Synonyms
Synonyms
Chinesische Synonyme für die Verarbeitung und das Verstehen natürlicher Sprache.
Bessere chinesische Synonyme: Chatbot, intelligentes Frage- und Antwort-Toolkit.
synonyms können für viele Aufgaben beim Verstehen natürlicher Sprache verwendet werden: Textausrichtung, Empfehlungsalgorithmen, Ähnlichkeitsberechnungen, semantischer Offset, Schlüsselwortextraktion, Konzeptextraktion, automatische Zusammenfassung, Suchmaschinen usw.
Um stabile, zuverlässige und langfristig optimierte Dienste bereitzustellen, hat Synonyms auf die Verwendung der Chunsong-Lizenz v1.0 umgestellt und Gebühren für das Herunterladen von Modellen für maschinelles Lernen erhoben. Weitere Informationen finden Sie im Zertifikatspeicher. Frühere Mitwirkende (Code-Mitwirkende mit herausragenden Beiträgen) können uns kontaktieren, um Gebührenprobleme zu besprechen. – Chatopera Inc. @ Okt. 2023
Führen Sie die folgenden Schritte aus, um Pakete zu installieren und zu aktivieren.
pip install -U synonymsDie aktuelle stabile Version ist v3.x.
Für die Modellpakete für maschinelles Lernen von Synonyms ist eine Lizenz vom Chatopera License Store erforderlich. Kaufen Sie zunächst eine Lizenz und rufen Sie die license id auf der Seite „Lizenzen“ im Chatopera License Store ab ( license id : Klicken Sie im Zertifikatspeicher auf der Seite mit den Zertifikatdetails auf [Kopieren Zertifikatsidentität] ).
Zweitens legen Sie die Umgebungsvariable in Ihren Terminal- oder Shell-Skripten wie unten beschrieben fest.
zB Shell, CMD-Skripte unter Linux, Windows, macOS.
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE 'Jupyter-Notizbuch usw.
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )
Tipp: Die Word-Vektordatei wird zum ersten Mal nach der Installation heruntergeladen und die Download-Geschwindigkeit hängt von den Netzwerkbedingungen ab.
Laden Sie zuletzt das Modellpaket per Befehl oder Skript herunter.
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
Unterstützt die Verwendung von Umgebungsvariablen zum Konfigurieren des Wortsegmentierungsvokabulars und von Word2vec-Wortvektordateien.
| Umgebungsvariablen | beschreiben |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | Word-Vektordatei, trainiert mit Word2vec, Binärformat. |
| SYNONYMS_WORDSEG_DICT | Hauptwörterbuch zur chinesischen Wortsegmentierung, Format- und Verwendungsreferenz |
| SYNONYMS_DEBUG | ["TRUE"|"FALSE"], ob Debug-Protokolle ausgegeben werden sollen, auf "TRUE"-Ausgabe gesetzt, der Standardwert ist "FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE]) gibt ein Tupel zurück: ([nearby_words], [nearby_words_score]) nearby_words werden ebenfalls in Form einer Liste gespeichert und basieren auf Die Längen sind von nah nach fern angeordnet. nearby_words_score ist der Wert des Abstands zwischen den Wörtern an der entsprechenden Position in nearby_words . Je näher er an 1 liegt, desto näher ist SIZE der Anzahl der zurückgegebenen Wörter Der Standardwert ist 10. Zum Beispiel:
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) Im Falle von OOV wird ([], []) zurückgegeben, aktuelle Wörterbuchgröße: 435.729.
Vergleich der Ähnlichkeit zwischen zwei Sätzen
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )Unter diesen gibt der Parameter seg an, ob synonyme.compare eine Wortsegmentierung für sen1 und sen2 durchführt, und der Standardwert ist True. Rückgabewert: [0-1], und je näher er an 1 liegt, desto ähnlicher sind die beiden Sätze.
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0 Gibt Synonyme auf benutzerfreundliche Weise aus, um das Debuggen zu erleichtern. display(WORD [, SIZE]) ruft synonyms#nearby auf.
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE ist die Anzahl der gedruckten Vokabellisten, der Standardwert ist 10.
