qlib
v0.9.5 ?

Zuletzt veröffentlichte Funktionen
 : LLM-basierte autonome Entwicklungsagenten für industrielle datengesteuerte Forschung und Entwicklung
: LLM-basierte autonome Entwicklungsagenten für industrielle datengesteuerte Forschung und EntwicklungWir freuen uns, die Veröffentlichung von RD-Agent ? bekannt zu geben, einem leistungsstarken Tool, das automatisiertes Factor Mining und Modelloptimierung in der Forschung und Entwicklung quantitativer Investitionen unterstützt.
RD-Agent ist jetzt auf GitHub verfügbar und wir heißen Ihren Star willkommen?!
Um mehr zu erfahren, besuchen Sie bitte unsere ♾️Demo-Seite. Hier finden Sie Demovideos auf Englisch und Chinesisch, die Ihnen helfen, das Szenario und die Verwendung von RD-Agent besser zu verstehen.
Wir haben mehrere Demo-Videos für Sie vorbereitet:
| Szenario | Demovideo (Englisch) | Demovideo (中文) |
|---|---|---|
| Quant-Factor-Mining | Link | Link |
| Quant Factor Mining aus Berichten | Link | Link |
| Quantenmodelloptimierung | Link | Link |
| Besonderheit | Status |
|---|---|
| BPQP für End-to-End-Lernen | ?Bald erhältlich!(In Prüfung) |
| LLM-gesteuerte Auto Quant Factory | Veröffentlicht in ♾️RD-Agent am 8. August 2024 |
| KRNN- und Sandwich-Modelle | ? Veröffentlicht am 26. Mai 2023 |
| Veröffentlichung von Qlib v0.9.0 | Veröffentlicht am 9. Dezember 2022 |
| RL-Lernrahmen | ? ? Veröffentlicht am 10. November 2022. #1332, #1322, #1316, #1299, #1263, #1244, #1169, #1125, #1076 |
| HIST- und IGMTF-Modelle | ? Veröffentlicht am 10. April 2022 |
| Qlib-Notebook-Tutorial | Veröffentlicht am 7. April 2022 |
| Ibovespa-Indexdaten | ? Veröffentlicht am 6. April 2022 |
| Point-in-Time-Datenbank | ? Veröffentlicht am 10. März 2022 |
| Beispiel für Backend- und Orderbuchdaten eines Arctic Providers | ? Veröffentlicht am 17. Januar 2022 |
| Meta-Learning-basiertes Framework und DDG-DA | ? ? Veröffentlicht am 10. Januar 2022 |
| Planungsbasierte Portfoliooptimierung | ? Veröffentlicht am 28. Dezember 2021 |
| Veröffentlichung von Qlib v0.8.0 | Veröffentlicht am 8. Dezember 2021 |
| Modell HINZUFÜGEN | ? Veröffentlicht am 22. November 2021 |
| ADARNN-Modell | ? Veröffentlicht am 14. November 2021 |
| TCN-Modell | ? Veröffentlicht am 4. November 2021 |
| Verschachteltes Entscheidungsframework | ? Veröffentlicht am 1. Oktober 2021. Beispiel und Dokument |
| Temporaler Routing-Adapter (TRA) | ? Veröffentlicht am 30. Juli 2021 |
| Transformator und Lokalformer | ? Veröffentlicht am 22. Juli 2021 |
| Veröffentlichung von Qlib v0.7.0 | Veröffentlicht am 12. Juli 2021 |
| TCTS-Modell | ? Veröffentlicht am 1. Juli 2021 |
| Online-Bereitstellung und automatisches Modell-Rolling | ? Veröffentlicht am 17. Mai 2021 |
| DoubleEnsemble-Modell | ? Veröffentlicht am 2. März 2021 |
| Beispiel für Hochfrequenz-Datenverarbeitung | ? Veröffentlicht am 5. Februar 2021 |
| Beispiel für den Hochfrequenzhandel | ? Teil des Codes, veröffentlicht am 28. Januar 2021 |
| Hochfrequenzdaten (1 Min.) | ? Veröffentlicht am 27. Januar 2021 |
| Tabnet-Modell | ? Veröffentlicht am 22. Januar 2021 |
Funktionen, die vor 2021 veröffentlicht wurden, werden hier nicht aufgeführt.

Qlib ist eine quelloffene, KI-orientierte quantitative Investmentplattform, deren Ziel es ist, das Potenzial auszuschöpfen, die Forschung zu stärken und mithilfe von KI-Technologien bei quantitativen Investitionen Mehrwert zu schaffen, von der Ideenfindung bis zur Umsetzung von Produktionen. Qlib unterstützt verschiedene Modellierungsparadigmen für maschinelles Lernen, darunter überwachtes Lernen, Marktdynamikmodellierung und verstärkendes Lernen.
In Qlib werden immer mehr SOTA Quant-Forschungsarbeiten/-Aufsätze zu unterschiedlichen Paradigmen veröffentlicht, um gemeinsam wichtige Herausforderungen bei quantitativen Investitionen zu lösen. Zum Beispiel 1) die Verwendung von überwachtem Lernen, um die komplexen nichtlinearen Muster des Marktes aus umfangreichen und heterogenen Finanzdaten zu ermitteln, 2) die Modellierung der dynamischen Natur des Finanzmarkts mithilfe der adaptiven Concept-Drift-Technologie und 3) die Verwendung von Reinforcement Learning zur Modellierung kontinuierlicher Investitionen Entscheidungen und unterstützen Anleger bei der Optimierung ihrer Handelsstrategien.
Es enthält die vollständige ML-Pipeline für Datenverarbeitung, Modelltraining und Backtesting. und deckt die gesamte Kette quantitativer Investitionen ab: Alpha-Suche, Risikomodellierung, Portfoliooptimierung und Auftragsausführung. Weitere Einzelheiten finden Sie in unserem Dokument „Qlib: Eine KI-orientierte quantitative Investmentplattform“.
| Frameworks, Tutorial, Daten & DevOps | Wichtigste Herausforderungen und Lösungen in der Quantenforschung |
|---|---|
|
|
Neue Funktionen in der Entwicklung (Reihenfolge nach voraussichtlicher Veröffentlichungszeit). Ihr Feedback zu den Funktionen ist sehr wichtig.

Das High-Level-Framework von Qlib finden Sie oben (Benutzer können das detaillierte Framework des Qlib-Designs finden, wenn sie näher darauf eingehen). Die Komponenten sind als lose gekoppelte Module konzipiert und jede Komponente kann einzeln verwendet werden.
Qlib bietet eine starke Infrastruktur zur Unterstützung der Quantenforschung. Daten sind immer ein wichtiger Teil. Ein starker Lernrahmen soll verschiedene Lernparadigmen (z. B. verstärkendes Lernen, überwachtes Lernen) und Muster auf verschiedenen Ebenen (z. B. Marktdynamikmodellierung) unterstützen. Durch die Modellierung des Marktes werden Handelsstrategien Handelsentscheidungen generieren, die ausgeführt werden. Mehrere Handelsstrategien und Executors auf unterschiedlichen Ebenen oder Granularitäten können verschachtelt werden, um optimiert und gemeinsam ausgeführt zu werden. Abschließend wird eine umfassende Analyse bereitgestellt und das Modell kann kostengünstig online bereitgestellt werden.
Diese Kurzanleitung versucht es zu veranschaulichen
Hier ist eine kurze Demo, die zeigt, wie man Qlib installiert und LightGBM mit qrun ausführt. Bitte stellen Sie jedoch sicher, dass Sie die Daten gemäß der Anleitung bereits vorbereitet haben.
Diese Tabelle zeigt die unterstützte Python-Version von Qlib :
| mit pip installieren | Von der Quelle installieren | Handlung | |
|---|---|---|---|
| Python 3.7 | ✔️ | ✔️ | ✔️ |
| Python 3.8 | ✔️ | ✔️ | ✔️ |
| Python 3.9 | ✔️ |
Notiz :
conda -Umgebung dazu führen, dass Header-Dateien fehlen, was dazu führt, dass die Installation bestimmter Pakete fehlschlägt.Qlib aus dem Quellcode zu Fehlern führt. Wenn Benutzer Python 3.6 auf ihren Computern verwenden, wird empfohlen, Python auf Version 3.7 zu aktualisieren oder conda Python zu verwenden, um Qlib von der Quelle zu installieren.Qlib die Ausführung von Arbeitsabläufen wie das Trainieren von Modellen, das Durchführen von Backtests und das Plotten der meisten zugehörigen Zahlen (die im Notebook enthalten sind). Allerdings wird die Darstellung der Modellleistung derzeit nicht unterstützt und wir werden dies beheben, wenn die abhängigen Pakete in Zukunft aktualisiert werden.Qlib erfordert das tables , hdf5 in Tabellen unterstützt Python3.9 nicht. Benutzer können Qlib einfach per Pip mit dem folgenden Befehl installieren.
pip install pyqlibHinweis : Pip installiert die neueste stabile qlib. Der Hauptzweig von qlib befindet sich jedoch in der aktiven Entwicklung. Wenn Sie die neuesten Skripte oder Funktionen im Hauptzweig testen möchten. Bitte installieren Sie qlib mit den folgenden Methoden.
Außerdem können Benutzer die neueste Entwicklungsversion Qlib über den Quellcode installieren, indem sie die folgenden Schritte befolgen:
Vor der Installation Qlib aus dem Quellcode müssen Benutzer einige Abhängigkeiten installieren:
pip install numpy
pip install --upgrade cython Klonen Sie das Repository und installieren Sie Qlib wie folgt.
git clone https://github.com/microsoft/qlib.git && cd qlib
pip install . # `pip install -e .[dev]` is recommended for development. check details in docs/developer/code_standard_and_dev_guide.rst Hinweis : Sie können Qlib auch mit python setup.py install installieren. Dies ist jedoch nicht der empfohlene Ansatz. Es wird pip überspringen und unklare Probleme verursachen. Zum Beispiel nur der Befehl pip install . kann die von pip install pyqlib installierte stabile Version überschreiben, während der Befehl python setup.py install dies nicht kann .
