EasyLLMOps
1.0.0
EasyLLMOps: Mühelose MLOps für leistungsstarke Sprachmodelle.
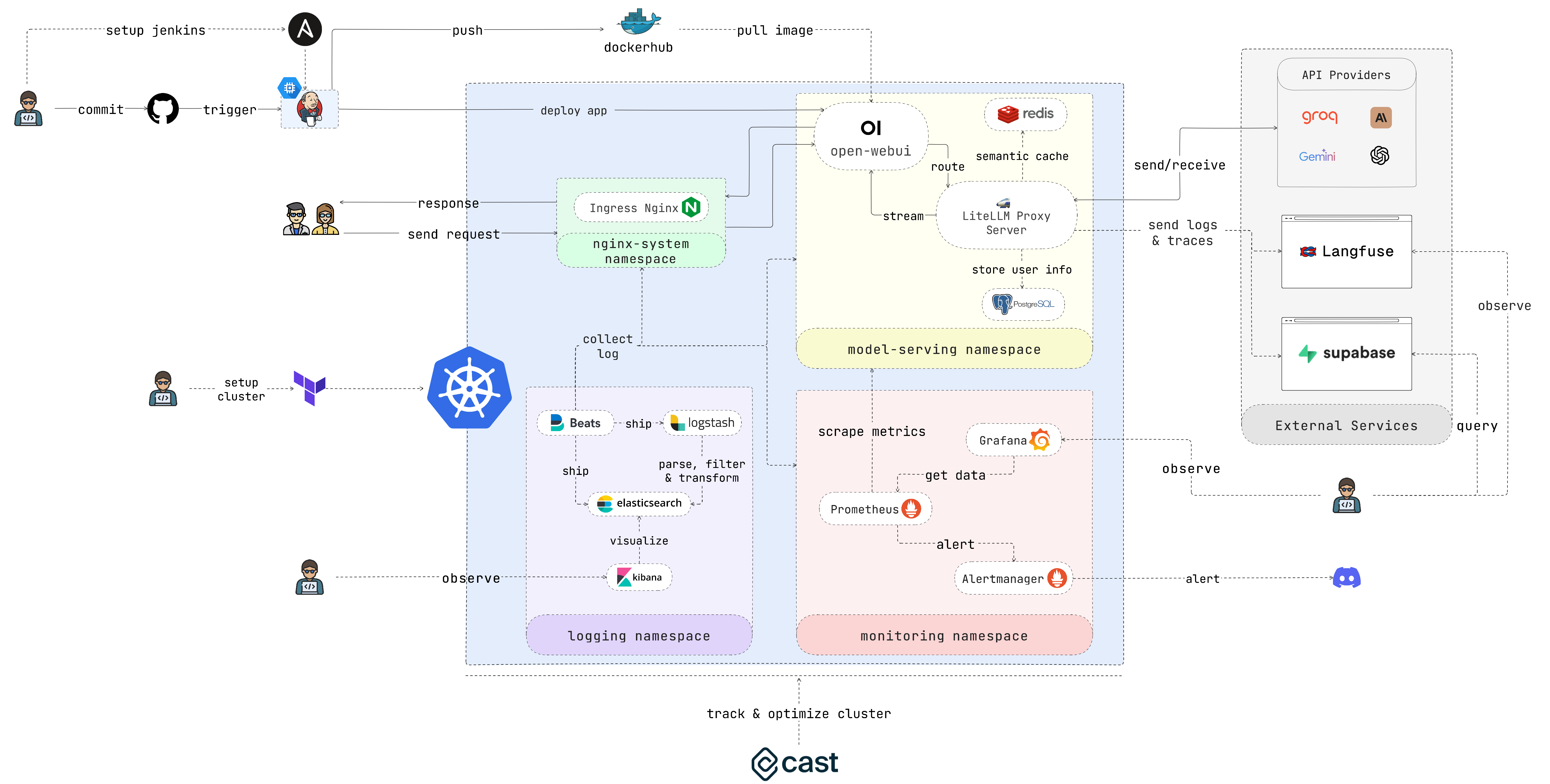
EasyLLMOps ist ein mit Open WebUI erstelltes Projekt, das auf Google Kubernetes Engine (GKE) zur Verwaltung und Skalierung von Sprachmodellen bereitgestellt werden kann. Es bietet sowohl Terraform- als auch manuelle Bereitstellungsmethoden und integriert robuste MLOps-Praktiken. Dazu gehören CI/CD-Pipelines mit Jenkins und Ansible zur Automatisierung, Überwachung mit Prometheus und Grafana für Leistungseinblicke und zentralisierte Protokollierung mit dem ELK-Stack zur Fehlerbehebung und Analyse. Entwickler finden detaillierte Dokumentationen und Anleitungen auf der Website des Projekts.
Entwickler, die LLM-basierte Anwendungen erstellen und bereitstellen. Datenwissenschaftler und Ingenieure für maschinelles Lernen, die mit LLMs arbeiten. DevOps-Teams, die für die Verwaltung der LLM-Infrastruktur verantwortlich sind. Organisationen, die LLMs in ihre Abläufe integrieren möchten.
Wenn Sie nicht viel Zeit aufwenden möchten, führen Sie bitte dieses Skript aus und genießen Sie Ihren Kaffee:
chmod +x ./cluster.sh
./cluster.shDenken Sie daran, sich bei GCP zu authentifizieren, bevor Sie Terraform verwenden:
gcloud auth application-default loginDieser Abschnitt enthält eine sehr schnelle Startanleitung, um die Anwendung so schnell wie möglich zum Laufen zu bringen. Ausführlichere Anweisungen finden Sie in den folgenden Abschnitten.
