pathway
v0.16.0
Erste Schritte | Bereitstellung | Dokumentation und Support | Blog | Lizenz
Pathway ist ein Python-ETL-Framework für Stream-Verarbeitung, Echtzeitanalysen, LLM-Pipelines und RAG.
Pathway verfügt über eine benutzerfreundliche Python-API , mit der Sie Ihre bevorzugten Python-ML-Bibliotheken nahtlos integrieren können. Pathway-Code ist vielseitig und robust: Sie können ihn sowohl in Entwicklungs- als auch in Produktionsumgebungen verwenden und sowohl Batch- als auch Streaming-Daten effektiv verarbeiten . Derselbe Code kann für die lokale Entwicklung, CI/CD-Tests, die Ausführung von Batch-Jobs, die Verarbeitung von Stream-Wiedergaben und die Verarbeitung von Datenströmen verwendet werden.
Pathway wird von einer skalierbaren Rust-Engine basierend auf Differential Dataflow angetrieben und führt inkrementelle Berechnungen durch. Obwohl Ihr Pathway-Code in Python geschrieben ist, wird er von der Rust-Engine ausgeführt, was Multithreading, Multiprocessing und verteilte Berechnungen ermöglicht. Die gesamte Pipeline wird im Speicher gehalten und kann problemlos mit Docker und Kubernetes bereitgestellt werden.
Sie können Pathway mit pip installieren:
pip install -U pathway
Bei Fragen finden Sie die Community und das Team hinter dem Projekt auf Discord.
Sind Sie bereit zu sehen, was Pathway leisten kann?
Probieren Sie eines unserer einfach umzusetzenden Beispiele aus!
Diese sofort einsatzbereiten Beispiele sind sowohl im Notebook- als auch im Docker-Format verfügbar und können mit nur wenigen Klicks gestartet werden. Wählen Sie eines aus und beginnen Sie noch heute Ihre praktische Erfahrung mit Pathway!
Mit seiner einheitlichen Engine für Batch und Streaming und seiner vollständigen Python-Kompatibilität macht Pathway die Datenverarbeitung so einfach wie möglich. Es ist die ideale Lösung für eine Vielzahl von Datenverarbeitungspipelines, darunter:
Pathway bietet spezielle LLM-Tools zum Aufbau von Live-LLM- und RAG-Pipelines. Wrapper für die gängigsten LLM-Dienste und -Dienstprogramme sind enthalten, was die Arbeit mit LLMs- und RAGs-Pipelines unglaublich einfach macht. Schauen Sie sich unsere LLM-XPack-Dokumentation an.
Zögern Sie nicht, eines unserer lauffähigen Beispiele mit LLM-Werkzeugen auszuprobieren. Solche Beispiele finden Sie hier.
Pathway erfordert Python 3.10 oder höher.
Sie können die aktuelle Version von Pathway mit pip installieren:
$ pip install -U pathway
import pathway as pw
# Define the schema of your data (Optional)
class InputSchema ( pw . Schema ):
value : int
# Connect to your data using connectors
input_table = pw . io . csv . read (
"./input/" ,
schema = InputSchema
)
#Define your operations on the data
filtered_table = input_table . filter ( input_table . value >= 0 )
result_table = filtered_table . reduce (
sum_value = pw . reducers . sum ( filtered_table . value )
)
# Load your results to external systems
pw . io . jsonlines . write ( result_table , "output.jsonl" )
# Run the computation
pw . run ()Führen Sie Pathway in Google Colab aus.
Weitere Beispiele finden Sie hier.
Um Pathway zu verwenden, müssen Sie es nur importieren:
import pathway as pwJetzt können Sie ganz einfach Ihre Verarbeitungspipeline erstellen und Pathway die Aktualisierungen überlassen. Sobald Ihre Pipeline erstellt ist, können Sie die Berechnung für Streaming-Daten mit einem einzeiligen Befehl starten:
pw . run () Anschließend können Sie Ihr Pathway-Projekt (z. B. main.py ) wie ein normales Python-Skript ausführen: $ python main.py Pathway verfügt über ein Überwachungs-Dashboard, mit dem Sie die Anzahl der von jedem Connector gesendeten Nachrichten und die Latenz des Systems verfolgen können. Das Dashboard enthält auch Protokollmeldungen.