Tipps : Wenn Sie Qlib nicht installieren oder die Beispiele in Ihrer Umgebung nicht ausführen können, kann Ihnen ein Vergleich Ihrer Schritte und des CI-Workflows möglicherweise dabei helfen, das Problem zu finden.
Tipps für Mac : Wenn Sie einen Mac mit M1 verwenden, können beim Erstellen des Rads für LightGBM Probleme auftreten, die auf fehlende Abhängigkeiten von OpenMP zurückzuführen sind. Um das Problem zu lösen, installieren Sie openmp zuerst mit brew install libomp und führen Sie dann pip install . um es erfolgreich aufzubauen.
❗ Aufgrund strengerer Datenschutzrichtlinien. Der offizielle Datensatz ist vorübergehend deaktiviert. Sie können diese von der Community bereitgestellte Datenquelle ausprobieren. Hier ist ein Beispiel zum Herunterladen der am 20240809 aktualisierten Daten.
wget https://github.com/chenditc/investment_data/releases/download/2024-08-09/qlib_bin.tar.gz
mkdir -p ~ /.qlib/qlib_data/cn_data
tar -zxvf qlib_bin.tar.gz -C ~ /.qlib/qlib_data/cn_data --strip-components=1
rm -f qlib_bin.tar.gzDer untenstehende offizielle Datensatz wird in Kürze wieder aufgenommen.
Laden Sie Daten und bereiten Sie sie vor, indem Sie den folgenden Code ausführen:
# get 1d data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
# get 1d data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
Dieser Datensatz wird aus öffentlichen Daten erstellt, die von Crawler-Skripten gesammelt und im selben Repository veröffentlicht wurden. Benutzer könnten damit denselben Datensatz erstellen. Beschreibung des Datensatzes
Bitte beachten Sie , dass die Daten von Yahoo Finance erfasst werden und möglicherweise nicht perfekt sind. Wir empfehlen Benutzern, ihre eigenen Daten vorzubereiten, wenn sie über einen qualitativ hochwertigen Datensatz verfügen. Weitere Informationen finden Benutzer im zugehörigen Dokument .
Dieser Schritt ist optional , wenn Benutzer ihre Modelle und Strategien nur anhand von Verlaufsdaten ausprobieren möchten.
Es wird empfohlen, dass Benutzer die Daten einmal manuell aktualisieren (--trading_date 25.05.2021) und sie dann auf automatische Aktualisierung einstellen.
HINWEIS : Benutzer können Daten basierend auf den von Qlib bereitgestellten Offline-Daten nicht inkrementell aktualisieren (einige Felder werden entfernt, um die Datengröße zu reduzieren). Benutzer sollten Yahoo Collector verwenden, um Yahoo-Daten von Grund auf herunterzuladen und sie dann schrittweise zu aktualisieren.
Weitere Informationen finden Sie unter: Yahoo Collector
Automatische Aktualisierung der Daten im Verzeichnis „qlib“ an jedem Handelstag (Linux)
Verwenden Sie crontab : crontab -e
Richten Sie zeitgesteuerte Aufgaben ein:
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
Manuelle Aktualisierung der Daten
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
docker pull pyqlib/qlib_image_stable:stabledocker run -it --name < container name > -v < Mounted local directory > :/app qlib_image_stable>>> python scripts/get_data.py qlib_data --name qlib_data_simple --target_dir ~ /.qlib/qlib_data/cn_data --interval 1d --region cn
>>> python qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml>>> exitdocker start -i -a < container name >docker stop < container name >docker rm < container name > Qlib bietet ein Tool namens qrun um den gesamten Workflow automatisch auszuführen (einschließlich Datensatzerstellung, Trainingsmodelle, Backtest und Auswertung). Sie können einen automatischen Quant-Recherche-Workflow starten und eine grafische Berichtsanalyse gemäß den folgenden Schritten durchführen:
Quant Research-Workflow: Führen Sie qrun mit der Lightgbm-Workflow-Konfiguration (workflow_config_lightgbm_Alpha158.yaml) wie folgt aus.
cd examples # Avoid running program under the directory contains `qlib`
qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml Wenn Benutzer qrun im Debug-Modus verwenden möchten, verwenden Sie bitte den folgenden Befehl:
python -m pdb qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml Das Ergebnis von qrun ist wie folgt. Weitere Einzelheiten zum Ergebnis finden Sie unter Intraday-Handel.
' The following are analysis results of the excess return without cost. '
risk
mean 0.000708
std 0.005626
annualized_return 0.178316
information_ratio 1.996555
max_drawdown -0.081806
' The following are analysis results of the excess return with cost. '
risk
mean 0.000512
std 0.005626
annualized_return 0.128982
information_ratio 1.444287
max_drawdown -0.091078 Hier finden Sie detaillierte Dokumente für qrun und Workflow.
Analyse grafischer Berichte: Führen Sie examples/workflow_by_code.ipynb mit jupyter notebook aus, um grafische Berichte zu erhalten
Prognosesignalanalyse (Modellvorhersage).