1. Richten Sie den Cluster ein:
Wenn Sie die Anwendung in GKE bereitstellen, können Sie Terraform verwenden, um die Einrichtung Ihres Kubernetes-Clusters zu automatisieren. Navigieren Sie zum Verzeichnis iac/terraform und initialisieren Sie Terraform:
cd iac/terraform
terraform initKonfiguration planen und anwenden:
Generieren Sie einen Ausführungsplan, um die Ressourcen zu überprüfen, die Terraform erstellen oder ändern wird, und wenden Sie dann die Konfiguration an, um den Cluster einzurichten:
terraform plan
terraform apply2. Cluster-Informationen abrufen:
Um mit Ihrem GKE-Cluster zu interagieren, müssen Sie dessen Konfiguration abrufen. Sie können die aktuelle Clusterkonfiguration mit dem folgenden Befehl anzeigen:
cat ~ /.kube/config Stellen Sie sicher, dass Ihr kubectl -Kontext richtig eingestellt ist, um den Cluster zu verwalten.
Für einen praktischeren Bereitstellungsprozess führen Sie die folgenden Schritte aus:
1. Stellen Sie den Nginx-Ingress-Controller bereit:
Der Nginx Ingress Controller verwaltet den externen Zugriff auf Dienste in Ihrem Kubernetes-Cluster. Erstellen Sie einen Namespace und installieren Sie den Ingress Controller mit Helm:
kubectl create ns nginx-system
kubens nginx-system
helm upgrade --install nginx-ingress ./deployments/nginx-ingressBitte geben Sie die IP-Adresse des Nginx Ingress Controllers an, da Sie diese später benötigen.
2. Konfigurieren Sie das API-Schlüsselgeheimnis:
Speichern Sie Ihre Umgebungsvariablen, wie z. B. API-Schlüssel, sicher in Kubernetes-Geheimnissen. Erstellen Sie einen Namespace für die Modellbereitstellung und ein Geheimnis aus Ihrer .env Datei:
kubectl create ns model-serving
kubens model-serving
kubectl delete secret easyllmops-env
kubectl create secret generic easyllmops-env --from-env-file=.env -n model-serving
kubectl describe secret easyllmops-env -n model-serving3. Berechtigungen erteilen:
Kubernetes-Ressourcen erfordern häufig bestimmte Berechtigungen. Wenden Sie die erforderlichen Rollen und Bindungen an:
cd deployments/infrastructure
kubectl apply -f role.yaml
kubectl apply -f rolebinding.yaml4. Stellen Sie den Caching-Dienst mit Redis bereit:
Stellen Sie nun den semantischen Caching-Dienst mit Redis bereit:
cd ./deployments/redis
helm dependency build
helm upgrade --install redis .5. LiteLLM bereitstellen:
Stellen Sie den LiteLLM-Dienst bereit:
kubens model-serving
helm upgrade --install litellm ./deployments/litellm6. Stellen Sie die Open WebUI bereit:
Stellen Sie als Nächstes die Web-Benutzeroberfläche in Ihrem GKE-Cluster bereit:
cd open-webui
kubectl apply -f ./kubernetes/manifest/base -n model-serving7. Spielen Sie mit der Anwendung herum:
Öffnen Sie den Browser, navigieren Sie zur URL Ihres GKE-Clusters (z. B. http://172.0.0.0 in Schritt 1) und fügen Sie .nip.io am Ende der URL hinzu (z. B. http://172.0.0.0.nip.io ). . Sie sollten die Open WebUI sehen:
Für automatisierte CI/CD-Pipelines verwenden Sie Jenkins und Ansible wie folgt:
1. Richten Sie den Jenkins-Server ein:
Erstellen Sie zunächst ein Dienstkonto und weisen Sie ihm die Rolle Compute Admin zu. Erstellen Sie dann eine Json-Schlüsseldatei für das Dienstkonto und speichern Sie sie im Verzeichnis iac/ansible/secrets .
Erstellen Sie als Nächstes eine Google Compute Engine-Instanz mit dem Namen „jenkins-server“, auf der Ubuntu 22.04 mit einer Firewall-Regel ausgeführt wird, die Datenverkehr auf den Ports 8081 und 50000 zulässt.
ansible-playbook iac/ansible/deploy_jenkins/create_compute_instance.yamlStellen Sie Jenkins auf einem Server bereit, indem Sie die Voraussetzungen installieren, ein Docker-Image abrufen und einen privilegierten Container mit Zugriff auf den Docker-Socket und die offengelegten Ports 8081 und 50000 erstellen.
ansible-playbook -i iac/ansible/inventory iac/ansible/deploy_jenkins/deploy_jenkins.yaml2. Greifen Sie auf Jenkins zu:
Um über SSH auf den Jenkins-Server zuzugreifen, müssen wir ein öffentliches/privates Schlüsselpaar erstellen. Führen Sie den folgenden Befehl aus, um ein Schlüsselpaar zu erstellen:
ssh-keygen Öffnen Sie Metadata und kopieren Sie den ssh-keys -Wert.
Wir müssen das Passwort des Jenkins-Servers finden, um auf den Server zugreifen zu können. Greifen Sie zunächst auf den Jenkins-Server zu:
ssh < USERNAME > : < EXTERNAL_IP >Führen Sie dann den folgenden Befehl aus, um das Passwort zu erhalten:
sudo docker exec -it jenkins-server bash
cat /var/jenkins_home/secrets/initialAdminPasswordSobald Jenkins bereitgestellt ist, greifen Sie über Ihren Browser darauf zu:
http://<EXTERNAL_IP>:8081
3. Jenkins-Plugins installieren:
Installieren Sie die folgenden Plugins, um Jenkins mit Docker, Kubernetes und GKE zu integrieren:
Starten Sie Jenkins nach der Installation der Plugins neu.
sudo docker restart jenkins-server4. Konfigurieren Sie Jenkins:
4.1. Fügen Sie Ihrem GitHub-Repository Webhooks hinzu, um Jenkins-Builds auszulösen.
Gehen Sie zum GitHub-Repository und klicken Sie auf Settings . Klicken Sie auf Webhooks und dann auf Add Webhook . Geben Sie die URL Ihres Jenkins-Servers ein (z. B. http://<EXTERNAL_IP>:8081/github-webhook/ ). Klicken Sie dann auf Let me select individual events und wählen Sie Let me select individual events aus. Wählen Sie Push und Pull Request und klicken Sie auf Add Webhook .
