
Vereinheitlichen Sie Daten in Ihrem gesamten Machine-Learning-Lebenszyklus mit Space , einer umfassenden Speicherlösung, die Daten von der Aufnahme bis zum Training nahtlos verarbeitet.
Hauptmerkmale:
space.core.schema.types.files ).space.TfFeatures ist ein integrierter Feldtyp, der Serialisierer für verschachtelte Diktate von Numpy-Arrays bereitstellt, basierend auf TFDS FeaturesDict.Installieren:
pip install space-datasetsOder installieren Sie es über den Code:
cd python
pip install .[dev]Weitere Informationen finden Sie im Setup- und Leistungsdokument.
Erstellen Sie einen Space-Datensatz mit zwei Indexfeldern ( id , image_name ) (in Parquet speichern) und einem Datensatzfeld ( feature ) (in ArrayRecord speichern).
In diesem Beispiel wird der einfache binary für das Datensatzfeld verwendet. Space unterstützt einen Typ space.TfFeatures , der in den TFDS-Feature-Serializer integriert ist. Weitere Details finden Sie in einem TFDS-Beispiel.
import pyarrow as pa
from space import Dataset
schema = pa . schema ([
( "id" , pa . int64 ()),
( "image_name" , pa . string ()),
( "feature" , pa . binary ())])
ds = Dataset . create (
"/path/to/<mybucket>/example_ds" ,
schema ,
primary_keys = [ "id" ],
record_fields = [ "feature" ]) # Store this field in ArrayRecord files
# Load the dataset from files later:
ds = Dataset . load ( "/path/to/<mybucket>/example_ds" ) Optional können Sie catalogs verwenden, um Datensätze nach Namen statt nach Standorten zu verwalten:
from space import DirCatalog
# DirCatalog manages datasets in a directory.
catalog = DirCatalog ( "/path/to/<mybucket>" )
# Same as the creation above.
ds = catalog . create_dataset ( "example_ds" , schema ,
primary_keys = [ "id" ], record_fields = [ "feature" ])
# Same as the load above.
ds = catalog . dataset ( "example_ds" )
# List all datasets and materialized views.
print ( catalog . datasets ())Einige Daten anhängen oder löschen. Jede Mutation erzeugt eine neue Datenversion, dargestellt durch eine zunehmende Ganzzahl-ID. Benutzer können Tags als Alias zu Versions-IDs hinzufügen.
import pyarrow . compute as pc
from space import RayOptions
# Create a local runner:
runner = ds . local ()
# Or create a Ray runner:
runner = ds . ray ( ray_options = RayOptions ( max_parallelism = 8 ))
# To avoid https://github.com/ray-project/ray/issues/41333, wrap the runner
# with @ray.remote when running in a remote Ray cluster.
#
# @ray.remote
# def run():
# return runner.read_all()
#
# Appending data generates a new dataset version `snapshot_id=1`
# Write methods:
# - append(...): no primary key check.
# - insert(...): fail if primary key exists.
# - upsert(...): overwrite if primary key exists.
ids = range ( 100 )
runner . append ({
"id" : ids ,
"image_name" : [ f" { i } .jpg" for i in ids ],
"feature" : [ f"somedata { i } " . encode ( "utf-8" ) for i in ids ]
})
ds . add_tag ( "after_append" ) # Version management: add tag to snapshot
# Deletion generates a new version `snapshot_id=2`
runner . delete ( pc . field ( "id" ) == 1 )
ds . add_tag ( "after_delete" )
# Show all versions
ds . versions (). to_pandas ()
# >>>
# snapshot_id create_time tag_or_branch
# 0 2 2024-01-12 20:23:57+00:00 after_delete
# 1 1 2024-01-12 20:23:38+00:00 after_append
# 2 0 2024-01-12 20:22:51+00:00 None
# Read options:
# - filter_: optional, apply a filter (push down to reader).
# - fields: optional, field selection.
# - version: optional, snapshot_id or tag, time travel back to an old version.
# - batch_size: optional, output size.
runner . read_all (
filter_ = pc . field ( "image_name" ) == "2.jpg" ,
fields = [ "feature" ],
version = "after_add" # or snapshot ID `1`
)
# Read the changes between version 0 and 2.
for change in runner . diff ( 0 , "after_delete" ):
print ( change . change_type )
print ( change . data )
print ( "===============" )Erstellen Sie einen neuen Zweig und nehmen Sie Änderungen im neuen Zweig vor:
# The default branch is "main"
ds . add_branch ( "dev" )
ds . set_current_branch ( "dev" )