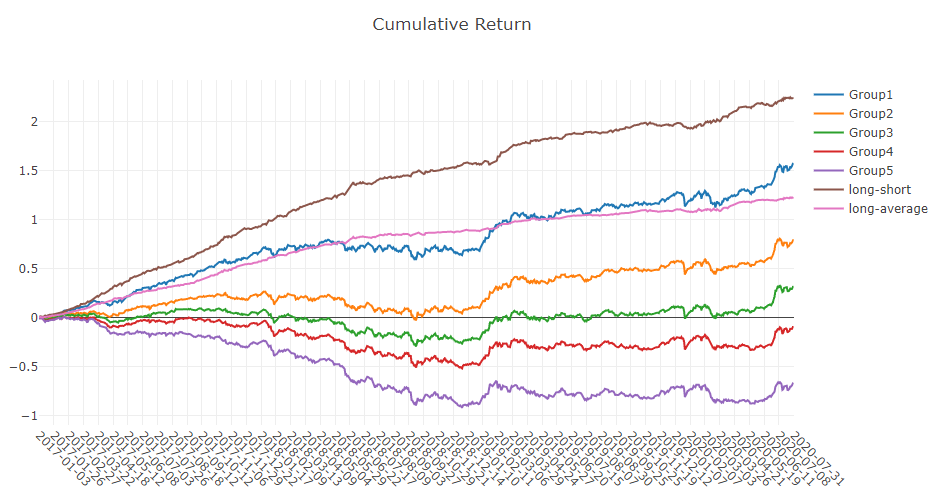
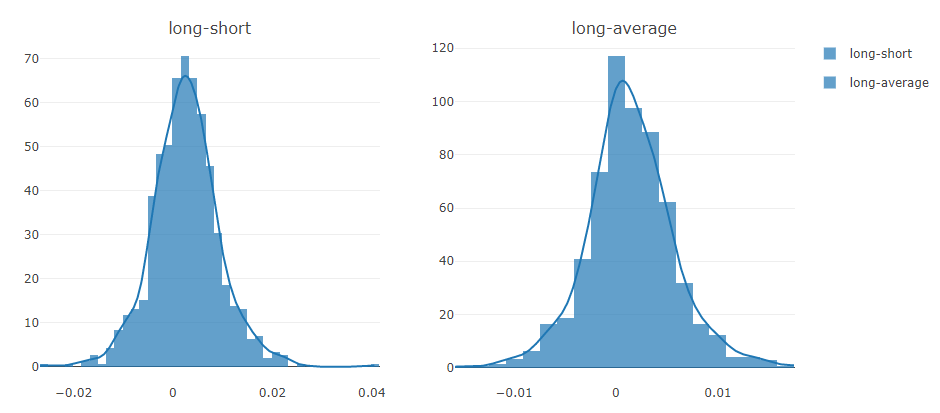
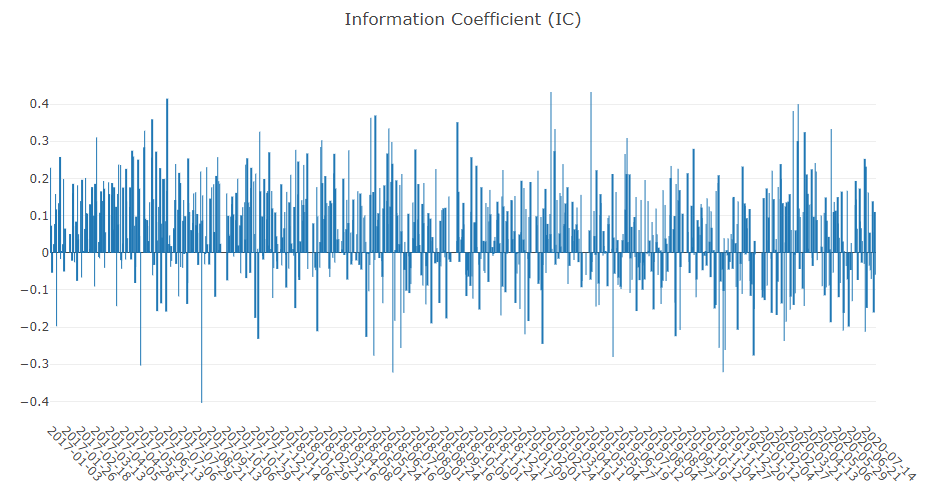
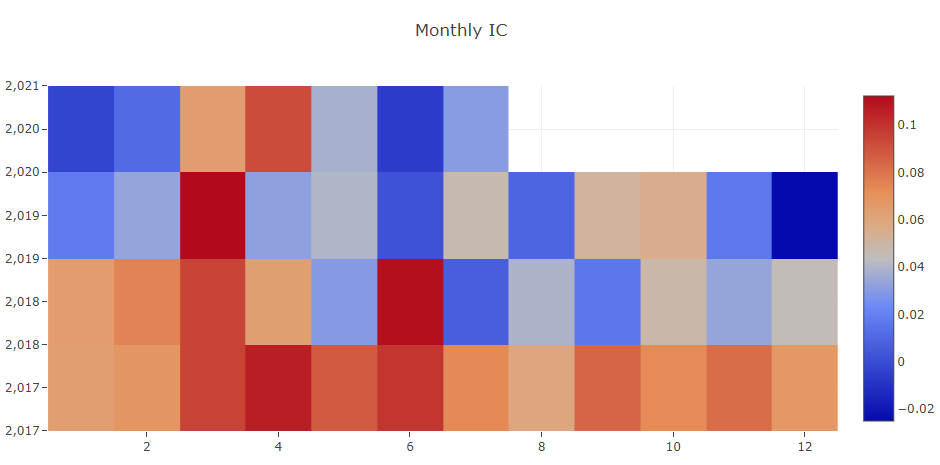
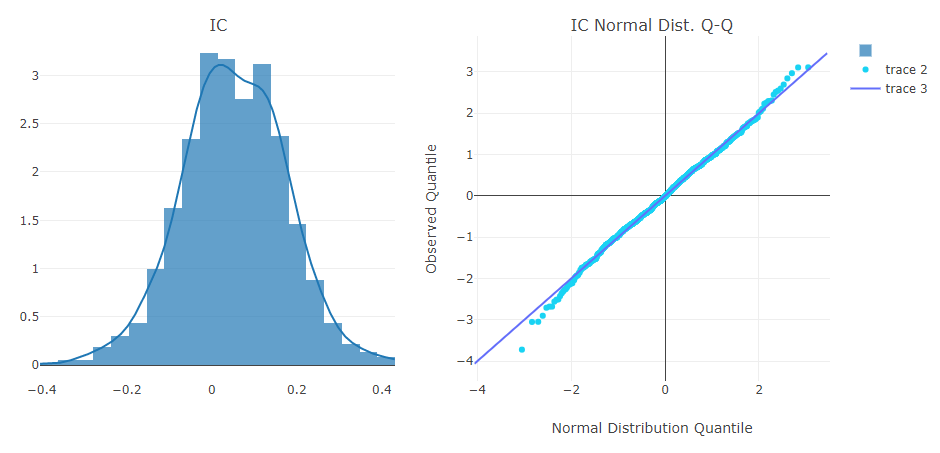
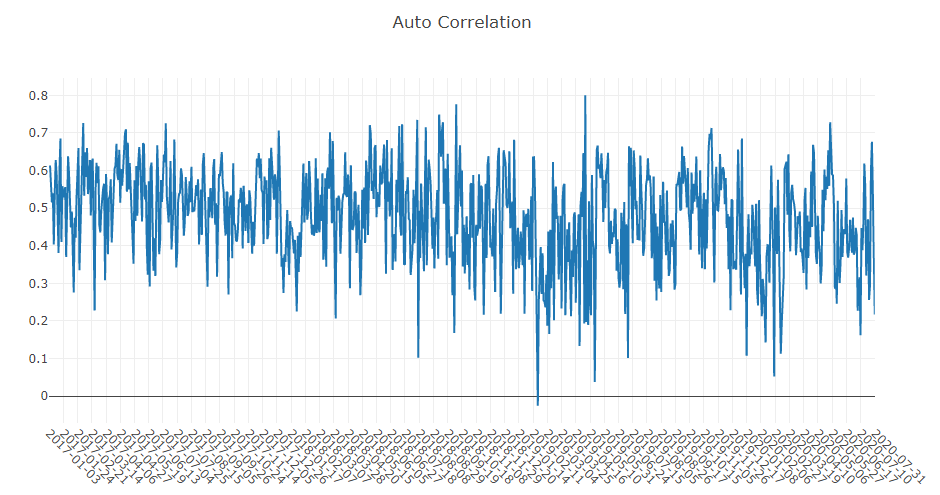
Portfolioanalyse
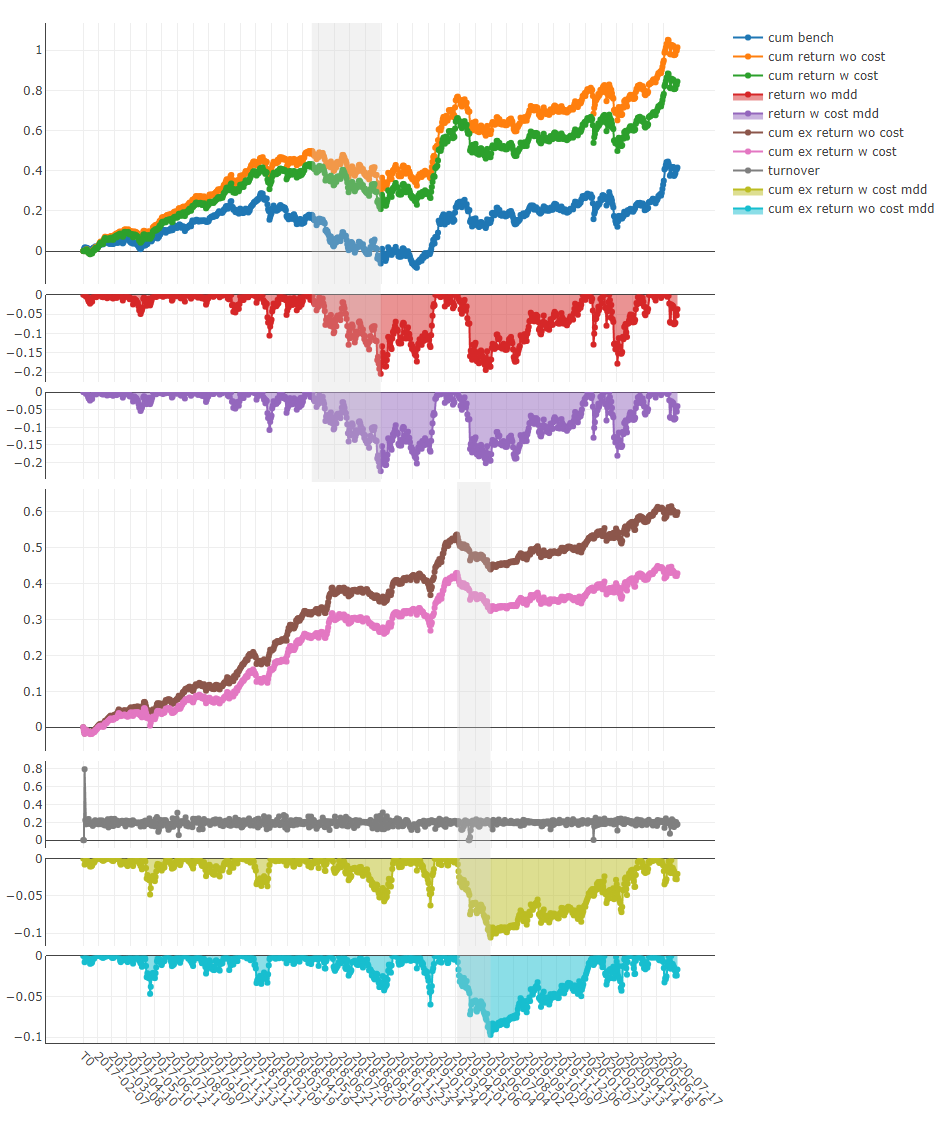
Erläuterung der obigen Ergebnisse
Der automatische Workflow passt möglicherweise nicht zum Forschungsworkflow aller Quant-Forscher. Um einen flexiblen Quant-Forschungsworkflow zu unterstützen, bietet Qlib außerdem eine modularisierte Schnittstelle, die es Forschern ermöglicht, ihren eigenen Workflow per Code zu erstellen. Hier ist eine Demo für einen maßgeschneiderten Quant-Recherche-Workflow per Code.
Quantitative Investitionen sind ein sehr einzigartiges Szenario mit vielen wichtigen Herausforderungen, die gelöst werden müssen. Derzeit bietet Qlib einige Lösungen für mehrere davon an.
Eine genaue Prognose der Aktienkursentwicklung ist ein sehr wichtiger Bestandteil beim Aufbau profitabler Portfolios. Allerdings gibt es auf dem Finanzmarkt riesige Datenmengen in verschiedenen Formaten, die die Erstellung von Prognosemodellen erschweren.