Alternativ können Sie die Pathway-Version verwenden:
$ pathway spawn python main.py
Pathway unterstützt nativ Multithreading. Um Ihre Anwendung mit 3 Threads zu starten, können Sie wie folgt vorgehen:
$ pathway spawn --threads 3 python main.py
Um ein Pathway-Projekt zu starten, können Sie unsere Cookie-Cutter-Vorlage verwenden.
Sie können Pathway ganz einfach mit Docker ausführen.
Sie können das Pathway-Docker-Image mithilfe einer Docker-Datei verwenden:
FROM pathwaycom/pathway:latest
WORKDIR /app
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD [ "python" , "./your-script.py" ]Anschließend können Sie das Docker-Image erstellen und ausführen:
docker build -t my-pathway-app .
docker run -it --rm --name my-pathway-app my-pathway-app Bei Einzeldateiprojekten scheint die Erstellung einer vollständigen Dockerfile möglicherweise unnötig. In solchen Szenarien können Sie ein Python-Skript direkt mit dem Pathway Docker-Image ausführen. Zum Beispiel:
docker run -it --rm --name my-pathway-app -v "$PWD":/app pathwaycom/pathway:latest python my-pathway-app.py Sie können auch ein Standard-Python-Image verwenden und Pathway mithilfe von pip mit einer Docker-Datei installieren:
FROM --platform=linux/x86_64 python:3.10
RUN pip install -U pathway
COPY ./pathway-script.py pathway-script.py
CMD [ "python" , "-u" , "pathway-script.py" ]Docker-Container eignen sich ideal für die Bereitstellung in der Cloud mit Kubernetes. Wenn Sie Ihre Pathway-Anwendung skalieren möchten, könnte Sie unser Pathway for Enterprise interessieren. Pathway for Enterprise ist speziell auf die End-to-End-Datenverarbeitung und intelligente Echtzeitanalysen zugeschnitten. Es skaliert durch verteiltes Computing in der Cloud und unterstützt die verteilte Kubernetes-Bereitstellung mit externer Persistenzeinrichtung.
