

MPIRE , kurz für MultiProcessing Is Really Easy, ist ein Python-Paket für Multiprocessing. MPIRE ist in den meisten Szenarien schneller, bietet mehr Funktionen und ist im Allgemeinen benutzerfreundlicher als das Standard-Multiprocessing-Paket. Es kombiniert die praktischen, kartenähnlichen Funktionen von multiprocessing.Pool mit den Vorteilen der Verwendung gemeinsamer Copy-on-Write-Objekte von multiprocessing.Process , zusammen mit benutzerfreundlichem Worker-Status, Worker-Einblicken, Worker-Init- und Exit-Funktionen, Zeitüberschreitungen usw Fortschrittsbalkenfunktion.
Die vollständige Dokumentation finden Sie unter https://sybrenjansen.github.io/mpire/.
map / map_unordered “ / imap / imap_unordered “ / apply apply_async “.fork verfügbar)rich und Notebook-Widgets werden unterstützt)daemon Option sind verschachtelte Worker-Pools zulässigMPIRE wurde unter Linux, macOS und Windows getestet. Für Windows- und macOS-Benutzer gibt es einige kleinere bekannte Einschränkungen, die im Kapitel „Fehlerbehebung“ dokumentiert sind.
Durch Pip (PyPi):
pip install mpireMPIRE ist auch über conda-forge erhältlich:
conda install -c conda-forge mpire Angenommen, Sie haben eine zeitaufwändige Funktion, die Eingaben empfängt und ihre Ergebnisse zurückgibt. Einfache Funktionen wie diese werden als peinlich parallele Probleme bezeichnet, d. h. Funktionen, die nur mit geringem oder gar keinem Aufwand in eine parallele Aufgabe umgewandelt werden können. Das Parallelisieren einer einfachen Funktion kann so einfach sein wie das Importieren multiprocessing und die Verwendung der Klasse multiprocessing.Pool :
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE kann quasi als Ersatz für multiprocessing verwendet werden. Wir verwenden die Klasse mpire.WorkerPool und rufen eine der verfügbaren map Funktionen auf:
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) Die Unterschiede im Code sind gering: Es besteht keine Notwendigkeit, eine völlig neue Multiprocessing-Syntax zu erlernen, wenn Sie an Vanilla multiprocessing gewöhnt sind. Was MPIRE jedoch auszeichnet, ist die zusätzliche verfügbare Funktionalität.
Angenommen, wir möchten den Status der aktuellen Aufgabe wissen: Wie viele Aufgaben sind abgeschlossen, wie lange dauert es, bis die Arbeit fertig ist? Es ist so einfach, den Parameter progress_bar auf True zu setzen:
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Und es wird ein schön formatierter TQDM-Fortschrittsbalken ausgegeben.
MPIRE bietet auch ein Dashboard, für das Sie zusätzliche Abhängigkeiten installieren müssen. Weitere Informationen finden Sie unter Dashboard.
Hinweis: Gemeinsam genutzte Objekte beim Schreiben kopieren ist nur für die Startmethode fork verfügbar. Für threading werden die Objekte unverändert freigegeben. Bei anderen Startmethoden werden die gemeinsam genutzten Objekte einmal für jeden Worker kopiert, was immer noch besser sein kann als einmal pro Aufgabe.
Wenn Sie ein oder mehrere Objekte haben, die Sie für alle Worker freigeben möchten, können Sie die Option shared_objects zum Kopieren beim Schreiben von MPIRE verwenden. MPIRE wird diese Objekte nur einmal für jeden Worker ohne Kopieren/Serialisierung weitergeben. Erst wenn Sie das Objekt in der Worker-Funktion ändern, wird es für diesen Worker kopiert.
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Weitere Informationen finden Sie unter shared_objects.
Worker können mit der Funktion worker_init initialisiert werden. Zusammen mit worker_state können Sie ein Modell laden, eine Datenbankverbindung einrichten usw.:
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) Ebenso können Sie die Funktion worker_exit verwenden, damit MPIRE immer dann eine Funktion aufruft, wenn ein Worker beendet wird. Sie können diese Exit-Funktion sogar Ergebnisse zurückgeben lassen, die später abgerufen werden können. Weitere Informationen finden Sie im Abschnitt worker_init und worker_exit.
Wenn Ihr Multiprocessing-Setup nicht wie gewünscht funktioniert und Sie keine Ahnung haben, was die Ursache dafür ist, gibt es die Worker-Insights-Funktionalität. Dadurch erhalten Sie Einblick in Ihr Setup, es wird jedoch kein Profil der von Ihnen ausgeführten Funktion erstellt (dafür gibt es andere Bibliotheken). Stattdessen werden die Startzeit, die Wartezeit und die Arbeitszeit des Arbeiters profiliert. Wenn Worker-Init- und Exit-Funktionen bereitgestellt werden, werden diese ebenfalls zeitlich festgelegt.
Möglicherweise senden Sie viele Daten über die Aufgabenwarteschlange, wodurch sich die Wartezeit verlängert. In jedem Fall können Sie die Erkenntnisse mit dem Flag enable_insights bzw. der Funktion mpire.WorkerPool.get_insights aktivieren und abrufen:
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()Ein detaillierteres Beispiel und die erwartete Ausgabe finden Sie unter „Worker Insights“.
