msg_reply
1.0.0
Haben Sie schon einmal Google Smart Reply gesehen oder verwendet? Dabei handelt es sich um einen Dienst, der automatische Antwortvorschläge für Benutzernachrichten bereitstellt. Siehe unten.
Dies ist eine nützliche Anwendung des abrufbasierten Chatbots. Denken Sie darüber nach. Wie oft schreiben wir eine SMS wie „Danke“ , „Hey“ oder „Bis später“ ? In diesem Projekt erstellen wir ein einfaches Vorschlagssystem für Nachrichtenantworten.
Kyubyong-Park
Code-Review von Yj Choe
Wir müssen die Liste der anzuzeigenden Vorschläge festlegen. Natürlich wird zuerst die Häufigkeit berücksichtigt. Aber was ist mit den Sätzen, deren Bedeutung ähnlich ist? Sollten zum Beispiel „Vielen Dank“ und „Danke“ unabhängig behandelt werden? Das glauben wir nicht. Wir wollen sie gruppieren und unsere Slots speichern. Wie? Wir nutzen einen Parallelkorpus. Vielen Dank und Danke werden wahrscheinlich in den gleichen Text übersetzt. Basierend auf dieser Annahme konstruieren wir englische Synonymgruppen, die dieselbe Übersetzung haben.
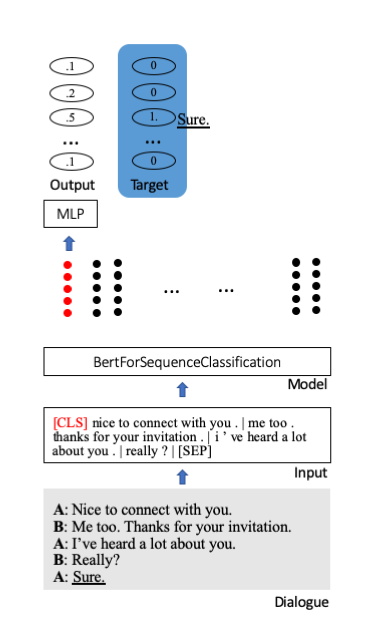
Wir optimieren das von Bert vorab trainierte Huggingface-Modell für die Sequenzklassifizierung. Darin speichert ein spezieller Starttoken [CLS] die gesamten Informationen eines Satzes. Um die verdichteten Informationen auf Klassifikationseinheiten (hier 100) zu projizieren, werden zusätzliche Schichten angebracht.
Wir verwenden das Spanisch-Englisch-Parallelkorpus von OpenSubtitles 2018, um Synonymgruppen zu erstellen. OpenSubtitles ist eine große Sammlung übersetzter Filmuntertitel. Die en-es-Daten bestehen aus mehr als 61 Millionen ausgerichteten Linien.
Idealerweise wird für das Training ein (sehr) großes Dialogkorpus benötigt, das wir nicht finden konnten. Wir verwenden stattdessen das Cornell Movie Dialogue Corpus. Es besteht aus 83.097 Dialogen oder 304.713 Zeilen.
Python>=3.6
tqdm>=4.30.0
pytorch>=1.0
pytorch_pretrained_bert>=0.6.1
nltk>=3,4
SCHRITT 0. Laden Sie die parallelen Daten von OpenSubtitles 2018 Spanisch-Englisch herunter.
bash download.sh
SCHRITT 1. Konstruieren Sie Synonymgruppen aus dem Korpus.
python construct_sg.py
SCHRITT 2. Erstellen Sie die Wörterbücher phr2sg_id und sg_id2phr.
python make_phr2sg_id.py
SCHRITT 3. Konvertieren Sie einen einsprachigen englischen Text in IDs.
python encode.py
SCHRITT 4. Trainingsdaten erstellen und als Pickle speichern.
python prepro.py
SCHRITT 5. Trainieren.