Drucken Sie die Beschreibungsinformationen des aktuellen Pakets aus:
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
Rufen Sie einen Wortvektor ab, der ein Numpy-Array ist. Wenn das Wort ein nicht registriertes Wort ist, wird eine KeyError-Ausnahme ausgelöst.
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )Erhalten Sie einen Vektor des Satzes nach der Wortsegmentierung. Der Vektor wird im BoW-Modus erstellt.
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量Chinesische Wortsegmentierung
synonyms . seg ( "中文近义词工具包" )Das Ergebnis der Wortsegmentierung ist ein Tupel, das aus zwei Listen besteht, bei denen es sich um Wörter und entsprechende Wortarten handelt.
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])Dieses Partizip entfernt keine Stoppwörter und Satzzeichen.
Schlüsselwörter extrahieren Standardmäßig werden Schlüsselwörter nach Wichtigkeit extrahiert.
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
Weitere Protokolle zum Debuggen abrufen, Umgebungsvariable festlegen.
SYNONYMS_DEBUG=TRUE
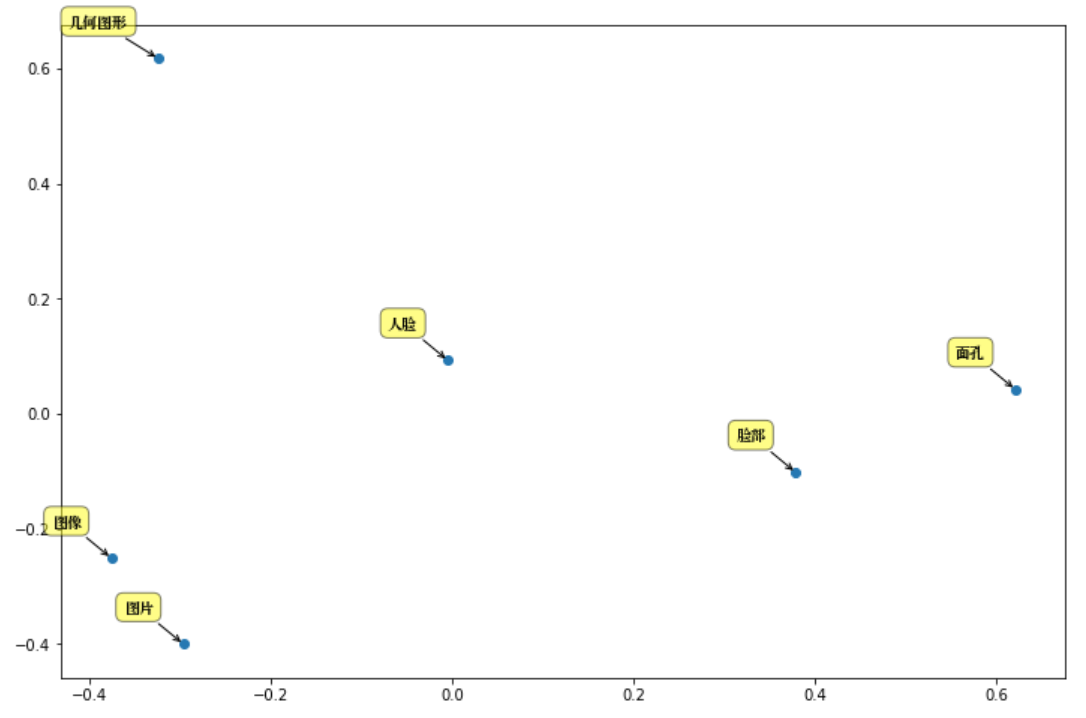
Am Beispiel des „menschlichen Gesichts“ werden die Hauptkomponenten analysiert:
$ pip install -r Requirements.txt
$ python demo.pyAktualisierte Statuserklärung.
Was Benutzer sagen:
Die Daten basieren auf dem Wikidata-Korpus.
„Synonyms Cilin“ wurde 1983 von Mei Jiaju und anderen zusammengestellt. Die heute am weitesten verbreitete Version ist „Synonyms Cilin Expanded Edition“, die vom Social Computing and Information Retrieval Research Center des Harbin Institute of Technology verwaltet wird. Sie unterteilt den chinesischen Wortschatz fein in große Teile Kategorien und Unterkategorien ordnen die Beziehung zwischen Wörtern. Die erweiterte Version von Synonyms Cilin enthält mehr als 70.000 Wörter, von denen mehr als 30.000 in Form offener Daten geteilt werden.
