chrono_lens
v1.1.1
Dies ist das öffentliche Repository des Traffic Cameras-Analyseprojekts, wie es im Office for National Statistics Data Science Campus Blog als Teil der ONS Coronavirus Faster Indicators (z. B. Traffic Camera Activity – 10. September 2020) und der zugrunde liegenden Methodik veröffentlicht wurde. Das Projekt nutzte Google Compute Platform (GCP), um eine skalierbare Lösung zu ermöglichen, aber die zugrunde liegende Methodik ist plattformunabhängig; Dieses Repository enthält unsere GCP-orientierte Implementierung.
Nachfolgend wird eine Beispielausgabe für den Coronavirus Faster Indicator dargestellt.
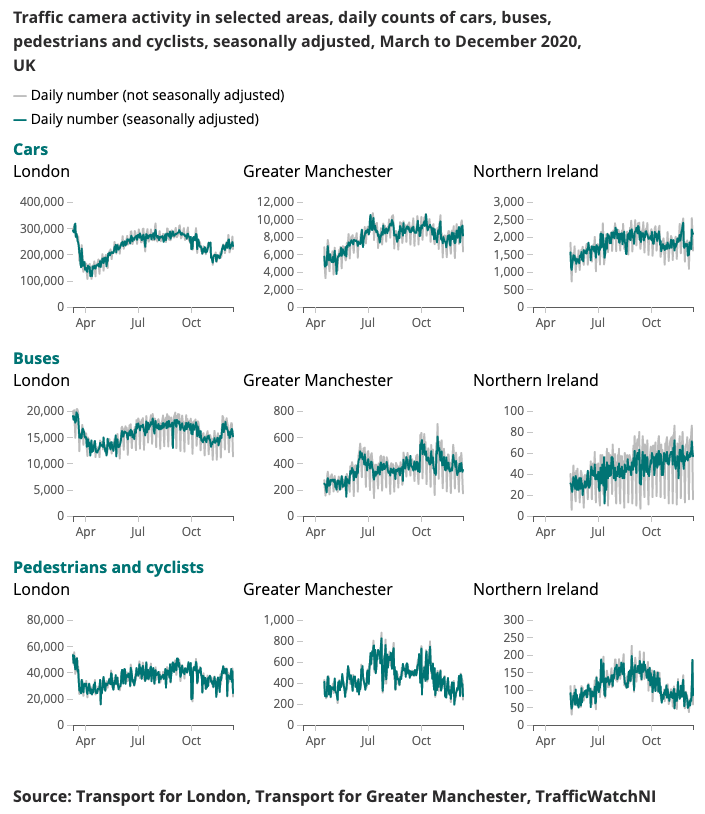
Das Verständnis veränderter Mobilitäts- und Verhaltensmuster in Echtzeit war ein Hauptschwerpunkt der staatlichen Reaktion auf das Coronavirus (COVID-19). Der Data Science Campus hat alternative Datenquellen untersucht, die Erkenntnisse darüber liefern könnten, wie das Ausmaß der sozialen Distanzierung abgeschätzt und der Aufschwung der Gesellschaft und der Wirtschaft verfolgt werden kann, wenn die Lockdown-Bedingungen gelockert werden.
Verkehrskameras sind eine weit verbreitete und öffentlich zugängliche Datenquelle, die es Verkehrsfachleuten und der Öffentlichkeit ermöglicht, den Verkehrsfluss in verschiedenen Teilen des Landes über das Internet zu beurteilen. Die von Verkehrskameras erzeugten Bilder sind öffentlich zugänglich, haben eine geringe Auflösung und ermöglichen keine individuelle Identifizierung von Personen oder Fahrzeugen. Sie unterscheiden sich von CCTV, die für die öffentliche Sicherheit und Strafverfolgung zur automatischen Nummernschilderkennung (ANPR) oder zur Überwachung der Verkehrsgeschwindigkeit eingesetzt werden.
