ThinkRAG
1.0.0
Englisch |. Vereinfachtes Chinesisch
Das ThinkRAG-System zur Generierung großer Modellabrufverbesserungen kann problemlos auf einem Laptop bereitgestellt werden, um eine intelligente Beantwortung von Fragen in einer lokalen Wissensdatenbank zu realisieren.
Das System basiert auf LlamaIndex und Streamlit und wurde in vielen Bereichen wie Modellauswahl und Textverarbeitung für Privatanwender optimiert.
ThinkRAG ist ein großes Modellanwendungssystem, das für Fachleute, Forscher, Studenten und andere Wissensarbeiter entwickelt wurde. Es kann direkt auf Laptops verwendet werden und die Wissensdatenbankdaten werden lokal auf dem Computer gespeichert.
ThinkRAG verfügt über die folgenden Funktionen:
Insbesondere hat ThinkRAG auch zahlreiche Anpassungen und Optimierungen für inländische Benutzer vorgenommen:
ThinkRAG kann alle vom LlamaIndex-Datenrahmen unterstützten Modelle verwenden. Informationen zur Modellliste finden Sie in der entsprechenden Dokumentation.
ThinkRAG hat sich zum Ziel gesetzt, ein Anwendungssystem zu schaffen, das direkt nutzbar, nützlich und einfach zu bedienen ist.
Deshalb haben wir sorgfältige Entscheidungen und Kompromisse zwischen verschiedenen Modellen, Komponenten und Technologien getroffen.
Erstens unterstützt ThinkRAG bei der Verwendung großer Modelle die OpenAI-API und alle kompatiblen LLM-APIs, einschließlich inländischer Mainstream-Hersteller großer Modelle, wie zum Beispiel:
Wenn Sie große Modelle lokal bereitstellen möchten, wählt ThinkRAG Ollama, das einfach und benutzerfreundlich ist. Wir können große Modelle herunterladen, um sie lokal über Ollama auszuführen.
Derzeit unterstützt Ollama die lokalisierte Bereitstellung fast aller gängigen Großmodelle, einschließlich Llama, Gemma, GLM, Mistral, Phi, Llava usw. Weitere Informationen finden Sie unten auf der offiziellen Website von Ollama.
Das System verwendet auch Einbettungsmodelle und neu angeordnete Modelle und unterstützt die meisten Modelle von Hugging Face. Derzeit verwendet ThinkRAG hauptsächlich die Modelle der BGE-Serie von BAAI. Inländische Benutzer können die Mirror-Website besuchen, um sich zu informieren und herunterzuladen.
Nachdem Sie den Code von Github heruntergeladen haben, installieren Sie mit pip die erforderlichen Komponenten.
pip3 install -r requirements.txtUm das System offline zu betreiben, laden Sie bitte zunächst Ollama von der offiziellen Website herunter. Verwenden Sie dann den Befehl Ollama, um große Modelle wie GLM, Gemma und QWen herunterzuladen.
Laden Sie gleichzeitig das Einbettungsmodell (BAAI/bge-large-zh-v1.5) und das Reranking-Modell (BAAI/bge-reranker-base) von Hugging Face in das Verzeichnis localmodels herunter.
Spezifische Schritte finden Sie im Dokument im Dokumentverzeichnis: HowToDownloadModels.md
Um eine bessere Leistung zu erzielen, wird empfohlen, die kommerzielle LLM-API für große Modelle mit Hunderten von Milliarden Parametern zu verwenden.
Besorgen Sie sich zunächst den API-Schlüssel vom LLM-Dienstanbieter und konfigurieren Sie die folgenden Umgebungsvariablen.
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "Sie können diesen Schritt überspringen und den API-Schlüssel über die Anwendungsschnittstelle konfigurieren, nachdem das System ausgeführt wurde.
Wenn Sie sich für die Verwendung einer oder mehrerer LLM-APIs entscheiden, löschen Sie bitte den Dienstanbieter, den Sie nicht mehr verwenden, in der Konfigurationsdatei config.py.
Natürlich können Sie in der Konfigurationsdatei auch andere mit der OpenAI API kompatible Dienstanbieter hinzufügen.
ThinkRAG läuft standardmäßig im Entwicklungsmodus. In diesem Modus nutzt das System den lokalen Dateispeicher und Sie müssen keine Datenbank installieren.
Um in den Produktionsmodus zu wechseln, können Sie die Umgebungsvariablen wie folgt konfigurieren.
THINKRAG_ENV = productionIm Produktionsmodus nutzt das System die Vektordatenbank Chroma und die Schlüsselwertdatenbank Redis.
Wenn Sie Redis nicht installiert haben, wird empfohlen, es über Docker zu installieren oder eine vorhandene Redis-Instanz zu verwenden. Bitte konfigurieren Sie die Parameterinformationen der Redis-Instanz in der Datei config.py.
