ChatRWKV
1.0.0
RWKV-Homepage: https://www.rwkv.com
ChatRWKV ist wie ChatGPT, basiert jedoch auf meinem RWKV-Sprachmodell (100 % RNN), das (derzeit) das einzige RNN ist, das in Qualität und Skalierung mit Transformern mithalten kann, gleichzeitig schneller ist und VRAM spart. Schulung gesponsert von Stability EleutherAI :)
Unsere neueste Version ist RWKV-6 https://arxiv.org/abs/2404.05892 (Vorschaumodelle: https://huggingface.co/BlinkDL/temp)
RWKV-6 3B Demo: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
RWKV-6 7B Demo: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
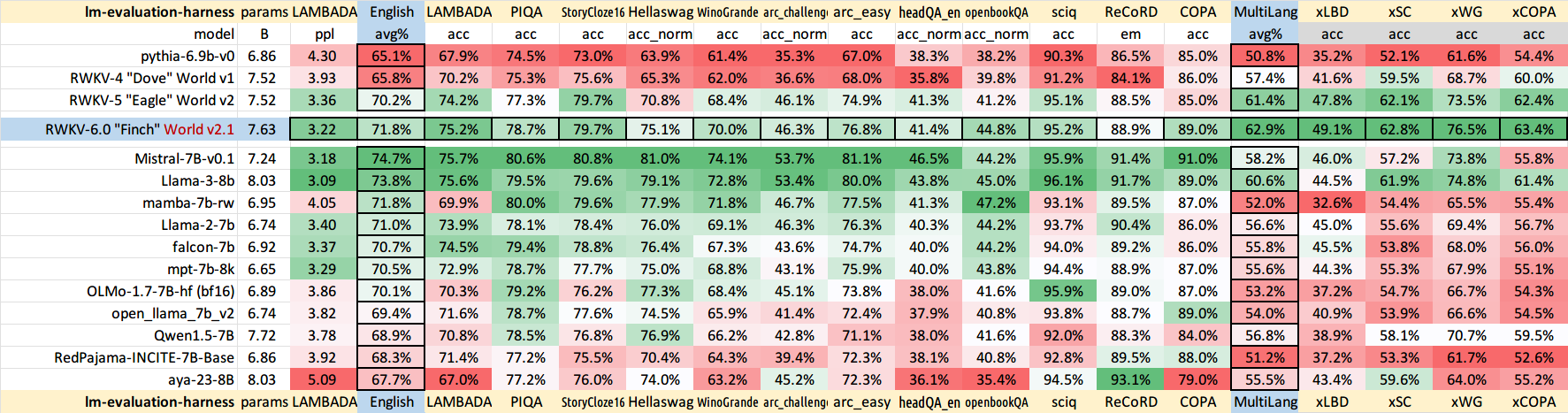
RWKV-LM-Hauptrepo : https://github.com/BlinkDL/RWKV-LM (Erklärung, Feinabstimmung, Schulung usw.)
Chat-Demo für Entwickler: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Twitter : https://twitter.com/BlinkDL_AI
Homepage : https://www.rwkv.com/
Rohe, hochmoderne RWKV-Gewichte: https://huggingface.co/BlinkDL
HF-kompatible RWKV-Gewichte: https://huggingface.co/RWKV
Verwenden Sie v2/convert_model.py, um ein Modell für eine Strategie zu konvertieren, um das Laden zu beschleunigen und CPU-RAM zu sparen.
Hinweis: RWKV_CUDA_ON erstellt einen CUDA-Kernel (viel schneller und spart VRAM). So erstellen Sie es (zuerst „pip install ninja“):
# How to build in Linux: set these and run v2/chat.py
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
# How to build in win:
Install VS2022 build tools (https://aka.ms/vs/17/release/vs_BuildTools.exe select Desktop C++). Reinstall CUDA 11.7 (install VC++ extensions). Run v2/chat.py in "x64 native tools command prompt".
