Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, Onkar Dabeer.
Dieses Repository enthält die Ressourcen für unser ECCV-2022-Papier „SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation“. Derzeit veröffentlichen wir den Visual Anomaly (VisA)-Datensatz.
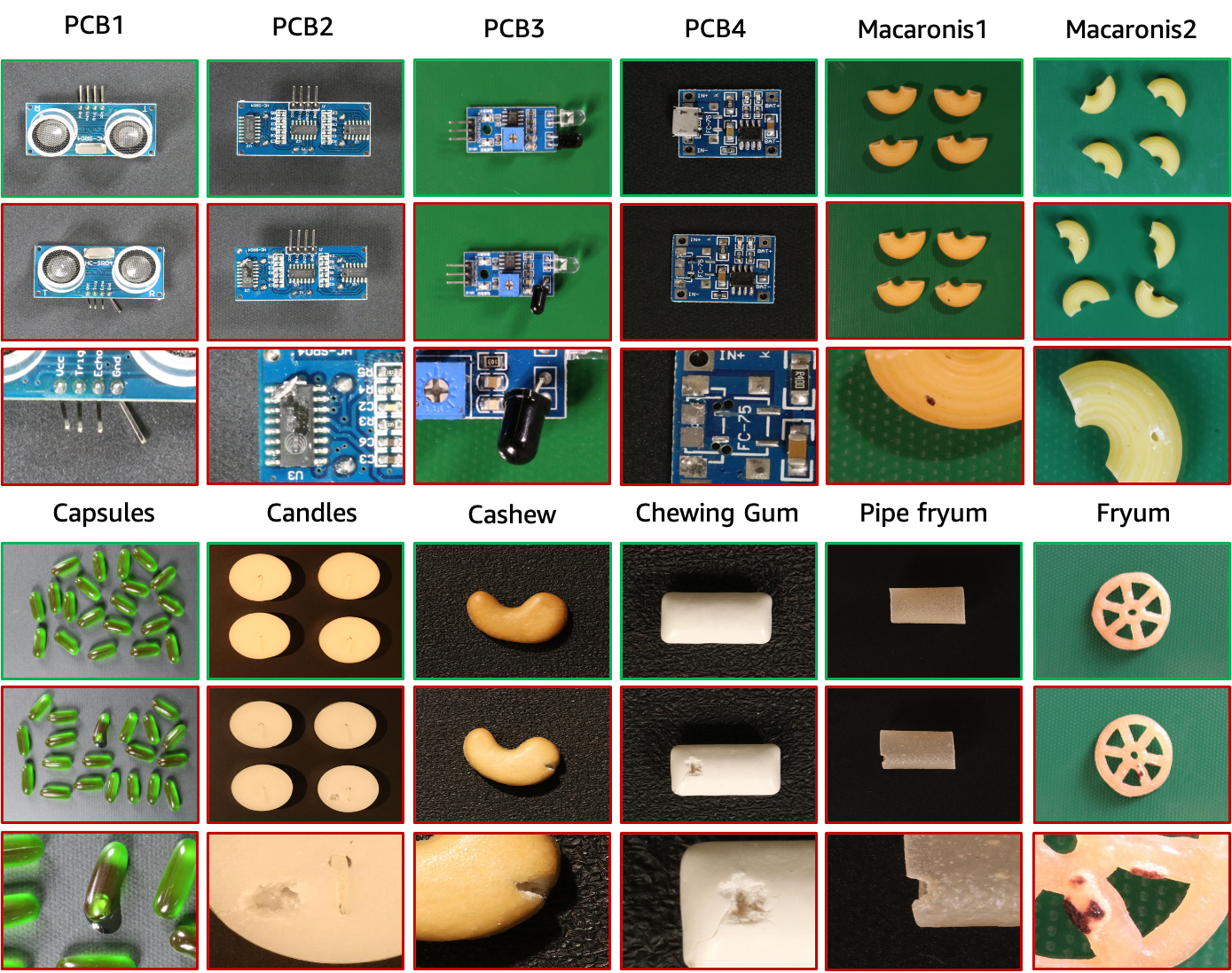
Der VisA-Datensatz enthält 12 Teilmengen, die 12 verschiedenen Objekten entsprechen, wie in der obigen Abbildung dargestellt. Es gibt 10.821 Bilder mit 9.621 normalen und 1.200 anomalen Proben. Vier Untergruppen sind verschiedene Arten von Leiterplatten (PCB) mit relativ komplexen Strukturen, die Transistoren, Kondensatoren, Chips usw. enthalten. Für den Fall mehrerer Instanzen in einer Ansicht erfassen wir vier Untergruppen: Kapseln, Kerzen, Makkaroni1 und Makkaroni2. Die Exemplare in Capsules und Macaroni2 unterscheiden sich stark in Lage und Pose. Darüber hinaus sammeln wir vier Untergruppen, darunter Cashew, Kaugummi, Fryum und Pipe Fryum, in denen Objekte grob ausgerichtet sind. Die anomalen Bilder enthalten verschiedene Mängel, darunter Oberflächenfehler wie Kratzer, Dellen, Farbflecken oder Risse sowie strukturelle Mängel wie falsche Platzierung oder fehlende Teile.
