Metro-Managementsystem
SUSTech 2024 Frühlingsprojekte des Kurses CS307 - Principles of Database System unter der Leitung von Yuxin MA
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
Im ersten Teil des Projekts geht es hauptsächlich um den Entwurf eines Datenbankschemas, das die Prinzipien relationaler Datenbanken auf der Grundlage der bereitgestellten Daten erfüllt. Sobald die Entwurfsphase abgeschlossen ist, haben wir Skripte geschrieben, um diese großen Datensätze zu importieren. Um die Richtigkeit der importierten Daten sicherzustellen, mussten wir einige Abfrageanweisungen ausführen und die Abfrageergebnisse am Tag der Verteidigung überprüfen. Darüber hinaus haben wir auch einige Experimente mit den Daten durchgeführt, um wunderbare Erkenntnisse zu gewinnen, wie später gezeigt wird.
[Lesen Sie die detaillierten Anforderungen]
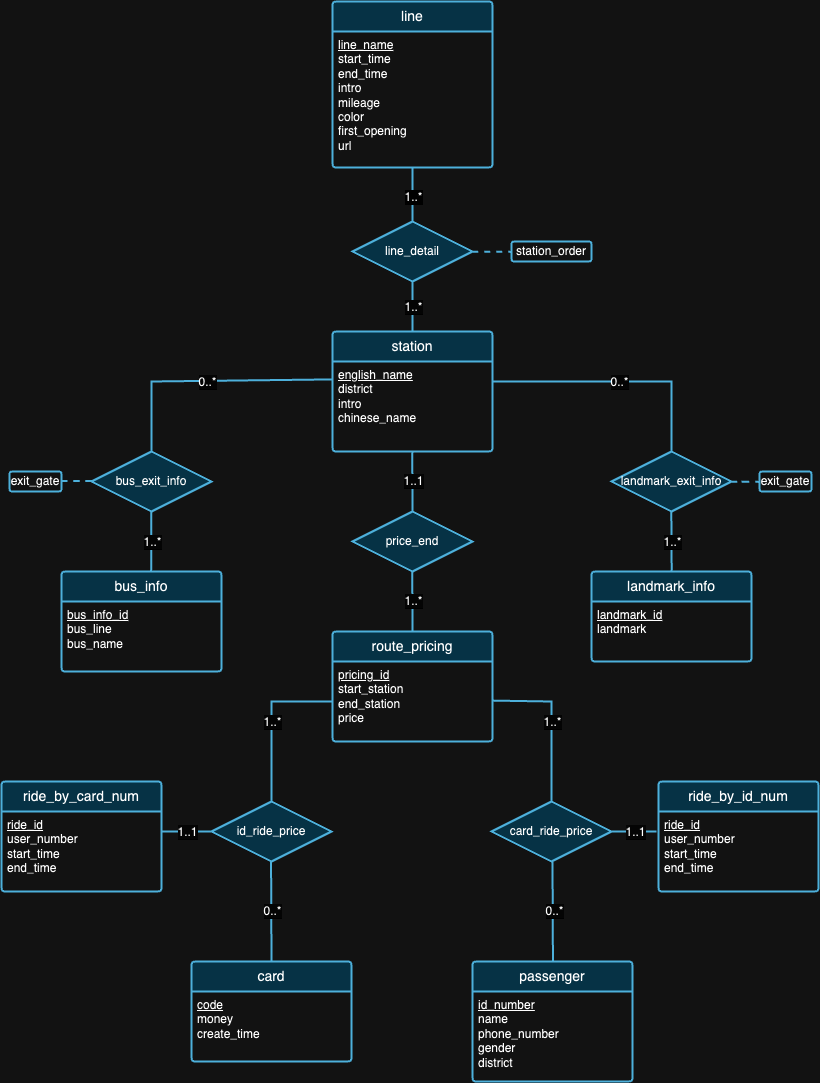
Wir glauben, dass kein Datenbankdesign perfekt ist. Tatsächlich weist das von uns im obigen ER-Diagramm vorgeschlagene Design Mängel auf. Nachdem Sie sich die Datensätze und den Hintergrund jedes Datensatzes angesehen haben, hoffen wir, dass Sie versuchen können, Designfehler selbst zu erkennen! :) :)
Hinweis : Zur Interpretation der Abbildungen
| AUSWEIS | Betriebssystem | Chip | Erinnerung | SSD | Werkzeuge |
|---|---|---|---|---|---|
| 1 | macOS Sonoma 14.4.1 | Apple M3 Pro | 18 GB | 1 TB | IDEA 2024.1 (CE), PyCharm 2023.3.4 (CE), Datagrip 2024.1 |
| 2 | Windows 11 Home 23H2 | Intel(R) Core(TM) i9-12900H der 12. Generation | 32 GB | 1 TB | IDEA 2024.1 (CE), Datagrip 2024.1 |
| 3 | Ubuntu 22.04.4 (VM) | Apple M1 Pro | 16 GB | 512 GB | IDEA 2024.1 (CE), Datagrip 2024.1 |
Experiment 1: Different Import Methods Methode 1 (Originalskript): Diese Methode nutzt die java.sql -Bibliothek. Zunächst haben wir eine Verbindung zu unserem PostgreSQL-Server hergestellt. Dann lesen wir alle Daten aus JSON-Dateien. Als nächstes haben wir jedes Datum durchlaufen und PreparedStatement für jede Einfügeanweisung erstellt. Zuletzt haben wir die executeUpdate() aufgerufen, um jede Anweisung einzeln auszuführen.