Jetzt können Sie ThinkRAG ausführen.
Bitte führen Sie den folgenden Befehl in dem Verzeichnis aus, das die Datei app.py enthält.
streamlit run app.pyDas System wird ausgeführt und öffnet automatisch die folgende URL im Browser, um die Anwendungsoberfläche anzuzeigen.
http://localhost:8501/
Der erste Durchlauf kann eine Weile dauern. Wenn das eingebettete Modell auf Hugging Face nicht im Voraus heruntergeladen wird, lädt das System das Modell automatisch herunter und Sie müssen länger warten.
ThinkRAG unterstützt die Konfiguration und Auswahl großer Modelle in der Benutzeroberfläche, einschließlich: der Basis-URL und des API-Schlüssels der LLM-API für große Modelle, und Sie können das spezifische Modell auswählen, das verwendet werden soll, zum Beispiel: glm-4 von ThinkRAG.
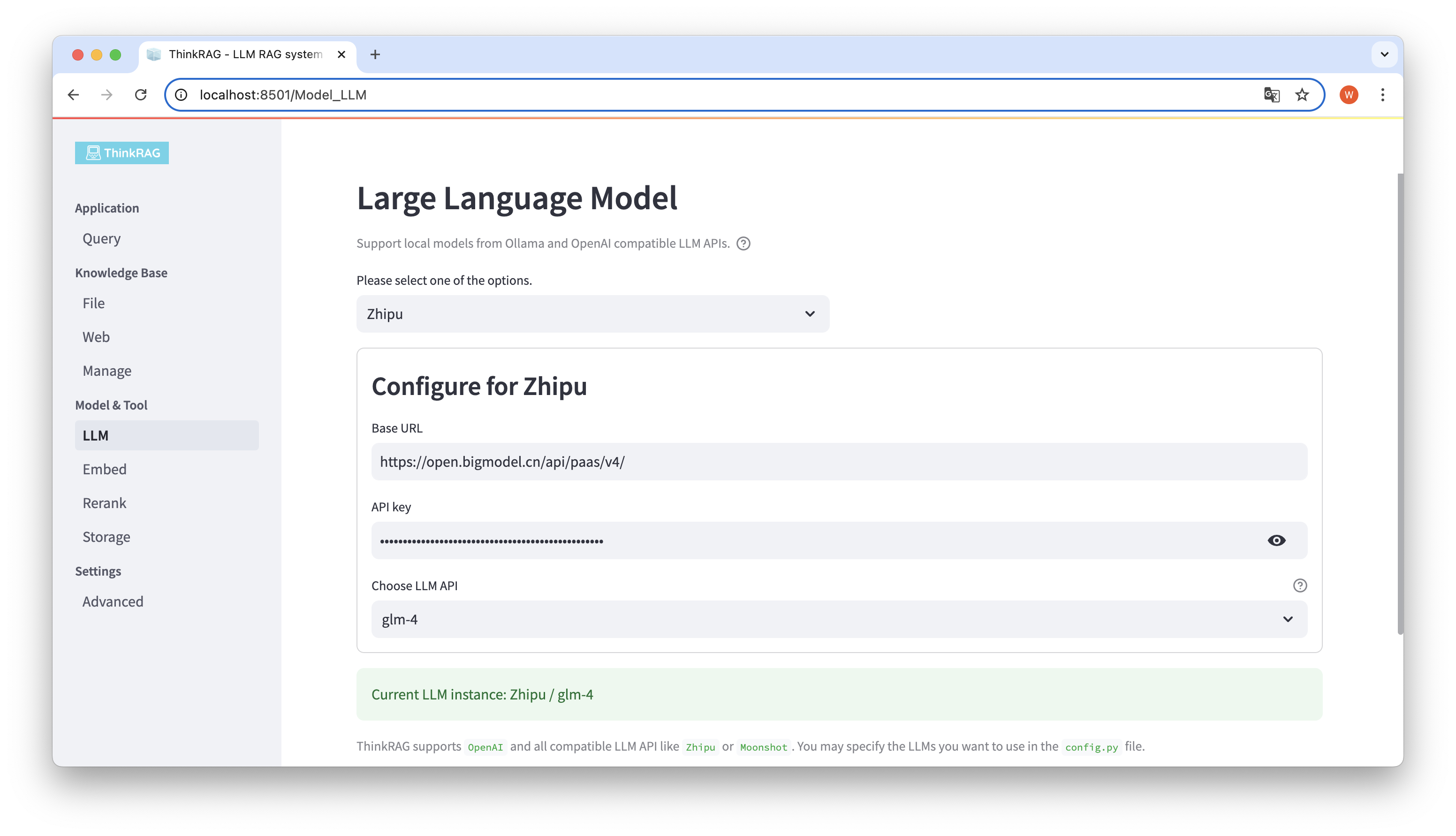
Das System erkennt automatisch, ob die API und der Schlüssel verfügbar sind. Falls verfügbar, wird die aktuell ausgewählte große Modellinstanz unten in grüner Schrift angezeigt.