| Objekt | # normale Proben | # Anomalieproben | # Anomalieklassen | Objekttyp |
|---|---|---|---|---|
| PCB1 | 1.004 | 100 | 4 | Komplexe Struktur |
| PCB2 | 1.001 | 100 | 4 | Komplexe Struktur |
| PCB3 | 1.006 | 100 | 4 | Komplexe Struktur |
| PCB4 | 1.005 | 100 | 7 | Komplexe Struktur |
| Kapseln | 602 | 100 | 5 | Mehrere Instanzen |
| Kerzen | 1.000 | 100 | 8 | Mehrere Instanzen |
| Makkaroni1 | 1.000 | 100 | 7 | Mehrere Instanzen |
| Makkaroni2 | 1.000 | 100 | 7 | Mehrere Instanzen |
| Cashew | 500 | 100 | 9 | Einzelinstanz |
| Kaugummi | 503 | 100 | 6 | Einzelinstanz |
| Fryum | 500 | 100 | 8 | Einzelinstanz |
| Rohrfryum | 500 | 100 | 9 | Einzelinstanz |
Wir hosten den VisA-Datensatz in AWS S3 und Sie können ihn unter dieser URL herunterladen.
Der Datenbaum der heruntergeladenen Daten ist wie folgt.
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv gibt für jedes Bild eine Beschriftung auf Bildebene und eine Anmerkungsmaske auf Pixelebene an. Die id2class-Map-Funktionen für Multi-Class-Masken finden Sie in ./utils/id2class.py. Hier werden die Masken für normale Bilder aus Platzgründen nicht gespeichert.
Um die im Originalpapier beschriebenen 1-Klassen-, 2-Klassen-Highshot- und 2-Klassen-Fewshot-Setups vorzubereiten, verwenden wir ./utils/prepare_data.py, um Daten gemäß den Datenaufteilungsdateien in „./split_csv/“ neu zu organisieren. . Wir geben wie folgt eine Beispielbefehlszeile für die Vorbereitung des 1-Klassen-Setups an.
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
Der Datenbaum des neu organisierten 1-Klassen-Setups sieht wie folgt aus.
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...Insbesondere folgen die neu organisierten Daten für die 1-Klassen-Einrichtung dem Datenbaum von MVTec-AD. Für jedes Objekt gibt es drei Ordner für die Daten:
Beachten Sie, dass die Multi-Class-Ground-Truth-Segmentierungsmasken im Originaldatensatz in Binärmasken neu indiziert werden, wobei 0 Normalität und 255 Anomalie anzeigt.
Darüber hinaus können die 2-Klassen-Setups auf ähnliche Weise vorbereitet werden, indem die Argumente von Prepare_data.py geändert werden.
Informationen zur Berechnung von Klassifizierungs- und Segmentierungsmetriken finden Sie unter ./utils/metrics.py. Beachten Sie, dass wir bei der Berechnung der Lokalisierungsmetriken die normalen Stichproben berücksichtigen. Dies unterscheidet sich von einigen anderen Werken, bei denen die normalen Beispiele bei der Lokalisierung außer Acht gelassen werden.
Bitte zitieren Sie das folgende Dokument, wenn dieser Datensatz Ihrem Projekt hilft:
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}Die Daten werden unter der CC BY 4.0-Lizenz veröffentlicht.