4.2. Fügen Sie das Github-Repository als Jenkins-Quellcode-Repository hinzu.
Gehen Sie zum Jenkins-Dashboard und klicken Sie auf New Item . Geben Sie einen Namen für Ihr Projekt ein (z. B. easy-llmops ) und wählen Sie Multibranch Pipeline aus. Klicken Sie auf OK . Klicken Sie auf Configure und dann auf Add Source . Wählen Sie GitHub aus und klicken Sie auf Add . Geben Sie die URL Ihres GitHub-Repositorys ein (z. B. https://github.com/bmd1905/EasyLLMOps ). Wählen Sie im Feld Credentials die Add und Username with password aus. Geben Sie Ihren GitHub-Benutzernamen und Ihr Passwort ein (oder verwenden Sie ein persönliches Zugriffstoken). Klicken Sie auf Test Connection und dann auf Save .
4.3. Richten Sie Docker-Hub-Anmeldeinformationen ein.
Erstellen Sie zunächst ein Docker Hub-Konto. Gehen Sie zur Docker Hub-Website und klicken Sie auf Sign Up . Geben Sie Ihren Benutzernamen und Ihr Passwort ein. Klicken Sie auf Sign Up . Klicken Sie auf Create Repository . Geben Sie einen Namen für Ihr Repository ein (z. B. easy-llmops ) und klicken Sie auf Create .
Gehen Sie im Jenkins-Dashboard zu Manage Jenkins > Credentials . Klicken Sie auf Add Credentials . Wählen Sie Username with password und klicken Sie auf Add . Geben Sie Ihren Docker Hub-Benutzernamen und Zugriffstoken ein und legen Sie ID auf dockerhub fest.
4.4. Richten Sie Kubernetes-Anmeldeinformationen ein.
Erstellen Sie zunächst ein Dienstkonto für den Jenkins-Server, um auf den GKE-Cluster zuzugreifen. Gehen Sie zur GCP-Konsole und navigieren Sie zu IAM & Admin > Dienstkonten. Erstellen Sie ein neues Dienstkonto mit der Rolle Kubernetes Engine Admin . Geben Sie dem Dienstkonto einen Namen und eine Beschreibung. Klicken Sie auf das Dienstkonto und dann auf die Registerkarte Keys . Klicken Sie auf Add Key und wählen Sie JSON als Schlüsseltyp aus. Klicken Sie auf Create und laden Sie die JSON-Datei herunter.
Gehen Sie dann im Jenkins-Dashboard zu Manage Jenkins > Cloud . Klicken Sie auf New cloud . Wählen Sie Kubernetes aus. Geben Sie den Namen Ihres Clusters ein (z. B. gke-easy-llmops-cluster-1), enter the URL and Certificate from your GKE cluster. In the Geben Sie gke-easy-llmops-cluster-1), enter the URL and Certificate from your GKE cluster. In the Kubernetes-Namespace , enter the namespace of your cluster (eg model-serving ). In the Wählen Sie ). In the field, select Anmeldeinformationen“ die Option „Hinzufügen“ and select . Geben Sie Ihre Projekt-ID und den Pfad zur JSON-Datei ein.
5. Testen Sie das Setup:
Pushen Sie einen neuen Commit in Ihr GitHub-Repository. Sie sollten einen neuen Build in Jenkins sehen.
1. Discord-Webhook erstellen:
Erstellen Sie zunächst einen Discord-Webhook. Gehen Sie zur Discord-Website und klicken Sie auf Server Settings . Klicken Sie auf Integrations . Klicken Sie auf Create Webhook . Geben Sie einen Namen für Ihren Webhook ein (z. B. easy-llmops-discord-webhook ) und klicken Sie auf Create . Kopieren Sie die Webhook-URL.
2. Konfigurieren Sie Helm-Repositorys
Zuerst müssen wir die notwendigen Helm-Repositorys für Prometheus und Grafana hinzufügen:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add grafana https://grafana.github.io/helm-charts
helm repo updateDiese Befehle fügen die offiziellen Prometheus- und Grafana-Helm-Repositorys hinzu und aktualisieren Ihre lokalen Helm-Diagramminformationen.
3. Abhängigkeiten installieren
Prometheus erfordert bestimmte Abhängigkeiten, die mit Helm verwaltet werden können. Navigieren Sie zum Überwachungsverzeichnis und erstellen Sie diese Abhängigkeiten:
helm dependency build ./deployments/monitoring/kube-prometheus-stack4. Setzen Sie Prometheus ein
Jetzt stellen wir Prometheus und die zugehörigen Dienste mithilfe von Helm bereit:
kubectl create namespace monitoring
helm upgrade --install -f deployments/monitoring/kube-prometheus-stack.expanded.yaml kube-prometheus-stack deployments/monitoring/kube-prometheus-stack -n monitoringDieser Befehl führt Folgendes aus:
helm upgrade --install : Dadurch wird Prometheus installiert, wenn es nicht existiert, oder aktualisiert, wenn es existiert.-f deployments/monitoring/kube-prometheus-stack.expanded.yaml : Dies gibt eine benutzerdefinierte Wertedatei für die Konfiguration an.kube-prometheus-stack : Dies ist der Releasename für die Helm-Installation.deployments/monitoring/kube-prometheus-stack : Dies ist das Diagramm, das für die Installation verwendet werden soll.-n monitoring : Dies gibt den Namespace an, in dem installiert werden soll.Standardmäßig werden die Dienste nicht extern verfügbar gemacht. Um darauf zuzugreifen, können Sie die Portweiterleitung verwenden:
Für Prometheus:
kubectl port-forward -n monitoring svc/kube-prometheus-stack-prometheus 9090:9090 Greifen Sie dann unter http://localhost:9090 auf Prometheus zu
Für Grafana:
kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80 Greifen Sie dann unter http://localhost:3000 auf Grafana zu
Die Standardanmeldeinformationen für Grafana sind normalerweise:
5. Testalarmierung
Zuerst müssen wir eine Beispielwarnung erstellen. Navigieren Sie zum monitoring und führen Sie den folgenden Befehl aus:
kubectl port-forward -n monitoring svc/alertmanager-operated 9093:9093Führen Sie dann in einem neuen Terminal den folgenden Befehl aus:
curl -XPOST -H " Content-Type: application/json " -d ' [
{
"labels": {
"alertname": "DiskSpaceLow",
"severity": "critical",
"instance": "server02",
"job": "node_exporter",
"mountpoint": "/data"
},
"annotations": {
"summary": "Disk space critically low",
"description": "Server02 has only 5% free disk space on /data volume"
},
"startsAt": "2023-09-01T12:00:00Z",
"generatorURL": "http://prometheus.example.com/graph?g0.expr=node_filesystem_free_bytes+%2F+node_filesystem_size_bytes+%2A+100+%3C+5"
},
{
"labels": {
"alertname": "HighMemoryUsage",
"severity": "warning",
"instance": "server03",
"job": "node_exporter"
},
"annotations": {
"summary": "High memory usage detected",
"description": "Server03 is using over 90% of its available memory"
},
"startsAt": "2023-09-01T12:05:00Z",
"generatorURL": "http://prometheus.example.com/graph?g0.expr=node_memory_MemAvailable_bytes+%2F+node_memory_MemTotal_bytes+%2A+100+%3C+10"
}
] ' http://localhost:9093/api/v2/alertsDieser Befehl erstellt eine Beispielwarnung. Sie können überprüfen, ob die Warnung erstellt wurde, indem Sie den folgenden Befehl ausführen:
curl http://localhost:9093/api/v2/statusOder Sie können den Discord-Kanal manuell überprüfen.