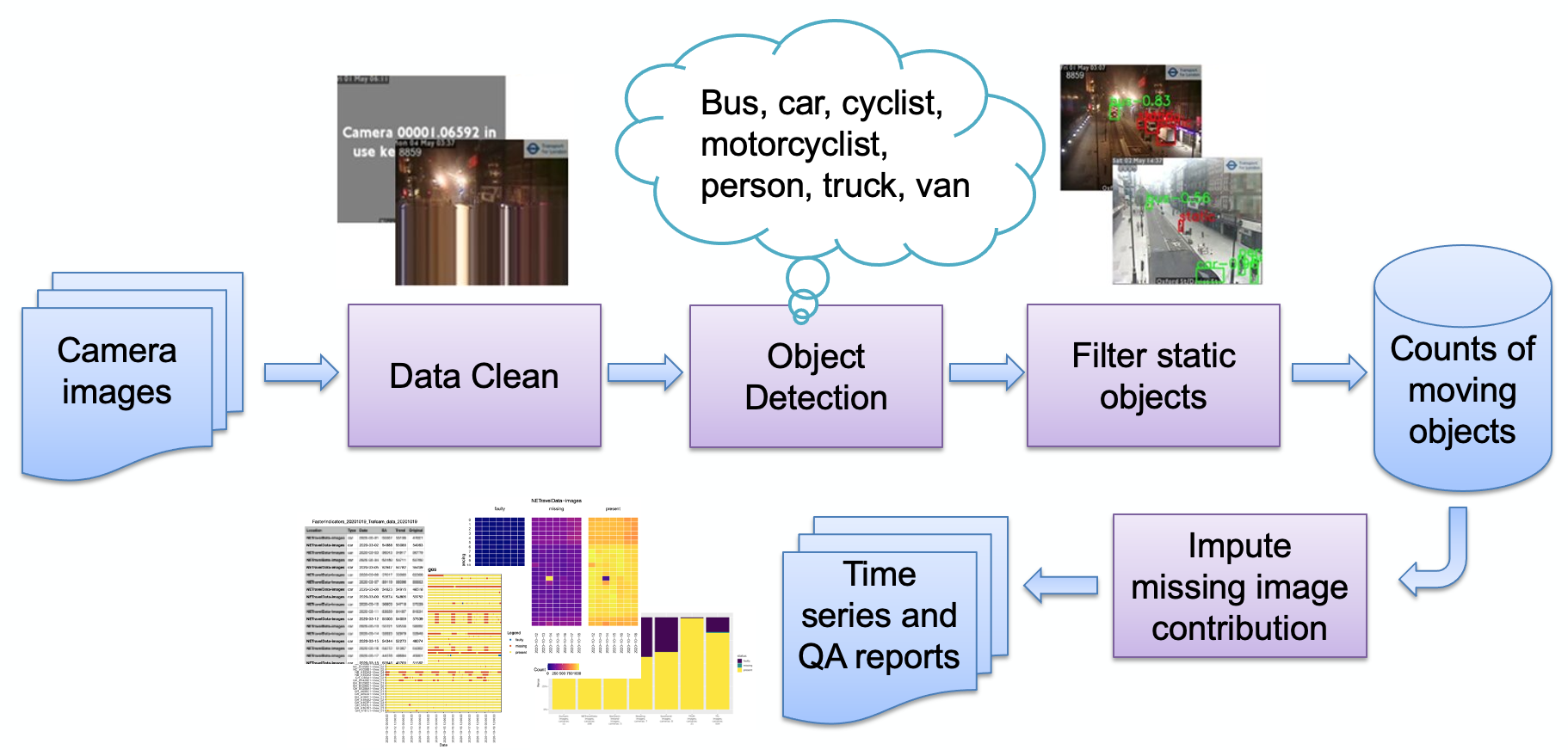
Die Hauptphasen der Pipeline, wie im Bild dargestellt, sind:
Bildaufnahme
Fehlerhafte Bilderkennung
Objekterkennung
Erkennung statischer Objekte
Speicherung der resultierenden Zählungen
Die Zählungen können dann weiterverarbeitet (Saisonbereinigung, Fehlwertimputation) und bei Bedarf in Berichte umgewandelt werden. Wir werden kurz auf die Hauptphasen der Pipeline eingehen.
Eine Reihe von Kameraquellen (im Internet gehostete JPEG-Bilder) wird vom Benutzer ausgewählt und dem Benutzer als Liste von URLs bereitgestellt. Es wird Beispielcode bereitgestellt, um öffentliche Bilder von Transport for London zu erhalten, und Spezialcode, um NE-Verkehrsdaten direkt vom Urban Observatory der Newcastle University abzurufen.
