cambrian
1.0.0
Interessante Tatsache: Das Sehvermögen entstand bei Tieren im Kambrium! Dies war die Inspiration für den Namen unseres Projekts, Cambrian.
eval/ .dataengine/ .Derzeit unterstützen wir Schulungen zu TPU mit TorchXLA
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " Hier finden Sie unsere Kontrollpunkte im Kambrium sowie Anweisungen zur Verwendung der Gewichte. Unsere Modelle zeichnen sich in verschiedenen Dimensionen auf den Parameterebenen 8B, 13B und 34B aus. Sie zeigen in mehreren Benchmarks eine wettbewerbsfähige Leistung im Vergleich zu proprietären Closed-Source-Modellen wie GPT-4V, Gemini-Pro und Grok-1.4V.
| Modell | # Vis. Tok. | MMB | SQA-I | MathVistaM | ChartQA | MMVP |
|---|---|---|---|---|---|---|
| GPT-4V | UNK | 75,8 | - | 49.9 | 78,5 | 50,0 |
| Gemini-1.0 Pro | UNK | 73,6 | - | 45.2 | - | - |
| Gemini-1.5 Pro | UNK | - | - | 52.1 | 81,3 | - |
| Grok-1.5 | UNK | - | - | 52,8 | 76.1 | - |
| MM-1-8B | 144 | 72,3 | 72,6 | 35.9 | - | - |
| MM-1-30B | 144 | 75.1 | 81,0 | 39.4 | - | - |
| Basis-LLM: Phi-3-3.8B | ||||||
| Kambrium-1-8B | 576 | 74,6 | 79,2 | 48.4 | 66,8 | 40,0 |
| Basis-LLM: LLaMA3-8B-Instruct | ||||||
| Mini-Gemini-HD-8B | 2880 | 72,7 | 75.1 | 37,0 | 59.1 | 18.7 |
| LLaVA-NeXT-8B | 2880 | 72.1 | 72,8 | 36.3 | 69,5 | 38.7 |
| Kambrium-1-8B | 576 | 75,9 | 80,4 | 49,0 | 73,3 | 51.3 |
| Basis-LLM: Vicuna1.5-13B | ||||||
| Mini-Gemini-HD-13B | 2880 | 68,6 | 71.9 | 37,0 | 56,6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70,0 | 73,5 | 35.1 | 62.2 | 36,0 |
| Kambrium-1-13B | 576 | 75,7 | 79,3 | 48,0 | 73,8 | 41.3 |
| Basis-LLM: Hermes2-Yi-34B | ||||||
| Mini-Gemini-HD-34B | 2880 | 80,6 | 77,7 | 43.4 | 67,6 | 37.3 |
| LLaVA-NeXT-34B | 2880 | 79,3 | 81,8 | 46,5 | 68,7 | 47.3 |
| Kambrium-1-34B | 576 | 81,4 | 85,6 | 53.2 | 75,6 | 52,7 |
Die vollständige Tabelle finden Sie in unserem Cambrian-1-Artikel.