Methode 2 (optimiertes Skript): Diese Methode nutzt ebenfalls die java.sql -Bibliothek und verwendet denselben Datenlesealgorithmus wie Methode 1. Der Unterschied besteht darin, dass wir jetzt die executeBatch() verwenden. Also haben wir die gesamten Daten durchlaufen, jede Einfügeanweisung mit PreparedStatement erstellt und jede PreparedStatement zu einem Stapel für eine Stapelausführung hinzugefügt.
Methode 3 (Ausführen einer .sql-Datei): Wir haben ein Java-Programm verwendet, um SQL-Einfügeanweisungen zu generieren und sie in eine .sql -Datei geschrieben, indem wir denselben oben erwähnten Datenlesealgorithmus verwendet haben. Dann führen wir die Datei in DataGrip aus.
Da wir für alle drei Methoden denselben Datenlesealgorithmus verwenden, verwenden wir für unsere nachfolgenden Tests eine durchschnittliche Laufzeit. Wir haben zunächst drei verschiedene Laufzeiten erfasst – 504 ms, 546 ms und 552 ms – und eine durchschnittliche Laufzeit von 534 ms berechnet.
| Testumgebung | Verfahren | Durchschnittliche Lesezeit (ms) | Schreibzeit (ms) | Gesamtzeit (ms) | Durchsatz (Anweisungen/s) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636,91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
Tabelle 2 zeigt unterschiedliche Leistungsmetriken für verschiedene Methoden, wobei Methode 2 den höchsten Durchsatz und Methode 1 die langsamste Gesamtzeit aufweist. Damit wird Methode 2 zur Standardtestmethode in den kommenden Experimenten.
Experiment 2: Data Import with Different Data VolumesDas Verwalten und Importieren unterschiedlich großer Datenmengen ist ein entscheidender Aspekt für die Gewährleistung der Leistung, Skalierbarkeit und Zuverlässigkeit eines Datenbanksystems.
Vor dem Importvorgang stellten wir fest, dass das Volumen der „Fahrt“-Daten im Vergleich zu den anderen deutlich größer war. Basierend auf dieser Idee haben wir beschlossen, den Datenimport mit unterschiedlichen Volumina nur auf der ride.json zu testen. Da die Datenmenge nicht konsistent ist, kann das Importieren einer geringeren Menge für die anderen Tabellen aufgrund der Konnektivität zwischen den Tabellen zu einem ernsthaften Problem führen.