In Qlib werden immer mehr Forschungsarbeiten/-papiere von SOTA Quant veröffentlicht, die sich auf die Erstellung von Prognosemodellen konzentrieren, um wertvolle Signale/Muster in komplexen Finanzdaten zu ermitteln
Hier ist eine Liste von Modellen, die auf Qlib basieren.
Ihre PR für neue Quant-Modelle ist sehr willkommen.
Die Leistung jedes Modells in den Datensätzen Alpha158 und Alpha360 finden Sie hier.
Alle oben aufgeführten Modelle sind mit Qlib lauffähig. Benutzer können die von uns bereitgestellten Konfigurationsdateien und einige Details zum Modell im Ordner „Benchmarks“ finden. Weitere Informationen finden Sie in den oben aufgeführten Modelldateien.
Qlib bietet drei verschiedene Möglichkeiten, ein einzelnes Modell auszuführen. Benutzer können diejenige auswählen, die am besten zu ihren Fällen passt:
Benutzer können das oben erwähnte Tool qrun verwenden, um den Workflow eines Modells basierend auf einer Konfigurationsdatei auszuführen.
Benutzer können ein workflow_by_code -Python-Skript basierend auf dem im examples aufgeführten erstellen.
Benutzer können das im examples aufgeführte Skript run_all_model.py verwenden, um ein Modell auszuführen. Hier ist ein Beispiel für den spezifischen Shell-Befehl, der verwendet werden soll: python run_all_model.py run --models=lightgbm , wobei die Argumente --models eine beliebige Anzahl der oben aufgeführten Modelle annehmen können (die verfügbaren Modelle finden Sie in Benchmarks). Weitere Anwendungsfälle finden Sie in den Dokumentzeichenfolgen der Datei.
tensorflow==1.15.0 nur Python 3.6~3.7). Qlib bietet außerdem ein Skript run_all_model.py , das mehrere Modelle für mehrere Iterationen ausführen kann. ( Hinweis : Das Skript unterstützt derzeit nur Linux . Andere Betriebssysteme werden in Zukunft unterstützt. Außerdem unterstützt es nicht die mehrfache parallele Ausführung desselben Modells, und dies wird in der zukünftigen Entwicklung ebenfalls behoben.)
