Candle ist ein minimalistisches ML-Framework für Rust mit Fokus auf Leistung (einschließlich GPU-Unterstützung) und Benutzerfreundlichkeit. Probieren Sie unsere Online-Demos aus: Whisper, LLaMA2, T5, Yolo, Segment Anything.
Stellen Sie sicher, dass Sie candle-core korrekt installiert haben, wie in Installation beschrieben.
Sehen wir uns an, wie man eine einfache Matrixmultiplikation durchführt. Schreiben Sie Folgendes in Ihre Datei myapp/src/main.rs :
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run sollte einen Tensor der Form Tensor[[2, 4], f32] anzeigen.
Nachdem Sie candle mit Cuda-Unterstützung installiert haben, definieren Sie einfach das device als GPU:
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;Weitere Beispiele für Fortgeschrittene finden Sie im folgenden Abschnitt.
Diese Online-Demos laufen vollständig in Ihrem Browser:
Wir bieten auch einige befehlszeilenbasierte Beispiele mit modernsten Modellen:
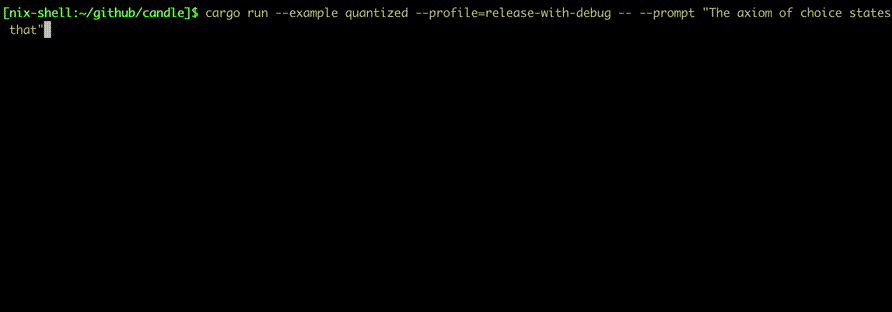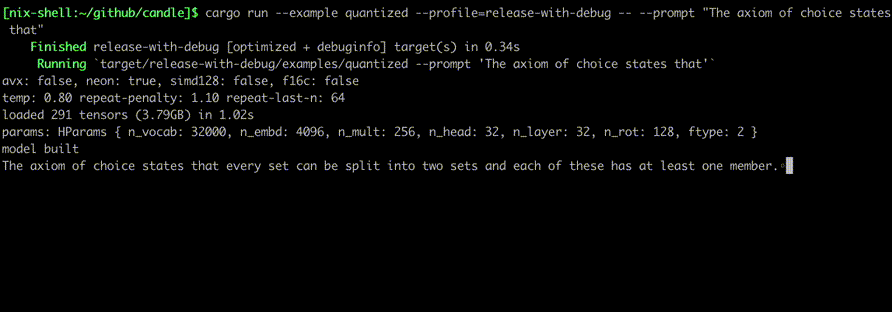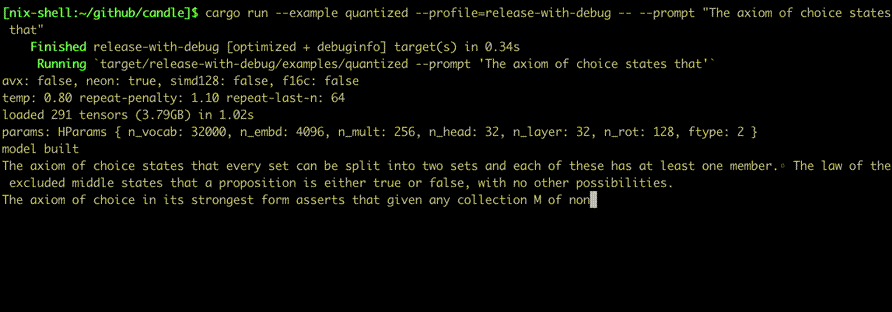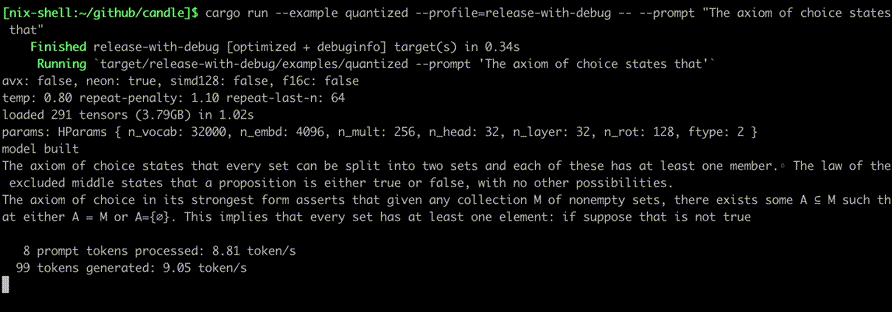





Führen Sie sie mit Befehlen aus wie:
cargo run --example quantized --release
Um CUDA zu verwenden, fügen Sie --features cuda zur Beispielbefehlszeile hinzu. Wenn Sie cuDNN installiert haben, verwenden Sie --features cudnn für noch mehr Beschleunigung.
Es gibt auch einige Wasm-Beispiele für whisper und llama2.c. Sie können sie entweder mit trunk erstellen oder online ausprobieren: whisper, llama2, T5, Phi-1.5 und Phi-2, Segment Anything Model.
Führen Sie für LLaMA2 den folgenden Befehl aus, um die Gewichtsdateien abzurufen und einen Testserver zu starten:
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081Gehen Sie dann zu http://localhost:8081/.
candle-tutorial : Ein sehr detailliertes Tutorial, das zeigt, wie man ein PyTorch-Modell in Candle konvertiert.candle-lora : Effiziente und ergonomische LoRA-Implementierung für Candle. candle-lora hatoptimisers : Eine Sammlung von Optimierern, einschließlich SGD mit Momentum, AdaGrad, AdaDelta, AdaMax, NAdam, RAdam und RMSprop.candle-vllm : Effiziente Plattform für Inferenz und