Ebenso kann das System die von Ollama heruntergeladenen Modelle automatisch abrufen und der Benutzer kann das gewünschte Modell auf der Benutzeroberfläche auswählen.
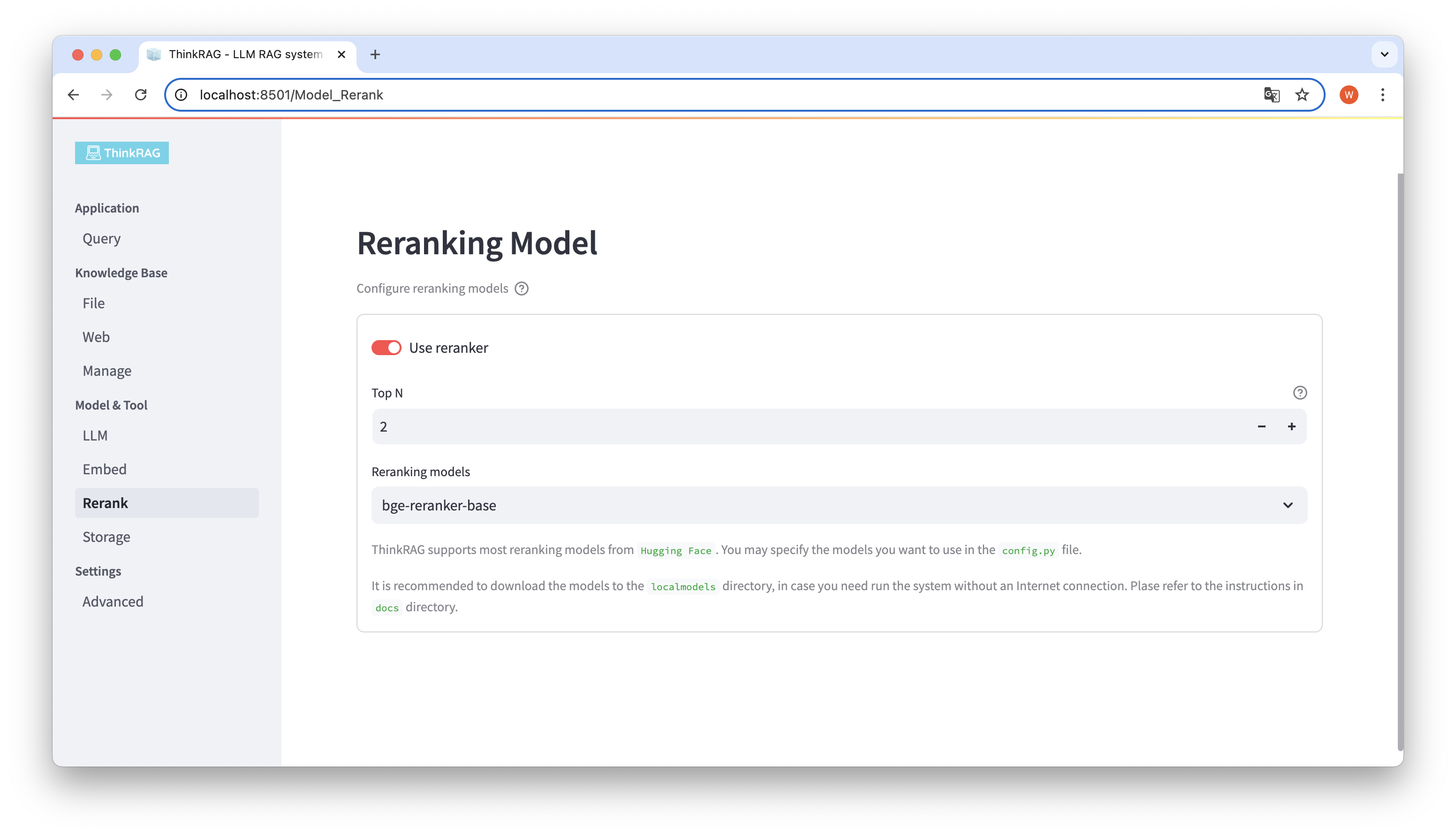
Wenn Sie das eingebettete Modell heruntergeladen und im lokalen Verzeichnis „localmodels“ neu angeordnet haben. Auf der Benutzeroberfläche können Sie das ausgewählte Modell wechseln und die Parameter des neu angeordneten Modells festlegen, z. B. Top N.