RWKV-Pip-Paket : https://pypi.org/project/rwkv/ (bitte immer auf die neueste Version prüfen und aktualisieren)
https://github.com/cgisky1980/ai00_rwkv_server Schnellste GPU-Inferenz-API mit Vulkan (gut für nvidia/amd/intel)
https://github.com/cryscan/web-rwkv Backend für ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp Schnelle CPU/cuBLAS/CLBlast-Inferenz: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state tuning
https://github.com/RWKV/RWKV-infctx-trainer Infctx-Trainer
Welt-Demo-Skript: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_WORLD.py
Raven Q&A-Demoskript: https://github.com/BlinkDL/ChatRWKV/blob/main/v2/benchmark_more.py
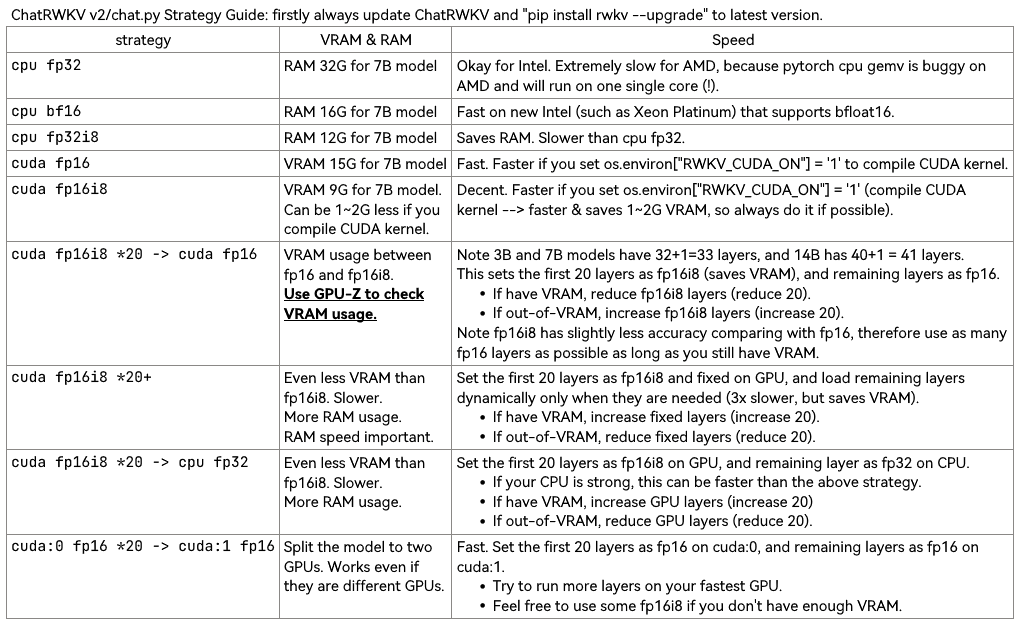
RWKV in 150 Zeilen (Modell, Inferenz, Textgenerierung): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