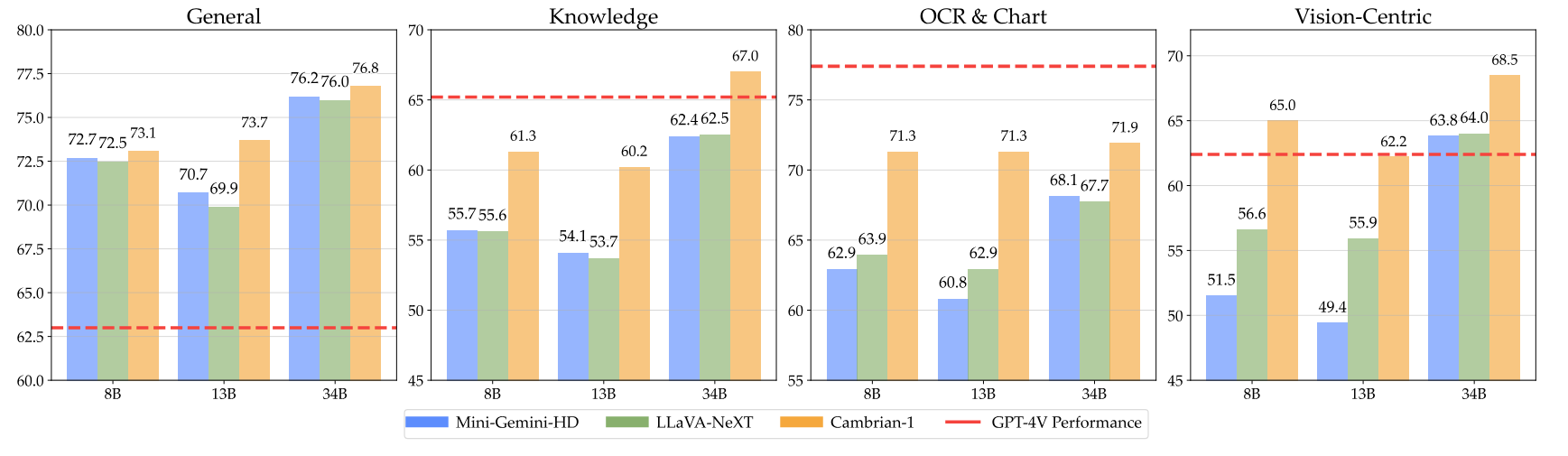
Unsere Modelle bieten eine äußerst wettbewerbsfähige Leistung und verwenden gleichzeitig eine kleinere feste Anzahl visueller Token.
Um die Modellgewichte zu verwenden, laden Sie sie von Hugging Face herunter:
Wir stellen in inference.py ein Beispielskript zum Laden und Generieren von Modellen bereit.

In dieser Arbeit sammeln wir einen sehr großen Pool an Instruktionsoptimierungsdaten, Cambrian-10M, für uns und zukünftige Arbeiten, um Daten beim Training von MLLMs zu untersuchen. In unserer Vorstudie filtern wir die Daten auf einen hochwertigen Satz von 7 Millionen kuratierten Datenpunkten herunter, den wir Cambrian-7M nennen. Beide Datensätze sind im folgenden Hugging Face-Datensatz verfügbar: Cambrian-10M.
Wir haben eine Vielzahl von Daten zur Optimierung visueller Anweisungen aus verschiedenen Quellen gesammelt, darunter VQA, visuelle Konversation und verkörperte visuelle Interaktion. Um qualitativ hochwertige, zuverlässige und umfangreiche Wissensdaten sicherzustellen, haben wir eine Internet Data Engine entwickelt.
Darüber hinaus haben wir beobachtet, dass VQA-Daten tendenziell sehr kurze Ausgaben erzeugen, was zu einer Verteilungsverschiebung gegenüber den Trainingsdaten führt. Um dieses Problem anzugehen, haben wir GPT-4v und GPT-4o genutzt, um erweiterte Antworten und kreativere Daten zu erstellen.
Um die Unzulänglichkeit wissenschaftsbezogener Daten zu beheben, haben wir eine Internet-Daten-Engine entwickelt, um zuverlässige wissenschaftsbezogene VQA-Daten zu sammeln. Mit dieser Engine können Daten zu jedem Thema gesammelt werden. Mit dieser Engine haben wir zusätzlich 161.000 wissenschaftsbezogene Datenpunkte zur Optimierung visueller Anweisungen gesammelt und damit die Gesamtdatenmenge in diesem Bereich um 400 % erhöht! Wenn Sie diesen Teil der Daten verwenden möchten, verwenden Sie bitte dieses JSONL.
Wir haben GPT-4v verwendet, um weitere 77.000 Datenpunkte zu erstellen. Diese Daten verwenden entweder GPT-4v, um die ursprüngliche, nur auf Antworten beschränkte VQA in längere Antworten mit detaillierteren Antworten umzuschreiben, oder es werden visuelle Anweisungsoptimierungsdaten basierend auf dem gegebenen Bild generiert. Wenn Sie diesen Teil der Daten verwenden möchten, verwenden Sie bitte dieses JSONL.
Wir haben GPT-4o verwendet, um weitere 60.000 kreative Datenpunkte zu erstellen. Diese Daten regen das Modell dazu an, sehr lange Antworten zu generieren und enthalten oft sehr kreative Fragen, wie zum Beispiel das Schreiben eines Gedichts, das Komponieren eines Liedes und mehr. Wenn Sie diesen Teil der Daten verwenden möchten, verwenden Sie bitte dieses JSONL.