HowNet, auch bekannt als HowNet, ist nicht nur ein semantisches Wörterbuch, sondern ein Wissenssystem. Die Beziehung zwischen Wörtern ist eines seiner grundlegenden Verwendungsszenarien. CNKI enthält mehr als 8 Wörter.
Der internationale Bewertungsstandard für Wortähnlichkeitsalgorithmen übernimmt im Allgemeinen den manuellen Beurteilungswert des von Miller & Charles veröffentlichten englischen Wortpaarsatzes. Der Wortpaarsatz besteht aus zehn Paaren stark verwandter, zehn Paaren mäßig verwandter und zehn Paaren gering verwandter englischer Wortpaare. Anschließend werden 38 Probanden gebeten, die semantische Relevanz dieser 30 Paare zu beurteilen und schließlich ihren Durchschnitt zu ermitteln Der Wert dient als manuelles Kriterium. Anschließend bewerten verschiedene Synonymtools auch die Ähnlichkeit dieser Wörter und vergleichen sie mit manuellen Beurteilungskriterien, beispielsweise mithilfe des Pearson-Korrelationskoeffizienten. Im chinesischen Bereich ist es auch eine gängige Methode, die übersetzte Version dieser Vokabelliste zum Vergleich chinesischer Synonyme zu verwenden.
Die Vokabelliste der Synonyme beträgt 435.729. Nachfolgend wählen wir einige Wörter aus, die in den Synonymen Cilin, CNKI und Synonymen vorkommen, um ihre Ähnlichkeit zu vergleichen:
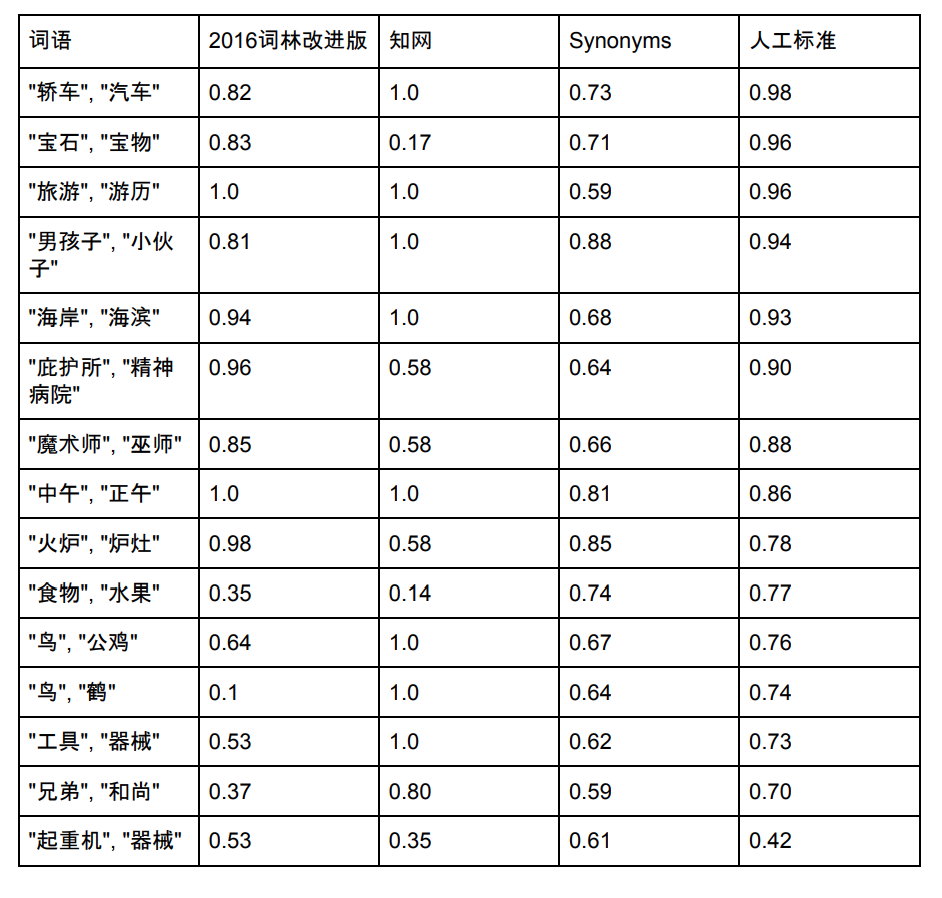
Hinweis: Quellen für Synonym Forest- und CNKI-Daten und -Scores. Synonyme werden ebenfalls ständig optimiert und die neuen Bewertungen stimmen möglicherweise nicht mit dem Bild oben überein.