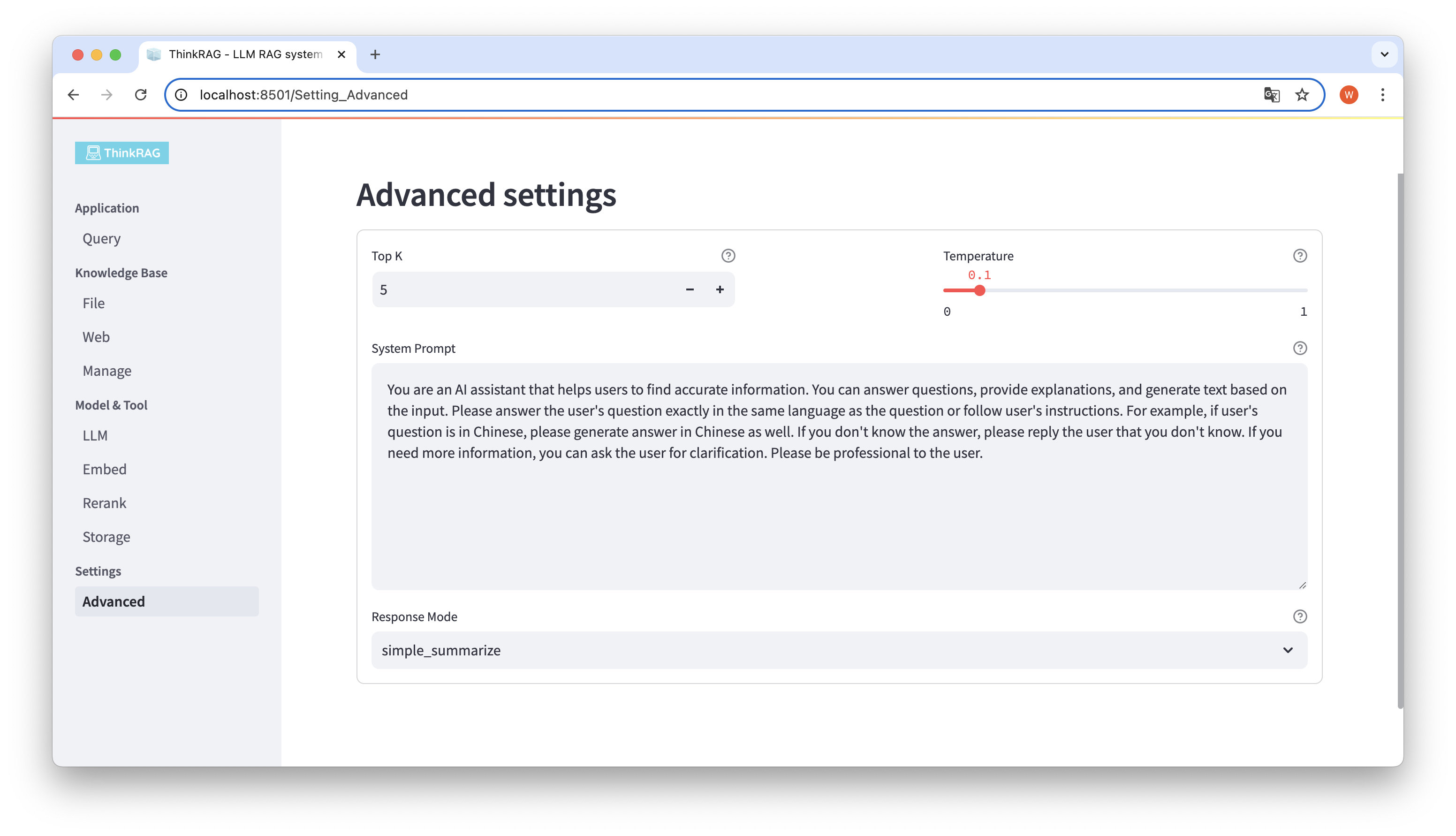
Klicken Sie in der linken Navigationsleiste auf Erweiterte Einstellungen (Einstellungen-Erweitert). Sie können auch die folgenden Parameter festlegen:
Durch die Verwendung verschiedener Parameter können wir große Modellausgaben vergleichen und die effektivste Kombination von Parametern finden.
ThinkRAG unterstützt das Hochladen verschiedener Dateien wie PDF, DOCX, PPTX usw. sowie das Hochladen von Webseiten-URLs.