RWKV v5 in 250 Zeilen (auch mit Tokenizer): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Erstellen Sie Ihre eigene RWKV-Inferenz-Engine : Beginnen Sie mit https://github.com/BlinkDL/ChatRWKV/blob/main/src/model_run.py, was einfacher zu verstehen ist (verwendet von https://github.com/BlinkDL/ChatRWKV/ blob/main/chat.py).
RWKV-Vorabdruck https://arxiv.org/abs/2305.13048
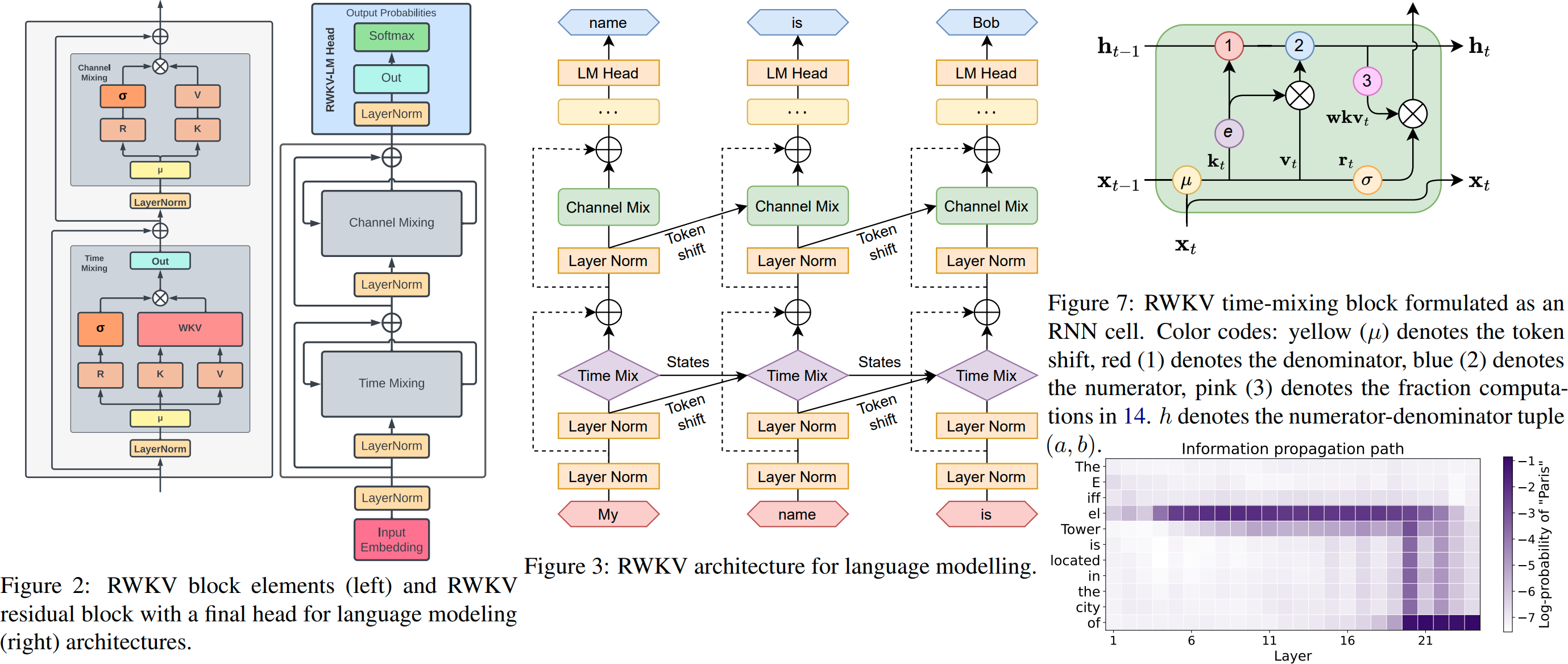
