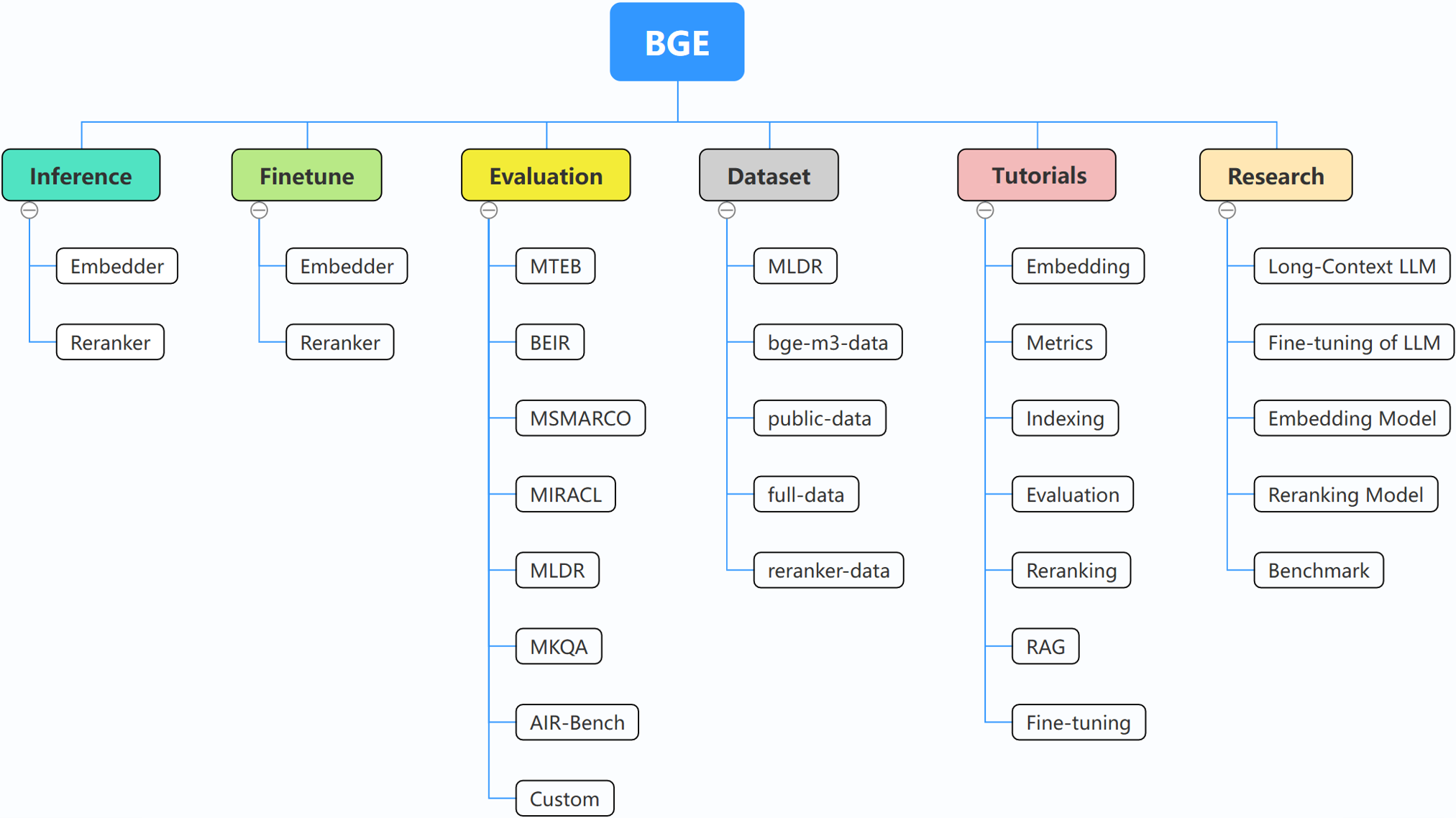
FlagEmbedding
1.3.2


Nachrichten | Installation | Schnellstart | Gemeinschaft | Projekte | Modellliste | Mitwirkender | Zitat | Lizenz
Englisch | 中文
BGE (BAAI General Embedding) konzentriert sich auf abrufgestützte LLMs und besteht derzeit aus folgenden Projekten:
29.10.2024: ? Wir haben eine WeChat-Gruppe für BGE erstellt. Scannen Sie den QR-Code, um dem Gruppenchat beizutreten! Um aus erster Hand über unsere Updates und Neuerscheinungen informiert zu werden oder Fragen oder Ideen zu haben, melden Sie sich jetzt bei uns an!