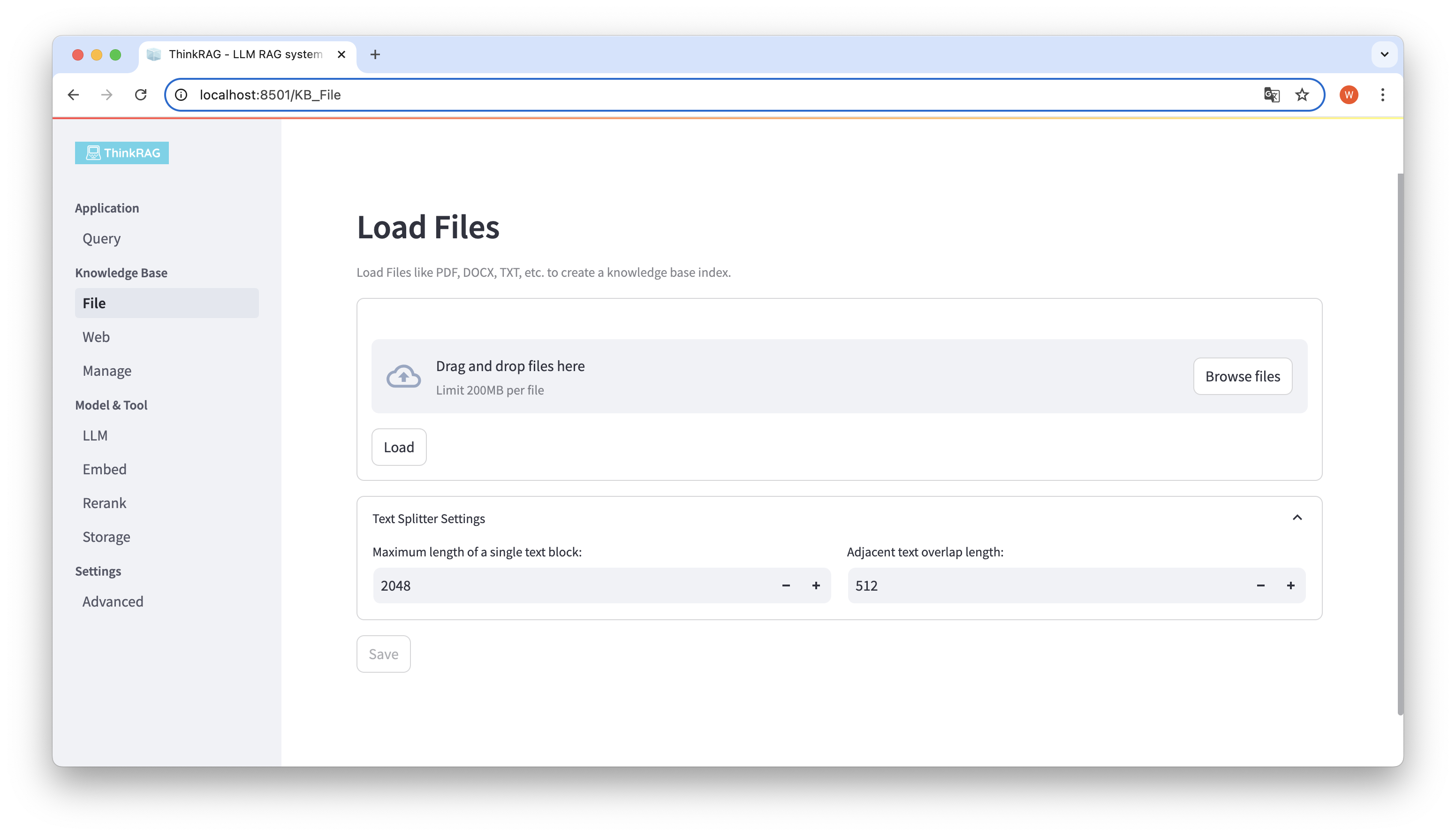
Klicken Sie auf die Schaltfläche „Dateien durchsuchen“, wählen Sie die Datei auf Ihrem Computer aus und klicken Sie dann auf die Schaltfläche „Laden“, um alle geladenen Dateien aufzulisten.
Klicken Sie dann auf die Schaltfläche „Speichern“, und das System verarbeitet die Datei, einschließlich der Textsegmentierung und -einbettung, und speichert sie in der Wissensdatenbank.
Ebenso können Sie die Webseiten-URL eingeben oder einfügen, die Webseiteninformationen abrufen und sie nach der Verarbeitung in der Wissensdatenbank speichern.
Das System unterstützt die Verwaltung der Wissensdatenbank.