Dieses Setup bietet umfassende Überwachungsfunktionen für Ihren Kubernetes-Cluster. Indem Prometheus Metriken erfasst und Grafana diese visualisiert, können Sie die Leistung effektiv verfolgen, Warnungen für potenzielle Probleme einrichten und wertvolle Einblicke in Ihre Infrastruktur und Anwendungen gewinnen.
Eine zentralisierte Protokollierung ist für die Überwachung und Fehlerbehebung von auf Kubernetes bereitgestellten Anwendungen unerlässlich. Dieser Abschnitt führt Sie durch die Einrichtung eines ELK-Stacks (Elasticsearch, Logstash, Kibana) mit Filebeat zur Protokollierung Ihres GKE-Clusters.
0. Schneller Lauf
Sie können dieses einzelne Helmfile-Skript verwenden, um den ELK-Stack zu starten:
cd deployments/ELK
helmfile sync1. ELK Stack mit Helm installieren
Wir werden Helm verwenden, um die ELK-Stack-Komponenten bereitzustellen:
Erstellen Sie zunächst einen Namensraum für die Protokollierungskomponenten:
kubectl create ns logging
kubens loggingAls nächstes installieren Sie Elasticsearch:
helm install elk-elasticsearch elastic/elasticsearch -f deployments/ELK/elastic.expanded.yaml --namespace logging --create-namespaceWarten Sie, bis Elasticsearch bereit ist:
echo " Waiting for Elasticsearch to be ready... "
kubectl wait --for=condition=ready pod -l app=elasticsearch-master --timeout=300sErstellen Sie ein Geheimnis für Logstash, um auf Elasticsearch zuzugreifen:
kubectl create secret generic logstash-elasticsearch-credentials
--from-literal=username=elastic
--from-literal=password= $( kubectl get secrets --namespace=logging elasticsearch-master-credentials -ojsonpath= ' {.data.password} ' | base64 -d )Kibana installieren:
helm install elk-kibana elastic/kibana -f deployments/ELK/kibana.expanded.yamlLogstash installieren:
helm install elk-logstash elastic/logstash -f deployments/ELK/logstash.expanded.yamlFilebeat installieren:
helm install elk-filebeat elastic/filebeat -f deployments/ELK/filebeat.expanded.yaml2. Zugriff auf Kibana:
Machen Sie Kibana über einen Dienst verfügbar und greifen Sie über Ihren Browser darauf zu:
kubectl port-forward -n logging svc/elk-kibana-kibana 5601:5601Bitte verwenden Sie dieses Skript, um das Kibana-Passwort zu erhalten:
kubectl get secrets --namespace=logging elasticsearch-master-credentials -ojsonpath= ' {.data.password} ' | base64 -d Öffnen Sie Ihren Browser und navigieren Sie zu http://localhost:5601 .
3. Überprüfen Sie die Protokollsammlung
Sie sollten jetzt Protokolle Ihrer Kubernetes-Pods in Kibana sehen können. Sie können Dashboards und Visualisierungen erstellen, um Ihre Protokolle zu analysieren und Einblicke in das Verhalten Ihrer Anwendung zu gewinnen.
Bitte gehen Sie zu Cast AI, um ein kostenloses Konto zu eröffnen und das TOKEN zu erhalten.
Führen Sie dann diese Zeile aus, um eine Verbindung zu GKE herzustellen:
curl -H " Authorization: Token <TOKEN> " " https://api.cast.ai/v1/agent.yaml?provider=gke " | kubectl apply -f - Klicken Sie auf I ran this script “, kopieren Sie dann den Konfigurationscode und fügen Sie ihn in das Terminal ein:
CASTAI_API_TOKEN= < API_TOKEN > CASTAI_CLUSTER_ID= < CASTAI_CLUSTER_ID > CLUSTER_NAME=easy-llmops-gke INSTALL_AUTOSCALER=true INSTALL_POD_PINNER=true INSTALL_SECURITY_AGENT=true LOCATION=asia-southeast1-b PROJECT_ID=easy-llmops /bin/bash -c " $( curl -fsSL ' https://api.cast.ai/v1/scripts/gke/onboarding.sh ' ) " Klicken Sie auf I ran this script und gewartet, bis die Installation abgeschlossen ist“.
