Dieses Repository enthält PyTorch-Code für Motif, der KI-Agenten auf NetHack mit Belohnungsfunktionen trainiert, die von den Präferenzen eines LLM abgeleitet werden.
Motiv: Intrinsische Motivation durch Feedback zu künstlicher Intelligenz
von Martin Klissarov* & Pierluca D'Oro*, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang und Mikael Henaff
Motif ermittelt die Präferenzen eines Large Language Model (LLM) für Paare von beschrifteten Beobachtungen aus einem auf NetHack gesammelten Datensatz von Interaktionen. Es destilliert automatisch den gesunden Menschenverstand des LLM in eine Belohnungsfunktion, die verwendet wird, um Agenten mit Reinforcement Learning zu schulen.
Um Vergleiche zu erleichtern, stellen wir Trainingskurven in der Pickle-Datei motif_results.pkl bereit, die ein Wörterbuch mit Aufgaben als Schlüssel enthält. Für jede Aufgabe stellen wir eine Liste mit Zeitschritten und durchschnittlichen Renditen für Motif und Baselines für mehrere Seeds bereit.
Wie in der folgenden Abbildung dargestellt, umfasst Motif drei Phasen:
Wir beschreiben jede Phase detailliert, indem wir die notwendigen Datensätze, Befehle und Rohergebnisse bereitstellen, um die Experimente in der Arbeit zu reproduzieren.
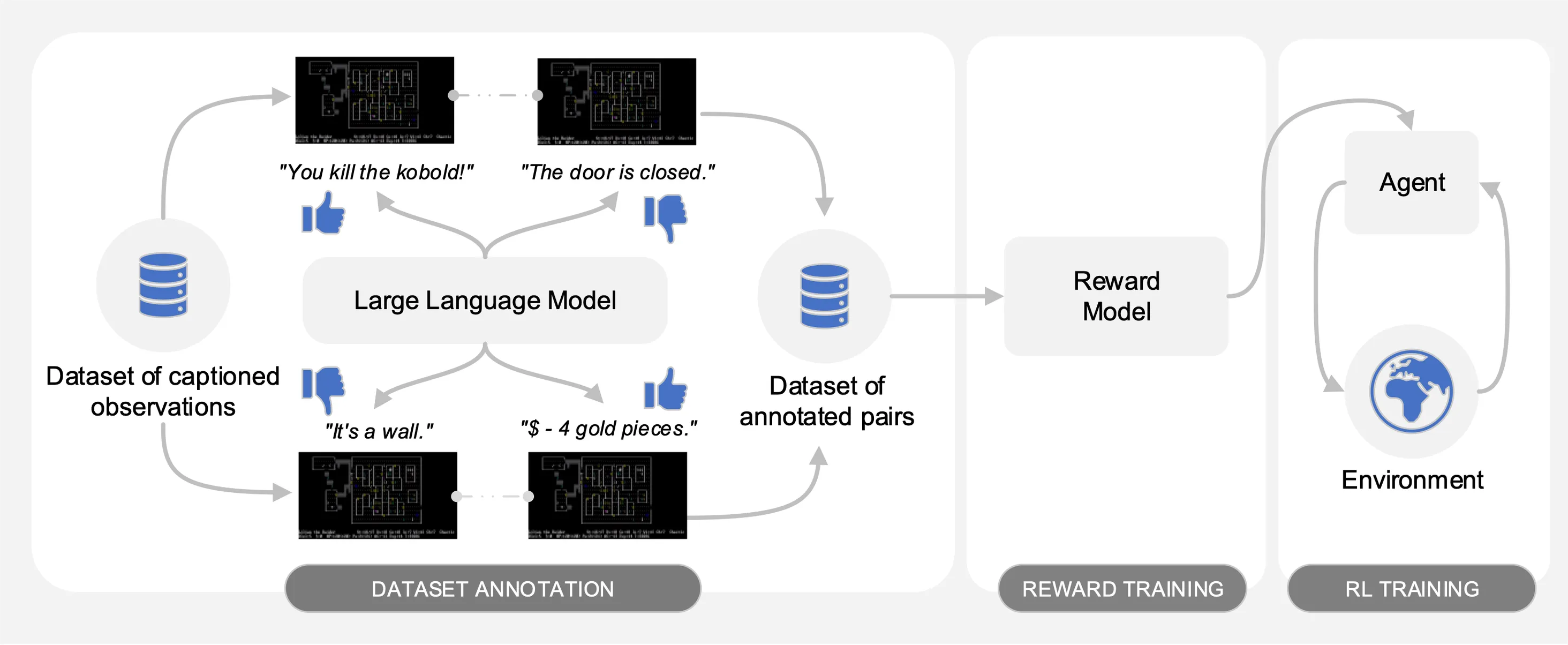
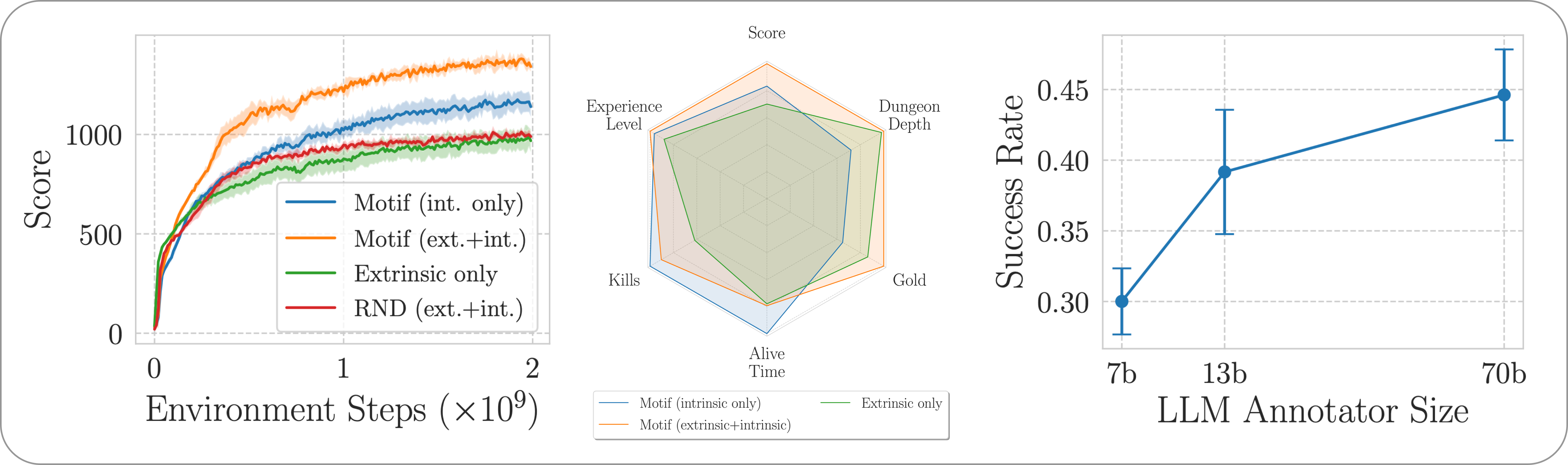
Wir bewerten die Leistung von Motif beim herausfordernden, offenen und prozedural generierten NetHack-Spiel mithilfe der NetHack-Lernumgebung. Wir untersuchen, wie Motif größtenteils intuitive, auf den Menschen ausgerichtete Verhaltensweisen erzeugt, die durch schnelle Änderungen leicht gesteuert werden können, sowie seine Skalierungseigenschaften.

Um die erforderlichen Abhängigkeiten für die gesamte Pipeline zu installieren, führen Sie einfach pip install -r requirements.txt aus.
Für die erste Phase verwenden wir einen Datensatz aus Beobachtungspaaren mit Untertiteln (d. h. Nachrichten aus dem Spiel), die von Agenten gesammelt wurden, die mit Reinforcement Learning geschult wurden, um den Spielstand zu maximieren. Wir stellen den Datensatz in diesem Repository bereit. Wir speichern die verschiedenen Teile im Verzeichnis motif_dataset_zipped , das mit dem folgenden Befehl entpackt werden kann.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
Der von uns bereitgestellte Datensatz enthält eine Reihe von Präferenzen, die von Llama-2-Modellen vergeben werden und im Verzeichnis preference/ enthalten sind, wobei die verschiedenen im Artikel beschriebenen Eingabeaufforderungen verwendet werden. Die Namen der .npy Dateien, die die Anmerkungen enthalten, folgen der Vorlage llama{size}b_msg_{instruction}_{version} , wobei size eine LLM-Größe aus dem Satz {7,13,70} ist, instruction eine in die eingeführte Anweisung ist Eingabeaufforderung, die dem LLM aus dem Satz {defaultgoal, zeroknowledge, combat, gold, stairs} übergeben wird. version ist die Version der Eingabeaufforderungsvorlage, die aus dem Satz {default, reworded} . Hier finden Sie eine Zusammenfassung der verfügbaren Anmerkungen:
| Anmerkung | Anwendungsfall aus dem Papier |
|---|---|
llama70b_msg_defaultgoal_default | Hauptexperimente |
llama70b_msg_combat_default | Ausrichtung auf das Verhalten von The Monster Slayer |
llama70b_msg_gold_default | Ausrichtung auf das Verhalten des Goldsammlers |
llama70b_msg_stairs_default | Ausrichtung auf das Verhalten des Descenders |
llama7b_msg_defaultgoal_default | Skalierungsexperiment |
llama13b_msg_defaultgoal_default | Skalierungsexperiment |
llama70b_msg_zeroknowledge_default | Zero-Knowledge-Prompt-Experiment |
llama70b_msg_defaultgoal_reworded | Experiment zur zeitnahen Umformulierung |
Um die Annotationen zu erstellen, verwenden wir vLLM und die Chat-Version von Llama 2. Wenn Sie Ihre eigenen Annotationen mit Llama 2 generieren oder unseren Annotationsprozess reproduzieren möchten, stellen Sie sicher, dass Sie das Modell herunterladen können, indem Sie den offiziellen Anweisungen folgen (dies ist möglich). Es kann einige Tage dauern, bis Sie Zugriff auf die Modellgewichte haben.
Das Annotationsskript geht davon aus, dass der Datensatz mithilfe des Arguments n-annotation-chunks in verschiedenen Blöcken annotiert wird. Dies ermöglicht einen Prozess, der je nach Ressourcenverfügbarkeit parallelisiert werden kann und robust gegenüber Neustarts/Bevorzugungen ist. Führen Sie den folgenden Befehl aus, um die Ausführung mit einem einzelnen Block durchzuführen (d. h. den gesamten Datensatz zu verarbeiten) und mit der standardmäßigen Eingabeaufforderungsvorlage und Aufgabenspezifikation zu kommentieren.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
Beachten Sie, dass das Standardverhalten den Annotationsprozess fortsetzt, indem die Annotationen an die Datei angehängt werden, die die Konfiguration angibt, sofern nicht mit dem Flag --ignore-existing etwas anderes angegeben wird. Der Name der „.npy“-Datei, die für die Anmerkungen erstellt wird, kann auch manuell mithilfe des Flags --custom-annotator-string ausgewählt werden. Es ist möglich, mit --llm-size 7 und --llm-size 13 Anmerkungen zu erstellen, wenn eine einzelne GPU mit 32 GB Speicher verwendet wird. Sie können mit --llm-size 70 mit einem 8-GPU-Knoten Anmerkungen machen. Wir stellen hier grobe Schätzungen der Annotationszeiten mit NVIDIA V100s 32G-GPUs für einen Datensatz von 100.000 Paaren bereit, der in der Lage sein sollte, die meisten unserer Ergebnisse (die mit 500.000 Paaren erzielt werden) grob zu reproduzieren.