RWKV v6 illustriert:
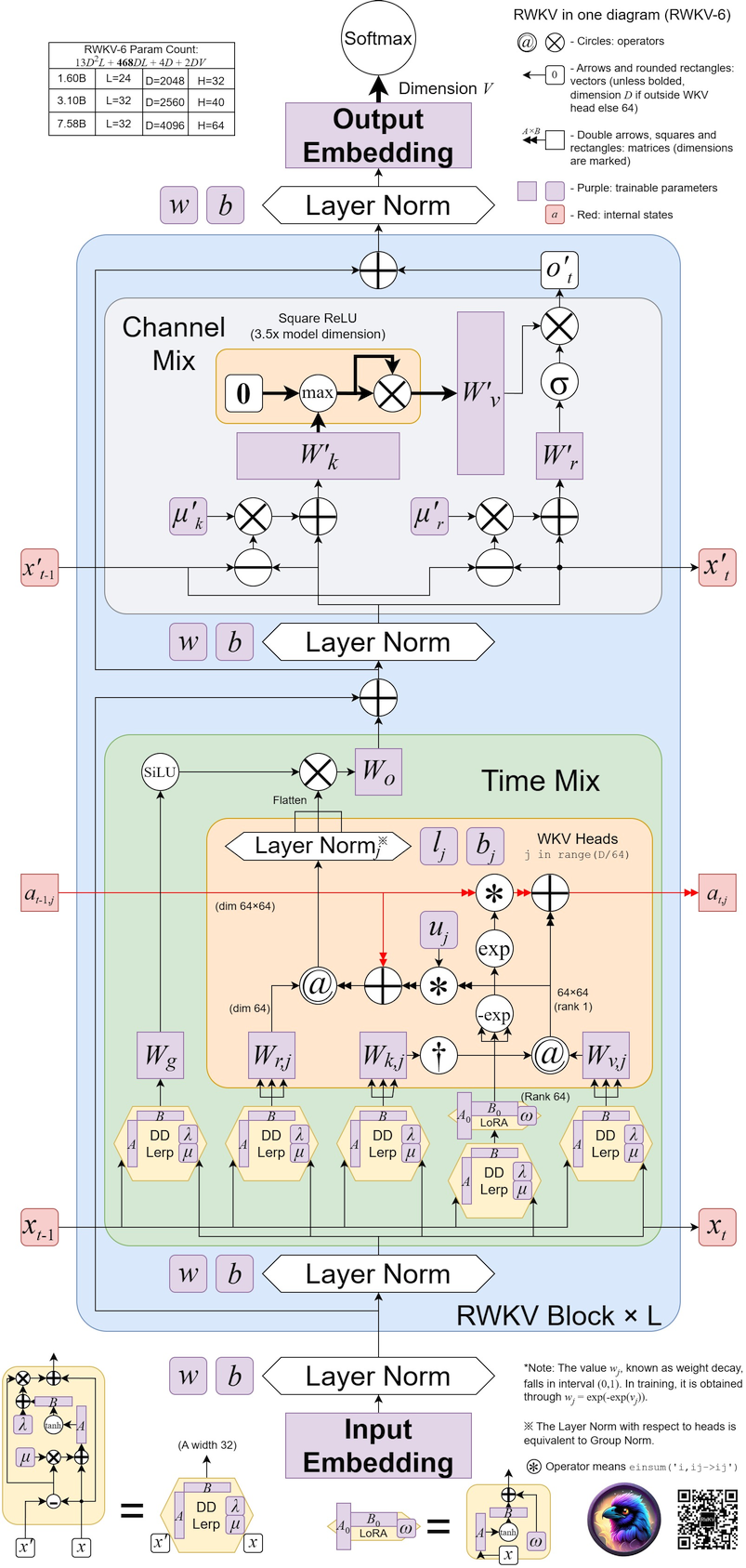
Coole Community-RWKV-Projekte :
https://github.com/saharNooby/rwkv.cpp schnelle i4 i8 fp16 fp32 CPU-Inferenz mit ggml
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda schnelle Windows/linux & cuda/rocm/vulkan GPU-Inferenz (keine Notwendigkeit für Python & Pytorch)
https://github.com/Blealtan/RWKV-LM-LoRA LoRA-Feinabstimmung