Sie können Pathway ganz einfach mithilfe von Diensten wie Render bereitstellen: Erfahren Sie, wie Sie Pathway mit wenigen Klicks bereitstellen.
Wenn Sie interessiert sind, zögern Sie nicht, uns zu kontaktieren, um mehr zu erfahren.
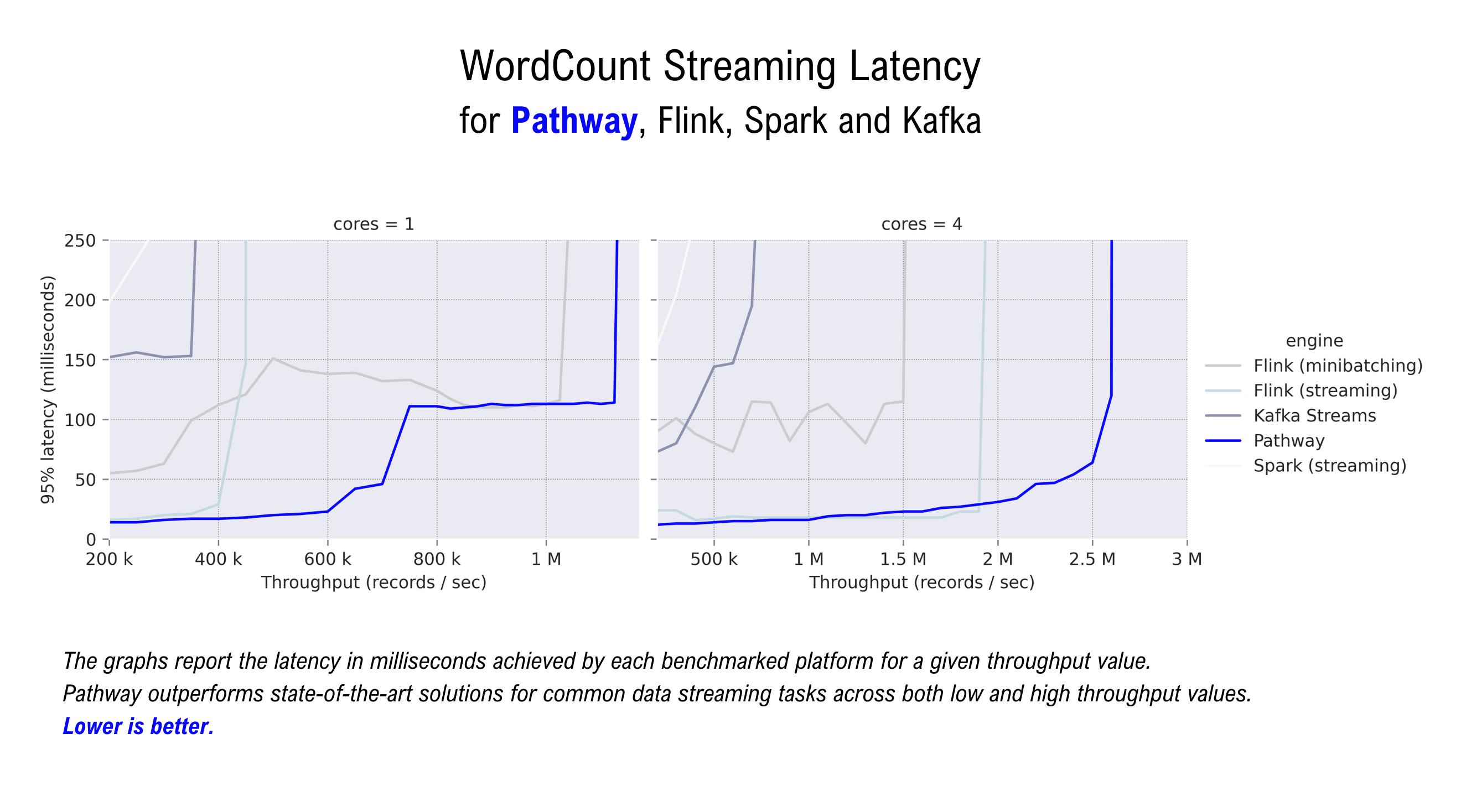
Pathway ist darauf ausgelegt, modernste Technologien für Streaming- und Batch-Datenverarbeitungsaufgaben zu übertreffen, darunter Flink, Spark und Kafka Streaming. Es ermöglicht auch die Implementierung vieler Algorithmen/UDFs im Streaming-Modus, die von anderen Streaming-Frameworks nicht ohne weiteres unterstützt werden (insbesondere: zeitliche Verknüpfungen, iterative Graphalgorithmen, Routinen für maschinelles Lernen).
Wenn Sie neugierig sind, finden Sie hier einige Benchmarks, mit denen Sie experimentieren können.
Die gesamte Dokumentation von Pathway ist unter pathway.com/developers/ verfügbar, einschließlich der API-Dokumente.
Wenn Sie Fragen haben, zögern Sie nicht, ein Problem auf GitHub zu eröffnen, sich uns auf Discord anzuschließen oder uns eine E-Mail an [email protected] zu senden.
Pathway wird unter einer BSL 1.1-Lizenz vertrieben, die eine unbegrenzte nichtkommerzielle Nutzung sowie die kostenlose Nutzung des Pathway-Pakets für die meisten kommerziellen Zwecke ermöglicht. Der Code in diesem Repository wird nach 4 Jahren automatisch in Open Source (Apache 2.0-Lizenz) konvertiert. Einige öffentliche Repos, die dieses ergänzen (Beispiele, Bibliotheken, Konnektoren usw.), sind unter der MIT-Lizenz als Open Source lizenziert.
Wenn Sie eine Bibliothek oder einen Connector entwickeln, den Sie in dieses Repo integrieren möchten, empfehlen wir, es zunächst als separates Repo unter einer MIT/Apache 2.0-Lizenz zu veröffentlichen.
Bei allen Bedenken bezüglich der Kernfunktionen von Pathway sind Issues willkommen. Für weitere Informationen wenden Sie sich bitte an die Discord-Community von Pathway.