Kameras können aus verschiedenen Gründen nicht verfügbar sein (Systemfehler, Feed durch lokalen Bediener deaktiviert usw.) und diese könnten dazu führen, dass das Modell falsche Objektzählungen generiert (z. B. könnte ein kleiner Fleck wie ein entfernter Bus aussehen). Ein Beispiel für ein solches Bild ist: 
Diese Bilder folgten bisher alle dem Muster eines sehr synthetischen Bildes, bestehend aus einer flachen Hintergrundfarbe und überlagertem Text (im Vergleich zu einem Bild einer natürlichen Szene). Diese Bilder werden derzeit erkannt, indem die Farbtiefe verringert wird (ähnliche Farben zusammengefügt werden) und dann der höchste Anteil des Bildes betrachtet wird, der von einer einzelnen Farbe eingenommen wird. Sobald dieser einen Schwellenwert überschreitet, stellen wir fest, dass das Bild synthetisch ist und kennzeichnen es als fehlerhaft. Durch die Kodierung können weitere Fehler auftreten, wie zum Beispiel: 
Hier ist der Camrera-Feed ins Stocken geraten und die letzte „Live“-Reihe wurde wiederholt; Wir erkennen dies, indem wir prüfen, ob die untere Bildreihe mit der darüber liegenden Reihe übereinstimmt (innerhalb des Schwellenwerts). Wenn ja, wird die nächste Zeile darüber auf Übereinstimmung überprüft und so weiter, bis die Zeilen nicht mehr übereinstimmen oder uns die Zeilen ausgehen. Wenn die Anzahl übereinstimmender Zeilen über einem Schwellenwert liegt, ist es unwahrscheinlich, dass das Bild nützliche Daten generiert, und es wird daher als fehlerhaft gekennzeichnet.
Beachten Sie, dass verschiedene Bildanbieter unterschiedliche Methoden verwenden, um anzuzeigen, dass eine Kamera nicht verfügbar ist. Unsere Erkennungstechnik basiert auf der Verwendung weniger Farben, also einem rein synthetischen Bild. Wenn ein natürlicheres Bild verwendet wird, funktioniert unsere Technik möglicherweise nicht. Eine Alternative besteht darin, eine „Bibliothek“ fehlerhafter Bilder zu führen und nach Ähnlichkeiten zu suchen, was bei natürlicheren Bildern möglicherweise besser funktioniert.
Der Objekterkennungsprozess identifiziert sowohl statische als auch sich bewegende Objekte mithilfe eines vorab trainierten Faster-RCNN, das vom Urban Observatory der Newcastle University bereitgestellt wird. Das Modell wurde anhand von 10.000 Verkehrskamerabildern aus Nordostengland trainiert und vom ONS Data Science Campus weiter validiert, um zu bestätigen, dass das Modell mit Kamerabildern aus anderen Gebieten des Vereinigten Königreichs verwendbar ist. Es erkennt folgende Objekttypen: Auto, Transporter, LKW, Bus, Fußgänger, Radfahrer, Motorradfahrer.
Da wir darauf abzielen, Aktivitäten zu erkennen, ist es wichtig, statische Objekte mithilfe zeitlicher Informationen herauszufiltern. Die Bilder werden in 10-Minuten-Intervallen abgetastet, daher sind herkömmliche Methoden zur Hintergrunderkennung in Videos, wie etwa die Gauß-Mischung, nicht geeignet.
Alle während der Objekterkennung klassifizierten Fußgänger und Fahrzeuge werden als statisch gesetzt und aus der Endzählung entfernt, wenn sie auch im Hintergrund erscheinen. Das folgende Bild zeigt Beispielergebnisse der statischen Maske, bei der die geparkten Autos in Bild (a) als statisch identifiziert und entfernt werden. Ein zusätzlicher Vorteil besteht darin, dass die statische Maske dazu beitragen kann, Fehlalarme zu beseitigen. Beispielsweise wird in Bild (b) der Mülleimer bei der Objekterkennung fälschlicherweise als Fußgänger identifiziert, aber als statischer Hintergrund herausgefiltert.