Anschließend können Sie Ihre Dashboards auf der Benutzeroberfläche von Cast AI sehen:
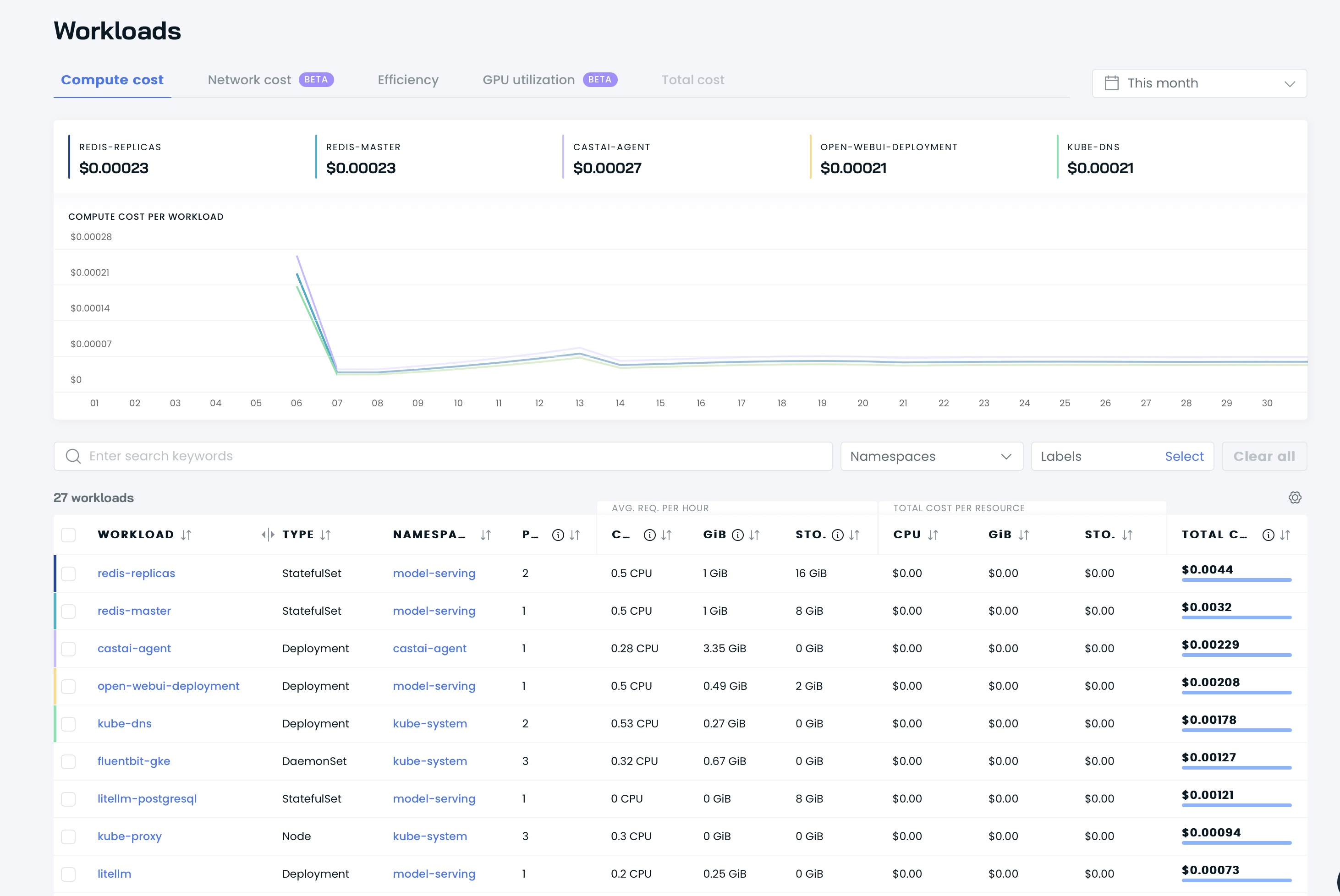
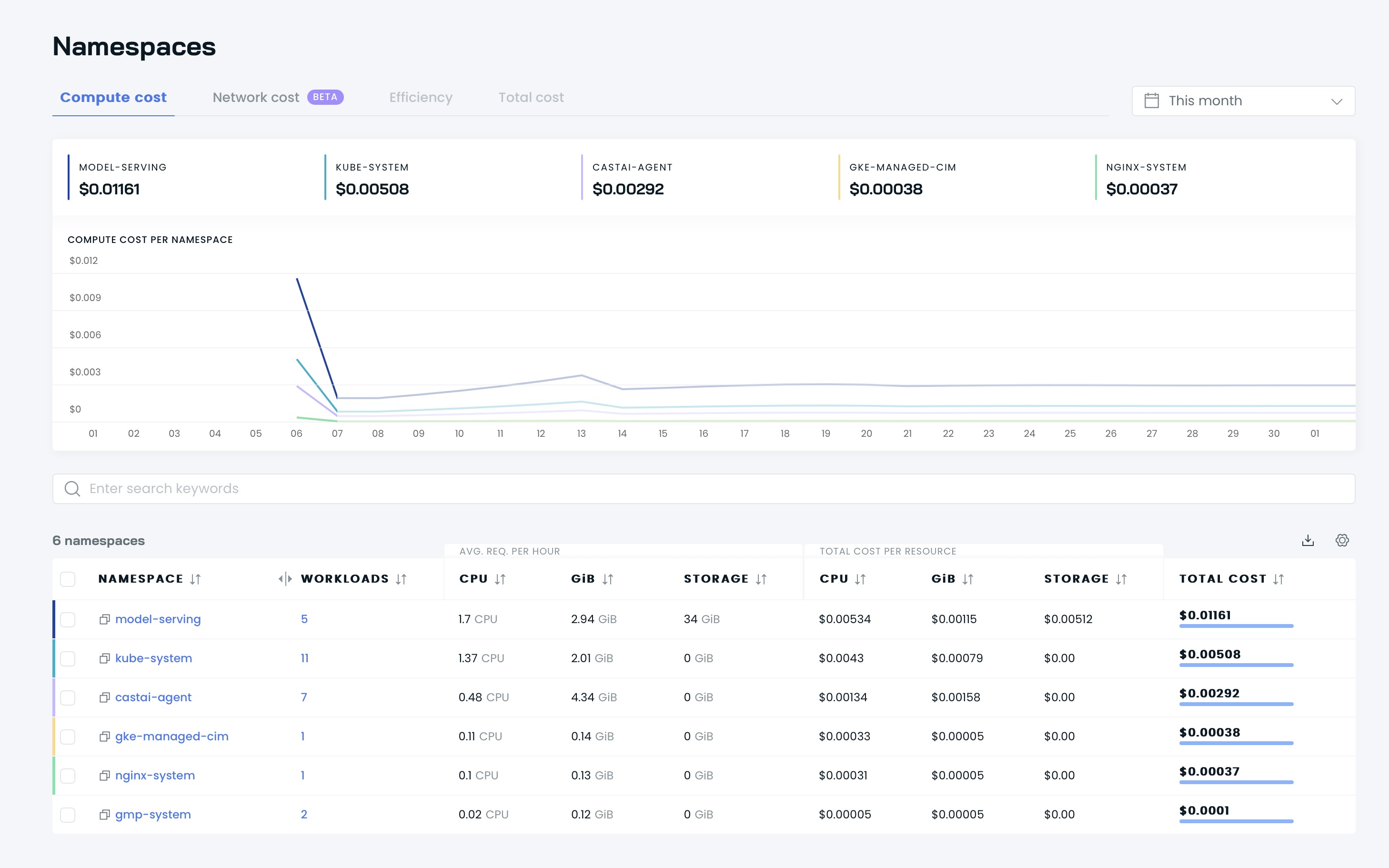
