LARS
v2.0-beta8:

LARS ist eine Anwendung, mit der Sie LLMs (Large Language Models) lokal auf Ihrem Gerät ausführen, Ihre eigenen Dokumente hochladen und an Gesprächen teilnehmen können, bei denen das LLM seine Antworten auf Ihre hochgeladenen Inhalte stützt. Diese Erdung trägt dazu bei, die Genauigkeit zu erhöhen und das häufige Problem von durch KI verursachten Ungenauigkeiten oder „Halluzinationen“ zu reduzieren. Diese Technik ist allgemein als „Retrieval Augmented Generation“ oder RAG bekannt.
Es gibt viele Desktop-Anwendungen zum lokalen Ausführen von LLMs, und LARS zielt darauf ab, die ultimative Open-Source-RAG-zentrierte LLM-Anwendung zu sein. Zu diesem Zweck führt LARS das RAG-Konzept noch weiter aus, indem es jeder Antwort detaillierte Zitate hinzufügt, Sie mit spezifischen Dokumentnamen, Seitenzahlen, Texthervorhebungen und Bildern versorgt, die für Ihre Frage relevant sind, und sogar einen Dokumentenleser direkt in der Antwort bereitstellt Antwortfenster. Obwohl nicht immer alle Zitate für jede Antwort vorhanden sind, besteht die Idee darin, dass für jede RAG-Antwort zumindest eine Kombination von Zitaten angezeigt wird, und das ist im Allgemeinen der Fall.
LARS-Feature-Demonstrationsvideo
Python v3.10.x oder höher: https://www.python.org/downloads/
PyTorch:
Wenn Sie planen, Ihre GPU zum Ausführen von LLMs zu verwenden, stellen Sie sicher, dass Sie die GPU-Treiber und CUDA/ROCm-Toolkits entsprechend Ihrem Setup installieren und erst dann mit der PyTorch-Einrichtung unten fortfahren
Laden Sie die für Ihr System geeignete PyTorch-Version herunter und installieren Sie sie: https://pytorch.org/get-started/locally/
Klonen Sie das Repository:
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensInstallieren Sie Python-Abhängigkeiten:
Windows über PIP:
pip install -r .requirements.txt
Linux über PIP:
pip3 install -r ./requirements.txt
Hinweis zu Azure: Einige benötigte Azure-Bibliotheken sind NICHT auf der MacOS-Plattform verfügbar! Für MacOS ist daher eine separate Anforderungsdatei mit Ausnahme dieser Bibliotheken enthalten:
MacOS:
pip3 install -r ./requirements_mac.txt
Zurück zum Inhaltsverzeichnis
Führen Sie LARS nach der Installation aus mit:
cd web_app
python app.py # Use 'python3' on Linux/macOS
Navigieren Sie in Ihrem Browser zu http://localhost:5000/
Alle von LARS benötigten Anwendungsverzeichnisse werden nun auf der Festplatte erstellt
Der HF-Waitress-Server startet automatisch und lädt beim ersten Start ein LLM (Microsoft Phi-3-Mini-Instruct-44) herunter, was je nach Geschwindigkeit Ihrer Internetverbindung eine Weile dauern kann
Bei der ersten Abfrage wird ein Einbettungsmodell (all-mpnet-base-v2) vom HuggingFace Hub heruntergeladen, was kurze Zeit dauern sollte
Zurück zum Inhaltsverzeichnis
Unter Windows:
Laden Sie Microsoft Visual Studio Build Tools 2022 von der offiziellen Website herunter – „Tools für Visual Studio“
HINWEIS: Stellen Sie bei der Installation der oben genannten Komponenten sicher, dass Sie die folgenden Komponenten auswählen:
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
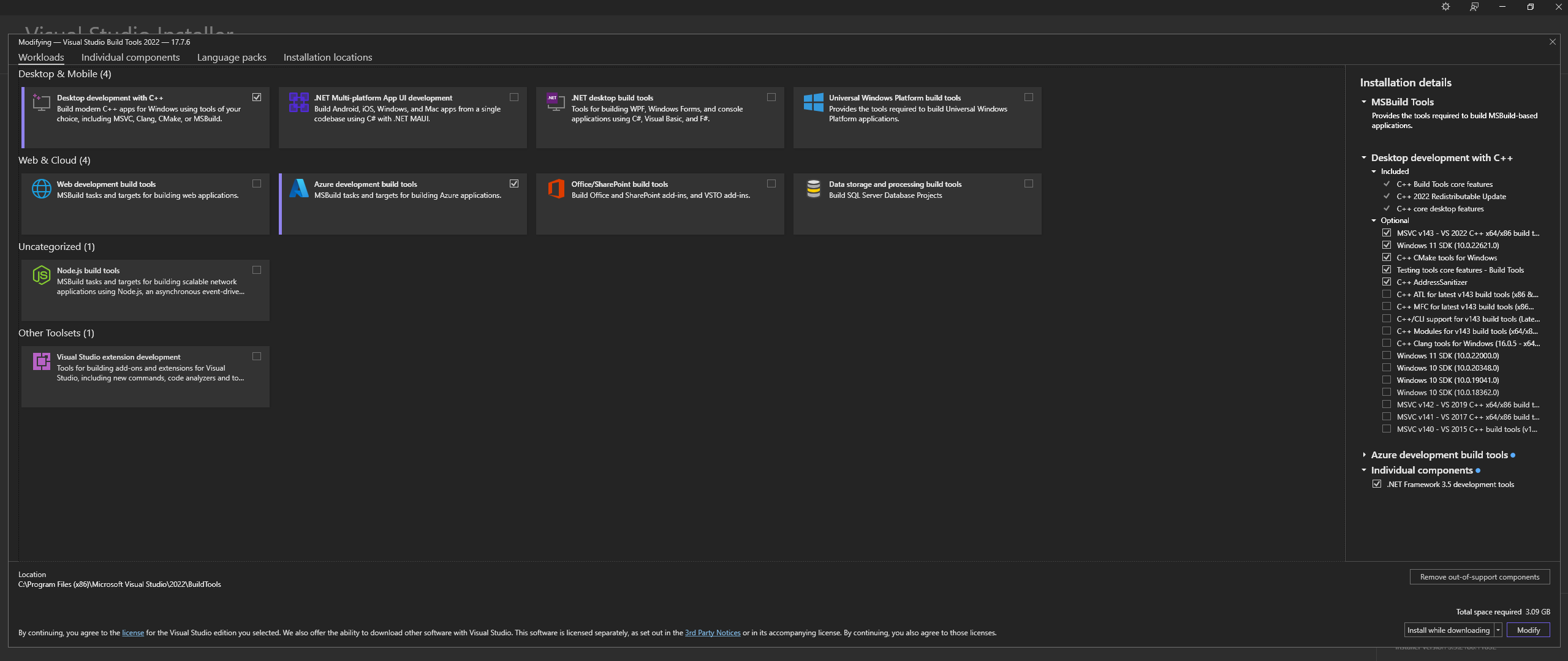
Desktop development with C++ Workload und die MSVC and C++ CMake Options wie oben beschrieben ausgewählt sindInstallieren Sie unter Linux (Ubuntu- und Debian-basiert) die folgenden Pakete:
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
Download aus dem offiziellen Repo:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Installieren Sie CMAKE unter Windows von der offiziellen Website
C:Program FilesCMakebinErstellen Sie llama.cpp mit CMAKE:
Hinweis: Für eine schnellere Kompilierung fügen Sie das Argument -j hinzu, um mehrere Jobs parallel auszuführen. Beispielsweise führt cmake --build build --config Release -j 8 8 Jobs parallel aus.
Erstellen Sie mit CUDA:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
Wenn beim Versuch, CMake -B build auszuführen, Probleme auftreten, lesen Sie die ausführlichen Schritte zur Fehlerbehebung bei der CMake-Installation weiter unten
Zum PATH hinzufügen:
path_to_cloned_repollama.cppbuildbinRelease
Überprüfen Sie die Installation über das Terminal:
llama-server
Installieren Sie Nvidia GPU-Treiber
Installieren Sie das Nvidia CUDA Toolkit – LARS, erstellt und getestet mit Version 12.2 und Version 12.4
Überprüfen Sie die Installation über das Terminal:
nvcc -V
nvidia-smi
CMAKE-CUDA-Fix (sehr wichtig!):
Kopieren Sie alle vier Dateien aus dem folgenden Verzeichnis:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
und fügen Sie sie in das folgende Verzeichnis ein:
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
Dies ist eine optionale, aber dringend empfohlene Abhängigkeit. Wenn diese Einrichtung nicht abgeschlossen ist, werden nur PDFs unterstützt
Windows:
Von der offiziellen Website herunterladen
Zu PATH hinzufügen, entweder über:
Erweiterte Systemeinstellungen -> Umgebungsvariablen -> Systemvariablen -> PATH-Variable BEARBEITEN -> Fügen Sie Folgendes hinzu (ändern Sie es entsprechend Ihrem Installationsort):
C:Program FilesLibreOfficeprogram
Oder über PowerShell:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Ubuntu- und Debian-basiertes Linux – von der offiziellen Website herunterladen oder über das Terminal installieren:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora und andere RPM-basierte Distributionen – von der offiziellen Website herunterladen oder über das Terminal installieren:
sudo dnf update
sudo dnf install libreoffice
MacOS – Von der offiziellen Website herunterladen oder über Homebrew installieren:
brew install --cask libreoffice
Installation überprüfen:
Unter Windows und MacOS: Führen Sie die LibreOffice-Anwendung aus
Unter Linux über das Terminal:
libreoffice --version
LARS nutzt die Python-Bibliothek pdf2image, um jede Seite eines Dokuments in ein Bild umzuwandeln, wie es für OCR erforderlich ist. Diese Bibliothek ist im Wesentlichen ein Wrapper um das Poppler-Dienstprogramm, das den Konvertierungsprozess abwickelt.