Die Ergebnisse werden einfach als Tabelle gespeichert, wobei das Schema Kamera-ID, Datum, Uhrzeit und zugehörige Zählungen pro Objekttyp (Auto, Transporter, Fußgänger usw.) aufzeichnet, wenn ein Bild fehlerhaft ist oder wenn ein Bild fehlt.
Ursprünglich war das System cloudnativ konzipiert, um Skalierbarkeit zu ermöglichen; Allerdings stellt dies eine Eintrittsbarriere dar – Sie müssen ein Konto bei einem Cloud-Anbieter haben, wissen, wie man die Infrastruktur sichert usw. Vor diesem Hintergrund haben wir den Code auch zurückportiert, damit er auf einem eigenständigen Computer funktioniert (oder „lokaler Host“), um es einem interessierten Benutzer zu ermöglichen, das System einfach auf seinem eigenen Laptop auszuführen. Beide Implementierungen werden nun im Folgenden beschrieben.
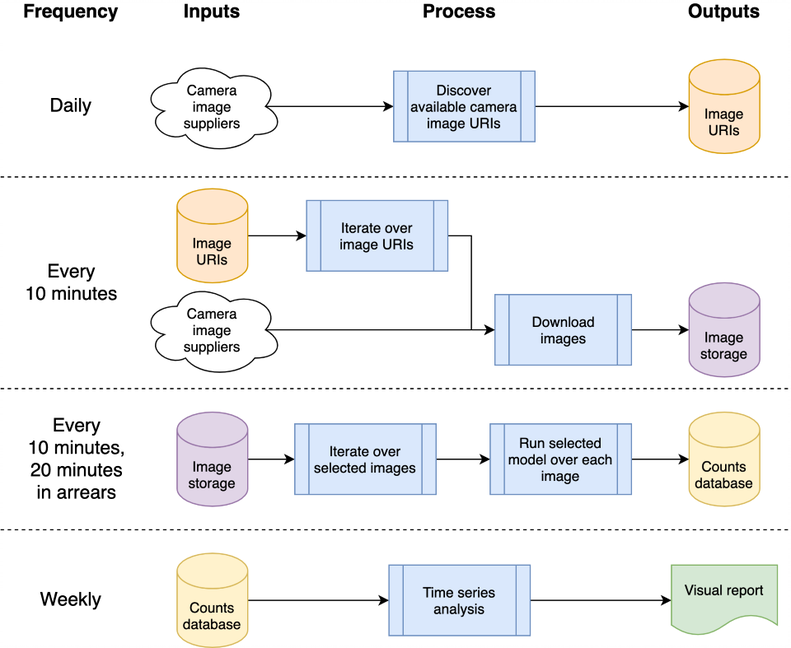
Diese Architektur kann einer einzelnen Maschine oder einem Cloud-System zugeordnet werden; Wir haben uns für die Verwendung der Google Compute Platform (GCP) entschieden, andere Plattformen wie Amazon Web Services (AWS) oder Microsoft Azure würden jedoch relativ gleichwertige Dienste bereitstellen.
Das System wird als „Cloud-Funktionen“ gehostet, bei denen es sich um eigenständigen, zustandslosen Code handelt, der wiederholt aufgerufen werden kann, ohne dass es zu Beschädigungen kommt – ein wichtiger Gesichtspunkt zur Erhöhung der Robustheit der Funktionen. Die täglichen und „alle 10 Minuten“-Verarbeitungsstöße werden mithilfe des GCP-Schedulers orchestriert, um ein GCP-Pub/Sub-Thema gemäß dem gewünschten Zeitplan auszulösen. GCP-Cloud-Funktionen werden für das Thema registriert und gestartet, sobald das Thema ausgelöst wird.
Die Verarbeitung der Bilder zur Erkennung von Fahrzeugen und Fußgängern führt dazu, dass die Anzahl der Objekte zur späteren Analyse als Zeitreihe in eine Datenbank geschrieben wird. Die Datenbank wird verwendet, um Daten zwischen der Datenerfassung und der Zeitreihenanalyse auszutauschen und so die Kopplung zu reduzieren. Wir verwenden BigQuery innerhalb der GCP als unsere Datenbank, da es in anderen GCP-Produkten breite Unterstützung bietet, wie z. B. Data Studio für die Datenvisualisierung; Die lokale Host-Implementierung speichert tägliche CSVs zum Vergleich, um jegliche Abhängigkeit von einer bestimmten Datenbank oder einer anderen Infrastruktur zu beseitigen.