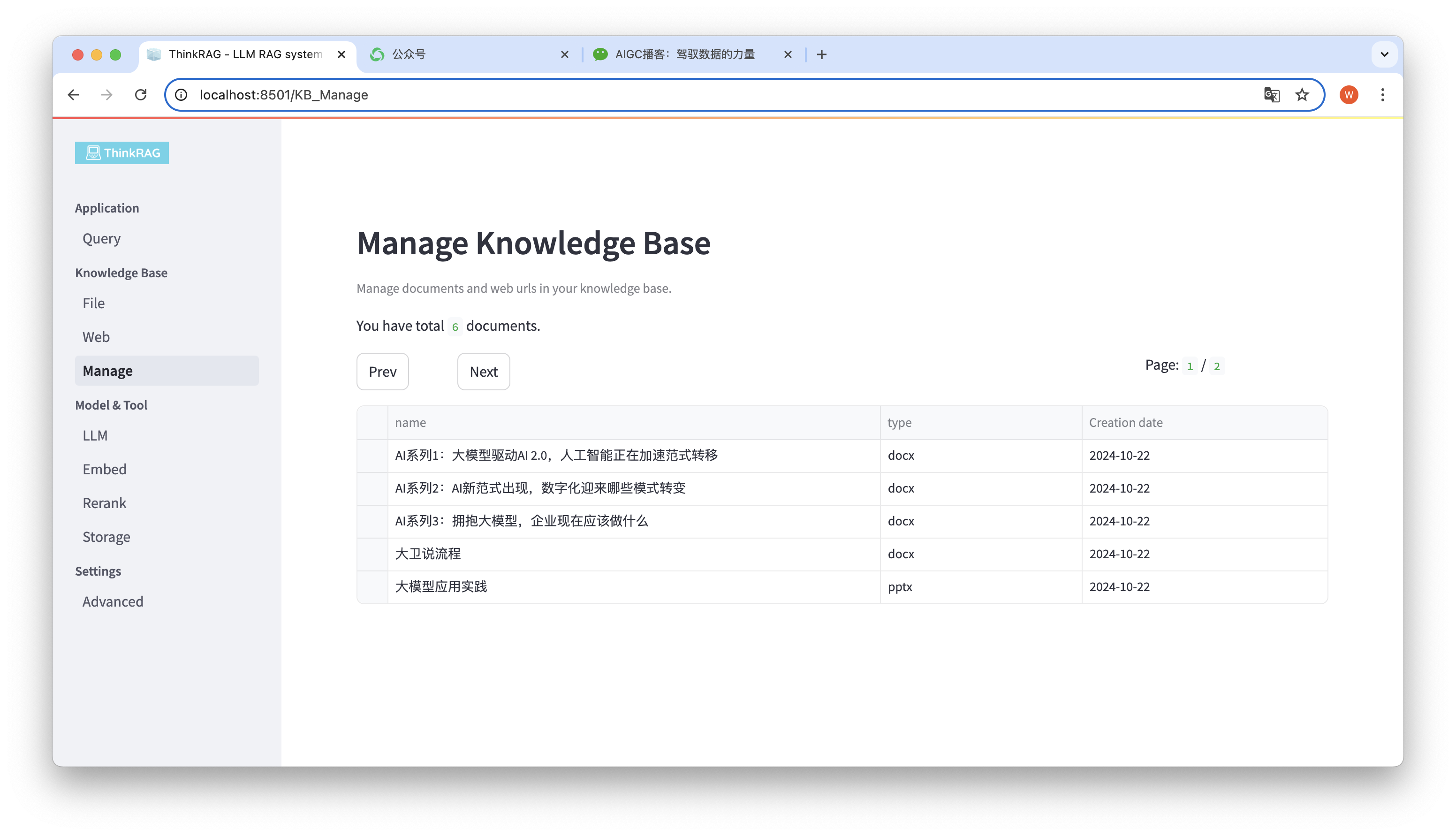
Wie in der Abbildung oben gezeigt, kann ThinkRAG alle Dokumente in der Wissensdatenbank seitenweise auflisten.
Wählen Sie die zu löschenden Dokumente aus. Die Schaltfläche „Ausgewählte Dokumente löschen“ wird angezeigt. Klicken Sie auf diese Schaltfläche, um die Dokumente aus der Wissensdatenbank zu löschen.
Klicken Sie in der linken Navigationsleiste auf „Abfrage“ und die intelligente Frage-und-Antwort-Seite wird angezeigt.
Nach Eingabe der Frage durchsucht das System die Wissensdatenbank und gibt eine Antwort. Während dieses Prozesses nutzt das System Technologien wie hybrides Abrufen und Neuordnen, um genaue Inhalte aus der Wissensdatenbank zu erhalten.
Wir haben beispielsweise ein Word-Dokument in der Wissensdatenbank hochgeladen: „David Says Process.docx“.