Bereitstellung lokaler LLMs, einschließlich eines OpenAI-kompatiblen API-Servers.candle-ext : Eine Erweiterungsbibliothek für Candle, die PyTorch-Funktionen bereitstellt, die derzeit in Candle nicht verfügbar sind.candle-coursera-ml : Implementierung von ML-Algorithmen aus Courseras Spezialisierungskurs für maschinelles Lernen.kalosm : Ein multimodales Meta-Framework in Rust für die Verbindung mit lokalen vorab trainierten Modellen mit Unterstützung für kontrollierte Generierung, benutzerdefinierte Sampler, In-Memory-Vektordatenbanken, Audiotranskription und mehr.candle-sampling : Sampling-Techniken für Candle.gpt-from-scratch-rs : Eine Portierung von Andrej Karpathys Let's build GPT- Tutorial auf YouTube, das die Candle-API an einem Spielzeugproblem vorstellt.candle-einops : Eine reine Rust-Implementierung der Python-Einops-Bibliothek.atoma-infer : Eine Rust-Bibliothek für schnelle Inferenz im großen Maßstab, die FlashAttention2 für eine effiziente Aufmerksamkeitsberechnung, PagedAttention für eine effiziente KV-Cache-Speicherverwaltung und Multi-GPU-Unterstützung nutzt. Es ist OpenAI-API-kompatibel.Wenn Sie eine Ergänzung zu dieser Liste haben, senden Sie bitte eine Pull-Anfrage.
Spickzettel:
| Verwendung von PyTorch | Kerze verwenden | |
|---|---|---|
| Schaffung | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| Schaffung | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| Indizierung | tensor[:, :4] | tensor.i((.., ..4))? |
| Operationen | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| Operationen | a.matmul(b) | a.matmul(&b)? |
| Arithmetik | a + b | &a + &b |
| Gerät | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| Dtyp | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| Sparen | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| Laden | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
TensorDas Hauptziel von Candle besteht darin, serverlose Schlussfolgerungen zu ermöglichen . Vollständige Frameworks für maschinelles Lernen wie PyTorch sind sehr groß, was die Erstellung von Instanzen auf einem Cluster langsam macht. Candle ermöglicht die Bereitstellung leichter Binärdateien.