Wir haben eine erste Studie zur Datenkuration durchgeführt von:
Empirisch haben wir diese Einstellung gefunden
| Kategorie | Datenverhältnis |
|---|---|
| Sprache | 21,00 % |
| Allgemein | 34,52 % |
| OCR | 27,22 % |
| Zählen | 8,71 % |
| Mathe | 7,20 % |
| Code | 0,87 % |
| Wissenschaft | 0,88 % |
Im Vergleich zum Vorgängermodell LLaVA-665K steigern die Skalierung und die verbesserte Datenkuratierung die Modellleistung erheblich, wie in der folgenden Tabelle dargestellt:
| Modell | Durchschnitt | Allgemeinwissen | OCR | Diagramm | Visionzentriert |
|---|---|---|---|---|---|
| LLaVA-665K | 40.4 | 64,7 | 45.2 | 20.8 | 31.0 |
| Kambrium-10M | 53,8 | 68,7 | 51.6 | 47.1 | 47,6 |
| Kambrium-7M | 54,8 | 69,6 | 52.6 | 47.3 | 49,5 |
Während das Training mit Cambrian-7M konkurrenzfähige Benchmark-Ergebnisse liefert, haben wir beobachtet, dass das Modell tendenziell kürzere Antworten ausgibt und wie eine Frage-Antwort-Maschine funktioniert. Dieses Verhalten, das wir als „Antwortmaschine“-Phänomen bezeichnen, kann die Nützlichkeit des Modells bei komplexeren Interaktionen einschränken.
Wir haben festgestellt, dass das Hinzufügen einer Systemaufforderung wie „Beantworten Sie die Frage mit einem einzelnen Wort oder einer einzelnen Phrase.“ kann helfen, das Problem zu lindern. Dieser Ansatz ermutigt das Modell, solch prägnante Antworten nur dann zu liefern, wenn dies kontextuell angemessen ist. Weitere Einzelheiten finden Sie in unserem Dokument.
Wir haben auch einen Datensatz, Cambrian-7M mit Systemeingabeaufforderung, kuratiert, der die Systemeingabeaufforderung enthält, um die Kreativität und Chatfähigkeit des Modells zu verbessern.
Nachfolgend finden Sie die neueste Trainingskonfiguration für Cambrian-1.
Im Cambrian-1-Artikel führen wir umfangreiche Studien durch, um die Notwendigkeit einer zweistufigen Ausbildung zu belegen. Das Cambrian-1-Training besteht aus zwei Phasen:
Cambrian-1 wird auf TPU-V4-512 trainiert, kann aber auch auf TPUs ab TPU-V4-64 trainiert werden. Der GPU-Trainingscode wird bald veröffentlicht. Reduzieren Sie für das GPU-Training auf weniger GPUs die per_device_train_batch_size und erhöhen Sie die gradient_accumulation_steps entsprechend, um sicherzustellen, dass die globale Stapelgröße gleich bleibt: per_device_train_batch_size x gradient_accumulation_steps x num_gpus .
Beide Hyperparameter, die beim Vortraining und bei der Feinabstimmung verwendet werden, sind unten aufgeführt.
| Basis-LLM | Globale Batchgröße | Lernrate | SVA-Lernrate | Epochen | Maximale Länge |
|---|---|---|---|---|---|
| LLaMA-3 8B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Vicuna-1,5 13B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Hermes Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048 |
| Basis-LLM | Globale Batchgröße | Lernrate | Epochen | Maximale Länge |
|---|---|---|---|---|
| LLaMA-3 8B | 512 | 4e-5 | 1 | 2048 |
| Vicuna-1,5 13B | 512 | 4e-5 | 1 | 2048 |
| Hermes Yi-34B | 1024 | 2e-5 | 1 | 2048 |
Zur Feinabstimmung der Anweisungen haben wir Experimente durchgeführt, um die optimale Lernrate für unser Modelltraining zu ermitteln. Basierend auf unseren Erkenntnissen empfehlen wir die Verwendung der folgenden Formel, um Ihre Lernrate an die Verfügbarkeit Ihres Geräts anzupassen:
optimal lr = base_lr * sqrt(bs / base_bs)
So erhalten Sie das Basis-LLM und trainieren die Modelle 8B, 13B und 34B:
Wir verwenden eine Kombination aus LLaVA-, ShareGPT4V-, Mini-Gemini- und ALLaVA-Ausrichtungsdaten, um unseren visuellen Konnektor (SVA) vorab zu trainieren. Im Kambrium-1 führen wir umfangreiche Studien durch, um die Notwendigkeit und den Nutzen der Verwendung zusätzlicher Ausrichtungsdaten aufzuzeigen.