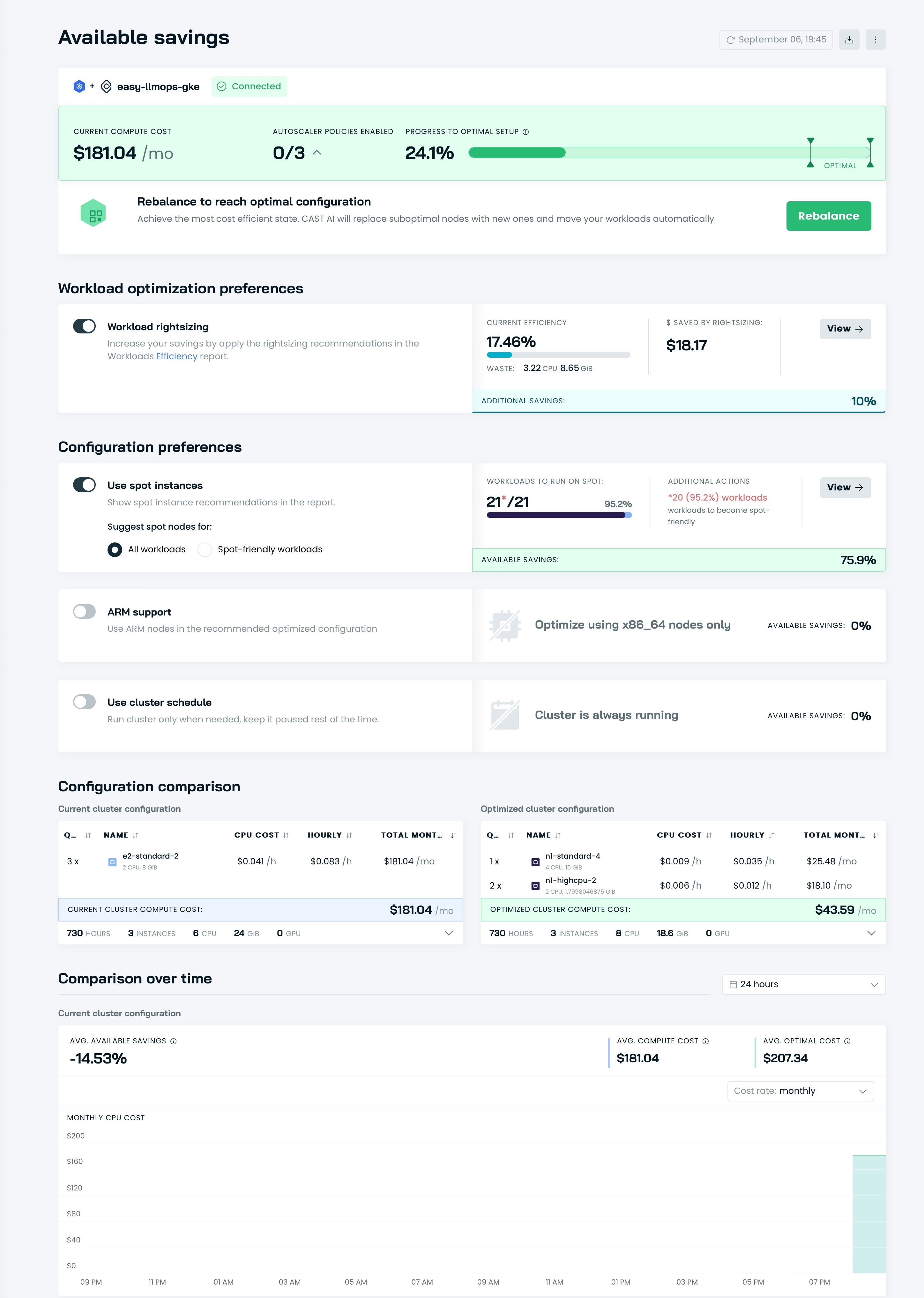
Es ist Zeit, Ihren Cluster mit Cast AI zu optimieren! Gehen Sie zur Option Available savings und klicken Sie auf die Schaltfläche Rebalance .