python train.py
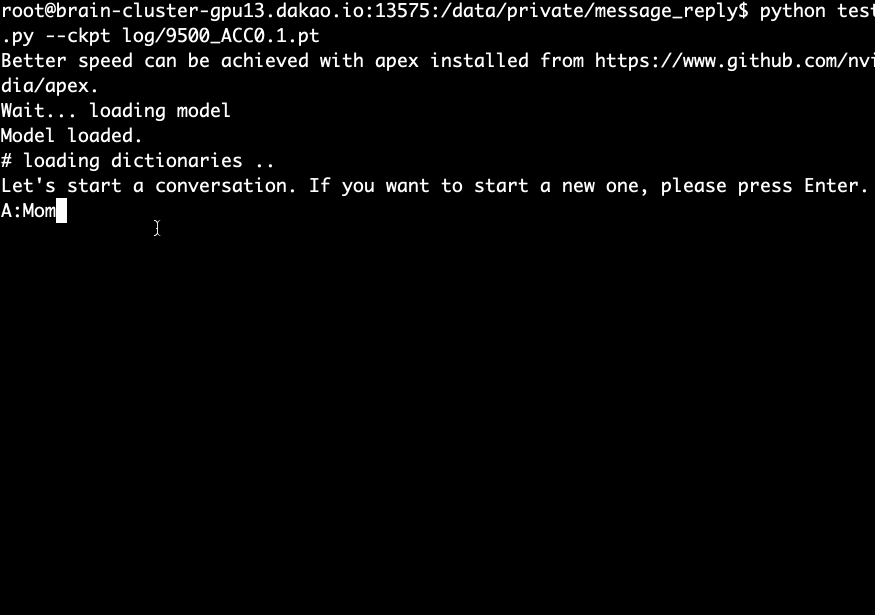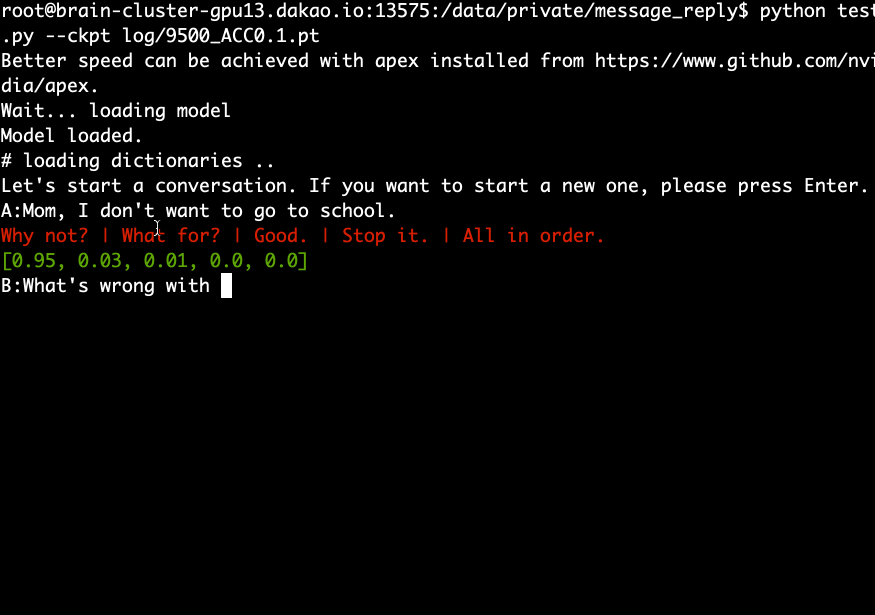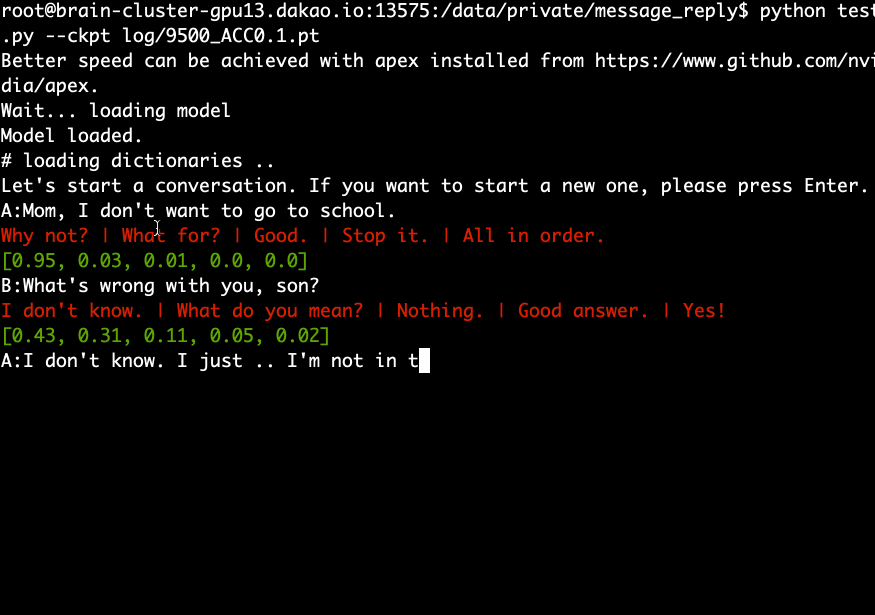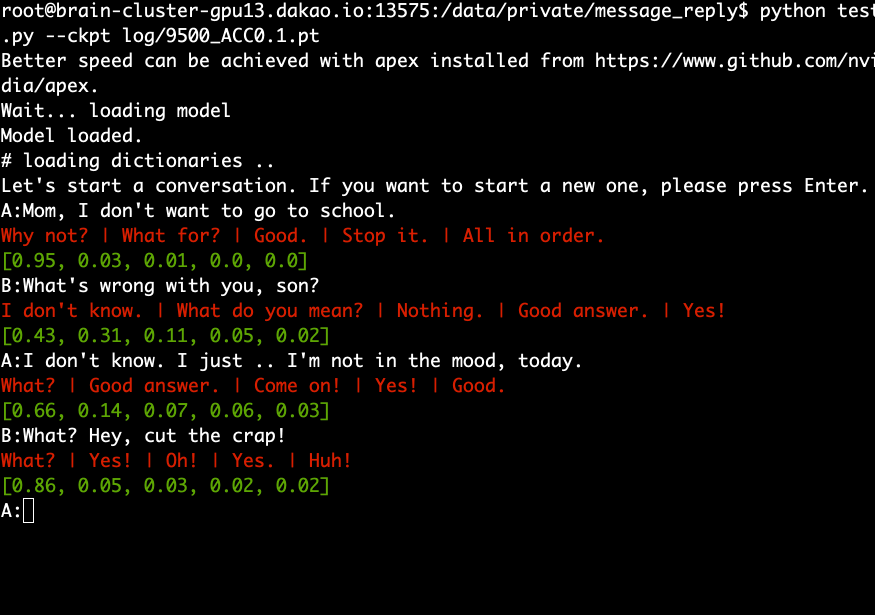
Laden Sie das vorab trainierte Modell herunter, extrahieren Sie es und führen Sie den folgenden Befehl aus.
python test.py --ckpt log/9500_ACC0.1.pt
Der Trainingsverlust nimmt langsam, aber stetig ab.
Die Genauigkeit@5 der Auswertungsdaten liegt zwischen 10 und 20 Prozent.
Für eine reale Anwendung ist ein viel größerer Korpus erforderlich.
Ich bin mir nicht sicher, inwieweit Filmdrehbücher den Nachrichtendialogen ähneln.
Eine bessere Strategie zum Aufbau von Synonymgruppen ist erforderlich.
Ein abrufbasierter Chatbot ist eine realistische Anwendung, da er sicherer und einfacher ist als ein generationsbasierter.