Weitere Informationen finden Sie zunächst auf unserer Datenseite zur Ausrichtung des Hugging Face. Sie können die Ausrichtungsdaten über die folgenden Links herunterladen:
Wir bieten Beispielschulungsskripte in:
Wenn Sie mit anderen Datenquellen oder benutzerdefinierten Daten trainieren möchten, unterstützen wir das häufig verwendete LLaVA-Datenformat. Für die Verarbeitung sehr großer Dateien verwenden wir das JSONL-Format anstelle des JSON-Formats für verzögertes Laden von Daten, um die Speichernutzung zu optimieren.
Ähnlich wie bei Training SVA besuchen Sie bitte unsere Cambrian-10M-Daten für weitere Details zu den Instruktions-Tuning-Daten.
Wir bieten Beispielschulungsskripte in:
--mm_projector_type : Um unser SVA-Modul zu verwenden, setzen Sie diesen Wert auf sva . Um den 2-Schicht-MLP-Projektor im LLaVA-Stil zu verwenden, legen Sie diesen Wert auf mlp2x_gelu fest.--vision_tower_aux_list : Die Liste der zu verwendenden Vision-Modelle (z. B. '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' ).--vision_tower_aux_token_len_list : Die Liste der Anzahl der Vision-Tokens für jeden Vision-Turm; Jede Zahl sollte eine Quadratzahl sein (z. B. '[576, 576, 576, 9216]' ). Die Merkmalskarte jedes Aussichtsturms wird interpoliert, um dieser Anforderung gerecht zu werden.--image_token_len : Die endgültige Anzahl der Vision-Tokens, die LLM bereitgestellt werden; Die Zahl sollte eine Quadratzahl sein (z. B. 576 ). Beachten Sie, dass, wenn mm_projector_type mlp ist, jede Zahl in vision_tower_aux_token_len_list mit image_token_len identisch sein muss. Die folgenden Argumente sind nur für den SVA-Projektor von Bedeutung--num_query_group : Der G Wert für das SVA-Modul.--query_num_list : Eine Liste von Abfragenummern für jede Abfragegruppe in SVA (z. B. '[576]' ). Die Länge der Liste sollte num_query_group entsprechen.--connector_depth : Der D Wert für das SVA-Modul.--vision_hidden_size : Die versteckte Größe für das SVA-Modul.--connector_only : Wenn true, erscheint das SVA-Modul nur vor dem LLM, andernfalls wird es mehrmals innerhalb des LLM eingefügt. Die folgenden drei Argumente sind nur dann sinnvoll, wenn dies auf False gesetzt ist.--num_of_vision_sampler_layers : Die Gesamtzahl der im LLM eingefügten SVA-Module.--start_of_vision_sampler_layers : Der LLM-Layer-Index, nach dem das Einfügen von SVA beginnt.--stride_of_vision_sampler_layers : Der Schritt der SVA-Moduleinfügung innerhalb des LLM. Wir haben unseren Evaluierungscode im Unterordner eval/ veröffentlicht. Weitere Informationen finden Sie in der README-Datei.
Die folgenden Anweisungen führen Sie durch den Start einer lokalen Gradio-Demo mit Cambrian. Wir stellen Ihnen eine einfache Weboberfläche zur Verfügung, über die Sie mit dem Modell interagieren können. Sie können die CLI auch für Rückschlüsse verwenden. Dieses Setup ist stark von LLaVA inspiriert.
Bitte befolgen Sie die folgenden Schritte, um eine lokale Gradio-Demo zu starten. Ein Diagramm des lokalen Bereitstellungscodes finden Sie unten 1 .