Der GCP-bezogene Quellcode wird im cloud -Ordner gespeichert; Dadurch werden die Bilder heruntergeladen, zur Zählung von Objekten verarbeitet, die Zählungen in einer Datenbank gespeichert und (wöchentlich) eine Zeitreihenanalyse erstellt. Die gesamte Dokumentation und der Quellcode werden im cloud -Ordner gespeichert. Einen Überblick über die Architektur und die Installation Ihrer eigenen Instanz mithilfe unserer Skripts in Ihrem GCP-Projektbereich finden Sie in der Cloud README.md. Das Projekt kann in GitHub integriert werden, was eine automatische Bereitstellung und Testausführung von Commits zu einem lokalen GitHub-Projekt ermöglicht; Dies ist auch in der Cloud README.md dokumentiert. Der Cloud-Unterstützungscode wird auch im Modul chrono_lens.gcloud gespeichert, sodass Befehlszeilenskripte neben dem Cloud-Funktionscode im cloud -Ordner GCP unterstützen können.
Eigenständiger Einzelmaschinencode („localhost“) ist im Modul chrono_lens.localhost enthalten. Der Prozess folgt demselben Ablauf wie die GCP-Variante, verwendet jedoch eine einzelne Maschine und jede Python-Datei in chrono_lens.localhost ist den Cloud-Funktionen von GCP zugeordnet. Weitere Einzelheiten finden Sie in README-localhost.md.
Wir beschreiben nun die verschiedenen Schritte und Voraussetzungen zur Installation des Systems, da sowohl GCP- als auch lokale Hos-Implementierungen mindestens eine lokale Installation erfordern.
Die Schaffung einer virtuellen Umgebung wird dringend empfohlen, um eine isolierte Arbeitsumgebung zu ermöglichen. Beispiele für gute Arbeitsumgebungen sind Conda, Pyenv und Poerty.
Beachten Sie, dass Abhängigkeiten bereits in requirements.txt enthalten sind. Installieren Sie dies daher bitte über pip:
pip install -r requirements.txt
Um zu verhindern, dass Passwörter versehentlich festgeschrieben werden, werden Pre-Commit-Hooks empfohlen, die verhindern, dass Git-Commits verarbeitet werden, bevor vertrauliche Informationen im Repository gelandet sind. Wir haben die Pre-Commit-Hooks von https://github.com/ukgovdatascience/govcookiecutter verwendet
Durch die Installation von „requirements.txt“ wird das Pre-Commit-Tool installiert, das nun mit git verbunden werden muss:
pre-commit install
...die dann die Konfiguration aus .pre-commit-config.yaml abruft.
HINWEIS: Die maximale KB-Größe des Pre-Commit-Tests check-added-large-files in .pre-commit-config.yaml wird vorübergehend auf 60 MB erhöht, wenn die RCNN-Modelldatei /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb hinzugefügt wird . Das Limit wird dann auf 5 MB als sinnvolle „normale“ Obergrenze zurückgesetzt.
Es wird empfohlen, alle Dateien zu durchsuchen, bevor Sie fortfahren, um sicherzustellen, dass nichts versehentlich bereits vorhanden ist:
pre-commit run --all-files
Dadurch werden alle vorhandenen Probleme gemeldet – nützlich, da der Hook ansonsten nur für bearbeitete Dateien ausgeführt wird.
Das Projekt ist hauptsächlich für die Nutzung über die Cloud-Infrastruktur konzipiert, es gibt jedoch Hilfsskripte für den lokalen Zugriff und Aktualisierungen der Zeitreihen in der Cloud. Diese Skripte befinden sich im Ordner scripts/gcloud . Jedes Skript wird nun in den folgenden separaten Abschnitten beschrieben. Weitere Informationen finden Sie in scripts/gcloud/README.md und ihre Verwendung durch eine optionale virtuelle Maschine wird in cloud/README.md beschrieben.
Die Verwendung außerhalb der Cloud wird durch die Skripte im Ordner scripts/localhost unterstützt. Einzelheiten zur Verwendung des chrono_lens Systems auf einem eigenständigen Computer werden in README-localhost.md beschrieben. Weitere Informationen zur Verwendung der Skripte finden Sie in scripts/localhost/README.md .