Das Skript erstellt für jedes Modell eine einzigartige virtuelle Umgebung und löscht die Umgebungen nach dem Training. Somit werden nur Experimentergebnisse wie IC und backtest -Ergebnisse generiert und gespeichert.
Hier ist ein Beispiel für die Ausführung aller Modelle für 10 Iterationen:
python run_all_model . py run 10Es stellt auch die API bereit, um bestimmte Modelle gleichzeitig auszuführen. Weitere Anwendungsfälle finden Sie in den Dokumentzeichenfolgen der Datei.
Aufgrund der instationären Natur des Finanzmarktumfelds kann sich die Datenverteilung in verschiedenen Zeiträumen ändern, was dazu führt, dass die Leistung von Modellen auf Trainingsdatenabfällen in zukünftigen Testdaten aufbaut. Daher ist die Anpassung der Prognosemodelle/-strategien an die Marktdynamik für die Leistung des Modells/der Strategie sehr wichtig.
Hier ist eine Liste von Lösungen, die auf Qlib basieren.
Qlib unterstützt jetzt Reinforcement Learning, eine Funktion zur Modellierung kontinuierlicher Investitionsentscheidungen. Diese Funktionalität unterstützt Anleger bei der Optimierung ihrer Handelsstrategien, indem sie aus Interaktionen mit der Umgebung lernen, um die Vorstellung einer kumulativen Belohnung zu maximieren.
Hier ist eine Liste von Lösungen, die auf Qlib basieren, kategorisiert nach Szenarien.
Hier ist die Einführung dieses Szenarios. Alle unten aufgeführten Methoden werden hier verglichen.
Der Datensatz spielt in Quant eine sehr wichtige Rolle. Hier ist eine Liste der auf Qlib erstellten Datensätze:
| Datensatz | US-Markt | China-Markt |
|---|---|---|
| Alpha360 | √ | √ |
| Alpha158 | √ | √ |
Hier ist ein Tutorial zum Erstellen eines Datensatzes mit Qlib . Ihre PR zur Erstellung eines neuen Quant-Datensatzes ist sehr willkommen.
Qlib ist hochgradig anpassbar und viele seiner Komponenten sind erlernbar. Die lernbaren Komponenten sind Instanzen von Forecast Model und Trading Agent . Sie werden auf der Grundlage der Learning Framework -Ebene erlernt und dann auf mehrere Szenarien in Workflow Ebene angewendet. Das Lernframework nutzt auch die Workflow Ebene (z. B. gemeinsame Nutzung Information Extractor , Erstellen von Umgebungen basierend auf Execution Env ).
Basierend auf Lernparadigmen können sie in verstärkendes Lernen und überwachtes Lernen kategorisiert werden.
Execution Env in Workflow Ebene, um Umgebungen zu erstellen. Es ist erwähnenswert, dass auch NestedExecutor unterstützt wird. Dadurch können Benutzer verschiedene Ebenen von Strategien/Modellen/Agenten gemeinsam optimieren (z. B. Optimierung einer Auftragsausführungsstrategie für eine bestimmte Portfoliomanagementstrategie).Wenn Sie einen kurzen Blick auf die am häufigsten verwendeten Komponenten von qlib werfen möchten, können Sie hier Notebooks ausprobieren.
Die detaillierten Dokumente sind in Dokumenten organisiert. Sphinx und das Readthedocs-Theme sind erforderlich, um die Dokumentation im HTML-Format zu erstellen.
cd docs/
conda install sphinx sphinx_rtd_theme -y
# Otherwise, you can install them with pip
# pip install sphinx sphinx_rtd_theme
make htmlSie können das aktuelle Dokument auch direkt online einsehen.
Qlib befindet sich in aktiver und kontinuierlicher Entwicklung. Unser Plan steht in der Roadmap, die als Github-Projekt verwaltet wird.
Der Datenserver von Qlib kann entweder im Offline -Modus oder Online -Modus bereitgestellt werden. Der Standardmodus ist der Offline-Modus.
Im Offline Modus werden die Daten lokal bereitgestellt.
Im Online -Modus werden die Daten als gemeinsamer Datendienst bereitgestellt. Die Daten und ihr Cache werden von allen Clients gemeinsam genutzt. Es wird erwartet, dass die Datenabrufleistung aufgrund einer höheren Cache-Trefferrate verbessert wird. Es wird auch weniger Speicherplatz beanspruchen. Die Dokumente des Online-Modus finden Sie im Qlib-Server. Der Onlinemodus kann automatisch mit Azure CLI-basierten Skripts bereitgestellt werden. Der Quellcode des Online-Datenservers befindet sich im Qlib-Server-Repository.
Die Leistung der Datenverarbeitung ist wichtig für datengesteuerte Methoden wie KI-Technologien. Als KI-orientierte Plattform bietet Qlib eine Lösung für die Datenspeicherung und Datenverarbeitung. Um die Leistung des Qlib-Datenservers zu demonstrieren, vergleichen wir ihn mit mehreren anderen Datenspeicherlösungen.
