duplicut
v2.2 release
Heutzutage erfordert die Erstellung einer Passwort-Wortliste normalerweise die Verknüpfung mehrerer Datenquellen.
Idealerweise sollten die wahrscheinlichsten Passwörter am Anfang der Wortliste stehen, sodass die häufigsten Passwörter sofort geknackt werden.
Bei vorhandenen Deduplizierungstools müssen Sie sich entscheiden, ob Sie lieber die Reihenfolge beibehalten ODER mit riesigen Wortlisten umgehen möchten.
Leider erfordert die Erstellung einer Wortliste beides :

Also habe ich Duplicut in hochoptimiertem C geschrieben, um diesem ganz speziellen Bedarf gerecht zu werden?
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt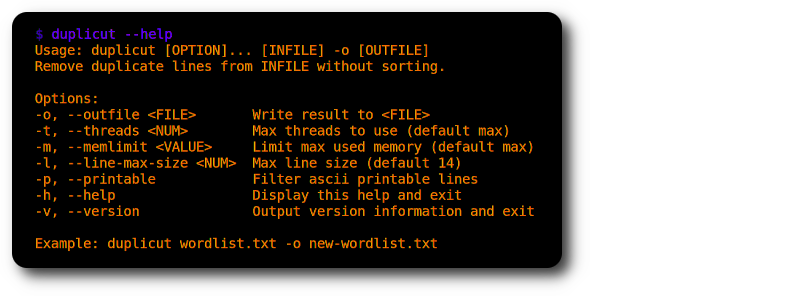
Merkmale :
-l )-p )Umsetzung :
Einschränkungen :
Ein uint64 reicht aus, um Zeilen in der Hashmap zu indizieren, indem size in die zusätzlichen Bits des Zeigers gepackt werden:
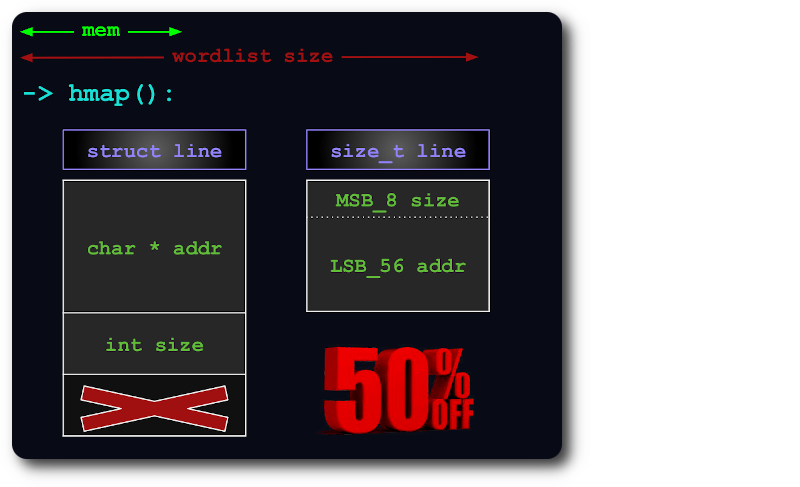
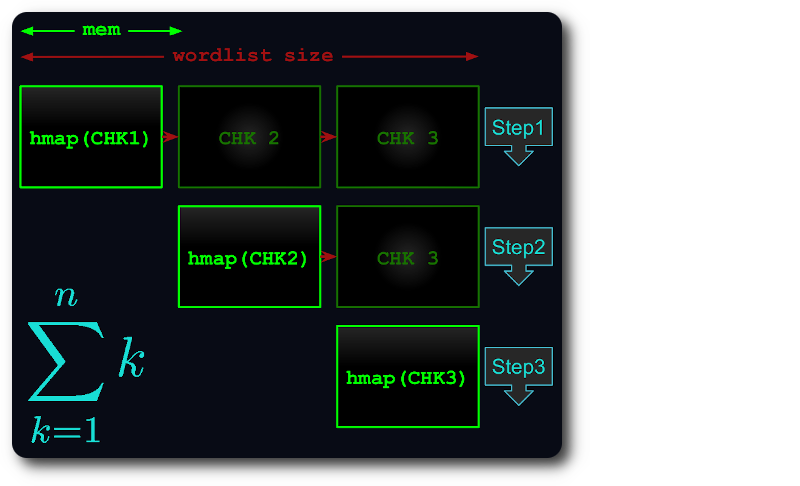
Wenn die gesamte Datei nicht in den Speicher passt, wird sie in virtuelle Blöcke aufgeteilt, sodass jeder Block so viel RAM wie möglich beansprucht.
Jeder Chunk wird dann in die Hashmap geladen, dedupliziert und mit nachfolgenden Chunks verglichen.
Auf diese Weise verkürzt sich die Ausführungszeit auf höchstens die Dreieckszahl :
Wenn Sie einen Fehler finden oder etwas nicht wie erwartet funktioniert, kompilieren Sie duplicut bitte im Debug-Modus und posten Sie ein Problem mit angehängter Ausgabe:
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