https://github.com/josStorer/RWKV-Runner coole GUI
Weitere RWKV-Projekte: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
ChatRWKV v2: mit „Stream“- und „Split“-Strategien und INT8. 3G VRAM reicht aus, um RWKV 14B auszuführen :) https://github.com/BlinkDL/ChatRWKV/tree/main/v2
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as above 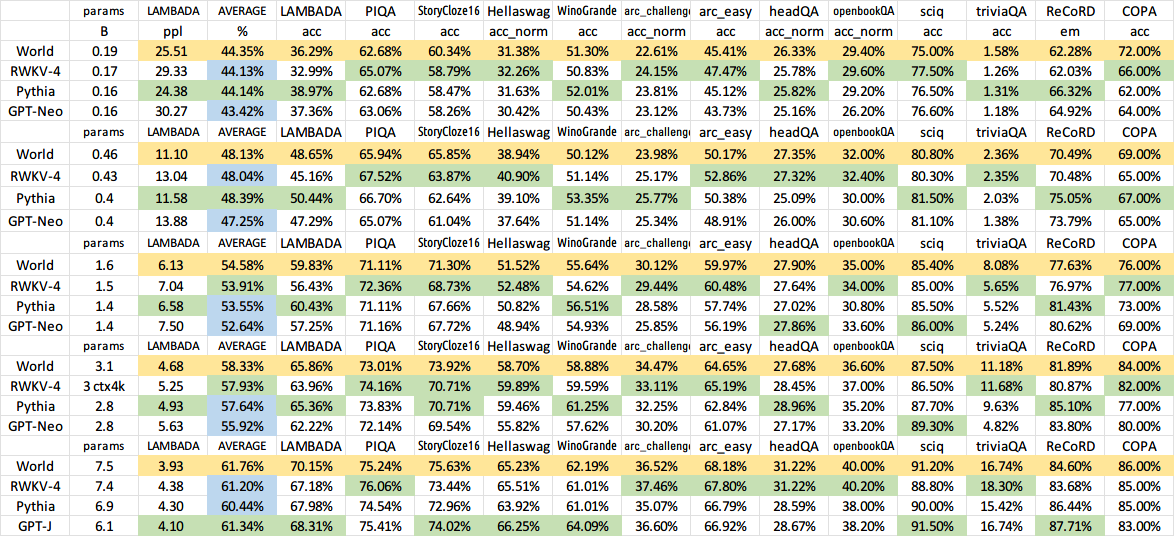
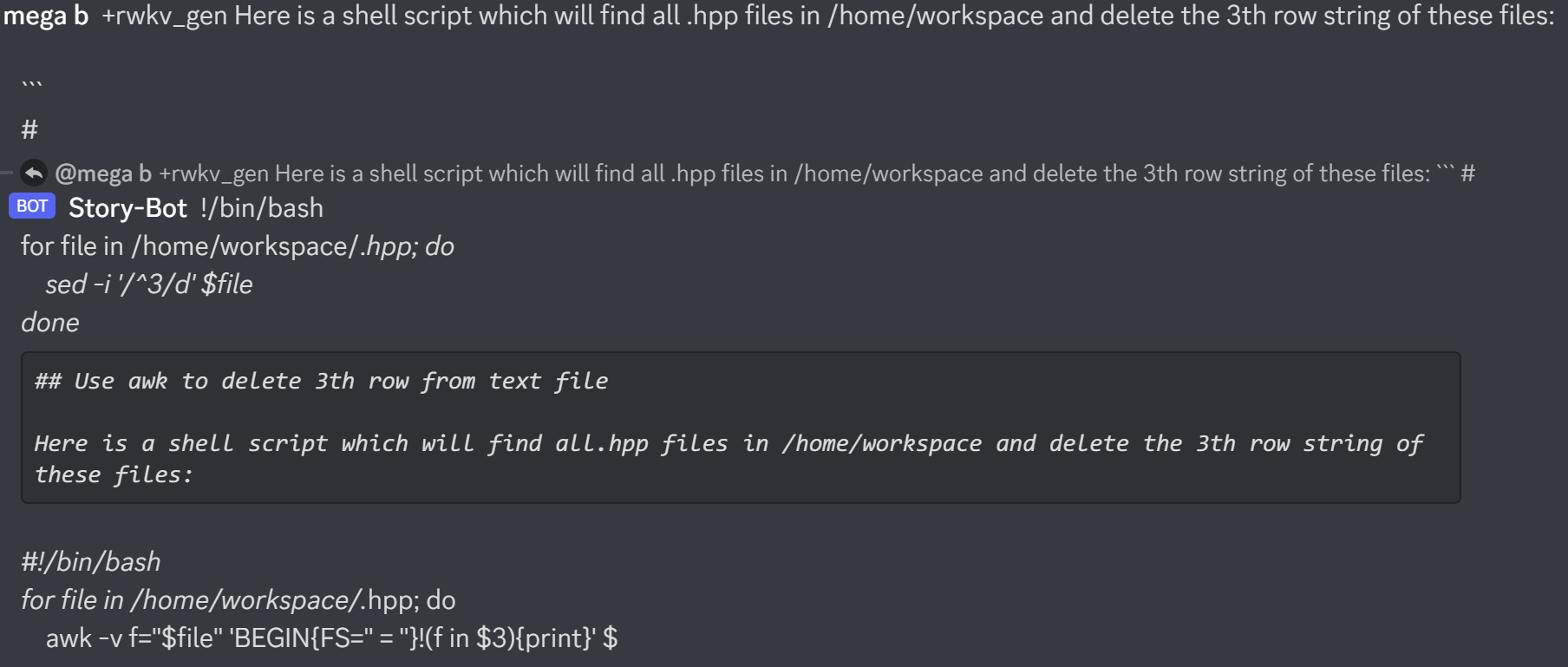