Zeitüberschreitungen können für die Funktionen target, worker_init und worker_exit separat festgelegt werden. Wenn ein Timeout festgelegt und erreicht wurde, wird ein TimeoutError ausgegeben:
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) Wenn threading als Startmethode verwendet wird, kann MPIRE bestimmte Funktionen wie time.sleep nicht unterbrechen.
Weitere Einzelheiten finden Sie unter Zeitüberschreitungen.
MPIRE wurde anhand von drei verschiedenen Benchmarks getestet: numerische Berechnung, zustandsbehaftete Berechnung und teure Initialisierung. Weitere Details zu diesen Benchmarks finden Sie in diesem Blogbeitrag. Der gesamte Code für diese Benchmarks ist in diesem Projekt zu finden.
Kurz gesagt, die Hauptgründe, warum MPIRE schneller ist, sind:
fork verfügbar ist, können wir gemeinsam genutzte Objekte beim Kopieren beim Schreiben verwenden, wodurch die Notwendigkeit verringert wird, Objekte zu kopieren, die über untergeordnete Prozesse gemeinsam genutzt werden müssenDie folgende Grafik zeigt die durchschnittlichen normalisierten Ergebnisse aller drei Benchmarks. Ergebnisse zu einzelnen Benchmarks finden Sie im Blogbeitrag. Die Benchmarks wurden auf einem Linux-Rechner mit 20 Kernen, deaktiviertem Hyperthreading und 200 GB RAM ausgeführt. Für jede Aufgabe wurden Experimente mit einer unterschiedlichen Anzahl von Prozessen/Workern durchgeführt und die Ergebnisse über 5 Durchläufe gemittelt.
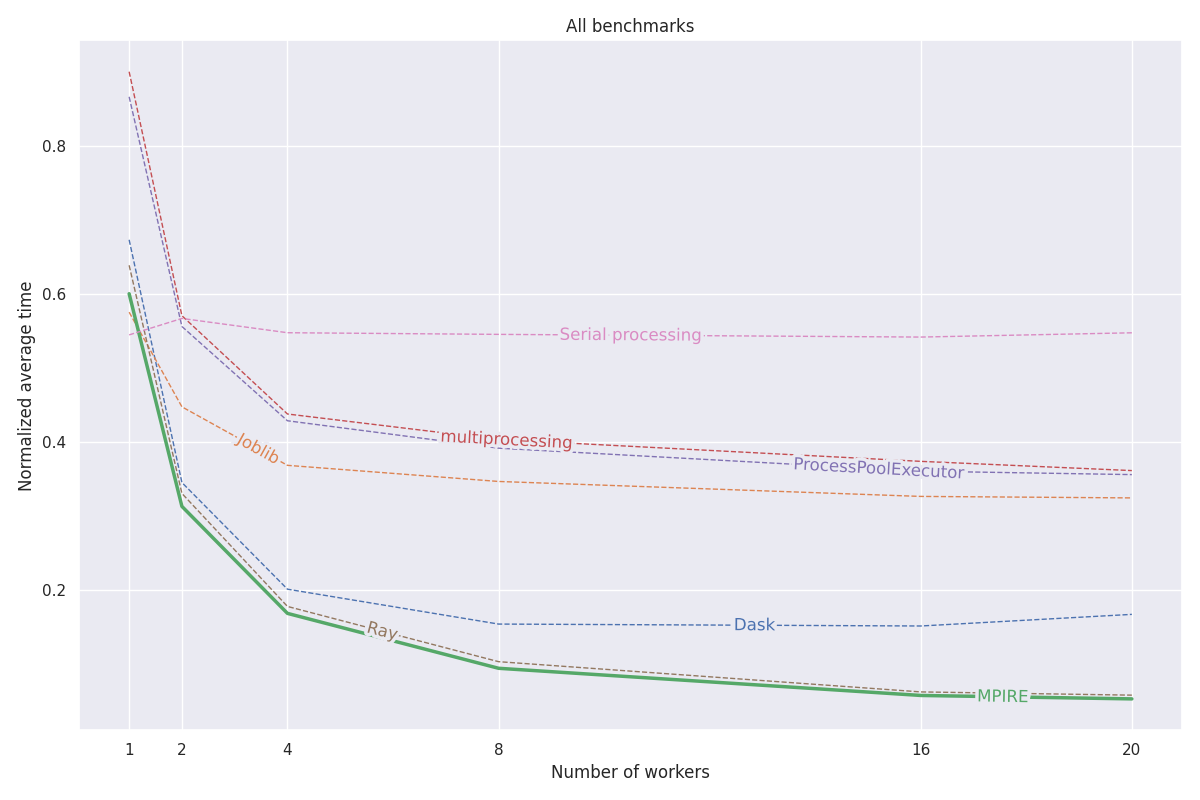
Informationen zu allen anderen Funktionen von MPIRE finden Sie in der vollständigen Dokumentation unter https://sybrenjansen.github.io/mpire/.
Wenn Sie die Dokumentation selbst erstellen möchten, installieren Sie bitte die Dokumentationsabhängigkeiten, indem Sie Folgendes ausführen:
pip install mpire[docs]oder
pip install .[docs]Die Dokumentation kann dann erstellt werden, indem Python <= 3.9 verwendet und Folgendes ausgeführt wird:
python setup.py build_docs Die Dokumentation kann auch direkt aus dem docs -Ordner erstellt werden. In diesem Fall sollte MPIRE in Ihrer aktuellen Arbeitsumgebung installiert und verfügbar sein. Führen Sie dann Folgendes aus:
make html im docs Ordner.