Wir bewerten die Leistung mehrerer Speicherlösungen, indem wir dieselbe Aufgabe abschließen, die einen Datensatz (14 Merkmale/Faktoren) aus den grundlegenden OHLCV-Tagesdaten einer Börse (800 Aktien pro Tag von 2007 bis 2020) erstellt. Die Aufgabe umfasst die Abfrage und Verarbeitung von Daten.
| HDF5 | MySQL | MongoDB | InfluxDB | Qlib -E -D | Qlib +E -D | Qlib +E +D | |
|---|---|---|---|---|---|---|---|
| Gesamt (1CPU) (Sekunden) | 184,4 ± 3,7 | 365,3 ± 7,5 | 253,6 ± 6,7 | 368,2 ± 3,6 | 147,0 ± 8,8 | 47,6 ± 1,0 | 7,4 ± 0,3 |
| Gesamt (64CPU) (Sekunden) | 8,8 ± 0,6 | 4,2 ± 0,2 |
+(-)E bedeutet mit (ohne) ExpressionCache+(-)D bedeutet mit (ohne) DatasetCacheDie meisten Allzweckdatenbanken benötigen zu viel Zeit zum Laden der Daten. Nach einem Blick auf die zugrunde liegende Implementierung stellen wir fest, dass Daten in Allzweck-Datenbanklösungen zu viele Schnittstellenebenen und unnötige Formattransformationen durchlaufen. Solche Overheads verlangsamen den Datenladevorgang erheblich. Qlib-Daten werden in einem kompakten Format gespeichert, das sich für wissenschaftliche Berechnungen effizient in Arrays kombinieren lässt.
Qlib leisten möchten, erstellen Sie bitte Pull-Requests.Treten Sie IM-Diskussionsgruppen bei:
| Gitter |
|---|
 |
Wir freuen uns über alle Beiträge und danken allen Mitwirkenden!
Bevor wir Qlib im September 2020 als Open-Source-Projekt auf Github veröffentlichten, war Qlib ein internes Projekt in unserer Gruppe. Leider wird der interne Commit-Verlauf nicht gespeichert. Viele Mitglieder unserer Gruppe haben auch viel zu Qlib beigetragen, darunter Ruihua Wang, Yinda Zhang, Haisu Yu, Shuyu Wang, Bochen Pang und Dong Zhou. Besonderer Dank geht an Dong Zhou für seine erste Version von Qlib.
Dieses Projekt freut sich über Beiträge und Vorschläge.
Hier finden Sie einige Codestandards und Entwicklungsanleitungen zum Einreichen einer Pull-Anfrage.
Beiträge zu leisten ist keine schwierige Sache. Das Lösen eines Problems (vielleicht nur das Beantworten einer in der Problemliste oder im Gitter aufgeworfenen Frage), das Beheben/Problem eines Fehlers, das Verbessern der Dokumente und sogar das Beheben eines Tippfehlers sind wichtige Beiträge zu Qlib.
Wenn Sie beispielsweise zum Dokument/Code von Qlib beitragen möchten, können Sie die Schritte in der folgenden Abbildung ausführen.

Wenn Sie nicht wissen, wie Sie anfangen sollen, einen Beitrag zu leisten, können Sie sich auf die folgenden Beispiele beziehen.
| Typ | Beispiele |
|---|---|
| Probleme lösen | Beantworten Sie eine Frage; einen Fehler melden oder beheben |
| Dokumente | Verbessern Sie die Qualität Ihrer Dokumente. Korrigieren Sie einen Tippfehler |
| Besonderheit | Implementieren Sie eine angeforderte Funktion wie diese. Refactor-Schnittstellen |
| Datensatz | Fügen Sie einen Datensatz hinzu |
| Modelle | Implementieren Sie ein neues Modell und einige Anweisungen zum Beitragen von Modellen |
Gute Erstausgaben sind gekennzeichnet, um darauf hinzuweisen, dass Sie mit Ihren Beiträgen leicht beginnen können.
Sie können einige einwandfreie Implementierungen in Qlib durch rg 'TODO|FIXME' qlib finden
Wenn Sie einer der Betreuer von Qlib werden möchten, um mehr beizutragen (z. B. bei der Merge-PR, bei Triage-Problemen), kontaktieren Sie uns bitte per E-Mail ([email protected]). Wir helfen Ihnen gerne bei der Aktualisierung Ihrer Erlaubnis.
Für die meisten Beiträge müssen Sie einem Contributor License Agreement (CLA) zustimmen, in dem Sie erklären, dass Sie das Recht haben, uns das Recht zur Nutzung Ihres Beitrags zu gewähren, und dies auch tatsächlich tun. Weitere Informationen finden Sie unter https://cla.opensource.microsoft.com.
Wenn Sie eine Pull-Anfrage einreichen, ermittelt ein CLA-Bot automatisch, ob Sie eine CLA bereitstellen müssen, und schmückt die PR entsprechend (z. B. Statusprüfung, Kommentar). Folgen Sie einfach den Anweisungen des Bots. Sie müssen dies nur einmal für alle Repos tun, die unsere CLA verwenden.
Dieses Projekt hat den Microsoft Open Source Verhaltenskodex übernommen. Weitere Informationen finden Sie in den häufig gestellten Fragen zum Verhaltenskodex oder wenden Sie sich bei weiteren Fragen oder Kommentaren an [email protected].


