lance
v0.20.0

Modernes spaltenorientiertes Datenformat für ML. Konvertieren Sie Parquet in zwei Codezeilen für einen 100-mal schnelleren Direktzugriff, einen Vektorindex, Datenversionierung und mehr.
Kompatibel mit Pandas, DuckDB, Polars und Pyarrow, weitere Integrationen sind geplant.
Dokumentation • Blog • Discord • Twitter
Lance ist ein modernes spaltenorientiertes Datenformat, das für ML-Workflows und -Datensätze optimiert ist. Lance ist perfekt für:
Zu den Hauptmerkmalen von Lance gehören:
Hochleistungsfähiger Direktzugriff: 100-mal schneller als Parquet, ohne Einbußen bei der Scanleistung.
Vektorsuche: Finden Sie die nächsten Nachbarn in Millisekunden und kombinieren Sie OLAP-Abfragen mit der Vektorsuche.
Keine Kopie, automatische Versionierung: Verwalten Sie Versionen Ihrer Daten, ohne dass zusätzliche Infrastruktur erforderlich ist.
Ökosystemintegrationen: Apache Arrow, Pandas, Polars, DuckDB und mehr in Vorbereitung.
Tipp
Lance befindet sich in der aktiven Entwicklung und wir freuen uns über Beiträge. Weitere Informationen finden Sie in unserem Beitragsleitfaden.
Installation
pip install pylanceSo installieren Sie eine Vorschauversion:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylanceTipp
Vorschauversionen werden häufiger veröffentlicht als Vollversionen und enthalten die neuesten Funktionen und Fehlerbehebungen. Sie erhalten das gleiche Maß an Tests wie Vollversionen. Wir garantieren, dass sie mindestens 6 Monate lang veröffentlicht und zum Download verfügbar bleiben. Wenn Sie eine bestimmte Version festlegen möchten, bevorzugen Sie eine stabile Version.
Konvertieren zu Lance
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )Lance-Daten lesen
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )Pandas
df = dataset . to_table (). to_pandas ()
dfDuckDB
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
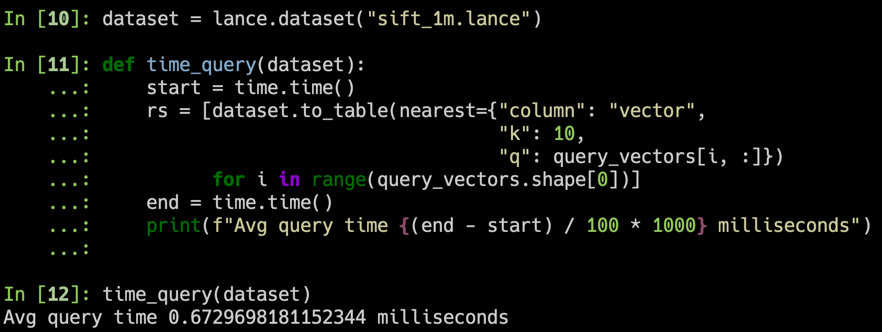
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()Vektorsuche
Laden Sie die Teilmenge „sift1m“ herunter
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gzWandeln Sie es in Lance um
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )Erstellen Sie den Index
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQDurchsuchen Sie den Datensatz
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| Verzeichnis | Beschreibung |
|---|---|
| Rost | Kern-Rust-Implementierung |
| Python | Python-Bindungen (pyo3) |
| Dokumente | Dokumentationsquelle |
Hier werden wir einige Aspekte von Lances Design hervorheben. Weitere Einzelheiten finden Sie im vollständigen Lance-Designdokument.
Vektorindex : Vektorindex für die Ähnlichkeitssuche im Einbettungsraum. Unterstützt sowohl CPUs ( x86_64 und arm ) als auch GPUs ( Nvidia (cuda) und Apple Silicon (mps) ).
Kodierungen : Um sowohl einen schnellen Spaltenscan als auch sublineare Punktabfragen zu erreichen, verwendet Lance benutzerdefinierte Kodierungen und Layouts.
Verschachtelte Felder : Lance speichert jedes Unterfeld als separate Spalte, um effiziente Filter wie „Bilder finden, in denen erkannte Objekte Katzen enthalten“ zu unterstützen.