| Modell | Ressourcen zum Kommentieren |
|---|---|
| Lama 2 7b | ~32 GPU-Stunden |
| Lama 2 13b | ~40 GPU-Stunden |
| Lama 2 70b | ~72 GPU-Stunden |
In der zweiten Phase destillieren wir die Präferenzen des LLM durch Kreuzentropie in eine Belohnungsfunktion. Verwenden Sie den folgenden Befehl, um das Belohnungstraining mit Standard-Hyperparametern zu starten.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
Die Belohnungsfunktion wird durch die Anmerkungen des annotator trainiert, die sich in --dataset_dir befinden. Die resultierende Funktion wird dann im train_dir im Unterordner --experiment gespeichert.
Abschließend schulen wir einen Agenten mit den resultierenden Belohnungsfunktionen durch verstärkendes Lernen. Um einen Agenten für die NetHackScore-v1 -Aufgabe zu schulen, wobei die Standard-Hyperparameter für Experimente verwendet werden, die intrinsische und extrinsische Belohnungen kombinieren, können Sie den folgenden Befehl verwenden.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
Um die Aufgabe zu ändern, ändern Sie einfach das Argument --root_env . Die folgende Tabelle gibt explizit die Werte an, die erforderlich sind, um die in der Arbeit vorgestellten Experimente abzugleichen. Die NetHackScore-v1 Aufgabe wird mit einem extrinsic_reward -Wert von 0.1 erlernt, während alle anderen Aufgaben einen Wert von 10.0 annehmen, um dem Agenten einen Anreiz zu geben, das Ziel zu erreichen.
| Umfeld | root_env |
|---|---|
| Punktzahl | NetHackScore-v1 |
| Treppe | NetHackStaircase-v1 |
| Treppe (Ebene 3) | NetHackStaircaseLvl3-v1 |
| Treppe (Ebene 4) | NetHackStaircaseLvl4-v1 |
| Orakel | NetHackOracle-v1 |
| Orakel-nüchtern | NetHackOracleSober-v1 |
Wenn Sie Agenten außerdem nur mit der intrinsischen Belohnung aus dem LLM, aber ohne Belohnung aus der Umgebung schulen möchten, legen Sie einfach --extrinsic_reward 0.0 fest. Bei den intrinsischen Experimenten, bei denen es nur um Belohnung geht, beenden wir die Episode nur, wenn der Agent stirbt, und nicht, wenn der Agent das Ziel erreicht. Diese geänderten Umgebungen sind in der folgenden Tabelle aufgeführt.
| Umfeld | root_env |
|---|---|
| Treppe (Ebene 3) – nur intrinsisch | NetHackStaircaseLvl3Continual-v1 |
| Treppe (Ebene 4) – nur intrinsisch | NetHackStaircaseLvl4Continual-v1 |
Zusätzlich stellen wir ein Skript zur Visualisierung Ihrer geschulten RL-Agenten zur Verfügung. Dies kann wichtige Einblicke in sein Verhalten liefern, generiert aber auch die Top-Nachrichten für jede Episode, die dabei helfen können, zu verstehen, wofür optimiert werden soll. Sie müssen lediglich den folgenden Befehl ausführen.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
Wenn Sie auf unserer Arbeit aufbauen oder sie nützlich finden, zitieren Sie sie bitte im folgenden Bibtex.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
Der Großteil von Motif ist unter CC-BY-NC lizenziert, Teile des Projekts sind jedoch unter separaten Lizenzbedingungen verfügbar: Sample-Factory ist unter der MIT-Lizenz lizenziert.