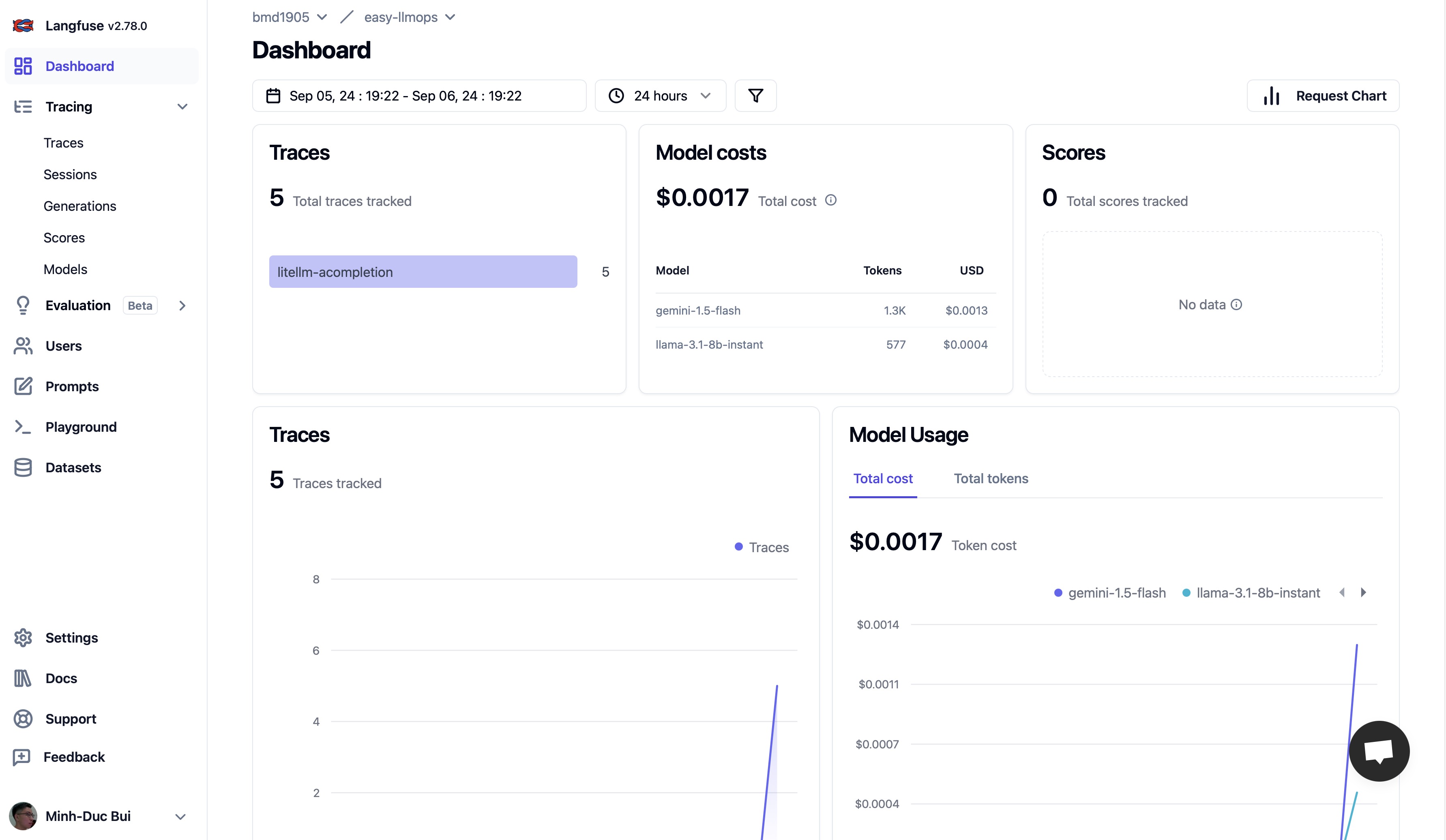
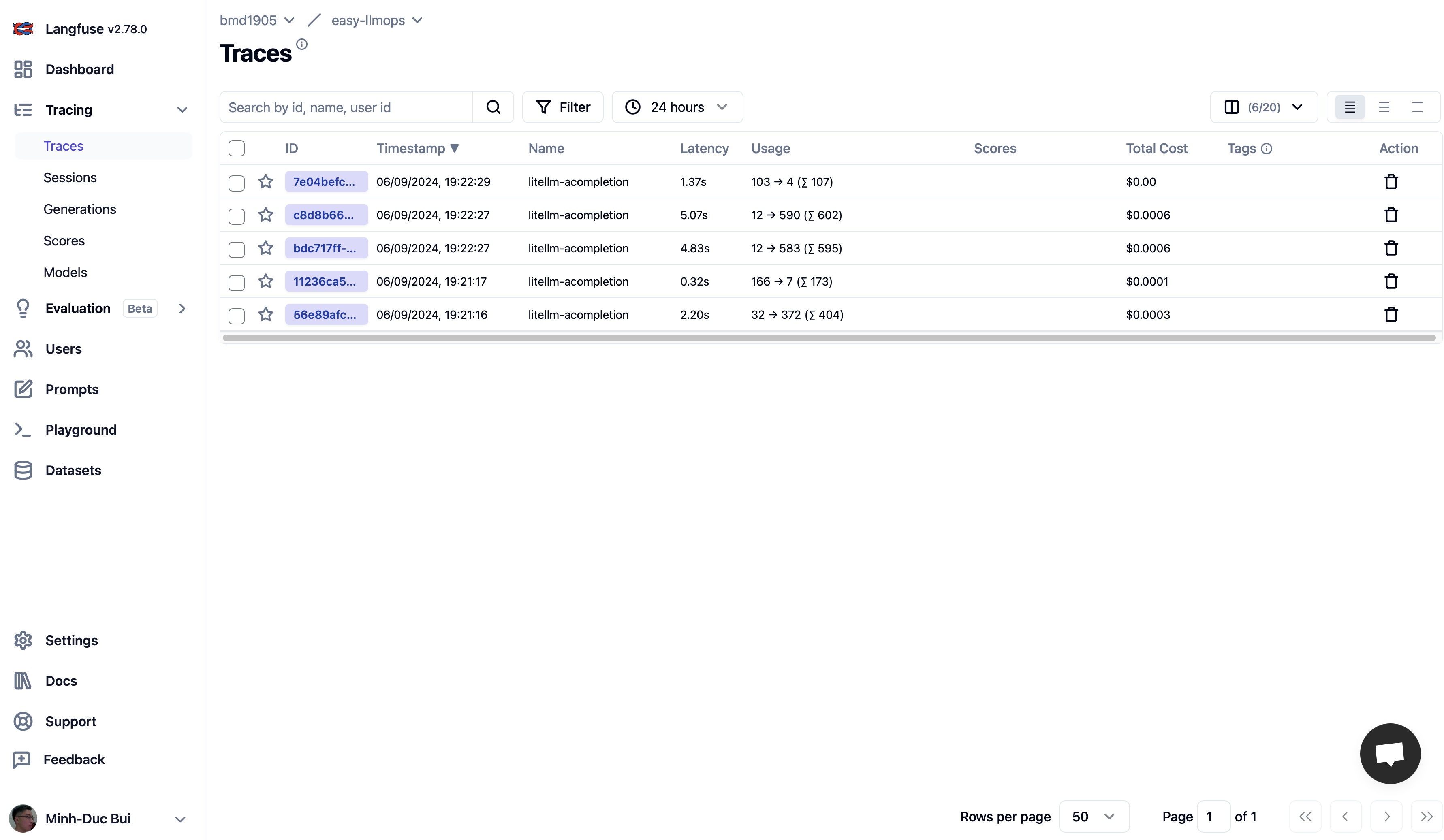
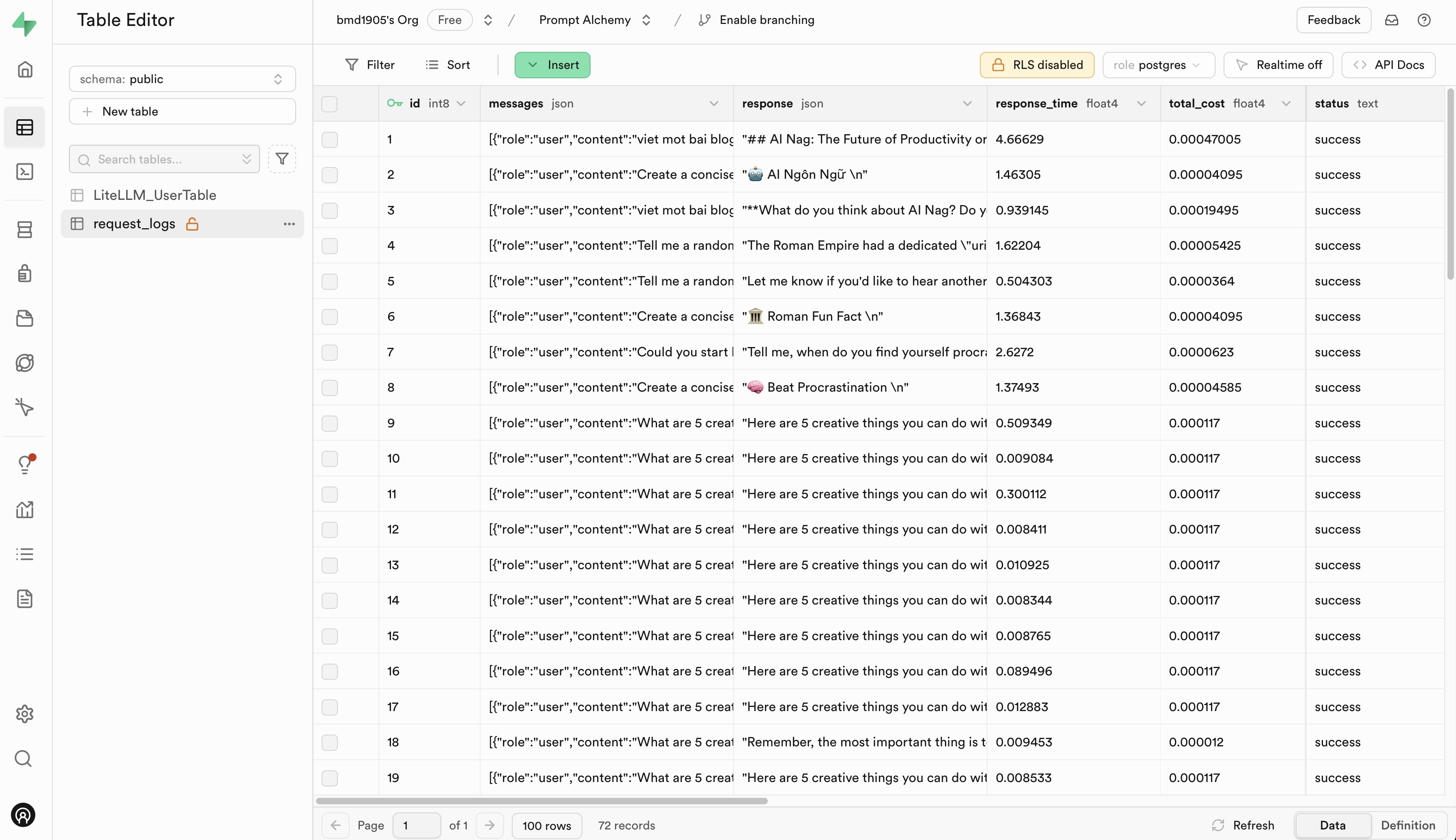
Bitte gehen Sie zu Langfuse und Supabase, um sich für ein kostenloses Konto zu registrieren und API-Schlüssel zu erhalten. Ersetzen Sie dann die Platzhalter in der Datei .env.example durch Ihre API-Schlüssel.
Wir freuen uns über Beiträge zu EasyLLMOps! Weitere Informationen zu den ersten Schritten finden Sie auf unserer Seite CONTRIBUTING.md.
EasyLLMOps wird unter der MIT-Lizenz veröffentlicht. Weitere Einzelheiten finden Sie in der LICENSE-Datei.
Wenn Sie EasyLLMOps in Ihrer Forschung verwenden, zitieren Sie es bitte wie folgt:
@software{EasyLLMOps2024,
author = {Minh-Duc Bui},
title = {EasyLLMOps: Effortless MLOps for Powerful Language Models.},
year = {2024},
url = {https://github.com/bmd1905/EasyLLMOps}
}
Bei Fragen, Problemen oder Kooperationen öffnen Sie bitte ein Issue in unserem GitHub-Repository oder wenden Sie sich direkt an die Betreuer.