Zunächst haben wir damit begonnen, die vollständigen Daten (100 % Volumen) für alle anderen Tabellen außer den Tabellen rides_by_id_num und rides_by_card_num zu importieren, um die Konsistenz unseres Designs sicherzustellen. Um dies effektiv zu verwalten, haben wir eine stufenweise Importstrategie für die ride eingeführt, beginnend mit einer 20-prozentigen Teilmenge der Daten, was 20.000 Datensätzen entspricht. In dieser ersten Phase konnten wir die Auswirkungen auf die Systemleistung beurteilen und notwendige Anpassungen am Importprozess vornehmen, ohne die Stabilität der Datenbank zu beeinträchtigen. Nach erfolgreicher Validierung und Leistungsoptimierung fuhren wir mit dem Import von 50 % der Daten fort und schließlich mit dem verbleibenden Teil, um den 100 %-Datenimport abzuschließen. Beachten Sie, dass wir für alle Importe Methode 2 verwendet haben, da diese die schnellste ist.
| Testumgebung | Verfahren | Volumen | Lesezeit (ms) | Schreibzeit (ms) | Gesamtzeit (ms) | Anweisungsanzahl | Durchsatz (Anweisungen/s) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20 % | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50 % | 521 | 1338 | 1859 | 130849 | 97794.47 |
| 1 | 2 | 100 % | 534 | 2114 | 2648 | 203502 | 96263,95 |
Aus Tabelle 3 geht hervor, dass mit zunehmender Datenmenge (von 20 % auf 50 % und auf 100 %) tendenziell sowohl die Lese- als auch die Schreibzeit zunehmen, was zu längeren Gesamtzeiten für die Vorgänge führt. Allerdings geben diese Zahlen keine aufschlussreiche Aussagekraft, da wir unterschiedliche Importmengen hatten. Wenn wir stattdessen die Anzahl der Durchsätze betrachten, nimmt der Durchsatz (Anweisungen/s) mit zunehmendem Datenvolumen allmählich ab, was darauf hindeutet, dass das System mit zunehmender Arbeitslast weniger effizient bei der Verarbeitung von Anweisungen wird.
Experiment 3: Data Import on Different Operating SystemsBeim Testen des Prozesses zum Importieren von Daten auf verschiedenen Betriebssystemen verwendeten wir die schnellste Importmethode, nämlich Methode 2, mit 100 % Importvolumen.
Beachten Sie, dass beim Ausführen des Java-Importskripts unter Linux über eine virtuelle Maschine unbedingt der unfaire Nachteil bei der Leistung und Ressourcenzuweisung berücksichtigt werden muss, da die Virtualisierung zu Mehraufwand führen und die Effizienz des Systems beeinträchtigen kann.
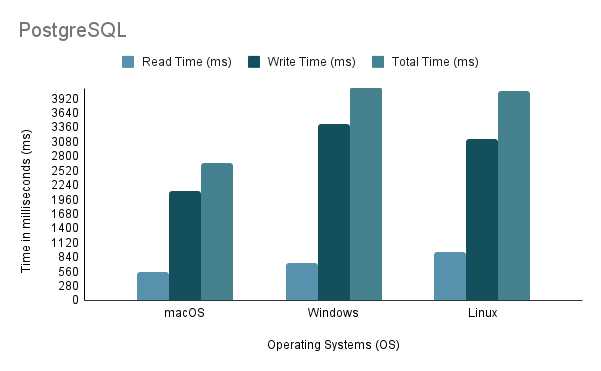
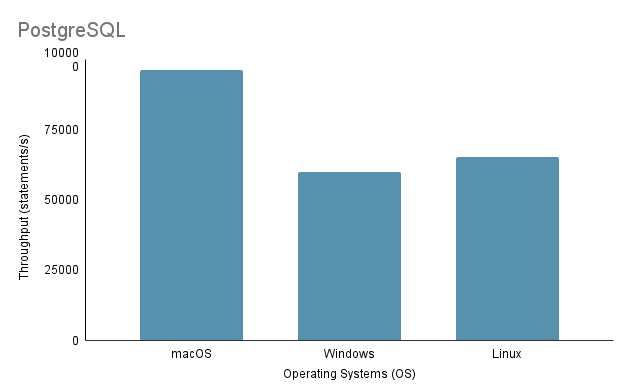
Basierend auf der obigen Analyse ist klar, dass Umgebung 1 (macOS) die beste Leistung mit der kürzesten Gesamtzeit von 2648 ms und dem höchsten Durchsatz von 97.632,92 Anweisungen/s aufweist. Im Gegensatz dazu ist Umgebung 2 (Windows) mit einer Gesamtzeit von 4117 ms und dem niedrigsten Durchsatz von 60.669,02 Anweisungen/s am langsamsten. Es ist erwähnenswert, dass Linux Ubuntu, obwohl es als VM ausgeführt wurde, immer noch besser war als Bare-Metal-Windows.