Geben Sie nun die Frage ein: „Was sind drei Merkmale eines Prozesses?“
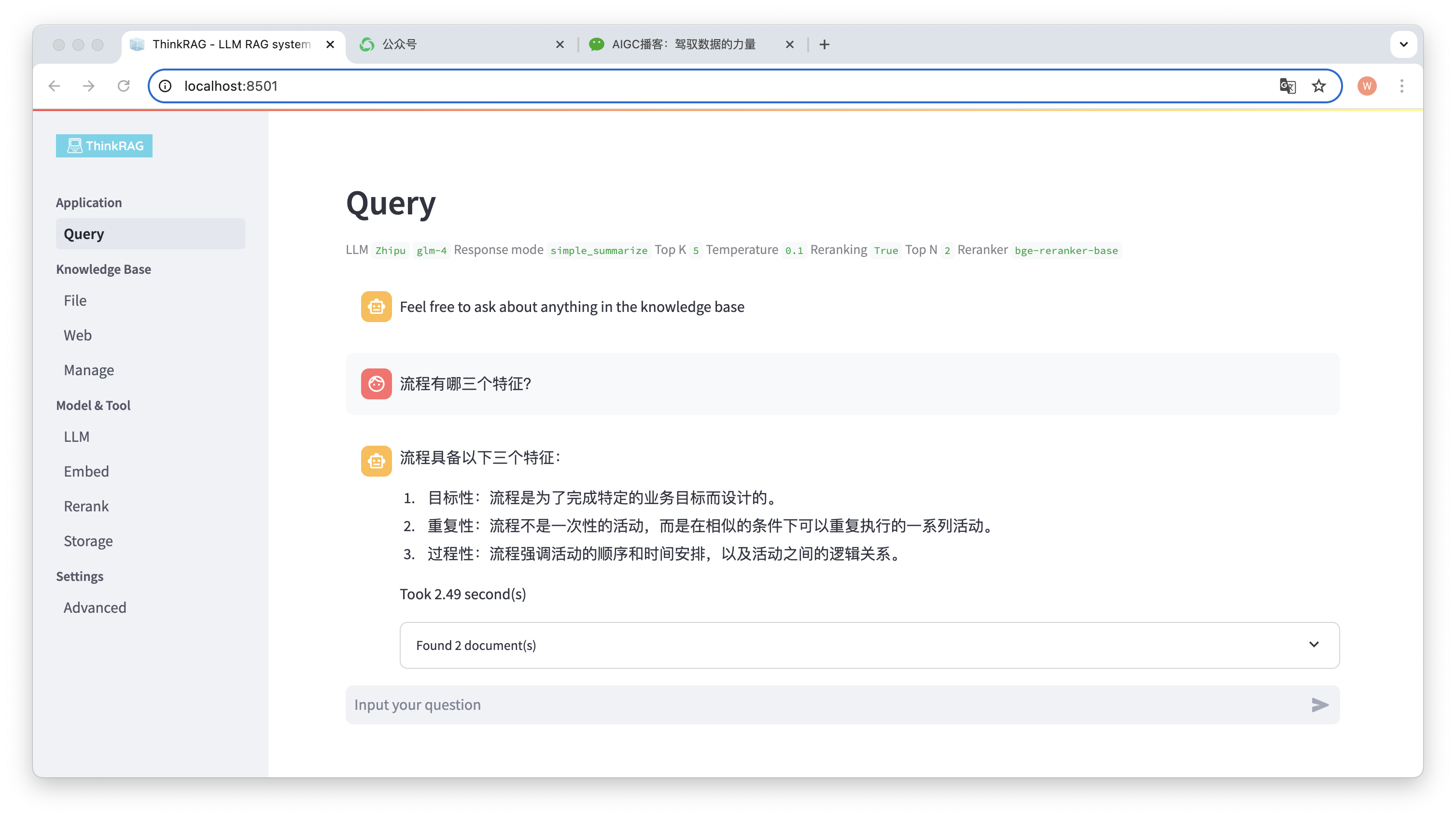
Wie in der Abbildung dargestellt, benötigte das System 2,49 Sekunden, um eine genaue Antwort zu geben: Der Prozess ist zielgerichtet, repetitiv und prozedural. Gleichzeitig stellt das System auch zwei zugehörige Dokumente bereit, die aus der Wissensdatenbank abgerufen werden.
Es ist ersichtlich, dass ThinkRAG die Funktion der erweiterten Generierung großer Modellabrufe basierend auf der lokalen Wissensbasis vollständig und effektiv implementiert.