22.10.2024: Wir veröffentlichen ein weiteres interessantes Modell: OmniGen, ein einheitliches Bildgenerierungsmodell, das verschiedene Aufgaben unterstützt. OmniGen kann komplexe Bildgenerierungsaufgaben erledigen, ohne dass zusätzliche Plugins wie ControlNet, IP-Adapter oder Hilfsmodelle wie Posenerkennung und Gesichtserkennung erforderlich sind.
10.09.2024: Einführung von MemoRAG , ein Schritt vorwärts in Richtung RAG 2.0 zusätzlich zur speicherinspirierten Wissensentdeckung (Repo: https://github.com/qhjqhj00/MemoRAG, Papier: https://arxiv.org/pdf/ 2409.05591v1)
02.09.2024: Beginnen Sie mit der Pflege der Tutorials. Die darin enthaltenen Inhalte werden aktiv aktualisiert und erweitert, bleiben Sie dran!
26.07.2024: Veröffentlichung eines neuen Einbettungsmodells bge-en-icl, eines Einbettungsmodells mit kontextbezogenen Lernfunktionen, das durch die Bereitstellung aufgabenrelevanter Abfrage-Antwort-Beispiele semantisch umfangreichere Abfragen kodieren und so die Semantik weiter verbessern kann Darstellungsfähigkeit der Einbettungen.
26.07.2024: Veröffentlichung eines neuen Einbettungsmodells bge-multilingual-gemma2, eines mehrsprachigen Einbettungsmodells basierend auf gemma-2-9b, das mehrere Sprachen und verschiedene nachgelagerte Aufgaben unterstützt und neue SOTA für mehrsprachige Benchmarks erreicht (MIRACL, MTEB-fr , und MTEB-pl).
26.07.2024: Veröffentlichung eines neuen Lightweight-Rerankers bge-reranker-v2.5-gemma2-lightweight, eines Lightweight-Rerankers auf Basis von Gemma-2-9b, der Token-Komprimierung und schichtweise Lightweight-Operationen unterstützt und dennoch eine gute Leistung beim Speichern gewährleisten kann eine erhebliche Menge an Ressourcen.
BAAI/bge-reranker-base und BAAI/bge-reranker-large , die leistungsfähiger sind als das Einbettungsmodell. Wir empfehlen, sie zu verwenden/zu optimieren, um Top-K-Dokumente, die durch Einbettungsmodelle zurückgegeben werden, neu einzuordnen.bge-*-v1.5 um das Problem der Ähnlichkeitsverteilung zu lösen und seine Abruffähigkeit ohne Anweisung zu verbessern.bge-large-* Modellen (kurz für BAAI General Embedding), Platz 1 im MTEB- und C-MTEB-Benchmark! ? ?Wenn Sie die Modelle nicht verfeinern möchten, können Sie das Paket ohne die Finetune-Abhängigkeit installieren:
pip install -U FlagEmbedding
Wenn Sie die Modelle verfeinern möchten, können Sie das Paket mit der Finetune-Abhängigkeit installieren:
pip install -U FlagEmbedding[finetune]
Klonen Sie das Repository und installieren Sie es
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install .[finetune]
Für die Entwicklung im bearbeitbaren Modus:
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install -e .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install -e .[finetune]
Laden Sie zunächst eines der BGE-Einbettungsmodelle:
from FlagEmbedding import FlagAutoModel
model = FlagAutoModel.from_finetuned('BAAI/bge-base-en-v1.5',
query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",
use_fp16=True)
Geben Sie dann einige Sätze in das Modell ein und erhalten Sie deren Einbettungen:
sentences_1 = ["I love NLP", "I love machine learning"]
sentences_2 = ["I love BGE", "I love text retrieval"]
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
Sobald wir die Einbettungen erhalten haben, können wir die Ähnlichkeit anhand des inneren Produkts berechnen:
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
Weitere Einzelheiten finden Sie unter Embedder-Inferenz, Reranker-Inferenz, Embedder-Feinabstimmung, Reranker-Fintune und Auswertung.
Wenn Sie mit verwandten Konzepten nicht vertraut sind, schauen Sie sich bitte das Tutorial an. Wenn es nicht da ist, lassen Sie es uns wissen.
Weitere interessante Themen rund um BGE finden Sie unter Forschung.
Wir pflegen aktiv die Community von BGE und FlagEmbedding. Teilen Sie uns mit, wenn Sie Vorschläge oder Ideen haben!
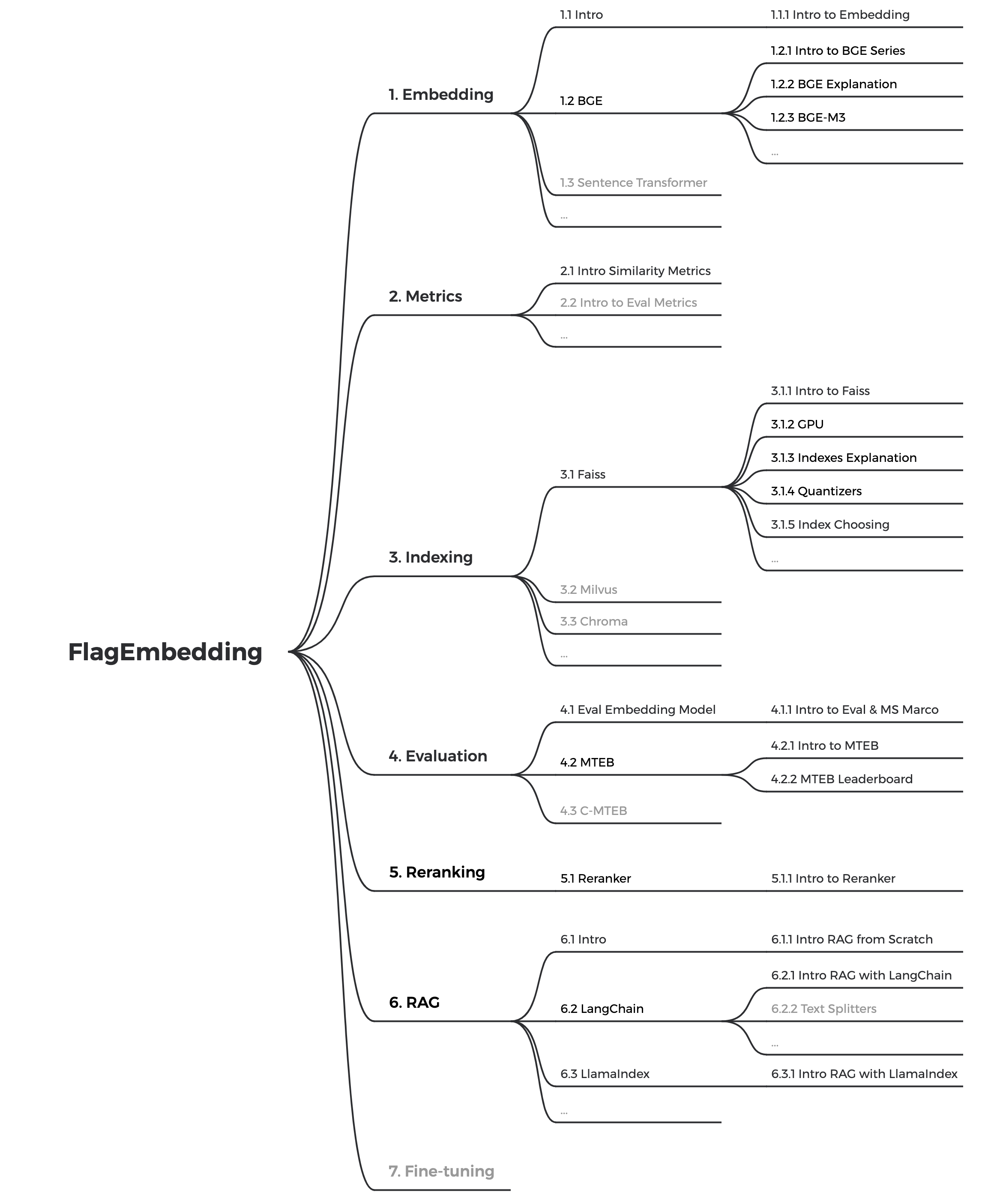
Derzeit aktualisieren wir die Tutorials. Unser Ziel ist es, ein umfassendes und detailliertes Tutorial für Anfänger zum Thema Textrecherche und RAG zu erstellen. Bleiben Sie dran!
Die folgenden Inhalte werden in den kommenden Wochen veröffentlicht:
bge ist die Abkürzung für BAAI general embedding .
| Modell | Sprache | Beschreibung | Abfrageanweisung zum Abrufen |
|---|---|---|---|
| BAAI/bge-en-icl | Englisch | Ein LLM-basiertes Einbettungsmodell mit kontextbezogenen Lernfunktionen, das anhand einiger Beispielbeispiele das Potenzial des Modells voll ausschöpfen kann | Stellen Sie basierend auf der gegebenen Aufgabe frei Anweisungen und Beispiele für wenige Aufnahmen bereit. |
| BAAI/bge-multilingual-gemma2 | Mehrsprachig | Ein LLM-basiertes mehrsprachiges Einbettungsmodell, trainiert für eine Vielzahl von Sprachen und Aufgaben. | Geben Sie Anweisungen basierend auf der gegebenen Aufgabe. |
| BAAI/bge-m3 | Mehrsprachig | Multifunktionalität (dichter Abruf, spärlicher Abruf, Multi-Vektor (Colbert)), Mehrsprachigkeit und Multi-Granularität (8192 Token) | |
| LM-Cocktail | Englisch | Fein abgestimmte Modelle (Llama und BGE), mit denen die Ergebnisse von LM-Cocktail reproduziert werden können | |
| BAAI/llm-embedder | Englisch | ein einheitliches Einbettungsmodell zur Unterstützung verschiedener Abruferweiterungsanforderungen für LLMs | Siehe README |
| BAAI/bge-reranker-v2-m3 | Mehrsprachig | ein leichtes Cross-Encoder-Modell, verfügt über starke mehrsprachige Fähigkeiten, ist einfach bereitzustellen und bietet schnelle Inferenz. | |
| BAAI/bge-reranker-v2-gemma | Mehrsprachig | Ein Cross-Encoder-Modell, das für mehrsprachige Kontexte geeignet ist und sowohl bei Englischkenntnissen als auch bei Mehrsprachigkeit gute Ergebnisse erzielt. | |
| BAAI/bge-reranker-v2-minicpm-layerwise | Mehrsprachig | Ein Cross-Encoder-Modell, das für mehrsprachige Kontexte geeignet ist, sowohl bei Englisch- als auch bei Chinesischkenntnissen gute Leistungen erbringt, die Freiheit bei der Auswahl von Ebenen für die Ausgabe ermöglicht und so eine beschleunigte Inferenz ermöglicht. | |
| BAAI/bge-reranker-v2.5-gemma2-lightweight | Mehrsprachig | Ein Cross-Encoder-Modell, das für mehrsprachige Kontexte geeignet ist, sowohl bei Englisch- als auch bei Chinesischkenntnissen gute Leistungen erbringt, die Freiheit bei der Auswahl von Ebenen, dem Komprimierungsverhältnis und der Komprimierung von Ebenen für die Ausgabe ermöglicht und so eine beschleunigte Inferenz ermöglicht. | |
| BAAI/bge-reranker-large | Chinesisch und Englisch | ein Cross-Encoder-Modell, das genauer, aber weniger effizient ist | |
| BAAI/bge-reranker-base | Chinesisch und Englisch | ein Cross-Encoder-Modell, das genauer, aber weniger effizient ist | |
| BAAI/bge-large-en-v1.5 | Englisch | Version 1.5 mit vernünftigerer Ähnlichkeitsverteilung | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | Englisch | Version 1.5 mit vernünftigerer Ähnlichkeitsverteilung | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en-v1.5 | Englisch | Version 1.5 mit vernünftigerer Ähnlichkeitsverteilung | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh-v1.5 | chinesisch | Version 1.5 mit vernünftigerer Ähnlichkeitsverteilung | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | chinesisch | Version 1.5 mit vernünftigerer Ähnlichkeitsverteilung | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | chinesisch | Version 1.5 mit vernünftigerer Ähnlichkeitsverteilung | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | Englisch | Einbettungsmodell, das Text in einen Vektor umwandelt | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | Englisch | ein Modell im Basismaßstab, aber mit ähnlicher Fähigkeit wie bge-large-en | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | Englisch | ein kleines Modell, aber mit konkurrenzfähiger Leistung | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh | chinesisch | Einbettungsmodell, das Text in einen Vektor umwandelt | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | chinesisch | ein Basismodell, aber mit ähnlichen Fähigkeiten wie bge-large-zh | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh | chinesisch | ein kleines Modell, aber mit konkurrenzfähiger Leistung | 为这个句子生成表示以用于检索相关文章: |
Wir danken allen Mitwirkenden für ihren Einsatz und heißen neue Mitglieder herzlich willkommen!
Wenn Sie dieses Repository nützlich finden, denken Sie bitte darüber nach, einen Stern zu vergeben und zu zitieren
@misc{bge_m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cocktail,
title={LM-Cocktail: Resilient Tuning of Language Models via Model Merging},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Xingrun Xing},
year={2023},
eprint={2311.13534},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{llm_embedder,
title={Retrieve Anything To Augment Large Language Models},
author={Peitian Zhang and Shitao Xiao and Zheng Liu and Zhicheng Dou and Jian-Yun Nie},
year={2023},
eprint={2310.07554},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
FlagEmbedding ist unter der MIT-Lizenz lizenziert.