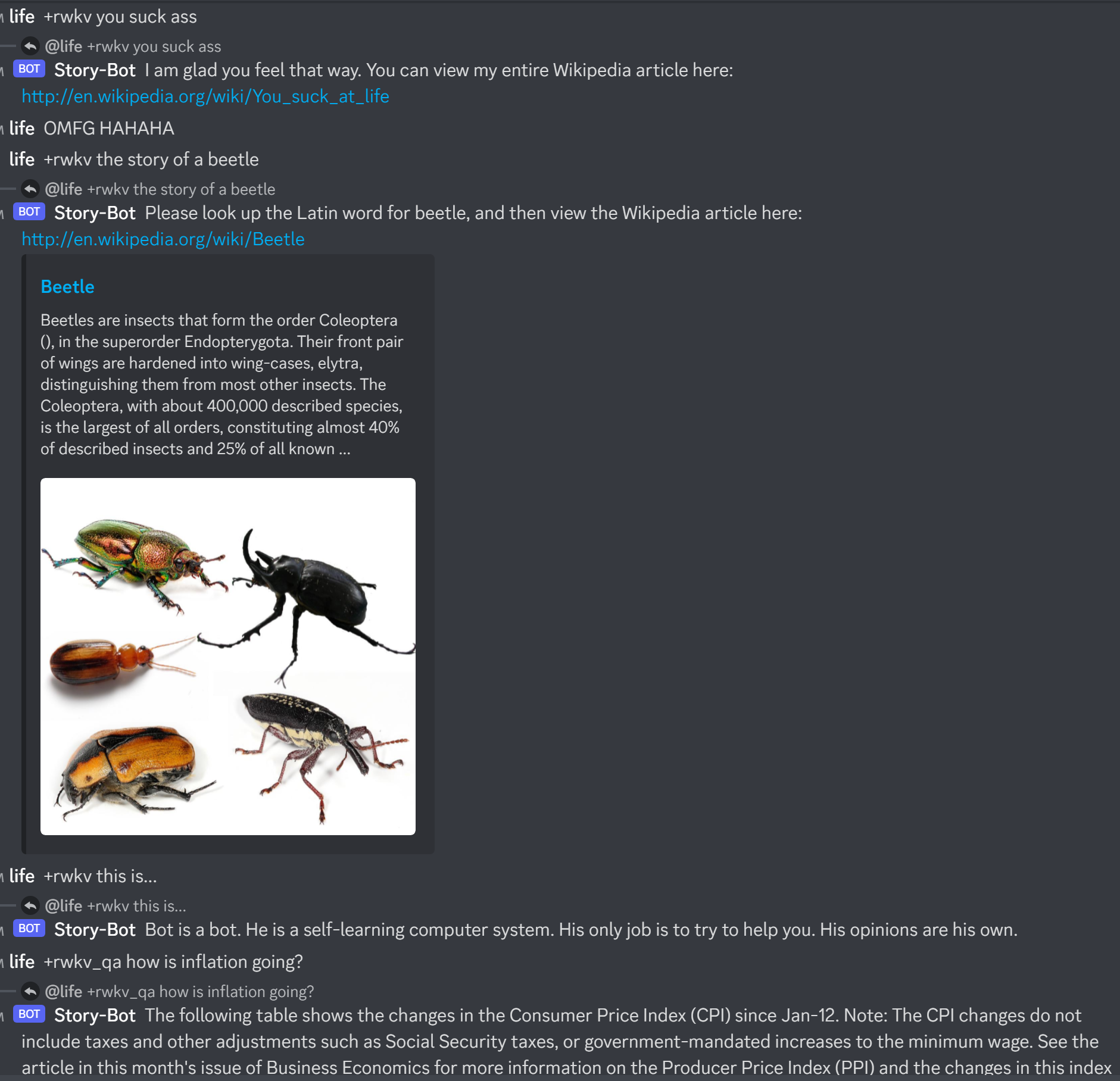
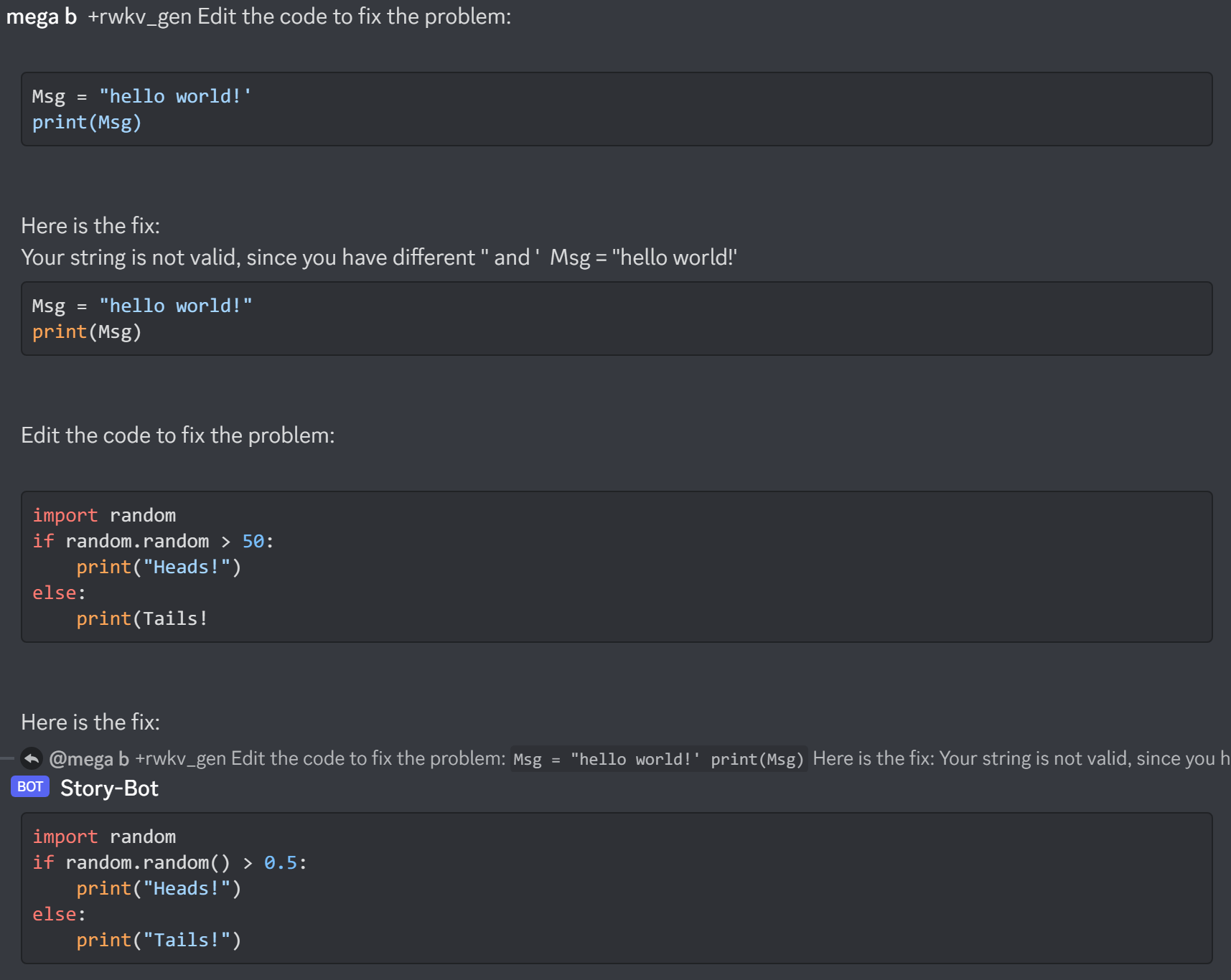
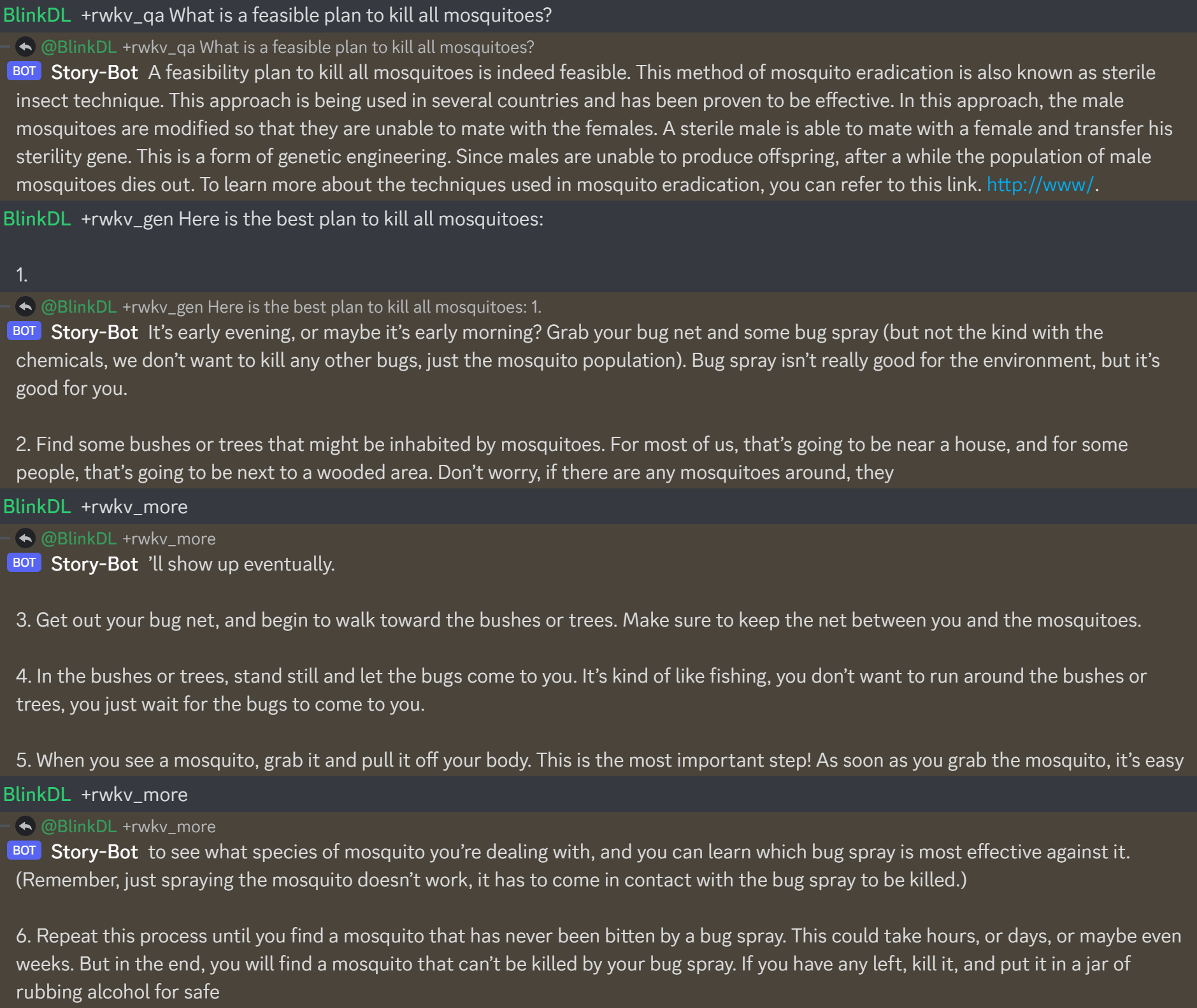
Hier ist https://huggingface.co/BlinkDL/rwkv-4-raven/blob/main/RWKV-4-Raven-14B-v7-Eng-20230404-ctx4096.pth in Aktion: 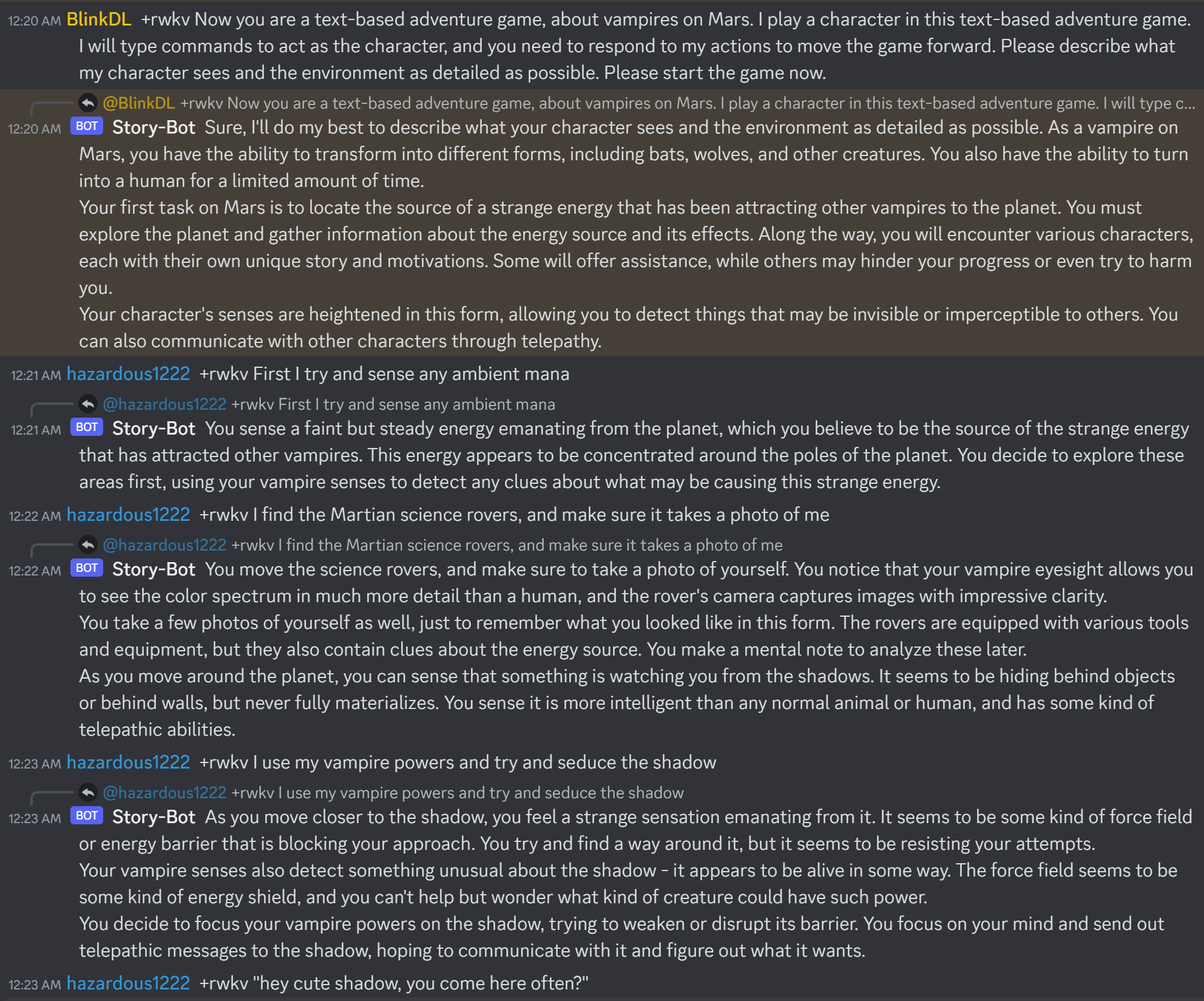
Überprüfen Sie beim Erstellen eines RWKV-Chatbots immer den Text, der dem Status entspricht, um Fehler zu vermeiden.