Zweitens können Sie mit Candle Python aus Produktions-Workloads entfernen . Der Python-Overhead kann die Leistung ernsthaft beeinträchtigen, und die GIL ist eine notorische Quelle von Kopfschmerzen.
Endlich ist Rust cool! Ein großer Teil des HF-Ökosystems verfügt bereits über Rust-Kisten wie Safetensoren und Tokenizer.
dfdx ist eine beeindruckende Kiste, in der Formen in Typen enthalten sind. Dies vermeidet viele Kopfschmerzen, da der Compiler sich sofort über Formunterschiede beschwert. Wir haben jedoch festgestellt, dass einige Funktionen immer noch eine nächtliche Arbeit erfordern und das Schreiben von Code für Nicht-Rost-Experten etwas entmutigend sein kann.
Wir nutzen zur Laufzeit andere Kern-Crates und tragen dazu bei, sodass hoffentlich beide Crates voneinander profitieren können.
burn ist eine allgemeine Kiste, die mehrere Backends nutzen kann, sodass Sie die beste Engine für Ihre Arbeitslast auswählen können.
tch-rs Bindungen zur Torch-Bibliothek in Rust. Äußerst vielseitig, aber sie integrieren die gesamte Brennerbibliothek in die Laufzeit. Der Hauptbeitragszahler von tch-rs ist auch an der Entwicklung von candle beteiligt.
Wenn beim Kompilieren von Binärdateien/Tests mit den mkl- oder Beschleunigungsfunktionen einige fehlende Symbole auftreten, z. B. für mkl, erhalten Sie Folgendes:
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
oder zum Beschleunigen:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
Dies liegt wahrscheinlich an einem fehlenden Linker-Flag, das zum Aktivieren der mkl-Bibliothek erforderlich war. Sie können versuchen, Folgendes für mkl oben in Ihrer Binärdatei hinzuzufügen:
extern crate intel_mkl_src ;oder zum Beschleunigen:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
Dies liegt wahrscheinlich daran, dass Sie keine Berechtigung für das LLaMA-v2-Modell haben. Um dies zu beheben, müssen Sie sich auf dem Huggingface-Hub registrieren, die LLaMA-v2-Modellbedingungen akzeptieren und Ihr Authentifizierungstoken einrichten. Weitere Einzelheiten finden Sie in Ausgabe Nr. 350.
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
Cutlass wird als Git-Submodul bereitgestellt, daher können Sie den folgenden Befehl ausführen, um es ordnungsgemäß einzuchecken.
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
Dies ist ein Fehler in gcc-11, der durch den Cuda-Compiler ausgelöst wird. Um dies zu beheben, installieren Sie eine andere, unterstützte gcc-Version, zum Beispiel gcc-10, und geben Sie den Pfad zum Compiler in der Umgebungsvariablen NVCC_CCBIN an.
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
Stellen Sie sicher, dass Sie alle nativen Bibliotheken verknüpfen, die sich möglicherweise außerhalb eines Projektziels befinden. Um beispielsweise MDBook-Tests auszuführen, sollten Sie Folgendes ausführen:
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
Dies kann daran liegen, dass die Modelle von /mnt/c geladen werden. Weitere Informationen zum Stackoverflow.
Sie können RUST_BACKTRACE=1 festlegen, um Backtraces zu erhalten, wenn ein Kerzenfehler generiert wird.
Wenn ein Fehler wie dieser called Result::unwrap() on an Err value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } unter Windows. Um das Problem zu beheben, kopieren Sie diese 3 Dateien und benennen Sie sie um (stellen Sie sicher, dass sie sich im Pfad befinden). Die Pfade hängen von Ihrer Cuda-Version ab. c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