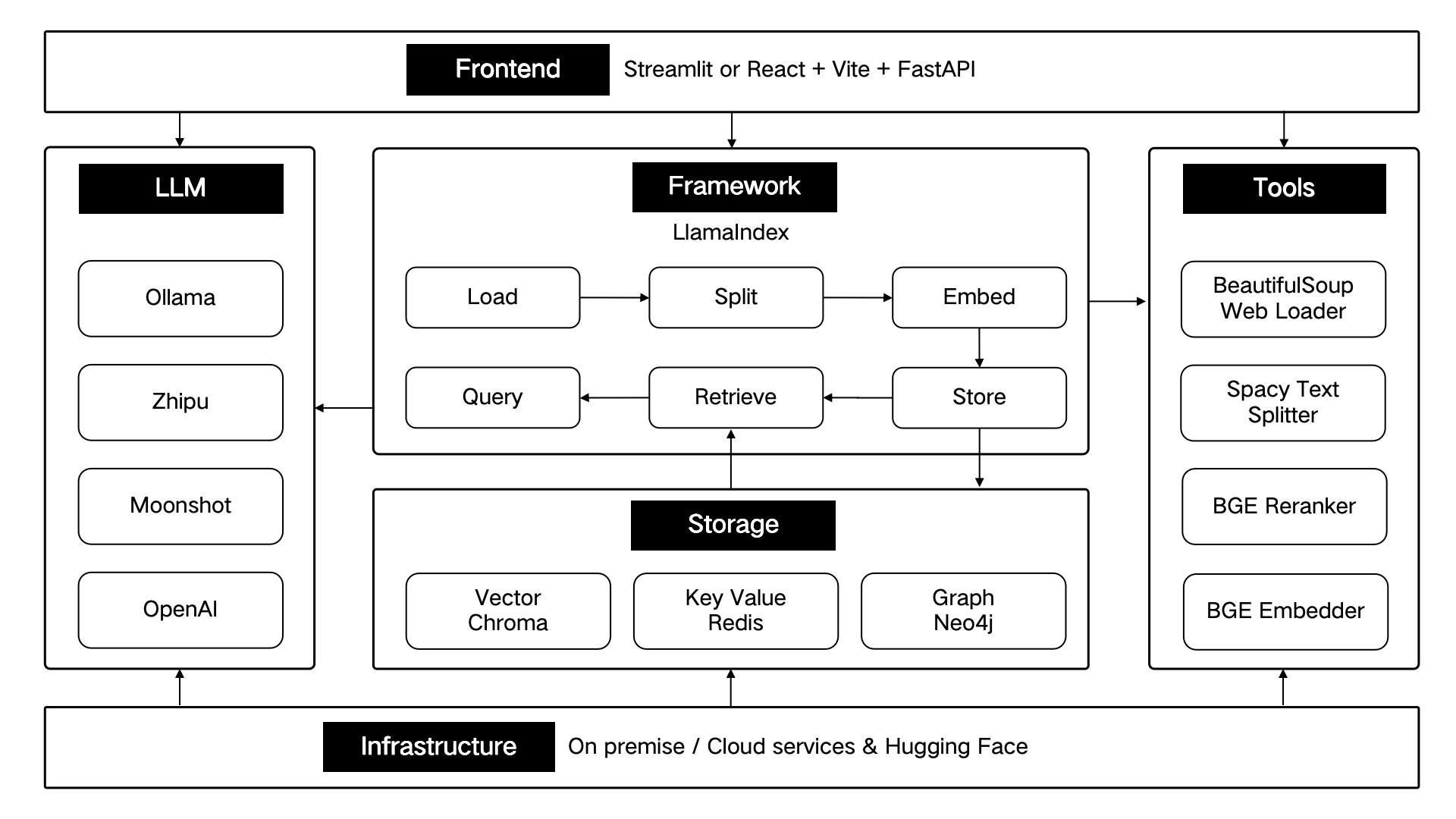
ThinkRAG wird unter Verwendung des LlamaIndex-Datenframeworks entwickelt und verwendet Streamlit für das Frontend. Der Entwicklungsmodus und der Produktionsmodus des Systems verwenden jeweils unterschiedliche technische Komponenten, wie in der folgenden Tabelle dargestellt:
| Entwicklungsmodus | Produktionsmodus | |
|---|---|---|
| RAG-Framework | LamaIndex | LamaIndex |
| Frontend-Framework | Streamlit | Streamlit |
| eingebettetes Modell | BAAI/bge-small-zh-v1.5 | BAAI/bge-large-zh-v1.5 |
| Modell neu anordnen | BAAI/bge-reranker-base | BAAI/bge-reranker-large |
| Textsplitter | SatzSplitter | SpacyTextSplitter |
| Konversationsspeicher | SimpleChatStore | Redis |
| Dokumentenspeicher | SimpleDocumentStore | Redis |
| Indexspeicher | SimpleIndexStore | Redis |
| Vektorspeicherung | SimpleVectorStore | LanceDB |
Diese technischen Komponenten sind architektonisch nach sechs Teilen gestaltet: Front-End, Framework, großes Modell, Tools, Speicher und Infrastruktur.
Wie unten gezeigt:
ThinkRAG wird die Kernfunktionen weiterhin optimieren und die Effizienz und Genauigkeit des Abrufs weiter verbessern, hauptsächlich einschließlich:
Gleichzeitig werden wir die Anwendungsarchitektur weiter verbessern und das Benutzererlebnis verbessern, insbesondere durch:
Sie sind herzlich eingeladen, dem Open-Source-Projekt ThinkRAG beizutreten und gemeinsam an der Entwicklung von KI-Produkten zu arbeiten, die Benutzer lieben!
ThinkRAG verwendet die MIT-Lizenz.