Windows:
Vom offiziellen Repo herunterladen
Zu PATH hinzufügen, entweder über:
Erweiterte Systemeinstellungen -> Umgebungsvariablen -> Systemvariablen -> PATH-Variable BEARBEITEN -> Fügen Sie Folgendes hinzu (ändern Sie es entsprechend Ihrem Installationsort):
path_to_installationpoppler_versionLibrarybin
Oder über PowerShell:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
Linux:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
Dies ist eine optionale Abhängigkeit – Tesseract-OCR wird in LARS nicht aktiv verwendet, aber Methoden zu seiner Verwendung sind im Quellcode vorhanden
Windows:
Laden Sie Tesseract-OCR für Windows über UB-Mannheim herunter
Zu PATH hinzufügen, entweder über:
Erweiterte Systemeinstellungen -> Umgebungsvariablen -> Systemvariablen -> PATH-Variable BEARBEITEN -> Fügen Sie Folgendes hinzu (ändern Sie es entsprechend Ihrem Installationsort):
C:Program FilesTesseract-OCR
Oder über PowerShell:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
Zurück zum Inhaltsverzeichnis
LARS wurde mit Python v3.11.x erstellt und getestet
Installieren Sie Python v3.11.x unter Windows:
Laden Sie v3.11.9 von der offiziellen Website herunter
Stellen Sie während der Installation sicher, dass Sie „Python 3.11 zu PATH hinzufügen“ aktivieren oder es später manuell hinzufügen, entweder über:
Erweiterte Systemeinstellungen -> Umgebungsvariablen -> Systemvariablen -> PATH-Variable BEARBEITEN -> Fügen Sie Folgendes hinzu (ändern Sie es entsprechend Ihrem Installationsort):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
Oder über PowerShell:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
Installieren Sie Python v3.11.x unter Linux (Ubuntu- und Debian-basiert):
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
Überprüfen Sie die Installation über das Terminal:
python3 --version
Wenn bei pip install Fehler auftreten, versuchen Sie Folgendes:
Versionsnummern entfernen:
==version.number , zum Beispiel:urllib3==2.0.4urllib3Erstellen und verwenden Sie eine virtuelle Python-Umgebung:
Es empfiehlt sich, eine virtuelle Umgebung zu verwenden, um Konflikte mit anderen Python-Projekten zu vermeiden
Windows:
Erstellen Sie eine virtuelle Python-Umgebung (venv):
python -m venv larsenv
Aktivieren Sie den venv und verwenden Sie ihn anschließend:
.larsenvScriptsactivate
Deaktivieren Sie venv, wenn Sie fertig sind:
deactivate
Linux und MacOS:
Erstellen Sie eine virtuelle Python-Umgebung (venv):
python3 -m venv larsenv
Aktivieren Sie den venv und verwenden Sie ihn anschließend:
source larsenv/bin/activate
Deaktivieren Sie venv, wenn Sie fertig sind:
deactivate
Wenn die Probleme weiterhin bestehen, sollten Sie erwägen, ein Issue im LARS-GitHub-Repository zu öffnen, um Unterstützung zu erhalten.
CMake nmake failed -Fehler wie den folgenden stoßen: 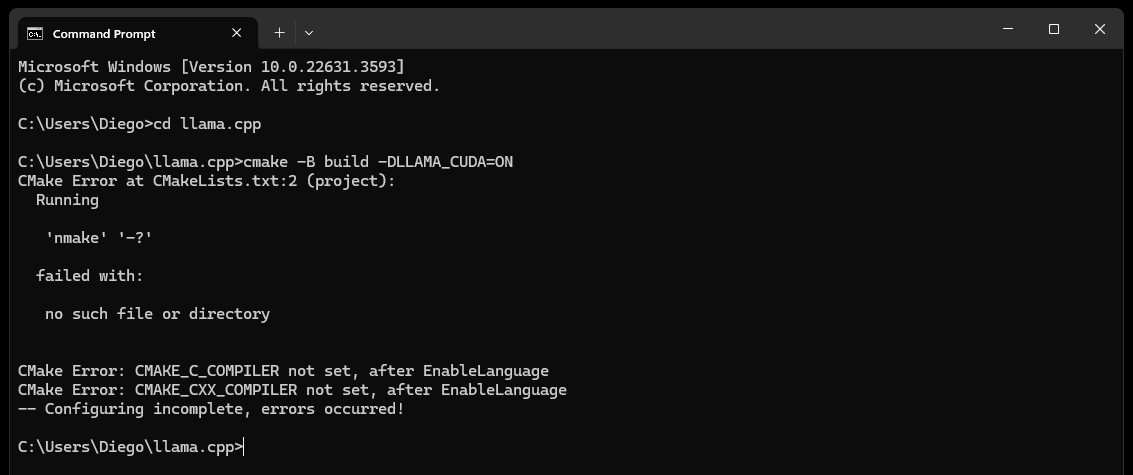
Dies weist typischerweise auf ein Problem mit Ihren Microsoft Visual Studio-Build-Tools hin, da CMake das Nmake-Tool, das Teil der Microsoft Visual Studio-Build-Tools ist, nicht finden kann. Versuchen Sie die folgenden Schritte, um das Problem zu beheben:
Stellen Sie sicher, dass Visual Studio Build Tools installiert sind:
Stellen Sie sicher, dass Sie die Visual Studio-Build-Tools installiert haben, einschließlich nmake. Sie können diese Tools über den Visual Studio Installer installieren, indem Sie die Workload Desktop development with C++ und die optionalen Optionen MSVC and C++ CMake auswählen
Überprüfen Sie Schritt 0 des Abschnitts „Abhängigkeiten“, insbesondere den darin enthaltenen Screenshot
Umgebungsvariablen prüfen:
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
Verwenden Sie die Entwickler-Eingabeaufforderung:
Öffnen Sie eine „Entwickler-Eingabeaufforderung für Visual Studio“, die die erforderlichen Umgebungsvariablen für Sie einrichtet
Sie finden diese Eingabeaufforderung im Startmenü unter Visual Studio
CMake-Generator einstellen:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
Wenn die Probleme weiterhin bestehen, sollten Sie erwägen, ein Issue im LARS-GitHub-Repository zu öffnen, um Unterstützung zu erhalten.
Irgendwann (nach etwa 60 Sekunden) wird auf der Seite eine Warnung angezeigt, die auf einen Fehler hinweist:
Failed to start llama.cpp local-server
Dies zeigt an, dass die Erstausführung abgeschlossen ist und alle App-Verzeichnisse erstellt wurden, im models jedoch keine LLMs vorhanden sind und diese nun dorthin verschoben werden können
Verschieben Sie Ihre LLMs (jedes von llama.cpp unterstützte Dateiformat, vorzugsweise GGUF) in das neu erstellte models , das sich standardmäßig an den folgenden Speicherorten befindet:
C:/web_app_storage/models/app/storage/models/app/models Sobald Sie Ihre LLMs oben im entsprechenden models abgelegt haben, aktualisieren Sie http://localhost:5000/
Nach etwa 60 Sekunden erhalten Sie erneut eine Fehlermeldung, die besagt, Failed to start llama.cpp local-server
Dies liegt daran, dass Ihr LLM jetzt im Menü LARS Settings ausgewählt werden muss
Akzeptieren Sie die Warnung und klicken Sie oben rechts auf das Zahnradsymbol Settings
Wählen Sie auf der Registerkarte LLM Selection Ihr LLM und das entsprechende Eingabeaufforderungsvorlagenformat aus den entsprechenden Dropdown-Listen aus
Ändern Sie die erweiterten Einstellungen, um GPU Optionen, die Context-Length und optional das Token-Generierungslimit ( Maximum tokens to predict ) für Ihr ausgewähltes LLM korrekt festzulegen
Klicken Sie auf Save und aktualisieren Sie die Seite manuell, wenn keine automatische Aktualisierung ausgelöst wird
Wenn alle Schritte korrekt ausgeführt wurden, ist die Ersteinrichtung nun abgeschlossen und LARS ist einsatzbereit
LARS merkt sich auch Ihre LLM-Einstellungen für die spätere Verwendung
Zurück zum Inhaltsverzeichnis
Unterstützte Dokumentformate:
Wenn LibreOffice installiert und zu PATH hinzugefügt wird, wie in Schritt 4 des Abschnitts „Abhängigkeiten“ beschrieben, werden die folgenden Formate unterstützt:
Wenn LibreOffice nicht eingerichtet ist, werden nur PDFs unterstützt
OCR-Optionen für die Textextraktion:
LARS bietet drei Methoden zum Extrahieren von Text aus Dokumenten und berücksichtigt verschiedene Dokumenttypen und -qualitäten:
Lokale Textextraktion: Verwendet PyPDF2 zur effizienten Textextraktion aus nicht gescannten PDFs. Ideal für eine schnelle Verarbeitung, wenn eine hohe Genauigkeit nicht entscheidend ist oder eine vollständig lokale Verarbeitung erforderlich ist.
Azure ComputerVision OCR – Verbessert die Genauigkeit der Textextraktion und unterstützt gescannte Dokumente. Nützlich für die Handhabung von Standarddokumentlayouts. Bietet ein kostenloses Kontingent, das für erste Testversionen und die Nutzung mit geringem Volumen geeignet ist und auf 5.000 Transaktionen/Monat bei 20 Transaktionen/Minute begrenzt ist.
Azure AI Document Intelligence OCR – Am besten für Dokumente mit komplexen Strukturen wie Tabellen. Ein benutzerdefinierter Parser in LARS optimiert den Extraktionsprozess.
HINWEISE:
Azure OCR-Optionen verursachen in den meisten Fällen API-Kosten und sind nicht im Paket mit LARS enthalten.
Ein begrenztes kostenloses Kontingent für ComputerVision OCR ist wie oben verlinkt verfügbar. Dieser Service ist insgesamt günstiger, aber langsamer und funktioniert möglicherweise nicht für nicht standardmäßige Dokumentlayouts (außer A4 usw.).
Berücksichtigen Sie bei der Auswahl einer OCR-Option die Dokumenttypen und Ihre Genauigkeitsanforderungen.
LLMs:
Derzeit werden nur lokale LLMs unterstützt
Das Menü Settings bietet dem Power-User viele Optionen zum Konfigurieren und Ändern des LLM über die Registerkarte LLM Selection .
Beachten Sie bei Verwendung von llama.cpp Folgendes: Sehr wichtig: Wählen Sie das entsprechende Eingabeaufforderungsvorlagenformat für das von Ihnen ausgeführte LLM aus
LLMs, die für die folgenden Eingabeaufforderungsvorlagenformate trainiert wurden, werden derzeit über llama.cpp unterstützt:
Optimieren Sie die Core-Konfigurationseinstellungen über Advanced Settings (löst LLM-Neuladen und Seitenaktualisierung aus):
Passen Sie die Einstellungen an, um das Antwortverhalten jederzeit zu ändern:
Einbettungsmodelle und Vektordatenbank:
In LARS stehen vier Einbettungsmodelle zur Verfügung:
Mit Ausnahme der Azure-OpenAI-Einbettungen laufen alle anderen Modelle vollständig lokal und kostenlos. Beim ersten Start werden diese Modelle vom HuggingFace Hub heruntergeladen. Dies ist ein einmaliger Download und sie sind anschließend lokal verfügbar.
Der Benutzer kann jederzeit über die Registerkarte VectorDB & Embedding Models im Menü Settings zwischen diesen Einbettungsmodellen wechseln
Mit Dokumenten geladene Tabelle: Im Menü Settings wird für das ausgewählte Einbettungsmodell eine Tabelle mit der Liste der in die zugehörige Vektordatenbank eingebetteten Dokumente angezeigt. Wenn ein Dokument mehrmals geladen wird, enthält es mehrere Einträge in dieser Tabelle, was zum Debuggen von Problemen hilfreich sein kann.
Löschen der VectorDB: Klicken Sie auf die Schaltfläche Reset und bestätigen Sie, um die ausgewählte Vektordatenbank zu löschen. Dadurch wird eine neue vectorDB auf der Festplatte für das ausgewählte Einbettungsmodell erstellt. Die alte vectorDB bleibt weiterhin erhalten und kann durch manuelles Ändern der Datei config.json wiederhergestellt werden.
System-Eingabeaufforderung bearbeiten:
Der System-Prompt dient dem LLM als Anweisung für das gesamte Gespräch
LARS bietet dem Benutzer die Möglichkeit, die Systemaufforderung über das Menü Settings zu bearbeiten, indem er im Dropdown-Menü auf der Registerkarte System Prompt die Option Custom auswählt
Änderungen an der System-Eingabeaufforderung starten einen neuen Chat
Aktivieren/Deaktivieren von RAG erzwingen:
Über das Menü Settings kann der Benutzer bei Bedarf die Aktivierung oder Deaktivierung von RAG (Retrieval Augmented Generation – die Verwendung von Inhalten aus Ihren Dokumenten zur Verbesserung von LLM-generierten Antworten) erzwingen
Dies ist oft nützlich, um LLM-Antworten in beiden Szenarien zu bewerten
Durch die erzwungene Deaktivierung werden auch die Attributionsfunktionen deaktiviert
Die Standardeinstellung, die NLP verwendet, um zu bestimmen, wann RAG durchgeführt werden soll und wann nicht, ist die empfohlene Option
Diese Einstellung kann jederzeit geändert werden
Chatverlauf:
Verwenden Sie das Chatverlaufsmenü oben links, um frühere Gespräche zu durchsuchen und fortzusetzen
Sehr wichtig: Achten Sie bei der Wiederaufnahme früherer Gespräche auf Abweichungen zwischen Eingabeaufforderungsvorlagen! Verwenden Sie das Information oben rechts, um sicherzustellen, dass das im vorherigen Gespräch verwendete und das derzeit verwendete LLM beide auf denselben Eingabeaufforderungsvorlagenformaten basieren!
Benutzerbewertung:
Jede Antwort kann vom Benutzer jederzeit auf einer 5-Punkte-Skala bewertet werden
Bewertungsdaten werden in der SQLite3-Datenbank chat-history.db gespeichert, die sich im App-Verzeichnis befindet:
C:/web_app_storage/app/storage/appBewertungsdaten sind für die Bewertung und Verfeinerung des Tools für Ihre Arbeitsabläufe sehr wertvoll
Dos und Don'ts:
Zurück zum Inhaltsverzeichnis
Wenn ein Chat schief geht oder seltsame Antworten generiert werden, versuchen Sie einfach, über das Menü oben links einen New Chat zu starten
Alternativ können Sie einen neuen Chat starten, indem Sie einfach die Seite aktualisieren
Wenn Probleme mit Zitaten oder der RAG-Leistung auftreten, versuchen Sie, die vectorDB zurückzusetzen, wie in Schritt 4 des allgemeinen Benutzerhandbuchs oben beschrieben
Wenn Anwendungsprobleme auftreten und sich nicht einfach durch Starten eines neuen Chats oder Neustartens von LARS lösen lassen, versuchen Sie, die Datei config.json zu löschen, indem Sie die folgenden Schritte ausführen:
CTRL+C beendenconfig.json in LARS/web_app (dasselbe Verzeichnis wie app.py ).Führen Sie bei schwerwiegenden Daten- und Zitierproblemen, die auch durch das Zurücksetzen der VectorDB wie in Schritt 4 des allgemeinen Benutzerhandbuchs oben beschrieben nicht behoben werden, die folgenden Schritte aus:
CTRL+C beendenC:/web_app_storage/app/storage/appWenn die Probleme weiterhin bestehen, sollten Sie erwägen, ein Issue im LARS-GitHub-Repository zu öffnen, um Unterstützung zu erhalten.
Zurück zum Inhaltsverzeichnis
LARS wurde über zwei separate Bilder wie unten an eine Docker-Container-Bereitstellungsumgebung angepasst:
Für beide gelten unterschiedliche Anforderungen, wobei Ersteres eine einfachere Bereitstellung darstellt, jedoch aufgrund der Engpässe bei der CPU und dem DDR-Speicher eine weitaus langsamere Inferenzleistung aufweist
Obwohl dies nicht ausdrücklich erforderlich ist, sind in diesem Abschnitt einige Erfahrungen mit Docker-Containern und Vertrautheit mit den Konzepten der Containerisierung und Virtualisierung sehr hilfreich!
Beginnen Sie mit den allgemeinen Einrichtungsschritten für beide:
Docker installieren
Ihre CPU sollte Virtualisierung unterstützen und diese sollte im BIOS/UEFI Ihres Systems aktiviert sein
Laden Sie Docker Desktop herunter und installieren Sie es
Unter Windows müssen Sie möglicherweise das Windows-Subsystem für Linux installieren, sofern es noch nicht vorhanden ist. Öffnen Sie dazu PowerShell als Administrator und führen Sie Folgendes aus:
wsl --install
Stellen Sie sicher, dass Docker Desktop betriebsbereit ist, öffnen Sie dann eine Eingabeaufforderung/ein Terminal und führen Sie den folgenden Befehl aus, um sicherzustellen, dass Docker ordnungsgemäß installiert und betriebsbereit ist:
docker ps
Erstellen Sie ein Docker-Speichervolume, das zur Laufzeit an die LARS-Container angehängt wird:
Das Erstellen eines Speichervolumens zur Verwendung mit dem LARS-Container ist äußerst vorteilhaft, da Sie so den LARS-Container auf eine neuere Version aktualisieren oder zwischen den CPU- und GPU-Containervarianten wechseln können, während alle Ihre Einstellungen, Chat-Verläufe und Vektordatenbanken nahtlos beibehalten werden .
Führen Sie den folgenden Befehl in einer Eingabeaufforderung/Terminal aus:
docker volume create lars_storage_volue
Dieses Volume wird später zur Laufzeit an den LARS-Container angehängt. Fahren Sie zunächst mit der Erstellung des LARS-Images in den folgenden Schritten fort.
Führen Sie in einer Eingabeaufforderung/Terminal die folgenden Befehle aus:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
Sobald Sie fertig sind, navigieren Sie in Ihrem Browser zu http://localhost:5000/ und folgen Sie den restlichen Schritten zur ersten Ausführung und dem Benutzerhandbuch
Die Abschnitte zur Fehlerbehebung gelten auch für Container-LARS
Anforderungen (zusätzlich zu Docker):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Für Linux sind Sie mit den oben genannten Schritten fertig. Überspringen Sie also den nächsten Schritt und fahren Sie direkt mit den Schritten zum Erstellen und Ausführen weiter unten fort
Wenn Sie unter Windows arbeiten und dies das erste Mal ist, dass Sie einen Nvidia-GPU-Container auf Docker ausführen, schnallen Sie sich an, denn das wird eine ziemliche Fahrt (Lieblingsgetränk oder drei, sehr zu empfehlen!)
Wenn Sie eine extreme Redundanz riskieren, stellen Sie vor dem Fortfahren sicher, dass die folgenden Abhängigkeiten vorhanden sind:
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
Wenn Sie sich nicht sicher sind, lesen Sie den Abschnitt „Nvidia CUDA-Abhängigkeiten“ und den Abschnitt „Docker-Setup“ oben
Wenn die oben genannten Punkte vorhanden und eingerichtet sind, können Sie fortfahren
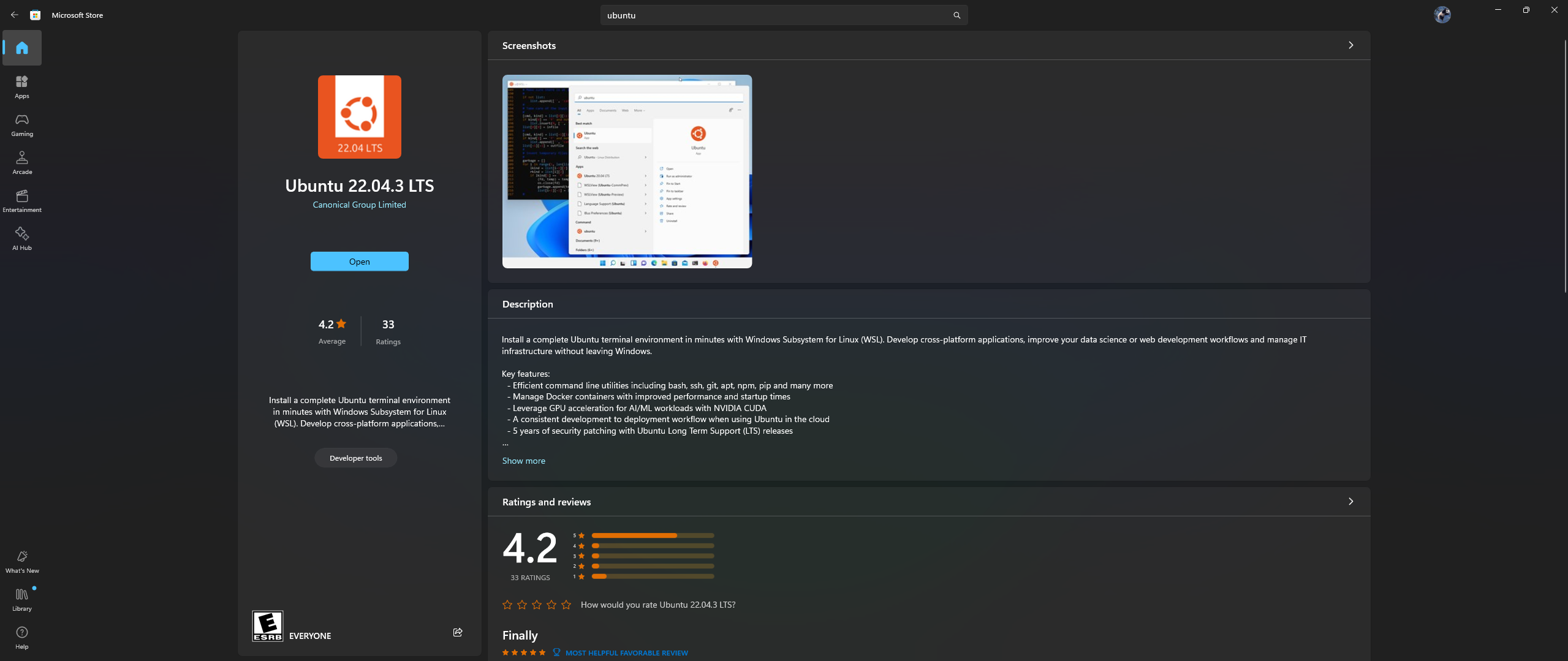
Öffnen Sie die Microsoft Store-App auf Ihrem PC und laden Sie Ubuntu 22.04.3 LTS herunter und installieren Sie es (muss mit der Version in Zeile 2 in der Docker-Datei übereinstimmen).
Ja, Sie haben das Obige richtig gelesen: Laden Sie Ubuntu aus der Microsoft Store-App herunter und installieren Sie es, siehe Screenshot unten:
Jetzt ist es an der Zeit, das Nvidia Container Toolkit in Ubuntu zu installieren. Führen Sie dazu die folgenden Schritte aus:
Starten Sie eine Ubuntu-Shell in Windows, indem Sie im Startmenü nach Ubuntu suchen, nachdem die obige Installation abgeschlossen ist
Führen Sie in dieser sich öffnenden Ubuntu-Befehlszeile die folgenden Schritte aus:
Konfigurieren Sie das Produktions-Repository:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Aktualisieren Sie die Paketliste aus dem Repository und installieren Sie die Nvidia Container Toolkit-Pakete:
sudo apt-get update && apt-get install -y nvidia-container-toolkit
Konfigurieren Sie die Container-Laufzeit mithilfe des Befehls nvidia-ctk, der die Datei /etc/docker/daemon.json ändert, sodass Docker die Nvidia-Container-Laufzeit verwenden kann:
sudo nvidia-ctk runtime configure --runtime=docker
Starten Sie den Docker-Daemon neu:
sudo systemctl restart docker
Jetzt ist Ihr Ubuntu-Setup abgeschlossen und es ist Zeit, die WSL- und Docker-Integrationen abzuschließen:
Öffnen Sie ein neues PowerShell-Fenster und legen Sie diese Ubuntu-Installation als WSL-Standard fest:
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
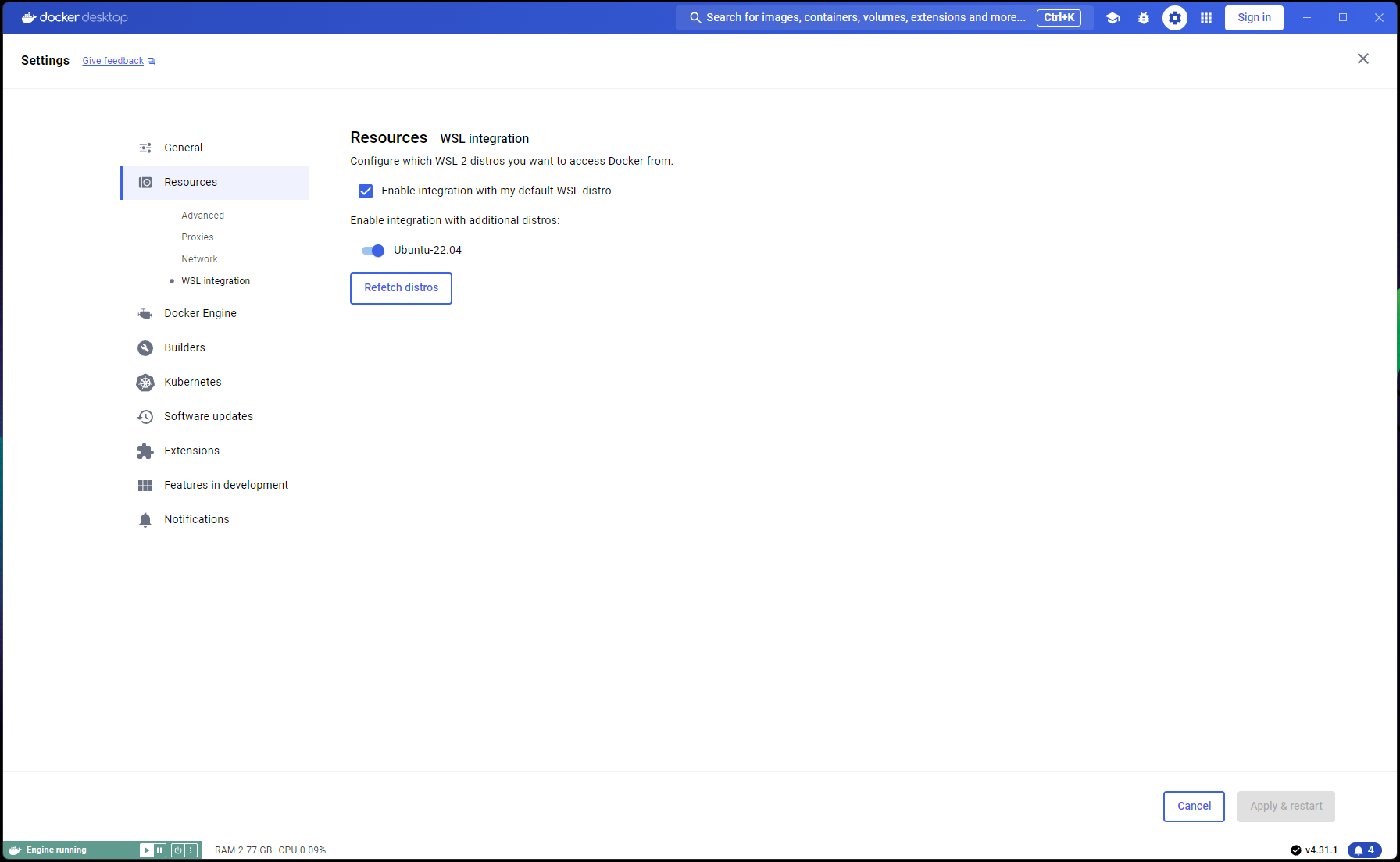
Navigieren Sie zu Docker Desktop -> Settings -> Resources -> WSL Integration -> Standard- und Ubuntu 22.04-Integrationen prüfen. Sehen Sie sich den folgenden Screenshot an:
Wenn nun alles richtig gemacht wurde, können Sie den Container erstellen und ausführen!