Weitere Vergleichsergebnisse.
Github-assoziierte Benutzerliste
Testen Sie mit py3, MacBook Pro.
python benchmark.py
++++++++++ Betriebssystemname und Version ++++++++++
Plattform: Darwin
Kernel: 16.7.0
Architektur: ('64bit', '')
++++++++++ CPU-Kerne ++++++++++
Kerne: 4
CPU-Last: 60
++++++++++ Systemspeicher ++++++++++
Meminfo 8 GB
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
Herzstück der Maschine
Online-Sharing-Datensatz: Synonyme Chinesisch-Synonym-Toolkit @ 07.02.2018
Synonyme veröffentlicht Zertifikat MIT. Daten und Verfahren dürfen in der Forschung und in kommerziellen Produkten verwendet werden und müssen zitiert und angesprochen werden, beispielsweise in allen veröffentlichten Medien, Zeitschriften, Magazinen oder Blogs.
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
Wikidata-Korpus
Ableitung des Word2vec-Prinzips und Codeanalyse
Nicht unterstützt, siehe Nr. 5 für weitere Informationen
Word2vec wurde von Google veröffentlicht. Diese Bibliothek ist in C-Sprache geschrieben, weist eine hohe Speichernutzungseffizienz und eine schnelle Trainingsgeschwindigkeit auf. Gensim kann von word2vec ausgegebene Modelldateien laden.
Weitere Informationen finden Sie unter Nr. 64
Hai Liang Wang
Hu Yingxi
Dieses Buch wurde von Synonyms-Autoren mitverfasst.
Link zum schnellen Buchkauf 
„Intelligente Fragebeantwortung und Deep Learning“ Dieses Buch richtet sich an Studenten und Softwareentwickler, die sich auf den Einstieg in maschinelles Lernen und die Verarbeitung natürlicher Sprache vorbereiten. Es stellt viele Prinzipien und Algorithmen in der Theorie vor und bietet auch viele Beispielprogramme, um sie praktischer zu machen Diese Programme sind in der Beispielprogrammcode-Bibliothek zusammengefasst und dienen vor allem dazu, die Prinzipien und Algorithmen zu verstehen. Sie können sie gerne herunterladen und ausführen. Die Adresse der Codebasis lautet:
https://github.com/l11x0m7/book-of-qna-code
Word2vec von Google
Wikimedia: Quelle des Trainingskorpus
gensim: word2vec.py
SentenceSim: Ähnlichkeitsbewertungskorpus
jieba: Chinesische Wortsegmentierung
Chunsong Public License, Version 1.0
https://bot.chatopera.com/
Der Chatopera-Cloud-Service ist ein One-Stop-Cloud-Service für die Implementierung von Chat-Robotern und wird auf Basis der Anzahl der Schnittstellenaufrufe abgerechnet. Chatopera Cloud Service ist eine Software-as-a-Service-Instanz der Chatopera-Bot-Plattform. Basierend auf Cloud Computing ist der Chatopera-Clouddienst ein Chatbot-as-a-Service -Clouddienst.
Die Chatopera-Roboterplattform umfasst Komponenten wie Wissensdatenbank, Mehrrundendialog, Absichtserkennung und Spracherkennung, standardisierte Chat-Roboter-Entwicklung und unterstützt Szenarien wie intelligente Fragen und Antworten für Unternehmens-OA, intelligente Fragen und Antworten für die Personalabteilung, intelligenten Kundenservice und Online-Marketing. IT-Abteilungen und Geschäftsabteilungen von Unternehmen nutzen die Cloud-Dienste von Chatopera, um Chatbots schnell online zu bringen!