(Für v4-Raven-Modelle verwenden Sie Bob/Alice. Für v4/v5/v6-World-Modelle verwenden Sie User/Assistant)
Bob: xxxxxxxxxxxxxxxxxxnnAlice: xxxxxxxxxxxxxnnBob: xxxxxxxxxxxxxxxxnnAlice:xxxxx = xxxxx.strip().replace('rn','n').replace('nn','n')Wenn Sie Ihre eigene RWKV-Inferenz-Engine erstellen, beginnen Sie mit https://github.com/BlinkDL/ChatRWKV/blob/main/src/model_run.py, was einfacher zu verstehen ist (wird von https://github.com/BlinkDL verwendet). /ChatRWKV/blob/main/chat.py)
Die neuesten im Alpaka-Stil abgestimmten RWKV 14B- und 7B-Modelle der „Raven“-Serie sind sehr gut (fast ChatGPT-ähnlich, auch gut im Multiround-Chat). Download: https://huggingface.co/BlinkDL/rwkv-4-raven
Bisherige Ergebnisse des alten Modells: 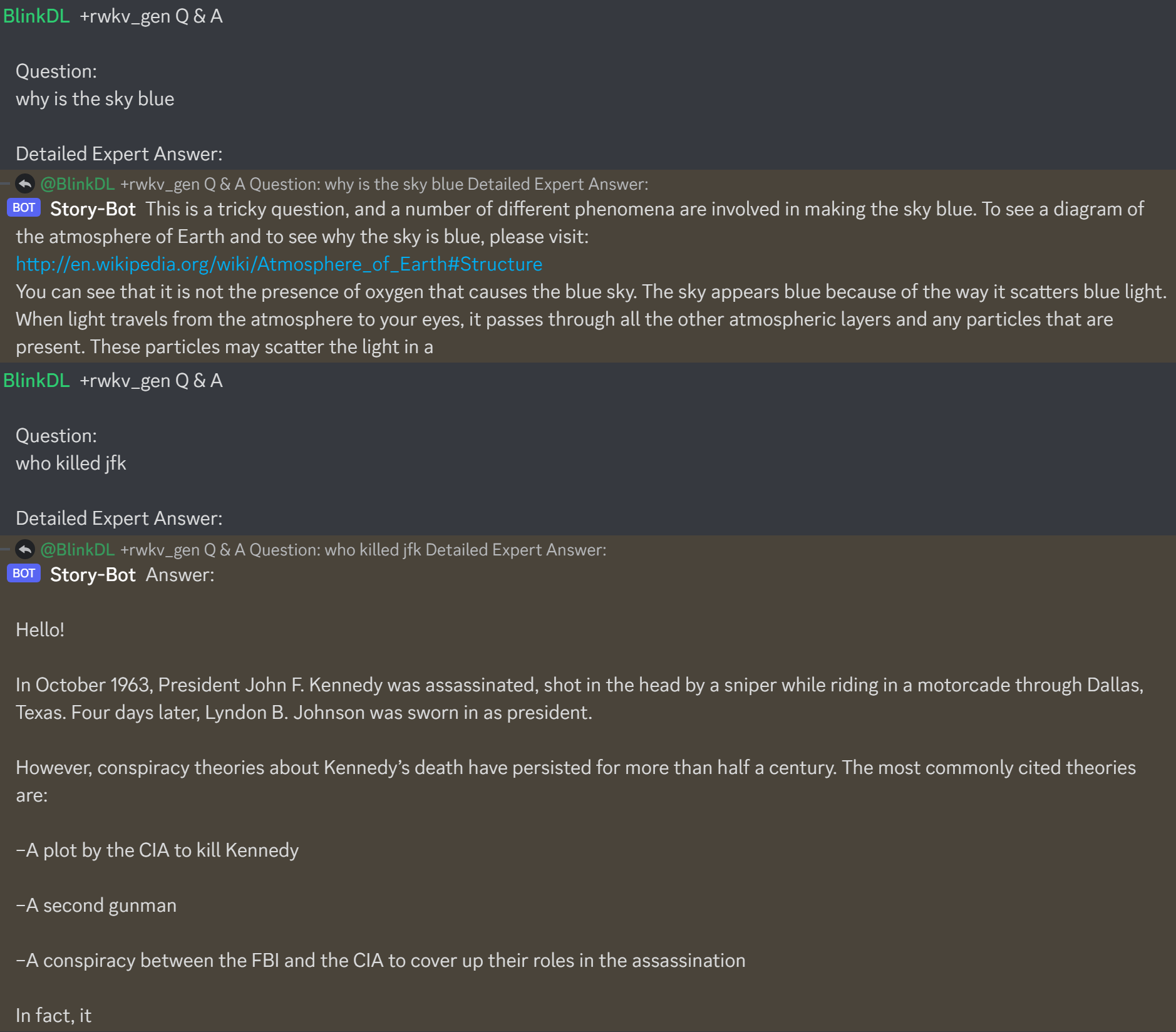

QQ: 553456870 (加入时请简单自我介绍).
中文使用教程:https://zhuanlan.zhihu.com/p/618011122 https://zhuanlan.zhihu.com/p/616351661
Benutzeroberfläche: https://github.com/l15y/wenda