Führen Sie in einer Eingabeaufforderung/Terminal die folgenden Befehle aus:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
Sobald Sie fertig sind, navigieren Sie in Ihrem Browser zu http://localhost:5000/ und folgen Sie den restlichen Schritten zur ersten Ausführung und dem Benutzerhandbuch
Die Abschnitte zur Fehlerbehebung gelten auch für Container-LARS
Falls Sie beim Erstellen des Containers auf netzwerkbezogene Fehler stoßen, insbesondere im Zusammenhang mit nicht verfügbaren Paket-Repositorys, handelt es sich hierbei um ein Netzwerkproblem auf Ihrer Seite, das häufig mit Firewall-Problemen zusammenhängt
Navigieren Sie unter Windows zu Control PanelSystem and SecurityWindows Defender FirewallAllowed apps oder suchen Sie im Startmenü nach Firewall , gehen Sie zu Allow an app through the firewall und stellen Sie sicher, dass „Docker Desktop Backend“ durchgelassen wird
Wenn Sie LARS zum ersten Mal ausführen, wird das Einbettungsmodell für Satztransformatoren heruntergeladen
In der Containerumgebung kann dieser Download manchmal problematisch sein und zu Fehlern führen, wenn Sie eine Abfrage stellen
Wenn dies auftritt, gehen Sie einfach zum LARS-Einstellungsmenü: Settings->VectorDB & Embedding Models und ändern Sie das Einbettungsmodell entweder in BGE-Base oder BGE-Large. Dadurch wird ein Neuladen und erneutes Herunterladen erzwungen
Wenn Sie fertig sind, stellen Sie erneut Fragen und die Antwort sollte wie gewohnt erfolgen
Sie können zum Satztransformer-Einbettungsmodell zurückkehren und das Problem sollte behoben sein
Wie im Abschnitt „Fehlerbehebung“ oben erwähnt, werden Einbettungsmodelle heruntergeladen, wenn LARS zum ersten Mal ausgeführt wird
Am besten speichern Sie den Status des Containers, bevor Sie ihn herunterfahren, damit dieser Download-Schritt nicht bei jedem weiteren Start des Containers wiederholt werden muss
Öffnen Sie dazu eine andere Eingabeaufforderung/ein anderes Terminal und übernehmen Sie die Änderungen, BEVOR Sie den laufenden LARS-Container schließen:
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
Dadurch wird ein aktualisiertes Image erstellt, das Sie bei nachfolgenden Läufen verwenden können:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
HINWEIS: Nachdem Sie die oben genannten Schritte ausgeführt haben und den von Bildern verwendeten Speicherplatz mit docker images überprüfen, werden Sie feststellen, dass viel Speicherplatz belegt ist. ABER nehmen Sie die Größenangaben hier nicht wörtlich! Die für jedes Bild angezeigte Größe umfasst die Gesamtgröße aller seiner Ebenen. Viele dieser Ebenen werden jedoch von Bildern gemeinsam genutzt, insbesondere wenn diese Bilder auf demselben Basisbild basieren oder wenn es sich bei einem Bild um eine festgeschriebene Version eines anderen handelt. Um zu sehen, wie viel Speicherplatz Ihre Docker-Images tatsächlich belegen, verwenden Sie:
docker system df
Zurück zum Inhaltsverzeichnis
| Kategorie | Aufgaben | Status |
|---|---|---|
| Fehlerbehebungen: | Gefahr bei der Erstellung von Null-Byte-Textdateien – Wenn die OCR/Textextraktion des Eingabedokuments fehlschlägt, bleibt möglicherweise eine 0B-.txt-Datei übrig, was zu weiteren Wiederholungsversuchen führt, bei denen angenommen wird, dass die Datei bereits geladen wurde | ? Zukünftige Aufgabe |
| Praktische Funktionen: | Auf Benutzerfreundlichkeit ausgerichtet: | |
| Umschalten der Benutzeroberfläche im kostenlosen Azure CV-OCR-Tarif | ✅ Geschehen am 8. Juni 2024 | |
| Chats löschen | ? Zukünftige Aufgabe | |
| Chats umbenennen | ? Zukünftige Aufgabe | |
| PowerShell-Installationsskript | ? Zukünftige Aufgabe | |
| Linux-Installationsskript | ? Zukünftige Aufgabe | |
| Ollama LLM-Inferenz-Backend als Alternative zu llama.cpp | ? Zukünftige Aufgabe | |
| Integration von OCR-Diensten anderer Cloud-Anbieter (GCP, AWS, OCI, etc.) | ? Zukünftige Aufgabe | |
| UI-Schalter zum Ignorieren vorheriger Textextrakte beim Hochladen eines Dokuments | ? Zukünftige Aufgabe | |
| Modales Popup für Datei-Uploads: Textextraktionsoptionen aus den Einstellungen spiegeln, globales Überschreiben bei Übermittlungen, umschalten, um die Einstellungen beizubehalten | ? Zukünftige Aufgabe | |
| Leistungsorientiert: | ||
| Nvidia TensorRT-LLM AWQ-Unterstützung | ? Zukünftige Aufgabe | |
| Forschungsaufgaben: | Untersuchen Sie Nvidia TensorRT-LLM: Erfordert die Erstellung von AWQ-LLM-TRT-Engines speziell für die Ziel-GPU. NvTensorRT-LLM ist ein eigenes Ökosystem und funktioniert nur auf Python v3.10. | ✅ Geschehen am 13. Juni 2024 |
| Lokale OCR mit Vision-LLMs: MS-TrOCR (erledigt), Kosmos-2.5 (hohe Priorität), Llava, Florence-2 | ? In Bearbeitung: Update vom 5. Juli 2024 | |
| RAG-Verbesserungen: Re-Ranker, RAPTOR, T-RAG | ? Zukünftige Aufgabe | |
| Untersuchen Sie die GraphDB-Integration: Verwenden Sie LLMs, um Entitätsbeziehungsdaten aus Dokumenten zu extrahieren und eine GraphDB zu füllen, zu aktualisieren und zu verwalten | ? Zukünftige Aufgabe |
Zurück zum Inhaltsverzeichnis
Ich hoffe, dass LARS für Ihre Arbeit wertvoll war und lade Sie ein, die weitere Entwicklung zu unterstützen! Wenn Sie das Tool schätzen und zu seinen zukünftigen Verbesserungen beitragen möchten, denken Sie über eine Spende nach. Ihre Unterstützung hilft mir, LARS weiter zu verbessern und neue Funktionen hinzuzufügen.
So spenden Sie: Um eine Spende zu tätigen, nutzen Sie bitte den folgenden Link zu meinem PayPal:
Spenden Sie über PayPal
Ihre Beiträge werden sehr geschätzt und zur Finanzierung weiterer Entwicklungsbemühungen verwendet.
Zurück zum Inhaltsverzeichnis