%%{init: {"theme": "base"}}%%
Flussdiagramm BT
%% Knoten deklarieren
Stil gws-Füllung:#f9f,Strich:#333,Strichbreite:2px
Stil c Füllung:#bbf,Strich:#333,Strichbreite:2px
Stil mw8b Füllung:#aff,Strich:#333,Strichbreite:2px
Stil mw13b Füllung:#aff,Strich:#333,Strichbreite:2px
%% Stil sglw13b Füllung:#ffa,Strich:#333,Strichbreite:2px
%% Stil lsglw13b Füllung:#ffa,Strich:#333,Strichbreite:2px
gws["Gradio (UI-Server)"]
c["Controller (API-Server):<br/>PORT: 10000"]
mw8b["Model Worker:<br/><b>Cambrian-1-8B</b><br/>PORT: 40000"]
mw13b["Modellarbeiter:<br/><b>Cambrian-1-13B</b><br/>HAFEN: 40001"]
%% sglw13b["SGLang Backend:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["SGLang Worker:<br/><b>Cambrian-1-34B<b><br/>PORT: 40002"]
Unterabschnitt „Demo-Architektur“
Richtung BT
c <--> gws
mw8b <--> c
mw13b <--> c
%% lsglw13b <--> c
%% sglw13b <--> lsglw13b
Ende
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadSie haben gerade die Gradio-Weboberfläche gestartet. Jetzt können Sie die Weboberfläche mit der auf dem Bildschirm angezeigten URL öffnen. Möglicherweise stellen Sie fest, dass in der Modellliste kein Modell vorhanden ist. Machen Sie sich keine Sorgen, wir haben noch keinen Model Worker eingeführt. Es wird automatisch aktualisiert, wenn Sie einen Modellarbeiter starten.
Kommt bald.
Dies ist der eigentliche Worker , der die Inferenz auf der GPU durchführt. Jeder Worker ist für ein einzelnes Modell verantwortlich, das in --model-path angegeben ist.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bWarten Sie, bis der Vorgang das Laden des Modells abgeschlossen hat und „Uvicorn läuft auf ...“ angezeigt wird. Aktualisieren Sie nun Ihre Gradio-Web-Benutzeroberfläche und Sie sehen das gerade gestartete Modell in der Modellliste.
Sie können so viele Worker starten, wie Sie möchten, und verschiedene Modellprüfpunkte in derselben Gradio-Benutzeroberfläche vergleichen. Bitte behalten Sie den --controller bei und ändern Sie --port und --worker für jeden Worker auf eine andere Portnummer.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> Wenn Sie ein Apple-Gerät mit einem M1- oder M2-Chip verwenden, können Sie das MPS-Gerät mithilfe des Flags --device angeben: --device mps .
Wenn der VRAM Ihrer GPU weniger als 24 GB beträgt (z. B. RTX 3090, RTX 4090 usw.), können Sie versuchen, ihn mit mehreren GPUs auszuführen. Unsere neueste Codebasis versucht automatisch, mehrere GPUs zu verwenden, wenn Sie mehr als eine GPU haben. Mit CUDA_VISIBLE_DEVICES können Sie angeben, welche GPUs verwendet werden sollen. Nachfolgend finden Sie ein Beispiel für die Ausführung mit den ersten beiden GPUs.
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bTODO
Wenn Sie Kambrium für Ihre Forschung und Anwendungen nützlich finden, zitieren Sie bitte mit diesem BibTeX:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
Nutzungs- und Lizenzhinweise : Dieses Projekt nutzt bestimmte Datensätze und Kontrollpunkte, die ihren jeweiligen Originallizenzen unterliegen. Benutzer müssen alle Bedingungen dieser Originallizenzen einhalten, einschließlich, aber nicht beschränkt auf die OpenAI-Nutzungsbedingungen für den Datensatz und die spezifischen Lizenzen für Basissprachenmodelle für Kontrollpunkte, die mit dem Datensatz trainiert wurden (z. B. Llama-Community-Lizenz für LLaMA-3, und Vicuna-1.5). Dieses Projekt erlegt keine zusätzlichen Einschränkungen auf, die über die in den ursprünglichen Lizenzen festgelegten hinausgehen. Darüber hinaus werden Benutzer daran erinnert, sicherzustellen, dass die Nutzung des Datensatzes und der Kontrollpunkte im Einklang mit allen geltenden Gesetzen und Vorschriften erfolgt.
Kopiert aus dem Diagramm von LLaVA. ↩