# Make changes in the new branch, the main branch is not updated.
# Switch back to the main branch.
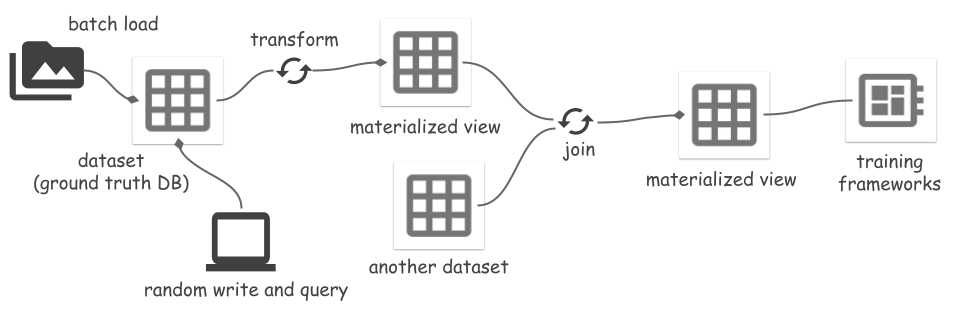
ds . set_current_branch ( "main" )Space unterstützt die Umwandlung eines Datensatzes in eine Ansicht und die Materialisierung der Ansicht in Dateien. Die Transformationen umfassen:
Wenn der Quelldatensatz geändert wird, werden die Änderungen durch die Aktualisierung der materialisierten Ansicht inkrementell synchronisiert, was Rechen- und E/A-Kosten spart. Weitere Details finden Sie in einem Segment Anything-Beispiel. Das Lesen oder Aktualisieren von Ansichten muss der Ray Runner sein, da sie auf Basis der Ray-Transformation implementiert werden.
Eine materialisierte Ansicht mv kann als Ansicht mv.view oder als Datensatz mv.dataset verwendet werden. Ersteres liest immer Daten aus den Dateien des Quelldatensatzes und verarbeitet alle Daten im laufenden Betrieb. Letzterer liest verarbeitete Daten direkt aus den Dateien des MV und überspringt die Verarbeitung von Daten.
# A sample transform UDF.
# Input is {"field_name": [values, ...], ...}
def modify_feature_udf ( batch ):
batch [ "feature" ] = [ d + b"123" for d in batch [ "feature" ]]
return batch
# Create a view and materialize it.
view = ds . map_batches (
fn = modify_feature_udf ,
output_schema = ds . schema ,
output_record_fields = [ "feature" ]
)
view_runner = view . ray ()
# Reading a view will read the source dataset and apply transforms on it.
# It processes all data using `modify_feature_udf` on the fly.
for d in view_runner . read ():
print ( d )
mv = view . materialize ( "/path/to/<mybucket>/example_mv" )
# Or use a catalog:
# mv = catalog.materialize("example_mv", view)
mv_runner = mv . ray ()
# Refresh the MV up to version tag `after_add` of the source.
mv_runner . refresh ( "after_add" , batch_size = 64 ) # Reading batch size
# Or, mv_runner.refresh() refresh to the latest version
# Use the MV runner instead of view runner to directly read from materialized
# view files, no data processing any more.
mv_runner . read_all ()Ein vollständiges Beispiel finden Sie im Beispiel „Segment Anything“. Das Erstellen einer materialisierten Ansicht des Join-Ergebnisses wird noch nicht unterstützt.
# If input is a materialized view, using `mv.dataset` instead of `mv.view`
# Only support 1 join key, it must be primary key of both left and right.
joined_view = mv_left . dataset . join ( mv_right . dataset , keys = [ "id" ])Es gibt mehrere Möglichkeiten, Space Storage in ML-Frameworks zu integrieren. Space bietet eine Datenquelle mit wahlfreiem Zugriff zum Lesen von Daten in ArrayRecord-Dateien:
from space import RandomAccessDataSource
datasource = RandomAccessDataSource (
# <field-name>: <storage-location>, for reading data from ArrayRecord files.
{
"feature" : "/path/to/<mybucket>/example_mv" ,
},
# Don't auto deserialize data, because we store them as plain bytes.
deserialize = False )
len ( datasource )
datasource [ 2 ]Ein Datensatz oder eine Ansicht kann auch als Ray-Datensatz gelesen werden:
ray_ds = ds . ray_dataset ()
ray_ds . take ( 2 )Daten in Parquet-Dateien können als HuggingFace-Datensatz gelesen werden:
from datasets import load_dataset
huggingface_ds = load_dataset ( "parquet" , data_files = { "train" : ds . index_files ()})Dateipfad aller Indexdateien (Parquet) auflisten:
ds . index_files ()
# Or show more statistics information of Parquet files.
ds . storage . index_manifest () # Accept filter and snapshot_idStatistikinformationen aller ArrayRecord-Dateien anzeigen:
ds . storage . record_manifest () # Accept filter and snapshot_id Space ist ein neues Projekt in aktiver Entwicklung.
? Laufende Aufgaben:
Dies ist kein offiziell unterstütztes Google-Produkt.


