llm chatbot rag
1.0.0
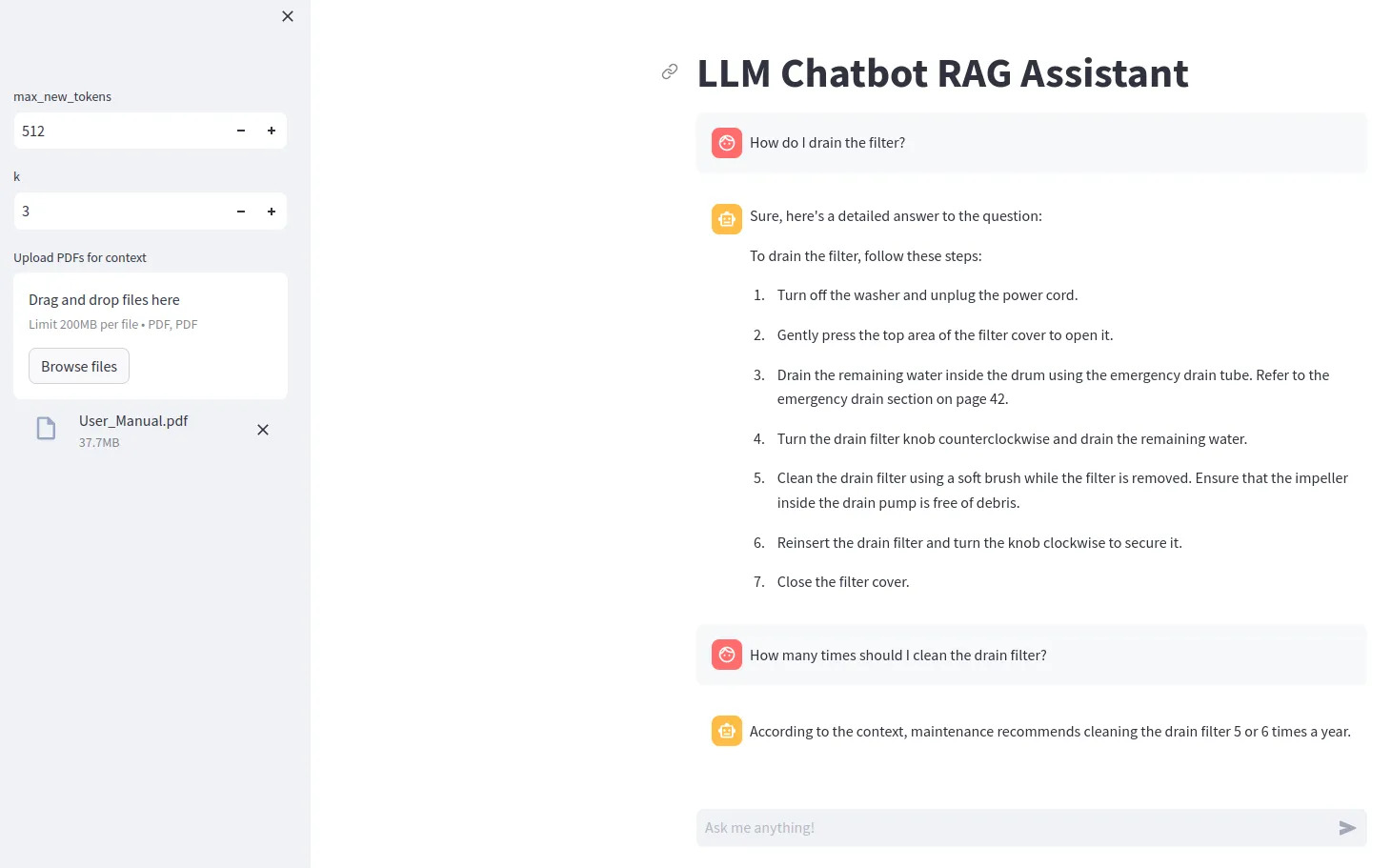
Um bestimmte LLM-Modelle (z. B. Gemma) zu verwenden, müssen Sie eine .env-Datei erstellen, die die Zeile ACCESS_TOKEN=<your hugging face token> enthält
Installieren Sie Abhängigkeiten mit pip install -r requirements.txt
Mit streamlit run src/app.py ausführen
Um die Bitsandbytes-Quantisierung nutzen zu können, ist eine Nvidia-GPU erforderlich. Stellen Sie sicher, dass Sie zuerst das NVIDIA Toolkit und dann PyTorch installieren.
Sie können mit überprüfen, ob Ihre GPU in Python verfügbar ist
import torch
print(torch.cuda.is_available())
Wenn Sie keine kompatible GPU haben, versuchen Sie device="cpu" für das Modell festzulegen und die Quantisierungskonfiguration zu entfernen.