Beachten Sie, dass Skripte Code im Ordner chrono_lens verwenden.
| Version | Datum | Notizen |
|---|---|---|
| 1.0.0 | 08.06.2021 | Erste Veröffentlichung des öffentlichen Repositorys |
| 1.0.1 | 21.09.2021 | Fehlerbehebung für isolierte Bilder, Tensorflow-Versionsfehler |
| 1.1.0 | ? | Eingeschränkte Unterstützung für eigenständige Einzelmaschinen hinzugefügt |
Hier werden Bereiche potenzieller zukünftiger Arbeiten vorgestellt. Diese Änderungen werden möglicherweise nicht untersucht, dienen jedoch dazu, die Menschen auf mögliche Verbesserungen aufmerksam zu machen, die wir in Betracht gezogen haben.
Derzeit werden Bash-Shell-Skripte zum Erstellen der GCP-Infrastruktur verwendet. Eine Verbesserung wäre die Verwendung von IaC wie Terraform. Dies vereinfacht das Ändern von (z. B.) Cloud-Funktionskonfigurationen, ohne dass der Cloud Build Trigger manuell entfernt und neu erstellt werden muss, wenn die Laufzeitumgebung oder Speichergrenzen geändert werden.
Das aktuelle Design basiert auf dem anfänglichen Anwendungsfall, Bilder zu erfassen, bevor die Modelle fertiggestellt wurden. Daher werden alle verfügbaren Bilder heruntergeladen und nicht nur diejenigen, die analysiert werden. Um Aufnahmekosten zu sparen, sollte der Aufnahmecode mit den Analyse-JSON-Dateien abgeglichen werden und nur diese Dateien herunterladen. Es sollte eine Warnung ausgelöst werden, wenn eine dieser Quellen nicht mehr verfügbar ist oder wenn neue Quellen verfügbar werden.
Das nächtliche Auffüllen von Bildern für NETravelData scheint etwa 40 % der NETravelData-Bilder zu aktualisieren; Der Vorteil einer regelmäßigen Aktualisierung verringert sich, wenn die Zahlen nur täglich benötigt werden. Aus diesem Grund kann die Cloud-Funktion distribute_ne_travel_data entfernt werden.
http async hin zu PubSub Der ursprüngliche Entwurf verwendet beim Testen neuer Modelle manuell ausgeführte Skripte – nämlich „ batch_process_images.py “. Hier werden der Erfolg (oder Misserfolg) und die Anzahl der verarbeiteten Bilder angezeigt. Hierfür eignet sich eine Cloud-Funktion gut, da sie ein Ergebnis zurückgibt. Eine effizientere Architektur bestünde jedoch darin, intern eine PubSub-Warteschlange zu verwenden, wobei die Funktionen distribute_json_sources und processed_scheduled Arbeit zu PubSub-Warteschlangen hinzufügen, die von einer einzelnen Worker-Funktion genutzt werden, und nicht die aktuelle Hierarchie asynchroner Aufrufe (wobei zwei zusätzliche Funktionen zur Skalierung verwendet werden). ).
Das Urban Observatory der Universität Newcastle hat das vorab trainierte Faster-RCNNN bereitgestellt, das wir verwenden (eine lokale Kopie wird in /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb gespeichert).
Die Daten werden vom North East Urban Traffic Management and Control Open Data Service bereitgestellt, der unter der Open Government License 3.0 lizenziert ist. Die Bilder werden Tyne and Wear Urban Traffic Management and Control zugeschrieben.
Die Nordostdaten werden vom Urban Observatory der Newcastle University weiterverarbeitet und gehostet, für dessen Unterstützung und Beratung wir dankbar danken.
Die Daten werden von TfL bereitgestellt und von TfL Open Data bereitgestellt. Die Daten sind unter Version 2.0 der Open Government Licence lizenziert. TfL-Daten enthalten Betriebssystemdaten © Crown Urheberrecht und Datenbankrechte 2016 und Geomni UK Kartendaten © und Datenbankrechte (2019).
In diesem Projekt werden verschiedene Bibliotheken von Drittanbietern verwendet. Diese sind auf der Seite „Abhängigkeiten“ aufgeführt, deren Beiträge wir dankbar anerkennen.