Experiment 4: Data Import with Various Programming LanguagesIn diesem Experiment haben wir die oben erwähnte Methode 2 für Java-Code verwendet, da sie die schnellste ist. In der Zwischenzeit haben wir für Python eine Importmethode geschrieben, die Psycopg2 für die Kommunikation mit dem PostgreSQL-Datenbankserver nutzt.
| Testumgebung | Programmiersprache | Lesezeit (ms) | Schreibzeit (ms) | Gesamtzeit (ms) | Durchsatz (Anweisungen/s) |
|---|---|---|---|---|---|
| 1 | Java | 534 | 2114 | 2648 | 96263,95 |
| 1 | Python | 390 | 7237 | 7627 | 28119.66 |
Die Daten aus Tabelle 4 zeigen, dass Java Python sowohl bei der Geschwindigkeit als auch beim Durchsatz übertraf, was auf seine überlegene Effizienz bei Lese-/Schreibvorgängen hinweist.
Experiment 5: Data Import on Different DatabasesWir haben drei verschiedene Importmethoden für PostgreSQL und MySQL entwickelt, aber wir haben nur ein Experiment mit Methode 2 durchgeführt, da diese für den Datenimport die Wahl des Entwicklers ist. Sowohl PostgreSQL als auch MySQL haben ein ähnliches Datenbankimplementierungsdesign (in Bezug auf DDL) und ein ähnliches Importcode-Design.
| Testumgebung | Verfahren | Datenbank | Lesezeit (ms) | Schreibzeit (ms) | Gesamtzeit (ms) | Durchsatz (Anweisungen/s) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 534 | 2114 | 2648 | 96263,95 |
| 1 | 2 | MySQL | 534 | 42315 | 42849 | 4809.22 |
Obwohl es sich bei beiden um SQL-basierte Datenbanken handelt, ist PostgreSQL in Bezug auf die Schreibzeit etwa 16-mal schneller. Dies kann auf Unterschiede in der Datenbank-Engine-Architektur und der Treiberimplementierung zurückzuführen sein ( postgresql-42.2.5.jar für PostgreSQL und mysql-connector-j-8.3.0.jar für MySQL).
Teil 2 des Projekts konzentriert sich auf die Bereitstellung der Grundfunktionen für den Zugriff auf das Datenbanksystem durch den Aufbau einer Backend-Bibliothek, die eine Reihe von Anwendungsprogrammierschnittstellen (APIs) bereitstellt. Beachten Sie, dass auch ein zusätzlicher Datensatz importiert werden muss und daher eine aktualisierte Datenbankimplementierung erforderlich ist (zu finden in ./Project2/DataImport ).
[Lesen Sie die detaillierten Anforderungen]
./Project2/DataImport/src/main/sql/ddl.sql bereitgestellt wird./Project2/DataImport/src/main/java/ImportScript.java bereitgestellten Skript./Project2/ShenzhenMetro ) mit Maven (IntelliJ IDEA IDE wird empfohlen)

