darin, sie gegen diese Schwachstellen zu testen (z. B. mit rotem Teaming und Schecks wie Garak) und in der Produktion (mit einem Rahmen wie Langfuse) zu beobachten.
Referenzen :
- OWASP LLM Top 10 von Hego Wiki: Liste der 10 am meisten kritischen Schwachstellen in LLM -Anwendungen.
- Einsprechende Injektionsprimer von Joseph Thacker: Kurzhandbuch für die sofortige Injektion für Ingenieure.
- LLM -Sicherheit von @llm_sec: Umfangreiche Liste der Ressourcen im Zusammenhang mit LLM -Sicherheit.
- Red Teaming LLMs von Microsoft: Leitfaden zur Durchführung von Red Teaming mit LLMs.
Danksagungen
Diese Roadmap wurde von der exzellenten DevOps Roadmap von Mailand Milanović und Romano Roth inspiriert.
Besonderer Dank geht an:
- Thomas Thelen, der mich motiviert hat, eine Roadmap zu schaffen
- André Frade für seine Beiträge und Überprüfung des ersten Entwurfs
- Dino Dunn für die Bereitstellung von Ressourcen zur LLM -Sicherheit
- Magdalena Kuhn zur Verbesserung des Teils "menschlicher Bewertung"
- Odoverdose, weil er 3Blue1Browns Video über Transformers vorschlägt
Haftungsausschluss: Ich bin nicht mit den hier aufgeführten Quellen verbunden.