Versionierung : Ein Manifest kann zum Aufzeichnen von Snapshots verwendet werden. Derzeit unterstützen wir die automatische Erstellung neuer Versionen durch Anhängen, Überschreiben und Indexerstellung.
Schnelle Updates (ROADMAP): Updates werden über Write-Ahead-Protokolle unterstützt.
Umfangreiche Sekundärindizes (ROADMAP):
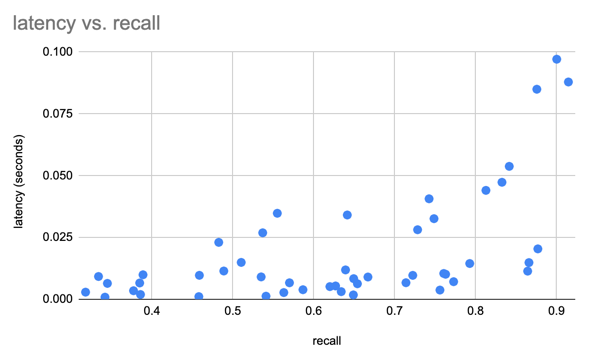
Wir haben den SIFT-Datensatz verwendet, um unsere Ergebnisse mit 1 Mio. Vektoren von 128D zu vergleichen
Wir erstellen einen Lance-Datensatz unter Verwendung des Oxford Pet-Datensatzes, um einige vorläufige Leistungstests von Lance im Vergleich zu Parquet und Rohbildern/XMLs durchzuführen. Bei Analyseabfragen ist Lance 50-100x besser als beim Lesen der Rohmetadaten. Beim Batch-Direktzugriff ist Lance 100-mal besser als Parkett- und Rohdateien.

Der Entwicklungszyklus für maschinelles Lernen umfasst die Schritte:
Grafik LR
A[Sammlung] -> B[Erkundung];
B -> C[Analytics];
C -> D[Feature Engineer];
D -> E[Training];
E -> F[Bewertung];
F -> C;
E -> G[Bereitstellung];
G --> H[Überwachung];
H -> A;
Menschen verwenden unterschiedliche Datendarstellungen in unterschiedlichen Phasen für die Leistung oder sind durch die verfügbaren Tools eingeschränkt. Academia verwendet hauptsächlich XML/JSON für Anmerkungen und komprimierte Bild-/Sensordaten für Deep Learning, was schwierig in die Dateninfrastruktur zu integrieren und über Cloud-Speicher nur langsam zu trainieren ist. Während die Industrie Data Lakes (Parquet-basierte Techniken, z. B. Delta Lake, Iceberg) oder Data Warehouses (AWS Redshift oder Google BigQuery) zum Sammeln und Analysieren von Daten verwendet, muss sie die Daten in schulungsfreundliche Formate wie Rikai/ umwandeln. Petastorm oder TFRecord. Mehrere zweckgebundene Datentransformationen sowie die Synchronisierung von Kopien zwischen Cloud-Speicher und lokalen Trainingsinstanzen sind mittlerweile gängige Praxis.
Während sich jedes der vorhandenen Datenformate durch die Arbeitslast auszeichnet, für die es ursprünglich entwickelt wurde, benötigen wir ein neues Datenformat, das auf mehrstufige ML-Entwicklungszyklen zugeschnitten ist, um Datensilos zu reduzieren.
Ein Vergleich verschiedener Datenformate in jeder Phase des ML-Entwicklungszyklus.
| Lanze | Parkett & ORC | JSON und XML | TFRecord | Datenbank | Lager | |
|---|---|---|---|---|---|---|
| Analytik | Schnell | Schnell | Langsam | Langsam | Anständig | Schnell |
| Feature-Engineering | Schnell | Schnell | Anständig | Langsam | Anständig | Gut |
| Ausbildung | Schnell | Anständig | Langsam | Schnell | N / A | N / A |
| Erforschung | Schnell | Langsam | Schnell | Langsam | Schnell | Anständig |
| Infrastrukturunterstützung | Reich | Reich | Anständig | Beschränkt | Reich | Reich |
Lance wird derzeit in der Produktion eingesetzt von:


